原文来源:新智元  图片来源:由无界 AI? 生成 一夜之间,全新开源模型「OpenLLM」击败ChatGPT的消息,在网上引起轩然大波。 根据官方的介绍,OpenLLM: - 在斯坦福AlpacaEval上,以80.9%的胜率位列开源模型第一 - 在Vicuna GPT-4评测中,性能则达到了ChatGPT的105.7% 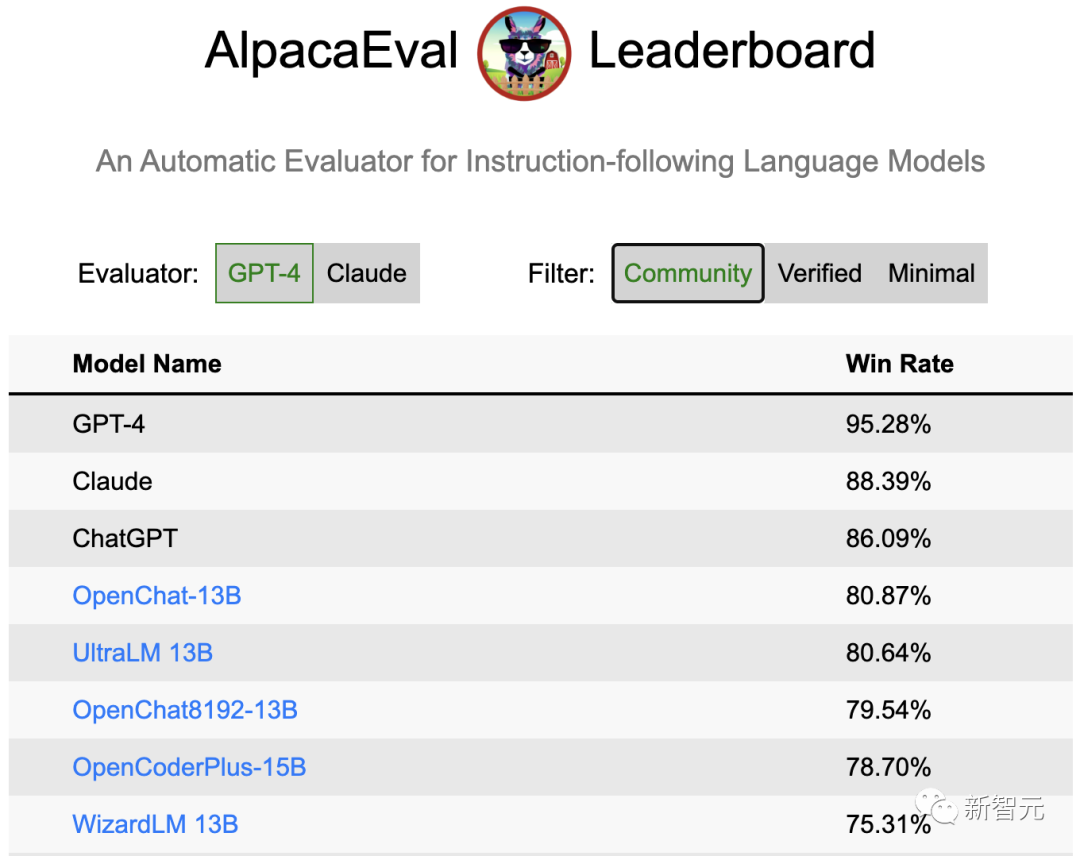 最重要的是,如此卓越的性能,只需要6K的GPT-4对话数据进行微调训练。  项目地址:https://github.com/imoneoi/openchat 不过Chatbot Arena的「榜单主」提醒称,由于旧的Vicu?a eval基准存在一些bias,因此提倡大家迁移到新提出的MT-bench上——从而更好地测评LLM更多方面的能力。  OpenLLM:只需6K GPT-4对话微调 OpenLLM:只需6K GPT-4对话微调OpenLLM是一个在多样化且高质量的多轮对话数据集上进行微调的开源语言模型系列。 具体来讲,研究人员从约90K的ShareGPT对话中,过滤出来约6K的GPT-4对话。 经过6k数据微调后,令人惊讶的是,OpenLLM已经被证明可以在有限的数据下实现高性能。 OpenLLM有两个通用模型,它们是OpenChat和OpenChat-8192。  OpenChat:基于LLaMA-13B微调,上下文长度为2048 - 在Vicuna GPT-4评估中达到ChatGPT分数的105.7% - 在AlpacaEval上取得了惊人的80.9%的胜率 OpenChat-8192:基于LLaMA-13B微调,上下文长度为8192 - 在Vicuna GPT-4评估中达到ChatGPT分数的106.6% - 在AlpacaEval上取得的79.5%胜率  此外,OpenLLM还有代码模型,其性能如下: OpenCoderPlus:基于StarCoderPlus,原始上下文长度为8192 - 在Vicuna GPT-4评估中达到ChatGPT分数的102.5% - 