Deep Blue是赢得国际象棋世界冠军的第一台计算机。那是1996年,花了20年的时间,另一个程序AlphaGo击败了最好的人类围棋选手。Deep Blue是具有硬线棋规则的基于模型的系统。AlphaGo是一个数据挖掘系统,它是一个经过数千次Go游戏训练的深度神经网络。没有改进的硬件,但是软件的突破对于从击败顶级国际象棋玩家到击败顶级Go玩家至关重要。 在迷你系列的第4部分中,我们将研究数据挖掘方法用于制定交易策略。这种方法不关心市场机制。它只是扫描价格曲线或其他数据源以查找预测模式。机器学习或“人工智能”并不总是涉及数据挖掘策略。实际上,最流行且利润惊人的数据挖掘方法无需任何花哨的神经网络或支持向量机即可工作。 机器学习原理 一种学习算法将提供数据样本,通常以某种方式从历史价格中得出数据。每个样本由n个变量x 1 .. x n组成,通常被称为预测变量,特征,信号或输入。这些预测变量可以是最后n条柱的价格回报,也可以是经典指标的集合,或者可以是价格曲线的任何其他可想象的函数。每个样本通常还包含目标变量 y,例如取样后的下一笔交易回报或下一次价格变动。在文献中,你可以找到?也称为标签或目标。在训练过程中,算法学习从预测变量x 1 .. x n预测目标y。学到的“内存”存储在名为模型的数据结构中,该数据结构特定于算法(不要与基于模型的策略的财务模型相混淆)!)。机器学习模型可以是具有由训练过程生成的C代码中的预测规则的函数。也可以是神经网络的一组连接权重。
预测变量,特征或您所谓的任何变量,都必须带有足以准确预测目标y的信息。他们通常还必须满足两个正式的要求。首先,所有预测值都应在同一范围内,例如-1 .. +1(对于大多数R算法)或-100 .. +100(对于Zorro或TSSB算法)。因此,在将它们发送到计算机之前,您需要以某种方式对其进行标准化。其次,样本应保持平衡,即均匀分布在目标变量的所有值上。因此,获胜的样本应该与失败的样本一样多。如果您没有遵守这两个要求,您会想知道为什么机器学习算法会产生不好的结果。 回归算法可以预测一个数值,例如下一个价格走势的幅度和符号。分类算法可预测定性的样本类别,例如,上涨还是下跌。某些算法(例如神经网络,决策树或支持向量机)可以在两种模式下运行。 一些算法学习将样本划分为类,而无需任何目标y。这是无监督学习,而不是使用目标进行监督学习。介于两者之间的是强化学习,即系统通过运行具有给定功能的仿真并将结果用作训练目标来进行自我训练。AlphaGo的后继者AlphaZero通过对自己进行数百万个Go游戏来使用强化学习。在金融领域,很少有无监督学习或强化学习的应用程序。99%的机器学习策略使用监督学习。 无论我们将哪些信号用作金融预测指标,它们都极有可能包含大量噪音和少量信息,并且在其之上是不稳定的。因此,金融预测是机器学习中最难的任务之一。更复杂的算法不一定能获得更好的结果。选择预测变量对于成功至关重要。使用大量的预测变量并不是一个好主意,因为这只会导致过拟合和样本外操作失败。因此,数据挖掘策略通常会应用预选算法在众多预测变量中确定了少数预测变量。预选择可以基于预测变量之间的相关性,重要性,信息内容或仅基于测试集的预测成功。 这是金融中最流行的数据挖掘方法的列表。 技术指标 我们为客户编程的大多数交易系统都不基于财务模型。客户只是想要来自某些技术指标的交易信号,并与其他技术指标结合更多的技术指标进行过滤。