| 原文出自Zack在知乎的专栏,软磨硬泡让我拿到首转,因为实在翻译的精彩。他在Twitter上写到,Roam的理想和愿景应该值得更多的人看到,也恰恰是我想说的。Enjoy。 Roam 是去年新涌现出来的笔记工具,其他作者已经在知乎上把它的功能进行了详尽介绍:Roam Research 这款笔记软件有何特别之处? 这里,我把Roam创始人写的白皮书翻译了一下,希望能给大家一些启发。摘抄一下原著的结论: 今天的人类知识体系,是一个浩瀚的信息与思想的海洋,其中很多是不准确的,有些是恶意的,其最佳资源或有看门人限制,或几乎不可能找到。信息量呈指数级增长,如果能够解决潜在的协作问题,这将带来巨大机会。 显然,我们需要一种跟以往本质上不同的方法。Roam对人类知识的愿景是一种集体的、开源的智能,不断地重新排列、迭代和进化以追求真理。我们每个人都将成为这个集体智能中的一个节点,建立联系并创建网络,分享每个人所能提供的最好的东西,在改善他人的同时也在改善自己,推进人类整体前进。 原著:Conor White-Sullivan | [email protected]英文:https://roamresearch.com/#/app/h elp/page/Vu1MmjinS中文:https://roamresearch.com/#/app/trade/page/nhzz3wRuM翻译:Zack Fan | [email protected] 摘要:Roam是一个用于组织和评估知识的在线工作区。该系统建立在一个有向图(Directed Graph)的基础上,使其不受经典文件树架构的束缚。用户可以在多个重叠的层次结构中混合和连接思想,每个信息单元都成为动态网络中的一个节点。任何给定的节点可以同时占据多个位置,通过可定义的关系链传递信息,并实时在整个有向图中更新。如果将节点之间关系强度分配了相应的权重,Roam也可成为贝叶斯推理和决策(Bayesian Inference)的工具。我们的最终目标将此系统扩展到协作推理领域,并允许团队构建可共享的心像地图(Mental Map),从而做出更快、更明智的决策。 1. 导言 我们正在经历前所未有的知识爆炸。仅在美国,每天就有2700本书籍出版,6850篇科学论文发表,200多万篇博客文章上线,2940亿封电子邮件飞来飞去。地球每转一次, 如果把新产生数据写入书里,那么这些书堆积在一起可以从地球到月球一个往返(注[1])。尽管这种指数增长为个人和整个社会带来了巨大的机遇,但无论是人脑还是当前的技术都还无法驾驭。 2. 当前知识管理的常见做法 人类对信息时代的适应性很差,信息时代仅在我们进化史的最后0.02%出现。尽管大脑确实具有非凡的原始存储能力,可能在几PB (Petabytes)范围内(注[2]), 但它在处理信息时极易出错。人类的记忆检索是有损且不可靠的,而许多固有的认知偏见及思维方式在现代世界中也会失效,从而扭曲了我们的感知、判断和决策能力。大脑的可塑性使它能够用新的链接重新连接自己,但即这也是一个“用则有,不用则无”的特质,那些不常用的的神经通路最终将逐渐萎缩。 为了应对这些局限,许多在大脑之外组织知识的技术应运而生。自古登堡印刷术(Gutenberg Press)发明以来,实体书籍和期刊大量涌现,此后又部分被文字处理程序,网站,博客,论坛,维基及其它软件应用所取代。 虽然我们对所学知识进行构架管理的方式有很多选择,但几乎每种技术都遵循相同的“文件柜”格式:即知识单元/文件被保存到某个特定文件路径中,该路径指向按章节或类别分类的某个文件夹。当某个知识单元/文件与许多知识点相关时,可以给它打相关知识点标签,但每个文件通常只存储在一个单一的嵌套层次结构中。要访问这些信息,用户必须记住他们存储文件的位置,标签的内容,或者使用搜索功能来定位文件。 相关讨论: https://twitter.com/Conaw/status/1099181050045952006By Conor White-Sullivan@Conaw 3. 文件柜架构的问题 在某些方面,当前的技术仍远不及人类的大脑。如果每个神经元仅能保存一个单独的“单位”记忆,我们的大脑就会迅速充满到溢出。相反,信息在大脑中是通过神经元和神经网络之间的联系来传递的,因此一个想法可以被整个大脑共用;蓝天的概念可能被重复用于无数看似互不相关的户外时光记忆中。