


原文作者:Eric?Zhang 翻译者:Yofu@DAOrayaki.org 审核者:DAOctor?@DAOrayaki.org 原文:Web3 Collaborative Intelligence – Knowledge Trees, Knowledge Forest, and Community Contributions 特别感谢 Zeo、DAOctor、Zhengyu、Christina 的贡献、审阅和反馈。 构建知识结构数据库和更好地可视化知识是推进计算机科学、人工智能和Web的重要任务。在加密货币和去中心化应用世界出现之前,旧的 Web 3.0 研究主要集中在构建知识库和知识图谱,以及基于这些结构的表示/推理(语义Web)。 建立知识库有两种通用方法。一种方法是从 Web 以及其他数据源获取数据,然后将它们组织到所需的知识数据库中(主要是“三元组”或“图”的巨大集合,然后执行“高阶逻辑”或机器学习推理结构和其他智能任务的技术)。另一种方法是依靠人类智能来协作建立数据库(例如,我们将在后面更详细讨论的 Wikipedia、ConceptNet 或 Citizen Science 项目)。 本文将首先回顾过去几十年的一些相关创新,然后讨论我们如何才能向前迈进,建立一个具有集体智慧和可持续激励机制的高水平知识数据库。 知识库、知识图谱和维基百科很长一段时间以来,人们对创建知识图谱很感兴趣,主要有两个原因: 连接人类创造的所有信息和知识的点,并且在知识图谱上执行推理和机器学习技术以产生更好的人工智能,并使用该系统改善 Web2 产品的用户体验。现在,很明显有用的知识图谱大多是作为 Web2 中大型公司的基础工具创建的。例如,Facebook 知识图谱有助于更好的社交网络搜索,谷歌知识图谱有助于呈现相关信息。由于一切都是闭源的,我们不知道知识图谱是如何构建的,但从 UI 来看,这些知识图谱肯定有助于改善用户体验。 维基百科社区的努力是惊人的。这是展示互联网社区力量的首次尝试之一。另一方面,开放数据库可作为互联网公共产品使用。一个例子是 DBpedia,它是一个为想要利用 Wikipedia 知识库的应用程序提供 API 的数据库。另一个例子是 ConceptNet,这是一个免费提供的语义网络,可帮助 AI 和 NLP 程序获取通用语义。 然而,这些互联网公益组织能做多少,有一些根本性的限制。维基百科每年都依赖捐赠,它在一个 501(c)3 组织内运作,很难在其上施加更先进的激励机制并基于知识网络构建更酷的基础设施。DBpedia 和 ConceptNet 等也是如此。作为非营利组织,这些公益组织很难深入建立一个不断构建基础设施并最终形成生态系统的社区。我在大学时使用 DBpedia 的 API 构建了一个 Wikipedia 图形可视化和搜索工具。然而,当时加入一个充满活力的社区要困难得多。现在在加密社区,情况大不相同了,有好主意的开发者可以参与更多的活动,组队并得到多链生态系统的支持。 