


原创:SenseAI “自 OpenAI 今年四月份推出 GPT-4 以来,越来越多的模型开源,AI 信徒们的关注点也正在从模型转移到应用。Lightspeed 最新文章对 AI 模型的发展趋势进行了推演,提出未来的大模型将分为三类模型,并结构化给出模型层面的可能机会梳理。本期内容带给大家模型基础设施层包括 AI Ops 中间层的发展趋势与机会思考。“Sense 思考我们尝试基于文章内容,提出更多发散性的推演和深思,欢迎交流。 根据模型能力和成本,AI 模型将分为“大脑模型”、“挑战者模型”和“长尾模型”。长尾模型小而灵活,更适合训练针对细分领域的专家模型。叠加摩尔定律的周期性,未来算力封锁并不存在,大脑模型的应用场景很难通杀,市场很可能还是根据应用场景的空间大小和价值链分配规则,选择适合的模型。 模型侧的新兴系统机会:1)模型评估框架;2)运行和维护模型;3)增强系统。需要考虑的是中美不同市场、原本企业服务生态的差异性和资本偏好。 企业级 RAG(检索增强) 平台机会:模型复杂性和多样性带来的机会,1)操作工具:可观察性,安全性,合规性;2)数据:在差异化商业价值和提供整体社会价值间,技术将带来数据货币化的机会。 本篇正文共 2426 字,仔细阅读约 7 分钟 在过去的十年里,美国老牌基金 Lightspeed 一直在 AI/ML 领域与杰出的公司、他们建立的平台以及他们服务的客户合作,以更好地了解企业是如何思考 Gen-AI 的。具体来说, Lightspeed 研究了基础模型生态系统,并提出了如“最好的模型会有赢者通吃的动态吗?”和“企业的使用案例都默认调用 OpenAI 的 API,还是实际使用会更多样化?”等问题。这些答案将决定这个生态系统的未来增长方向,以及能源、人才和资金的流动方向。 01.模型生态系统分类根据我们的学习,我们相信 AI 中即将出现一场模型的寒武纪大爆发。开发者和企业会选择最适合“要完成的任务”的模型,尽管在探索阶段的使用可能看起来更为集中。企业采纳的可能路径是使用大型模型进行探索,随着他们对使用案例的了解逐渐增加,逐渐转移到生产时使用的较小的专用(调整+提炼)模型。下图概述了我们如何看待基础模型生态系统的演变。 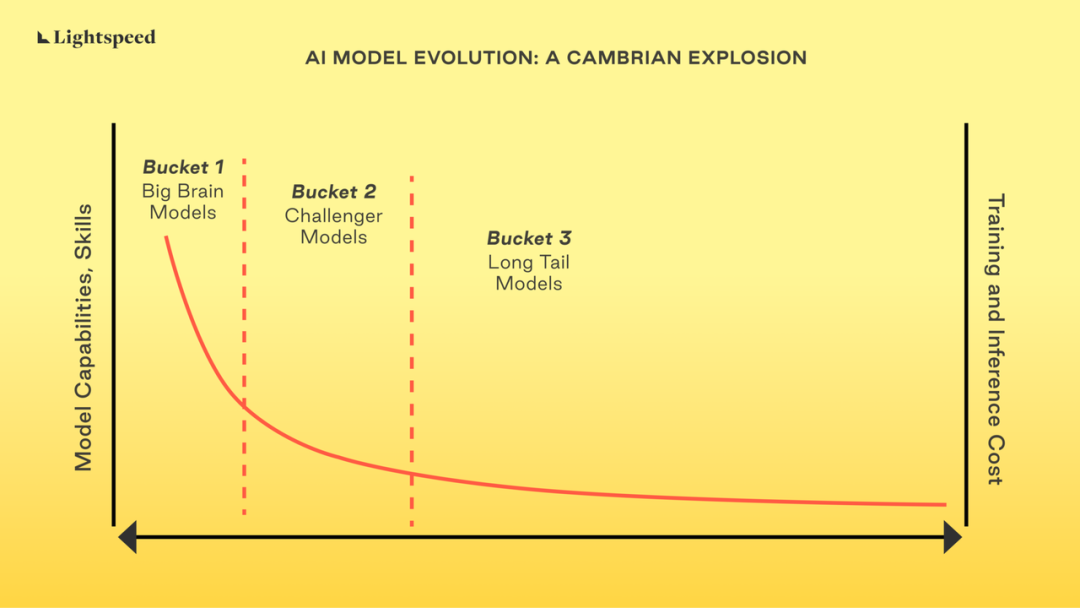 AI 模型版图可分为 3 个主要、可能会有重叠的类别: 类别一:“大脑”模型 这些是最好的模型,代表着模型的最前沿。这是那些令人兴奋的神奇演示的来源。开发者在尝试探索 AI 为他们的应用程序所能做到的极限时,通常首先考虑的是这些模型。这些模型的训练成本高,维护和扩展复杂。但是同一个模型可以参加 LSAT、MCAT、为您写高中论文,并作为聊天机器人与您互动。开发者目前正在这些模型上进行实验,并评估 AI 在企业应用程序中的使用。 但是,通用模型使用起来昂贵、且推理延迟高,并且对于定义明确的有约束的使用案例可能是过度的。第二个问题是这些模型是通才,可能在专业任务上不太准确。(可参考这篇 Cornell 的论文) 最后,在几乎所有情况下,它们也是黑盒子,对于正努力利用这些模型而不放弃其数据资产的企业来说,这可能会带来隐私和安全挑战。OpenAI、Anthropic、Cohere 是一些公司实例。 类别二:“挑战者”模型 这些也是高能力的模型,其技能和能力仅次于前面的通用大模型。Llama 2 和 Falcon 是这一类别中的最佳代表。它们通常与从训练通用模型的公司出来的 Gen“N-1” 或 “N-2” 模型一样好。例如,根据某些基准,Llama2 与 GPT-3.5-turbo 一样好。在企业数据上调整这些模型可以使它们在特定任务上与第一类通用大模型一样好。 其中许多模型是开源的(或接近),一旦发布,便立即带来了开源社区的改进和优化。 类别三:“长尾”模型 这些是“专家”模型。它们被建造用来为一个具体的目的服务,比如分类文档、识别图像或视频中的特定属性、识别业务数据中的模式等。这些模型灵活,训练和使用成本低,可以在数据中心或边缘运行。 简单浏览 Hugging Face 就足以了解这个生态系统现在和未来的庞大规模,因为它服务的使用案例范围非常广泛。 02.基础适配与实用案例尽管仍然处于早期阶段,但我们已经看到一些领先的开发团队和企业已经以这种细致的方式思考生态系统。