在AlpacaEval上获得78.7%的胜率 模型评估研究人员使用Vicuna GPT-4和AlpacaEval基准评估了最新模型,结果如下图所示: 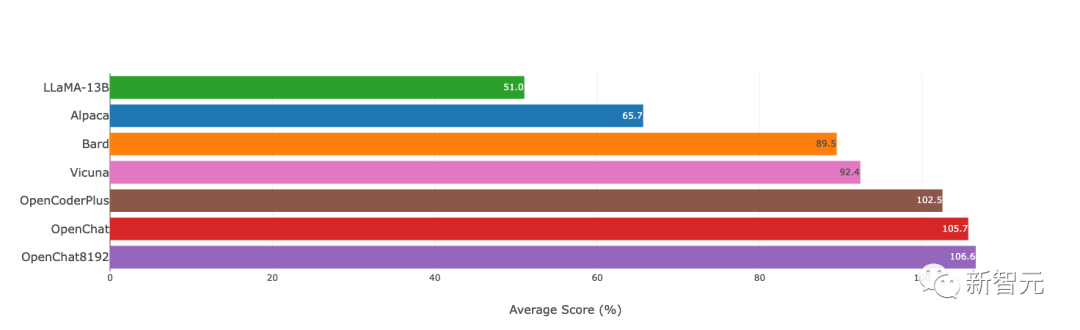 Vicuna GPT-4评估(v.s. gpt-3.5-turbo) 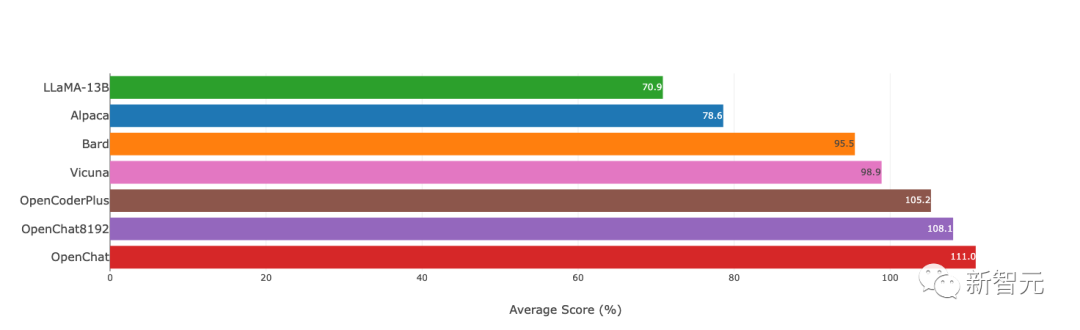 Vicuna GPT-3.5-Turbo评估(v.s. gpt-3.5-turbo) 另外,值得注意的是,研究者采用的评估模式与Vicuna的略有不同,还使用了证据校准(EC)+平衡位置校准(BPC)来减少潜在的偏差。 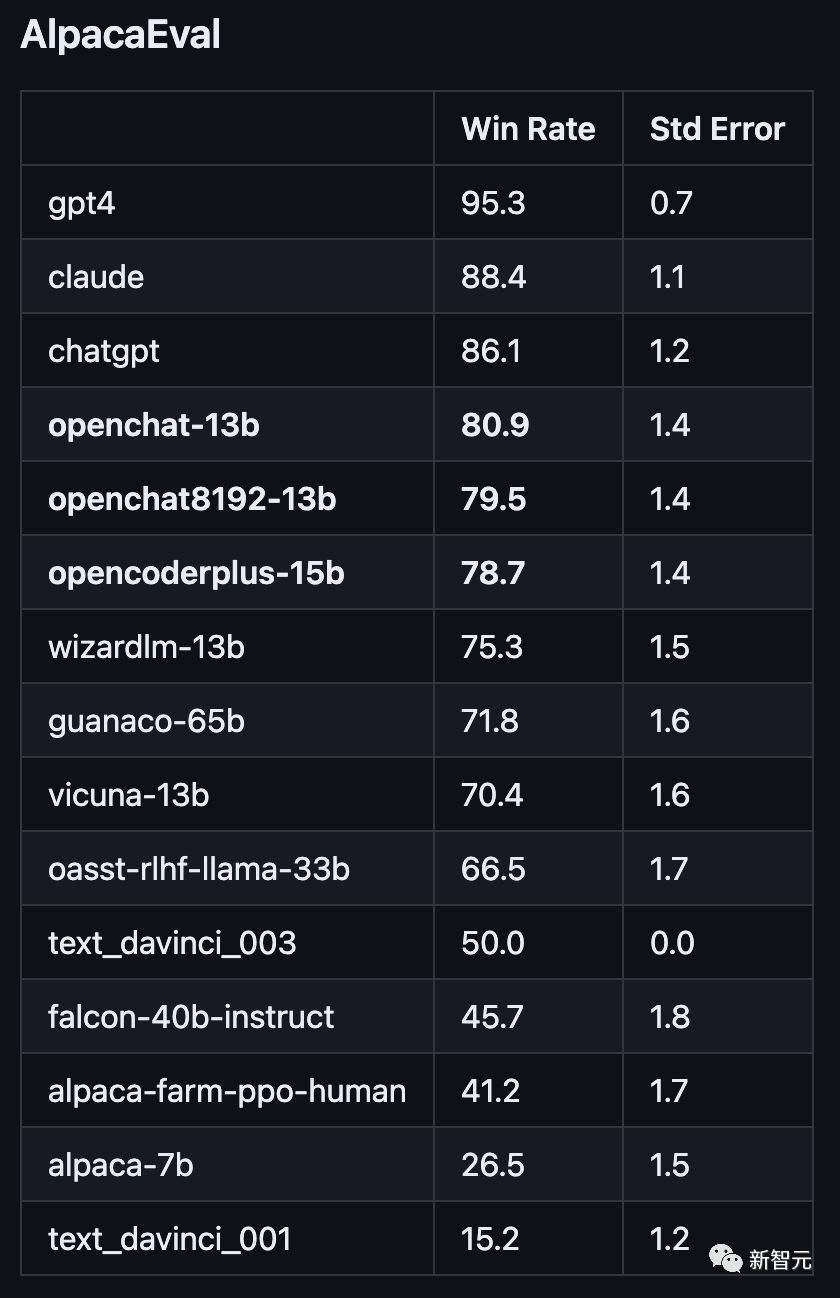 安装和权重 安装和权重要使用OpenLLM,需要安装CUDA和PyTorch。用户可以克隆这个资源库,并通过pip安装这些依赖: git clone [email protected]:imoneoi/OChat.gitpip install -r requirements.txt 目前,研究人员已经提供了所有模型的完整权重作为huggingface存储库。 用户可以使用以下命令在本地启动一个API服务器,地址为http://localhost:18888。 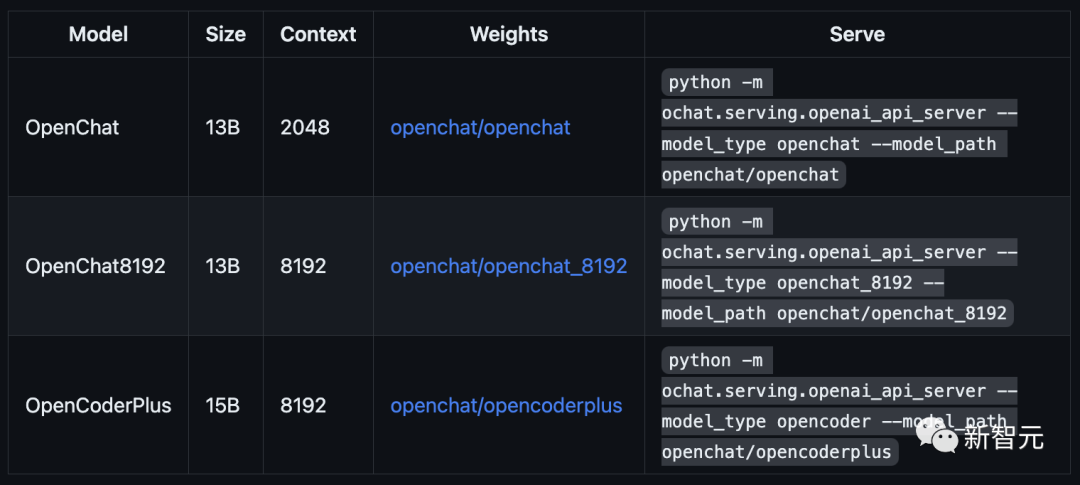 其中,服务器与openai包,以及ChatCompletions协议兼容(请注意,某些功能可能不完全支持)。 用户可以通过设置以下方式指定openai包的服务器: openai.api_base = "http://localhost:18888/v1" 当前支持的ChatCompletions参数有: 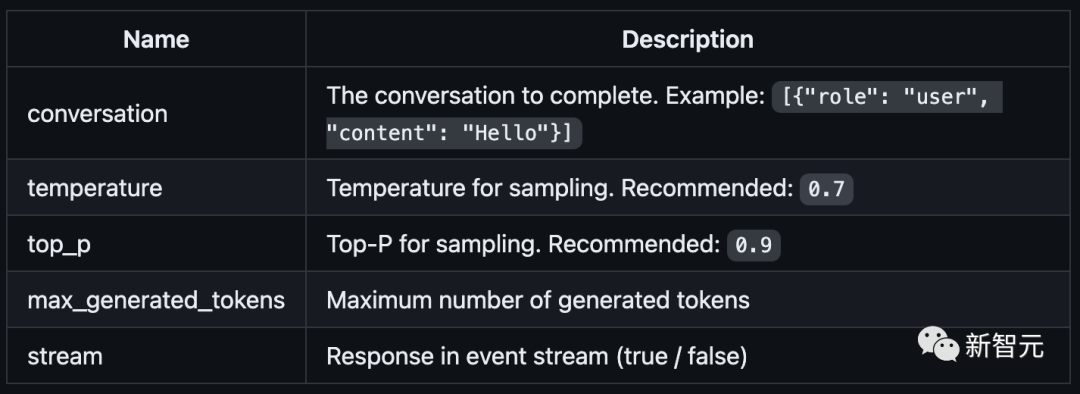 建议:使用至少40GB(1x A100)显存的GPU来运行服务器。 数据集转换后的数据集可在openchat_sharegpt4_dataset上获取。 项目中所使用的数据集,是对ShareGPT清洗和筛选后的版本。 