但是,我不建议建立另一个 Wikipedia(又名 DAO-ify Wikipedia,或“Web3 Wikipedia”),因为尽管当前的非营利组织模式存在局限性,但 Wikipedia 网站的内容和结构都得到了很好的策划和组织,人们已经在很大程度上受益于它的成果。总的来说,Wikipedia 擅长存储知识的描述,并且通过 Web1 和 Web2 基础设施,我们已经使知识可搜索。维基百科和现有的网络基础设施不擅长的是呈现“人类理解”的知识——人脑中的结构性知识。为了呈现这些信息,人的策展和人的协作是核心,这在 Web1/Web2 基础设施中并不能很好地支持,但是通过 Web3 基础设施和协调机制将可以实现 **值得注意的是,人们努力建立海量结构数据库以增强机器对知识的理解。例如,像 Cyc 这样的公司几十年来一直在尝试建立一个常识知识库来帮助机器模仿人类的大脑。这些公司最终将自己变成了商业软件公司,因为强大的人工智能显然需要的不仅仅是节点和关系的知识库。与为机器建立结构性知识库相比,人类对知识的理解和人类管理在这里很重要——建立人类理解的知识库以帮助更多的人理解。 另一方面,值得思考的是,如何将更高层次的语义添加到当前的 Web of Knowledge 中,也就是我们在本文中描述的结构性知识。 公民科学和志愿计算我想提到的另一个探索分支是公民科学和志愿计算。在 2010 年代初期,科学界有许多令人兴奋的项目,它们利用人群的智慧来加速研究和科学发现的进展。这种努力一般有两种类型。第一种称为志愿计算,它将计算任务分配给一群个人计算设备(例如 LHC@Home、SETI@Home)。第二种类型称为公民科学,它创造了每个人都可以执行的重复性任务(这里不是一个贬义词!)。该项目从众多贡献者那里收集数据(有时是分析结果),并将它们输入到一些研究项目中以创建有意义的结果(例如,在 Citizen Cyberlab、SciStarter 或机器学习社区中列出的项目,标记图片以丰富训练数据可以是众包)。在不发明“DAO”这个词的情况下将这些努力想象成“DAO”,去中心化社区的协调方面并不是什么新鲜事! 许多项目取得了成功,但不幸的是,这些项目的可持续性再次受到限制。SETI@Home 不再运营,许多公民科学项目本可以持续更长时间但没有持续下去。激励和生态系统对任何协作努力来说都是很重要的两个方面。没有生态系统,创新就会受到限制。没有可持续的激励机制,就没有充满活力的社区,也就永远不会出现生态系统。 复杂概念和知识的结构现在让我们考虑一下高级概念和知识是什么样的。从直觉上看,当我们“理解”某个概念时,实际上我们理解了这个概念的相当多的细节。我们可以通过两种方式来思考“理解”的过程: 1. 通过树状结构理解 当我们试图“理解”某事,或者说“学习”某事时,我们会将其分解为树形结构。例如,如果我们想理解“Merkle 树”这样的概念,就必须理解“密码哈希函数”和“树数据结构”这样的子概念,这就需要我们进一步理解“哈希函数”、“抗碰撞性”等这样的基本概念。 树分解得越深,概念就越原始。