Swarm是以太坊上最新的项目之一,可能是整个去中心化生态系统的核心部分。据以太坊官网介绍,Swarm是一个不受审查、不受许可、分散的存储和通信基础设施。 炬象矿池通过长时间的研究与实践。已经掌握了Swarm的整体技术结构。其技术实现难度高于市场上其他的矿机与节点,因此也能实现更大的应用层。 今天,炬象矿池整理出了关于Swarm的技术架构框架概述,让大家能更深层的了解Swarm。 Swarm的主要目的是成为dApp代码、用户数据、区块链数据和状态数据的去中心化存储。 Swarm开始为Web 3.0提供各种底层服务。服务包括节点到节点的消息传递、媒体流、分散的数据库服务和用于分散服务经济的可伸缩的状态通道基础设施。 1、关于Swarm的介绍 在我深入研究Swarm的技术结构之前,我应该先定义数据是如何存储在这个分散的文件存储系统中的。
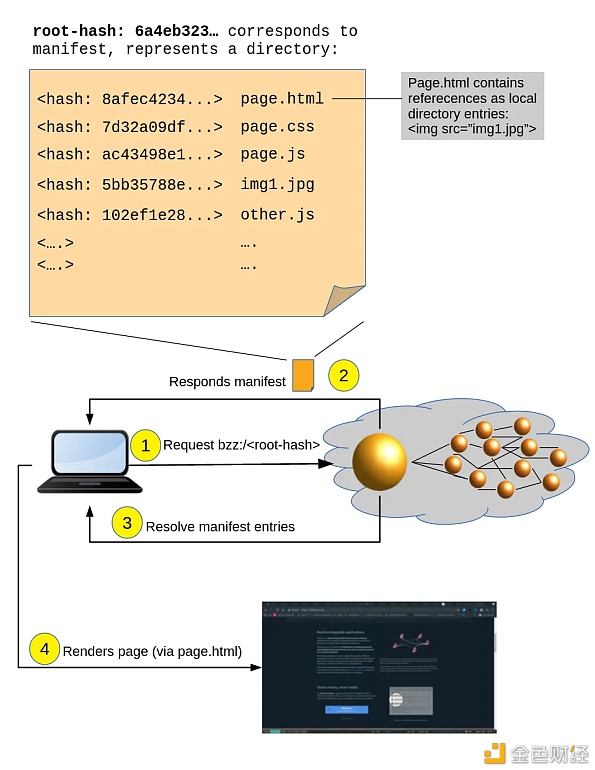
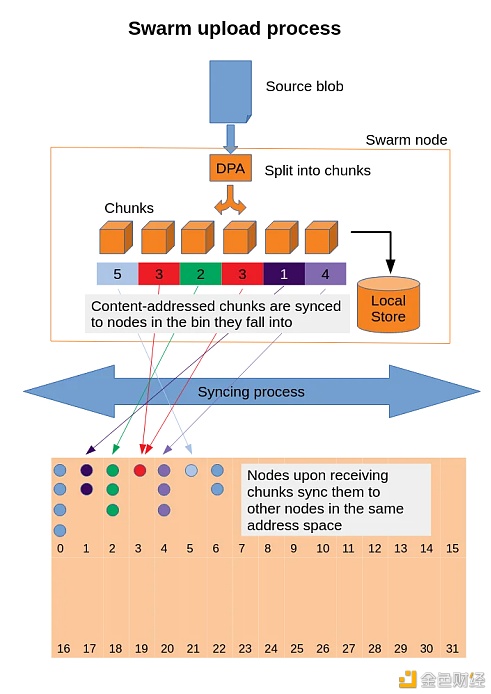
一个请求是如何在Swarm中呈现?Swarm的底层基础设施通过允许每个服务互相贡献资源来提供上述服务。 这些贡献在点对点的基础上被准确地计算出来,允许节点以资源交换资源,同时向消耗少于服务的节点提供货币补偿。 Swarm正在使用以太坊等现有的智能合约平台来实施其激励模式。 Swarm去中心化存储系统主要由三个部分组成: 块:这些是有限大小的数据块(最大4K),在Swarm中充当存储和检索的基本单元。块被链接到地址。 引用:这是文件的唯一标识符,允许客户端检索和访问内容。 Manifest:这是描述文件集合的数据结构。它指定路径和相应的内容散列,允许基于url的内容检索。 上图显示了一个请求是如何通过Swarm呈现的。块由像page.html或page.css这样的散列信息表示。 每个块包含Manifest中的一个引用,告诉请求者如何检索和呈现信息。 接下来,让我们看看Swarm的架构以及数据是如何上传和写入到不同节点的。 Swarm的堆栈和架构 2.?? Swarm如何存储每条数据 下图显示了上传过程是如何进行的,以及信息是如何以分散方式存储的
Swarm节点接收到一个blob后,它会将该blob分割成较小的、相等的数据块,然后将该数据块分布到不同的节点中,这些节点会根据每个数据块的时间戳自动同步数据。 DPA或分布式预映像归档将选择哪些节点存储哪些块。 最后,每个bin(0,1,…,31)显示了相同地址空间上的节点如何存储相关的块。
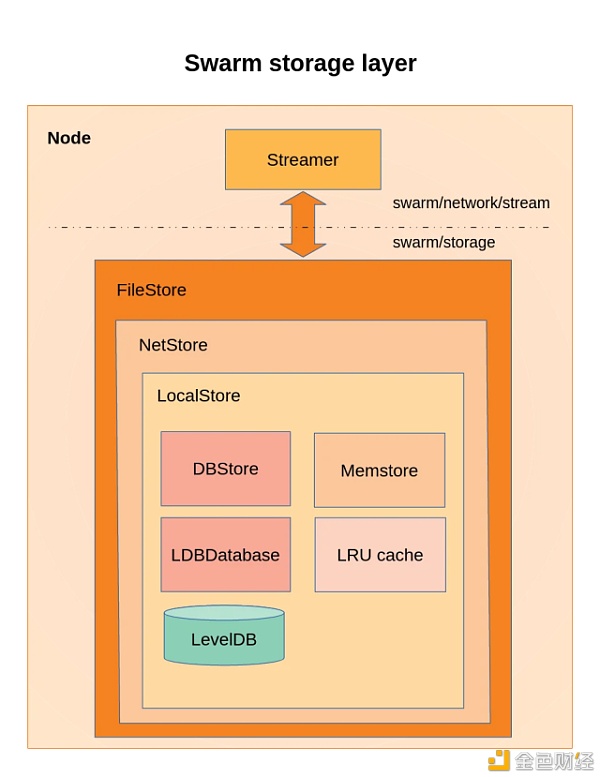
