人工智能(AI)与TDC交通大数据 TDC从同类项目中脱颖而出的关键在于其视频采集设备搭载了一块自主研发的人工智能芯片,所有的标注活动、数据筛查活动均由这块芯片来完成。 人工智能(AI)之所以能处理图像分类、语音识别、只是问答等复杂问题,关键在于卷积神经网络与深度学习技术的采用。交通数据自动标注本质上是图像处理和图像分类,数据标注的意义就是帮助及其理解、认识世界。 交通大数据的标注对象主要为图像、文本、视频等,其中图像和视频的标注内容通常有人像、建筑物、植物、道路、交通标志、车辆等等。据分析,一辆自动驾驶车辆的传感器组每天产生的数据量为10-20 TB,如此大量的数据让人来做分析和标注,成本过高且效率低下。 比如我们常用的Imagenet数据集,是由来自全世界167个国家,近5万名标注人员历时两年完成的。对与复杂一些的标注场景,比如语义分割在coco数据集上标注一张图片平均要19分钟,标注一张几百K、几M的图片都需要这么长的时间,那就更不用说动态的10-20TB的交通数据了。 标注的目的就是为了让机器理解、认识世界,这需要让机器明白画面中各个元素都是什么,并且把各个元素区分开,这就需要实现几个关键点——语义分割、二维/三维框线标注、线段标注、精细回归。
语义分割 - 如上图所示,将车辆标记为蓝色、人标记为红色、路牌标记为黄色、人行道标记为玫红色……。
二维/三位框线标注 – 如图所示,用框线标注出车辆及行人。
线段标注– 标注出道路标线。 精细回归就是指结合语义分割、二维/三维框线标注、线段标注,辅以交互式图像分割技术、精细化边框技术等,生成更精确的边缘信息。采用迁移学习,可以扩展至未训练过的全新数据集,进一步去除分割粘连,逼近真实图像边界,生成精细化的交通动态数据。
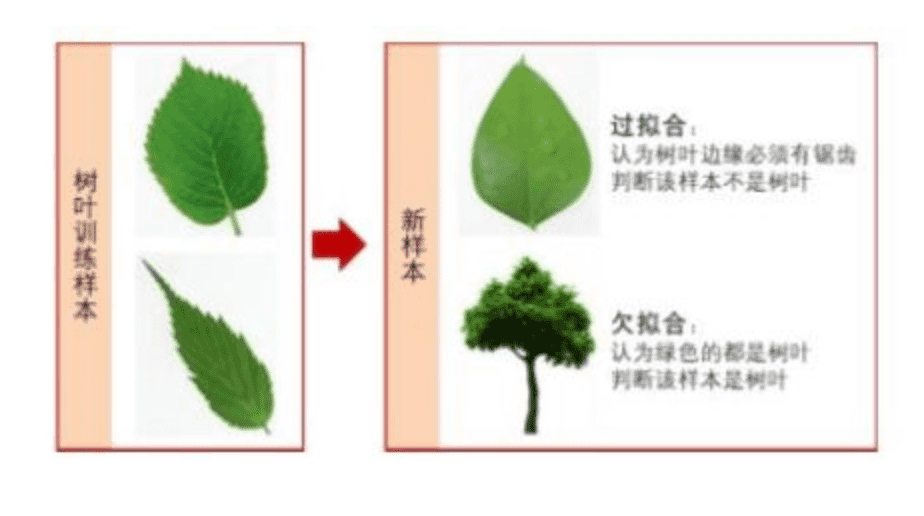
智慧交通对大数据的要求非常高,交通数据又有着数量庞杂、种类繁多的特性。在TDC与华为、京东的合作中,华为和京东表示,交通数据传统标注服务,一张图要花几十分钟,成本在20元以上,而使用人工智能自动标注,则可以节省80%以上的时间,降低人力成本,同时还能避免人工标注造成的数据不规范等问题,增强标注的一致性,提高标注的准确率。 在2019年第四季度TDC已经开发出了比较完备的自动标注系统,并将其置入早期数百台训练型矿机中,通过400多PB交通视频以及200多万张路况照片的训练,TDC训练型矿机已经圆满完成数据训练工作。 TDC训练型矿机是如何进行训练的 对人工智能的训练方法被称为“深度学习模型训练”。深度学习模型训练是一个很费时间,但也很有技巧的过程。模型训练中有梯度弥散,过拟合等各种痛点,正是为了解决这些问题,不断涌现出了各种设计精巧的网络结构。 在选定网络结构之后,深度学习一般分为以下四个步骤: 1.定义算法公式,也就是神经网络的前向算法。我们一般使用现成的网络,如inceptionV4,mobilenet等。 2.定义loss,选择优化器,来让loss最小 3.对数据进行迭代训练,使loss到达最小 4.在测试集或者验证集上对准确率进行评估 在这四个步骤中,又存在着很多难点。 难点一:收敛速度慢,训练时间长。