其中,原始的ShareGPT数据集包含大约90,000个对话,而仅有6,000个经过清理的GPT-4对话被保留用于微调。 清洗后的GPT-4对话与对话模板和回合结束时的token相结合,然后根据模型的上下文限制进行截断(超出限制的内容将被丢弃)。 要运行数据处理流程,请执行以下命令: ./ochat/data/run_data_pipeline.sh INPUT_FOLDER OUTPUT_FOLDER 输入文件夹应包含一个ShareGPT文件夹,其中包含每个ShareGPT对话页面的.html文件。 数据处理流程包括三个步骤: - 清洗:对HTML进行清理并转换为Markdown格式,删除格式错误的对话,删除包含被屏蔽词汇的对话,并进行基于哈希的精确去重处理 - 筛选:仅保留token为Model: GPT-4的对话 - 转换:为了模型的微调,针对所有的对话进行转换和分词处理 最终转换后的数据集遵循以下格式: MODEL_TYPE.train.json / .eval.json [ [token_id_list, supervise_mask_list],[token_id_list, supervise_mask_list],... ] MODEL_TYPE.train.text.json / .eval.text.json从token_id_list解码的纯文本 除此之外,研究人员还提供了一个用于可视化对话嵌入的工具。 只需用浏览器打开ochat/visualization/ui/visualizer.html,并将MODEL_TYPE.visualizer.json拖放到网页中。点击3D图中的点,就可以显示相应的对话。 其中,嵌入是使用openai_embeddings.py创建的,然后使用dim_reduction.ipynb进行UMAP降维和K-Means着色。  模型修改 模型修改研究人员为每个基础模型添加了一个EOT(对话结束)token。 对于LLaMA模型,EOT的嵌入初始化为所有现有token嵌入的平均值。对于StarCoder模型,EOT的嵌入以0.02标准差进行随机初始化。 