当被问及如何将这些杂乱无章的指标变成一种有利可图的策略时,他通常会回答:“相信我。我正在手动交易,它可以正常工作。” 确实做到了,至少有时候会成功。尽管这些系统大多数都没有通过WFA测试(有些甚至没有通过简单的回测),但数量却惊人地多。而且这些也经常在真实交易中获利。客户系统地尝试了技术指标,直到找到一种组合可以用于某些资产的实时交易。这种反复试验的技术分析方法是一种经典的数据挖掘方法,仅由人而不是由机器执行。我不能真正推荐这种方法-可能涉及很多运气,更不用说金钱了-但是我可以证明它有时会带来有利可图的系统。 蜡烛图形态 不要与很早以前就存在其最佳日期的日本蜡烛图案混淆。现代等价物是价格行为交易。您仍在查看蜡烛的开盘价,最高价,最低价和收盘价。您仍然希望找到一种预测价格方向的模式。但是,您现在正在数据挖掘当代价格曲线以收集这些模式。有用于此目的的软件包。他们搜索可以通过某些用户定义的准则获利的模式,并使用它们来构建特定的模式检测功能。看起来可能像这样(来自Zorro的模式分析器):
当信号与模式之一匹配时,此C函数将返回1,否则返回0。从冗长的代码中可以看出,这不是检测模式的最快方法。Zorro在不需要导出检测功能时使用的一种更好的方法是按信号的大小对信号进行排序并检查排序顺序。这样的系统的一个例子可以在这里找到。 价格行为交易真的可以工作吗?就像技术指标一样,它也不基于任何理性的财务模型。充其量只能想象价格波动的序列会导致市场参与者以某种方式做出反应,从而建立一种临时的预测模式。但是,当您仅查看几个相邻蜡烛的序列时,图案的数量就非常有限。下一步是比较不相邻但在较长时间内任意选择的蜡烛。通过这种方式,您将获得几乎无限数量的模式-但要以最终离开理性领域为代价。很难想象如何通过几周前的一些蜡烛形态来预测价格走势。 尽管如此,仍需要付出很多努力。博客作者Daniel Fernandez则经营着一个订阅网站(Asirikuy),专门从事数据挖掘蜡烛图模式。他将模式交易细化为最小的细节,如果有人能以这种方式获得任何利润,那就是他。但是令他的订阅者失望的是,实时交易其模式(QuriQuant)产生的结果与他出色的回测结果截然不同。如果确实存在有利可图的价格行动系统,显然还没有人找到它们。 线性回归 许多复杂的机器学习算法的简单基础:通过预测变量x 1 .. x n的线性组合来预测目标变量y。
感知器 通常称为只有一个神经元的神经网络。实际上,感知器是如上所述的回归函数,但是具有二进制结果,因此称为逻辑回归。它不是回归,而是分类算法。Zorro的advisor(PERCEPTRON,…)函数生成C代码,该代码返回100或-100,具体取决于预测结果是否高于阈值:
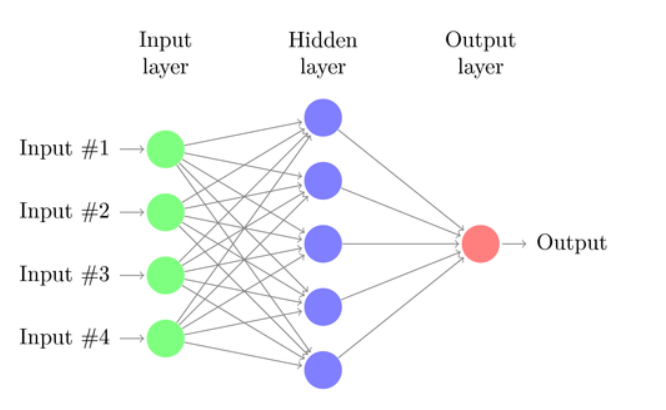
神经网络 线性或逻辑回归只能解决线性问题。许多不属于这一类–一个著名的例子是预测简单XOR函数的输出。而且最有可能还预测价格或投资回报。人工神经网络(ANN)可以解决非线性问题。这是一堆感知器,它们以多层的形式连接在一起。任何感知器都是网络的神经元。其输出将进入下一层所有神经元的输入,如下所示:
像感知器一样,神经网络也可以通过确定最小化样本预测和样本目标之间误差的系数来学习。但这现在需要一个近似过程,通常是将误差从输出反向传播到输入,从而优化权重。此过程施加了两个限制。首先,神经元输出现在必须具有连续可微的功能,而不是简单的感知器阈值。其次,网络一定不能太深-输入和输出之间的神经元一定不能有太多的“隐藏层”。第二个限制条件限制了标准神经网络可以解决的问题的复杂性。 当使用神经网络来预测交易时,您会使用很多参数,如果您不小心的话,会产生很多选择偏差: l隐藏层数 l每个隐藏层的神经元数量 l反向传播周期数,称为时期 l学习率,一个时代的步幅 l动量,权重自适应的惯性因子 l激活功能 对于反向传播,您需要一个可连续微分的函数,该函数可在某个x值处生成一个“软”步。通常使用Sigmoid,tanh或softmax函数。有时它也是一个线性函数,只返回所有输入的加权和。在这种情况下,网络可用于回归,用于预测数值而不是二进制结果。 深度学习 深度学习方法使用具有许多隐藏层和数千个神经元的神经网络,而传统的反向传播再也无法对其进行有效训练。在过去的几年中,用于训练如此庞大的网络的几种方法变得很流行。他们通常会预先训练隐藏的神经元层,以实现更有效的学习过程。甲受限玻尔兹曼机(RBM)是一种无监督分类算法与具有隐藏神经元之间没有任何连接一个特殊的网络结构。一个稀疏自动编码器(SAE)使用传统的网络结构,但是通过以尽可能少的活动连接在层输出上再现输入信号,以一种巧妙的方式对隐藏层进行了预训练。这些方法允许使用非常复杂的网络来处理非常复杂的学习任务。例如击败世界上最好的人类围棋运动员。 Deepnet和darch R软件包中提供了深度学习网络。Deepnet提供了自动编码器,Darch提供了受限的Boltzmann机器。我还没有尝试过Darch,但是这里有一个示例脚本,其中使用了Deepnet自动编码器,该编码器具有3个隐藏层,可通过Zorro的Neuro()函数来交易信号:
支持向量机 像神经网络一样,支持向量机(SVM)是线性回归的另一种扩展。当我们再次查看回归公式
我们可以将特征x n解释 为n维特征空间的坐标。将目标变量y 设置为固定值将确定该空间中的一个平面,称为超平面,因为它具有两个以上的维度(实际上是n-1)。超平面将y> 0的样本与y <0的样本分开。在一个?可以通过以下方式计算系数:平面到最近样本的距离(称为平面的“支持向量”,因此称为算法名称)最大。这样,我们就有了一个二元分类器,可以将获胜和失败的样本进行最佳分离。 问题是:通常这些样本不是线性可分离的- 它们在特征空间中不规则地散布。赢家和输家之间不能挤扁平面。如果可以的话,我们可以采用更简单的方法来计算该平面,进行线性判别分析。但是对于常见情况,我们需要SVM技巧:在要素空间中添加更多尺寸。为此,SVM算法利用内核功能产生了更多功能将现有的两个预测变量组合到一个新功能中。这类似于上面的从简单回归到多项式回归的步骤,在该步骤中,通过将唯一的预测变量取n次幂,还添加了更多特征。添加的尺寸越多,用平坦的超平面分离样品就越容易。然后,该平面被转换回原始的n维空间,在途中起皱和起皱。通过巧妙地选择内核功能,可以在不实际计算转换的情况下执行该过程。 像神经网络一样,支持向量机不仅可以用于分类,而且可以用于回归。它们还提供了一些参数来优化和可能过度拟合预测过程: l内核功能。通常,您使用RBF内核(径向基函数,对称内核),但也可以选择其他内核,例如Sigmoid,多项式和线性。 lGamma,RBF内核的宽度 l成本参数C,训练样本中错误分类的“惩罚” 常用的SVM是libsvm库。它也可以通过e1071软件包的R版本获得。在本系列的下一个也是最后一部分,我计划描述使用此SVM的交易策略。 K最近邻 与繁重的ANN和SVM相比,这是一种具有独特属性的不错的简单算法:无需训练。因此样本就是模型。您可以通过简单地添加越来越多的样本将这种算法用于永久学习的交易系统。最近邻居算法计算从当前特征值到k个最近样本的特征空间中的距离。就像两个维度一样,计算两个特征集(x 1 .. x n)和(y 1 .. y n)在n维空间中的距离:
该算法仅根据最近样本的k个目标变量的平均值(由其反距离加权)来预测目标。它可以用于分类以及回归。从计算机图形学借来的软件技巧,例如自适应二叉树(ABT),可以使最近邻居搜索变得相当快。在我过去作为计算机游戏程序员的生活中,我们在游戏中使用了这种方法来完成诸如自学敌人情报之类的任务。您可以在R中调用knn函数进行最近邻居预测-或为此目的在C中编写一个简单函数。 K均值 这是无监督分类的一种近似算法。它与k最近邻有一些相似之处,不仅是名称。为了对样本进行分类,该算法首先将k个随机点放置在特征空间中。然后,将所有距离最短的样本分配给这些点中的任何一个。然后将点移动到这些最近样本的平均值。这将产生一个新的样本分配,因为现在一些样本更接近另一个点。重复该过程,直到通过移动这些点不再改变分配,即,每个点正好位于其最近样本的平均值处。现在,我们有k个样本类别,每个样本都在k点之一附近。 这个简单的算法可以产生令人惊讶的良好结果。在R中,kmeans函数可以解决问题。可以在此处找到用于对烛型进行分类的k-means算法的示例:无监督烛台分类,以获取乐趣和收益。 朴素贝叶斯 该算法使用贝叶斯定理对非数字特征(即事件)的样本进行分类,例如上述蜡烛图案。假设事件X(例如,上一个小节的“开盘”低于当前小节的“开盘”)出现在所有获胜样本中的80%。那么,样本包含事件X时获胜的概率是多少?可能不是您想象的0.8。概率可以用贝叶斯定理计算:
P(Y | X)是事件 Y(fi获胜)发生在所有包含事件 X的样本中的概率 (在我们的示例中, Open(1)<Open(0))。根据公式,它等于 所有获胜样本中 X发生的概率(此处为0.8)乘以所有样本中 Y的概率(遵循我上面关于均衡样本的建议时约为0.5)并除以所有样本中 X的概率。 如果我们很幼稚并且假设所有事件X彼此独立,则可以通过简单地将每个事件X的概率P (X | winning)相乘来计算样本获胜的总体概率。这样,我们最终得到以下公式:
比例因子为s。为使公式起作用,应以尽可能独立的方式选择功能,这对在交易中使用朴素贝叶斯构成了障碍。例如,两个事件Close(1)<Close(0)和Open(1)<Open(0)最有可能彼此不独立。通过将数字划分为单独的范围,可以将数字预测变量转换为事件。 朴素贝叶斯算法可在无处不在的e1071 R软件包中使用。 决策树和回归树 这些树根据一系列的if-then-else决定来预测结果或数值,其结构类似于树的分支。任何决定都是事件的存在与否(在非数字特征的情况下)或特征值与固定阈值的比较。由Zorro的树生成器生成的典型树函数如下所示: 从一组样本中如何产生这样的树?有几种方法。Zorro使用Shannon 信息熵。首先它会检查其中一个特征,例如x1。它将具有平面公式x1 = t 的超平面放入特征空间。此超平面与所述样品分离X 1 >t从与样品X 1 < t。选择划分阈值t,以便信息增益– 整个空间的信息熵与两个划分的子空间的信息熵之和之差最大。