深度学习本质上讲是一个反复调整模型参数的过程,人工智能认知事物的过程和人认知事物过程类似,收敛速度可简单理解为人对所认知事物的归纳总结速度。人工智能和人最大的差别在于,人有举一反三的认知功能,而人工智能仅能通过反复修正它的认知才能得到最合适的结果。 这一过程需要大量的训练时间以及迭代次数,虽然计算机GPU的硬件性能在逐年提升,但面对复杂的深度学习任务,硬件性能依旧捉襟见肘,加快收敛速度也就成了人工智能训练之路上的第一个难关。 难点二:线性模型具有一定局限性。深度学习的基础是神经网络,这是对人脑神经网络的模仿,然而现在主流的神经网络模型往往是线性模型,仅仅只是表征了神经网络。线性模型的局限性在于,任意线性网络的组合任然是线性网络,它能解决的问题是有限的。 说白了就是告诉人工智能1到10的加减运算,它可以递推出10以上的加减运算,但它不会明白2+2=2*2。它的学习能力是线性的。 难点三:过拟合问题。过拟合在机器学习中广泛存在,指的是经过一定次数的迭代后,模型准确度在训练集上越来越好,但在测试集上却越来越差。究其原因,就是模型学习了太多无关特征,将这些特征认为是目标所应该具备的特征。
难点四:梯度弥散, 无法使用更深的网络。深度学习利用正向传播来提取特征,同时利用反向传播来调整参数。反向传播中梯度值逐渐减小,神经网络层数较多时,传播到前面几层时,梯度接近于0,无法对参数做出指导性调整了,此时基本起不到训练作用。这就称为梯度弥散。 TDC采用TensorFlow训练模型进行训练,整个训练过程非常硬核及枯燥。 以图片训练为例,工程师需要先将一组训练样本打包,并将所有样本的名称以“类型-序号”的格式编辑,然后让程序遍历目录下所有图片,通过一个不重复的随机数序列,来达到随机抓取的目的。之后通过获取样本的“名称标签”标注视频元素,建立字典产生映射关系。这就产生了一个线性模型。 为了避免出现过拟合问题,接下来需要将上一批样本的像素降低到原来的一半,再生成一个线性模型。 为了突破线性模型的局限性,工程师还需要再每个卷积后加入一个非线性激活函数。这个函数是模拟了人脑的阈值相应机制,利用人脑只对大于某个值的信号才产生响应的机制,提出了单侧抑制的理念。 接下来就是不断丰富深度学习的样本数据库,反复校验深度学习成果。 经过数月的努力,我们非常荣幸的宣布,TDC训练型矿机已经完成了训练任务,它的训练成果将搭载进我们下一代M1型视频采集设备。 —- 编译者/作者:TDChain 玩币族申明:玩币族作为开放的资讯翻译/分享平台,所提供的所有资讯仅代表作者个人观点,与玩币族平台立场无关,且不构成任何投资理财建议。文章版权归原作者所有。 |
TDC训练型矿机已完成训练任务,M1型矿机正式进入研发阶段
2020-02-16 TDChain 来源:火星财经




LOADING...
相关阅读:
- NodeMax(N3)——数字经济迸发驶向财富蓝海2020-08-06
- 区块链就是比特币吗?现在如何获取比特币呢2020-08-06
- 天生说:8.6ETH晚间行情分析2020-08-06
- 震荡趋势走出,比特币有望再次冲高2020-08-06
- 区块链和5G产生的结合,带来的是相“+”效应还是相“×”效应?2020-08-06