对于具有8192上下文的LLaMA-based模型,max_position_embeddings被设置为8192,并且进行了RoPE(相对位置编码)代码的外推。 训练训练模型时使用的超参数在所有模型中都是相同的:  使用8xA100 80GB进行训练: NUM_GPUS=8deepspeed --num_gpus=$NUM_GPUS --module ochat.training_deepspeed.train \--model_type MODEL_TYPE \--model_path BASE_MODEL_PATH \--save_path TARGET_FOLDER \--length_grouping \--epochs 5 \--data_path DATASET_PATH \--deepspeed \--deepspeed_config ochat/training_deepspeed/deepspeed_config.json 评估 要运行Vicuna GPT-4评估,请执行以下步骤: 1. 生成模型答案 python -m ochat.evaluation.get_model_answer --model_type MODEL_TYPE --models_path PATH_CONTAINING_ALL_MODELS_SAME_TYPE --data_path ./ochat/evaluation/vicuna --output_path ./eval_results 2. 生成基线(GPT-3.5)答案 OPENAI_API_KEY=sk-XXX python -m ochat.evaluation.get_openai_answer --data_path ./ochat/evaluation/vicuna --output_path ./eval_baselines --model_types gpt-3.5-turbo 3. 运行GPT-4评估 OPENAI_API_KEY=sk-XXX python -m ochat.evaluation.openai_eval --data_path ./ochat/evaluation/vicuna --baseline_path ./eval_baselines/vicuna_gpt-3.5-turbo.jsonl --input_path ./eval_results 4. 可视化和细节 要获得可视化和绘制评估结果,请使用浏览器打开ochat/visualization/eval_result_ui/eval_result_visualizer.html,并选择./eval_results/eval_result_YYYYMMDD文件夹中的所有文件以显示结果。 局限性基础模型限制 尽管能够实现优秀的性能,但OpenLLM仍然受到其基础模型固有限制的限制。这些限制可能会影响模型在以下领域的性能: - 复杂推理 - 数学和算术任务 - 编程和编码挑战 不存在信息的幻觉 OpenLLM有时可能会产生不存在或不准确的信息,也称为「幻觉」。用户应该意识到这种可能性,并验证从模型中获得的任何关键信息。 参考资料: https://github.com/imoneoi/openchat https://tatsu-lab.github.io/alpaca_eval/ —- 编译者/作者:AI之势 玩币族申明:玩币族作为开放的资讯翻译/分享平台,所提供的所有资讯仅代表作者个人观点,与玩币族平台立场无关,且不构成任何投资理财建议。文章版权归原作者所有。 |
击败ChatGPT?OpenChat霸榜斯坦福AlpacaEval开源榜首,性能高达105.7%
2023-07-03 AI之势 来源:区块链网络
LOADING...
相关阅读:
- 人工智能来了,工作和管理方式需要做出哪些改变?2023-07-03
- ChatGPT 访问量或现负增长,市场担忧“人工智能泡沫”2023-07-03
- GPT上车只为人车交互?车企还在憋大招2023-07-03
- 深度报告|生成式AI的顶尖人才都在哪?2023-07-03
- 北京市经信局局长姜广智:北京将加强人工智能政策创新,加大场景开2023-07-02