人们希望将使用与最佳可能的模型相匹配。甚至使用多个模型来服务一个更复杂的使用案例。 评估哪个模型/模型用于使用的因素通常包括以下内容: 1. 数据隐私和合规性要求:这影响了模型是否需要在企业基础设施中运行,或者数据是否可以发送到外部托管的推理端点 2. 模型是否允许微调 3. 所需的推理“性能”级别(延迟、精度、费用等) 然而,实际上要考虑的因素往往比上面列出的要长得多,反映了开发者希望用 AI 实现的使用案例的巨大多样性。 03.机会在哪里?1. 模型评估框架:企业将需要获得工具和专业知识,以帮助评估针对哪种用例使用哪种模型。开发人员需要决定如何以最佳方式评估特定模型是否适合 "待完成的工作"。评估需要考虑多个因素,不仅包括模型的性能,还包括成本、可实施的控制水平等。 2. 运行和维护模型:帮助企业训练、微调和运行模型(尤其是第三类长尾模型)的平台将会出现。传统上,这些平台被广泛称为 ML Ops 平台,我们预计这一定义也将扩展到生成式人工智能。诸如 Databricks、Weights and Biases、Tecton 等平台都在迅速朝这个方向发展。 3. 增强系统:模型,尤其是托管的 LLM,需要检索增强生成以提供理想的结果。这就需要做出一系列辅助决策,包括 数据和元数据提取:如何连接到结构化和非结构化的企业数据源,然后提取数据以及访问策略等元数据。 数据生成和存储嵌入:使用哪种模型为数据生成嵌入。然后如何存储它们:使用哪种矢量数据库,特别是基于所需的性能、规模和功能? 现在有机会建立企业级 RAG 平台,从而消除选择和拼接这些平台的复杂性: 1. 操作工具: 企业 IT 将需要为工程团队建立防护栏、管理成本等;他们现在处理的所有软件开发任务现在都需要扩展到人工智能的使用。IT 部门感兴趣的方面包括 可观察性:模型在生产中的表现如何?它们的性能是否随着时间的推移而提高/降低?是否存在可能影响未来版本应用程序模型选择的使用模式? 安全性:如何保证人工智能本地应用程序的安全。这些应用程序是否容易受到需要新平台的新型攻击载体的攻击? 合规性:我们预计人工智能原生应用和 LLM 的使用将需要符合相关管理机构已经开始制定的框架。这是对现有的隐私、安全、消费者保护、公平等合规制度的补充。企业将需要能够帮助他们保持合规、进行审计、生成合规证明及相关任务的平台。 2. 数据: 帮助了解企业拥有的数据资产以及如何利用这些资产从新的人工智能模型中获取最大价值的平台将得到迅速采用。全球最大的软件公司之一曾对我们说过:"我们的数据是我们的护城河,是我们的核心知识产权,是我们的竞争优势。利用人工智能将这些数据货币化,并以一种 "在不削弱可防御性的情况下促进差异化 "的方式,将是关键所在。Snorkel 等平台在这方面发挥着至关重要的作用。 现在是构建人工智能基础设施平台的极好时机。人工智能的应用将继续改变整个行业,但它需要配套的基础设施、中间件、安全性、可观察性和操作平台,才能让地球上的每个企业都能采用这项强大的技术。 参考材料 https://lsvp.com/will-enterprise-ai-models-be-winner-take-all/ 作者:Vela,Yihao,Leo 编辑与排版:Zoey,Vela —- 编译者/作者:AIcore 玩币族申明:玩币族作为开放的资讯翻译/分享平台,所提供的所有资讯仅代表作者个人观点,与玩币族平台立场无关,且不构成任何投资理财建议。文章版权归原作者所有。 |
光速美国:AI基础设施层的未来在哪
2023-08-30 AIcore 来源:区块链网络
- 上一篇:谷歌 CEO 解释为何急于发布 AI 产品:内部势头太猛
- 下一篇:AI攻入客服
相关阅读:
- AI攻入客服2023-08-30
- 为什么大模型拥抱生产力,人力成本依然居高不下?2023-08-30
- 巴比特 | 元宇宙每日必读:我国拟立学位法,利用 AI 代写学位论文或被2023-08-29
- 赛迪顾问:截至 7 月,中国累计有 130 个大模型问世2023-08-28
- 从 AI Grant 开始,看 Nat Friedman 与 Daniel Gross 如何投出美国人工智能的半壁2023-08-28