当子空间中的样本比整个空间中的样本彼此更相似时,就是这种情况。 然后,使用下一个特征x 2和拆分两个子空间的两个超平面重复此过程。每个分割等效于特征与阈值的比较。通过反复拆分,我们很快就会得到一棵巨大的树,其中包含数千个阈值比较。然后,通过修剪树并删除所有不会导致实质性信息获取的决策来向后运行该过程。最终,我们得到了上面代码中相对较小的树。 决策树具有广泛的应用。它们可以产生优于神经网络或支持向量机的出色预测。但是它们并不是万能的解决方案,因为它们的分割平面始终平行于要素空间的轴。这在某种程度上限制了他们的预测。它们不仅可以用于分类,还可以用于回归,例如通过返回对树的某个分支有贡献的样本的百分比。Zorro的树是回归树。最著名的分类树算法是C5.0,可在C50软件包中找到R。 为了进一步改善预测效果或克服平行轴限制,可以使用称为随机森林的树丛。然后通过平均或投票来自单个树的预测来生成预测。 结论 您可以使用许多不同的数据挖掘和机器学习方法。关键问题:基于机器学习的策略会更好?毫无疑问,机器学习具有很多优势。您无需关心市场的微观结构,经济,交易者的心理。您可以专注于纯数学。机器学习是生成交易系统的一种更为优雅,更具吸引力的方式。尽管在交易论坛上有很多热情的话题,但它往往会在实时交易中神秘地失败。 每隔两周就会发布一篇有关使用机器学习方法进行交易的新论文(下面可以找到一些)。请对这些出版物保持谨慎的态度。根据一些论文,已经达到了70%,80%甚至85%的幻象赢率。尽管获胜率不是唯一的相关标准–即使获胜率很高,您也可能会亏损–预测交易的准确度通常为85%,高于五成的利润率。通过这样的系统,相关科学家应该同时是亿万富翁。不幸的是,我从来没有用所描述的方法来重现那些获胜率,甚至都没有接近。因此,结果可能会出现很多选择偏见。或者也许我太愚蠢了。 与基于模型的策略相比,到目前为止,我还没有看到很多成功的机器学习系统。从成功的对冲基金所听说的算法方法来看,机器学习似乎仍然很少使用。但是,随着更多处理能力的出现以及用于深度学习的新算法的出现,这种情况将来可能会改变。 本文来源:蜂鸟数据Trochil —- 编译者/作者:蜂鸟数据Trochil 玩币族申明:玩币族作为开放的资讯翻译/分享平台,所提供的所有资讯仅代表作者个人观点,与玩币族平台立场无关,且不构成任何投资理财建议。文章版权归原作者所有。 |
蜂鸟数据Trochil:机器学习的原理-构建更好的策略4
2020-06-30 蜂鸟数据Trochil 来源:火星财经
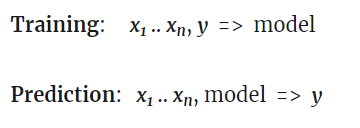

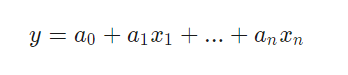


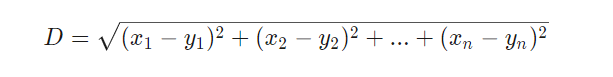
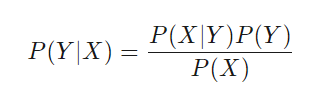

LOADING...
相关阅读:
- 蜂巢区块链获得知识产权证书以及多项计算机软件著作权登记证书2020-08-04
- 三分钟读懂Allocate Dividend技术构架之拜占庭容错算法(PBFT)2020-08-04
- 金銘玥:8.4比特币新手交易如何看盘以及读懂K线2020-08-04
- Gate.io区块链新闻一分钟2020.08.032020-08-04
- 过去四个月勒索软件 NetWalker 获得 2795 枚比特币2020-08-04