在某一时刻,Web 上会有一些非常直接的资源可以直接引用(例如,维基百科页面或一些文章/视频)。 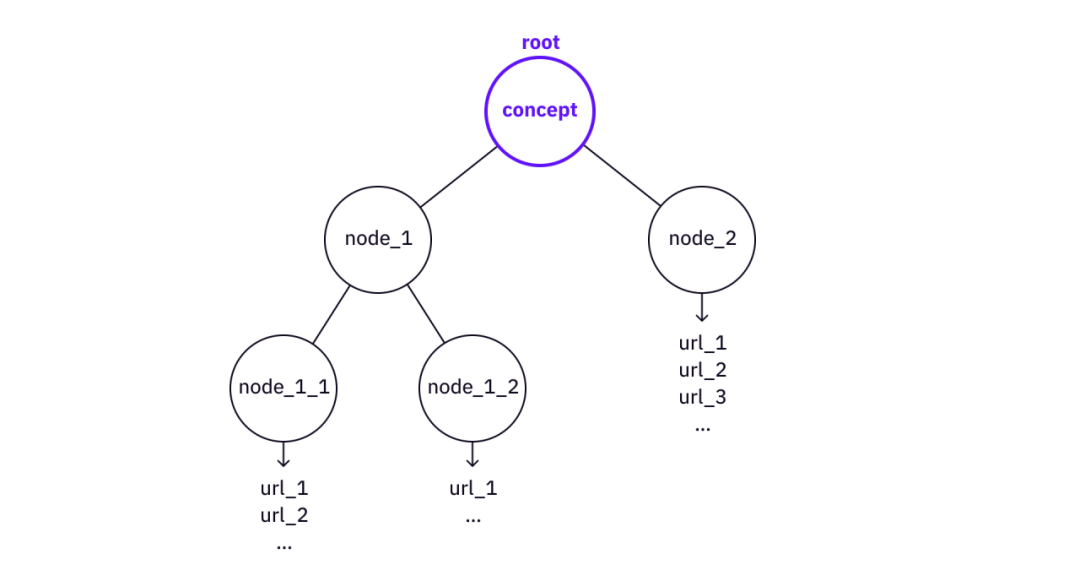 将概念“分解”为树形结构 我们可以从旧时的 AI 中找到一些类似的想法。K 线理论表明我们的记忆和知识存储在树结构中(P 节点和 K 节点)。虽然缺乏实际证据表明这种结构确实存在于我们的大脑中,但该模型具有解释人类记忆和人类大脑如何工作的能力,而树状结构确实是存储结构知识的最简洁形式。 我们可以使用树结构来存储和理解两个方向——分解和建立。 如果我们想检索细节,我们分解一个知识树。另一方面,如果我们有一个知识树,我们可以使用这棵树来构建更大的树(也就是知识和理解的更高抽象)。 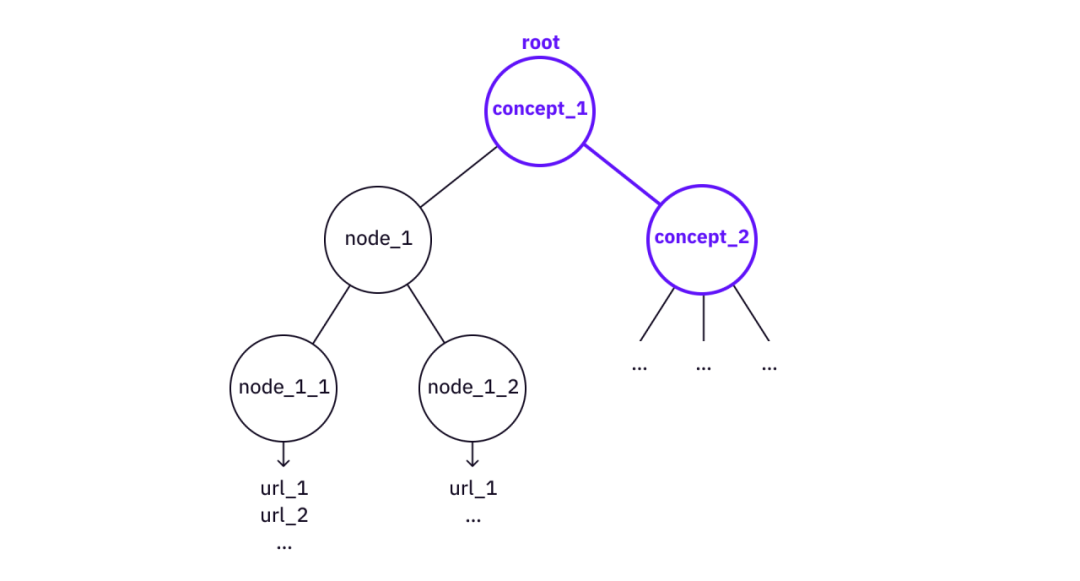 使用概念_2“建立”概念_1 在“构建”的情况下,可以使用“Merkle 树”树作为节点来构建更复杂的知识树,例如“Verkle 树”或“Merkle 多重证明”。 值得注意的是,这里的关键点是树的结构。知识树从根概念到叶子,指向所有对现有 Web 资源的必要引用。节点之间的关系在这里并不重要(与知识图谱系统中的“三重”思想不同)。 2.通过“相关知识”理解 我们还通过添加更多“上下文”来获得对知识的更深入理解。正如Weigenstain的名言,“但‘五’这个词是什么意思?这里没有这样的问题,只有“五”这个词是如何使用的”。它背后的想法是,某事物的意义实际上取决于与之相关的其他概念,它们共同决定某事物的意义。通过添加更多上下文(也就是知识本身的相关知识),我们可以更“深入”地理解知识。 一般来说,人们更容易理解树,而不是图。与其构建知识图谱,不如把“相关知识”想成更实用的方式——一组根节点相连的知识树,本质上形成了一个知识森林。 知识森林可以构建为许多知识树的数据库(并行种植)。我们可以对数据库执行两种基本操作。 在不同的树之间建立联系。当我们可视化知识树时,它将很有用。知识树的特征可以构造为某个向量空间中的向量。然后可以使用向量来关联在概念上相关但不通过 (1) 直接链接的知识树。 测量知识树之间的关系 关于理解的深度一般来说,人们对同一个概念有不同程度的理解。对于一些人来说,Merkle树的概念很简单,不需要进一步分解(他们的大脑已经将这个概念封装成一些常识),而另一些人没有足够的信息来理解“Merkle树”的概念,可能需要一个进一步细分。 因此,知识树不必相互排斥,这意味着不同树之间可能存在重叠。可能有解释基本概念的树,以及为高级概念构建的树。 重叠可能会在树之间产生冗余。为了减少冗余,我们可以引入以下操作: 跨树引用(虚线链接) - 创建一个链接,将节点从一棵树连接到另一棵树的根。合并 - 两棵树的节点下可能已经有子树,如果基本树还没有覆盖到一些有价值的节点、叶子和参考,那么可能值得将来自更高级树的信息合并到更基本的树。 跨树参考链接 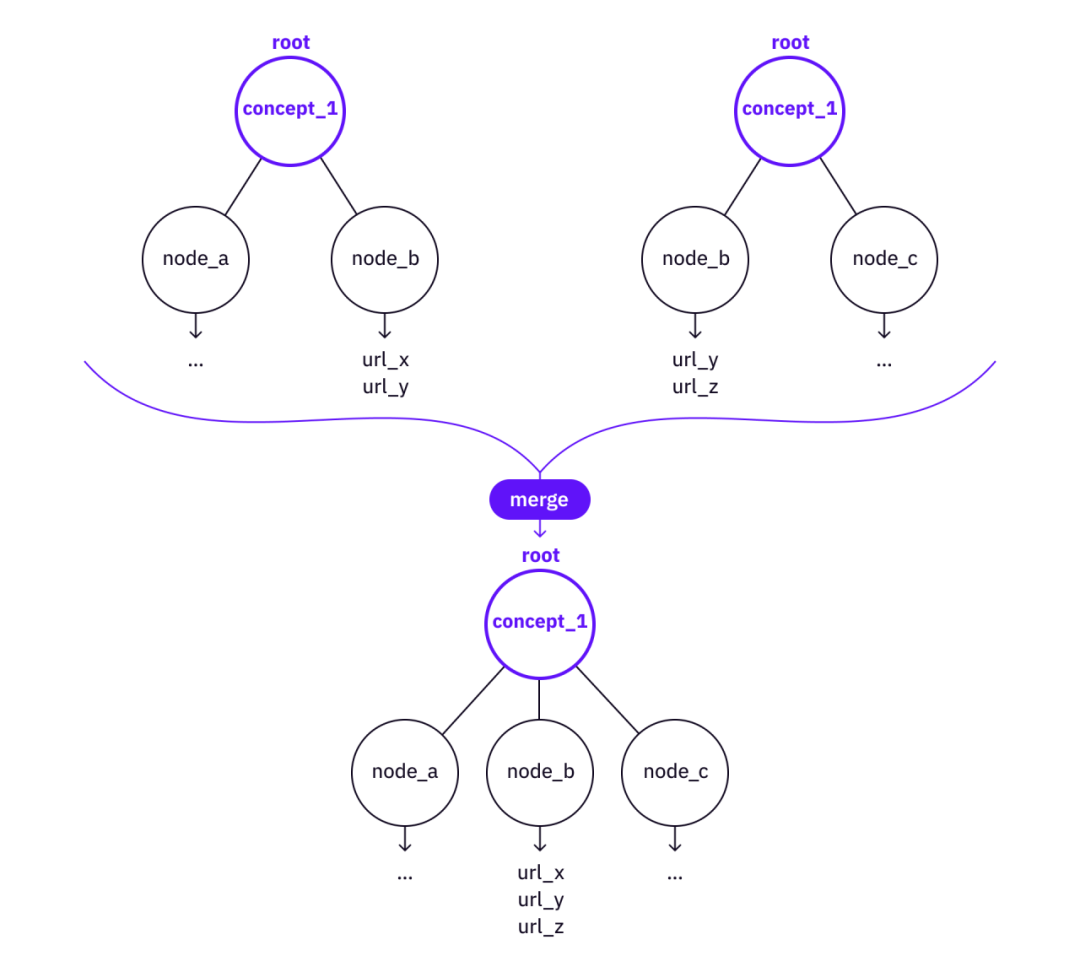 将两棵树合并为一棵 知识树和元操作单个知识树由一个根、一组子节点和一组叶子组成,组织成一个树结构。