3.Swarm的存储层概述 Swarm的实际存储层由两个主要组件组成:LocalStore和NetStore。LocalStore由内存中快速缓存(Memstore)和持久磁盘存储(DBStore)组成。NetStore将LocalStore扩展为Swarm的分布式存储,并实现了DPA。 FileStore是存储和检索文件的本地接口。当文件被交给FileStore进行存储时,它将文档分割成一个Merkle散列树,并将其根密钥返回给调用者。这个键稍后可用于检索相关文档的部分或全部。 最后,FileStore使用Swarm散列,并使用NetStore为用户检索文档的根块。 4.?? Swarm概述 从终端用户的角度来看,Swarm不会影响导航或行为。 在后台,不同之处在于内容托管在对等存储网络上,而不是单独的服务器上。由于内置的激励机制,这种点对点网络能够自我维持。只有使用公共区块链,允许交易资源支付,激励才有可能。 Swarm旨在与以太坊的DevP2P多协议网络层以及以太坊区块链进行深度集成,用于域名解析(ENS)、服务支付和内容可用性保险。 5.Swarm vs IPFS vs Filecoin 最后,我想强调一下Swarm和其他分布式文件存储(如IPFS和Filecoin)之间的关键区别: Swarm的核心存储组件是一个不可变的内容地址,而不是一个通用DHT (IPFS使用DHT)。 Swarm、Filecoin和IPFS使用不同的网络通信层和对等管理协议。 Swarm与以太坊区块链深度集成,激励系统既受益于智能合约,也受益于半稳定的对等池。Filecoin使用可检索性证明作为挖掘的一部分。IPFS没有内在的激励机制。 —- 编译者/作者:炬象矿池 玩币族申明:玩币族作为开放的资讯翻译/分享平台,所提供的所有资讯仅代表作者个人观点,与玩币族平台立场无关,且不构成任何投资理财建议。文章版权归原作者所有。 |
十分钟看懂SWARM的技术架构
2021-05-28 炬象矿池 来源:区块链网络
LOADING...
相关阅读:
- Champion致力于打造全民治理生态,代币CAP即将上线JustSwap交易所2021-05-28
- ?错过了filchia挖矿这次swarm还能错过2021-05-28
- 一文详解ArbitrumRollup如何工作2021-05-28
- 逸戈谈币:5.28行情分析上行再度受阻回踩趋势转空毋庸置疑请顺势操作2021-05-28
- WisdomTree File Ethereum ETF应用| 加密宪报2021-05-28