然后我们可以定义一组基本操作来创建和细化一棵树。 创建根(树)添加子节点向节点添加叶子将参考链接添加到叶子然后我们可以为实际用户定义一系列高级操作来“种植”一棵树并为一棵树做出贡献。 添加子树 - 为具有完整节点和叶子的知识树引入必要的子节点合并两个相同概念的树知识森林种下大量的知识树,我们就有了知识森林! 知识森林是一大群一起种植的知识树。关于知识森林的一个有趣事实是,树木之间可能存在纠缠。理论上,不同节点和叶子之间的连接可以是任意的(例如,一棵树的叶子和另一棵树的根之间的链接)。实际上,如果我们添加虚线链接,知识森林“有点”就变成了知识图谱。但是,重要的是个人知识树。 例如,虚线表示 MACI 树和 zk-Snark 树之间的链接。 知识树的叶子连接到网络上现有的文章/视频/资源。因此,这些叶子之上的层是结构信息或理解层。 我们可以用知识森林做的事情是完全开放的。我们应该考虑的最重要的事情可能是从一开始就协作知识库的生态系统。我们可能想要对知识森林做很多事情,这里举三个例子: 可视化知识树和知识森林通过虚线链接浏览知识森林查找知识树集群建立一个 DAO,而不是一个非营利组织非营利组织可以让事情发生,但 DAO 可以让事情变得更好。这里的想法是将一组树操作映射到一组激励。元操作越标准化,DAO 协调其成员的可扩展性就越高。  知识树操作 <-> DAO 贡献 在知识树的情况下,DAO 的贡献者可以创建一个根(等于“创建/种植一棵树”),添加一个知识路径(“养植树”),并为树叶添加参考链接。激励机制创建了一套规则来奖励那些采取可验证的行动来规划和种植知识树的社区贡献者。 同时,审查委员会(或审查团体)对于规划和质量控制也很重要。DAO 的协调和激励已经过广泛的试验(例如,DAOrayaki DAO),并且可以在这里实现类似的结构。 知识森林与知识图谱当我们学习新概念并获得知识时,树更容易理解。对于任何特定的主题,人类很容易理解树中的知识结构,因为树中没有循环,如果将树的深度限制在一定水平,对人脑来说进行处理和记忆就容易多了。 此外,知识图的表示在表示知识节点之间的模糊或模糊连接方面受到了限制(与常识知识表示相同的问题)。 这并不意味着知识树总是比知识图更好。在讲故事方面,知识图比知识树(例如,所有希腊神话的图)更有用。实际上有很多现有的工具(1 2)来构建知识图谱,但令我惊讶的是,它们中的大多数正在成为 SaaS 公司。 一个致力于知识树和知识森林的实际实现的 BUIDLers 团队有很多细节——数据结构、产品设计、贡献和激励细节、UI 等等。尽管如此,如果要建立一个知识森林,我觉得总的来说它应该作为一种公共产品来组织知识并向世界上的所有人开放。但是,让我们看看 Dora 社区想出了什么! 结论这个想法是在现有的 Web 基础设施(如维基百科等)之上建立一种新的知识库,并使其可供所有人使用,从而最大限度地降低理解抽象知识的复杂性(通过像Web或维基百科这样的知识图进行路由可以复杂到O(nlog(n)),但是有n个节点的树只有log(n)的深度,这使得导航更容易)。与 DAO 中的贡献者协调,并使用先进的加密原生激励措施来确保组织的可持续性。本文中的想法并不完整,还有很多讨论和改进的空间,如果某个团队想要将其变为现实,还有很多工程和产品问题需要考虑。 参考文献语义Web:https://en.wikipedia.org/wiki/Semantic_Web三元组:https://conceptnet.io/高阶逻辑:https://en.wikipedia.org/wiki/CycConceptNet:https://conceptnet.io/DBpedia:https://www.dbpedia.org/Wikipedia 图形可视化和搜索工具:https://github.com/zhangjiannan/Graphpedia多链生态系统:https://hackerlink.io/grant/dora-factory/topCyc:https://en.wikipedia.org/wiki/Cyc志愿计算:https://en.wikipedia.org/wiki/Volunteer_computingLHC@Home:https://lhcathome.cern.ch/lhcathome/SETI@Home:https://setiathome.berkeley.edu/Citizen Cyberlab:https://www.citizencyberlab.org/projects/SciStarter:https://scistarter.org/知识图谱构建工具1:https://obsidian.md/知识图谱构建工具2:https://www.ideaflow.io/DAOrayaki DAO研究奖金池:资助地址:DAOrayaki.eth 投票进展:DAO Committee 2/0?通 过 赏金总量:130USDC 研究种类:Web3, Knowledge Trees,?Knowledge Forest,Community Contributions —- 编译者/作者:DAOrayaki 玩币族申明:玩币族作为开放的资讯翻译/分享平台,所提供的所有资讯仅代表作者个人观点,与玩币族平台立场无关,且不构成任何投资理财建议。文章版权归原作者所有。 |
如何利用DAO建立一个具有集体智慧和可持续激励机制的知识数据库
2022-03-01 DAOrayaki 来源:区块链网络
相关阅读:
- Domani DAO发布Avalanche蓝筹指数基金2022-03-01
- 在文科生眼里Web3是怎么样的?2022-03-01
- 深度探讨DAO的协作方式:如何引导与激励人们为DAO工作?2022-02-28
- 数字隐私平台HOPR获超100万美元web3生态系统捐赠2022-02-28
- ADAMoracle预言机即将开启DAO治理打造全球化协作网络2022-02-28