这种效率有助于解释为什么一台计算机需要几百万倍的能量来完成与人脑相同的任务(人脑的功率大约相当于一个昏暗灯泡的功率)。(注[3]) 与大脑不同,文件柜方法使聚合或重用同一条信息很难甚至是不可能,因为每次对任何给定文件进行修改时,都必须在其存在的每个位置对其进行跟踪和更新。这就导致了冗余,几乎相同的想法重复被记录,且在任何需要系统范围更改时都要进行大量工作。 当前的解决方案也缺乏互联性, 许多文件被孤立而脱离了其上下文;信息被放在抽屉里,而不是系统性的放进更广泛的知识框架中。知识树可以在给定层次结构中的文件之间创建非正式关系,但这些关系通常是不明确的,且只能描述垂直的“父和子”分类关系。一些工具,如网页和wiki,同样允许相关文件之间的正交链接,但通常是非标准化的,且并没有清晰定义链接特性的能力。 4. 用节点网来展现的知识图谱 与传统的文件树相比,大规模协作需要更灵活的数据结构。Roam是建立在映射所有可能关系的知识图上的,并在用户所定义的概念之间建立了“智能”链接。用户可以在多个重叠的层次结构中连接相似的想法,在不覆盖原文的情况下重新合成它们,并有选择地与其他人共享知识图的一部分,以便在特定的子问题上进行协作。 如果市场现有的工具类似于文件柜,那么Roam更类似于电信网络中的节点网或者人脑中的神经元集群。每个注释或文件不是存在于真空中,而是成为相互联系的知识图中的一个节点。单个节点可以同时在多个不同的序列、层次结构或文件路径中保持位置,并且可以与其他节点“对话”,双向传递有关每种关系性质的信息。该网络是动态的,任何更新和修订将实时更新至整个网络。网络中的各个节点或分支可以根据需要进行分叉,从而允许在不更改原始含义的情况下建立新路径。 在最简单的层面上,Roam的结构使得存储、回忆和交叉引用思想变得更加容易, 这也是针对学生、作者、自学者和现有笔记程序用户Roam能帮到的主要领域。 对于高级用户,知识图还可以帮助解锁逻辑与推理,贝叶斯推理与决策,复杂问题建模及协作研究等多领域的更多应用。这些功能以及相关技术的潜在用例将在第5-8章中进行探讨。 5. 用节点网来展现的知识图谱 从研究论文的同行评审到报纸的时评,人们都是基于某种前提下来阐述某个观点,大致如下: 如果A为真,则B为真。如果C和D都为真,则A为真。C和D是都为真。因此,B为真。 当访问其中一个被引用的语句(block)时,我们能看到整个复合句已被关联。例如: 通常,C和D的论点是通过外部文章的链接得到支持,它们往往是基于更大论点之下,并综合其它前提后所得出的结论。不幸的是,论据的结构只是在语句中被暗示。除了在作者用作推论的草稿外, 论据和证据之间的关系极少在文章中被明确的阐述。 Roam允许科研工作者或作家把他们在不同项目中所想表达的思想组织起来。它也为大规模的跨学科研究项目创造了机会。当感兴趣的合作团队在一个一致同意的框架下讨论正反论点时,那我们就有可能创建可扩展的用户界面,将一些需要专业知识的洞察转化为更容易被外行人理解的观点。 自然语言的歧义性常常阻碍了许多有意义的讨论,且除非讨论的议题从一开始就有明确的定义,否则任何形式的争论都是徒劳的,并且通常最终会巩固对话者的最初立场。 示例A爱丽丝:“一棵树倒在一大片荒芜的森林里会发出声音。”鲍伯:“一棵树倒在一大片荒芜的森林里不会发出声音。” 示例B爱丽丝:“一棵树倒在一大片荒芜的森林里会(产生声波振动)。”鲍勃:“一棵倒在一大片荒芜森林中不会(产生听觉体验)。” (注[4]) 虽然这些立场如示例A所示是矛盾的,但简单地定义“声音”一词则可以表明双方基本看法 是完全兼容的。 在依赖关系图(Dependency Graph)中使用明确定义的集合有助于解决歧义,减少讨论的参与者夹杂其他目的进行辩论,或者故意使用“莫特和贝利谬误战术”(Motte-and-bailey fallacy) 进行误导。(注[5]) 除了推理和论证,依赖关系图在教育、自主学习和日常决策中也有众多应用。即使是一个非常复杂的项目,也可以追溯到一些较小的任务。用户可以看到每个决策路径所涉及的权衡,找出哪条路径最快,哪条路径可能更接近其他有趣的目标。当学生记录学习进程时,他们也可以利用学习中获得的技能发现新的任务和路径。 语言表达的问题甚至适用于数学证明领域,请参阅Lamport的“如何编写21世纪的证明” (How to write a 21st Century Proof)。 6. 理清复杂关系6.1 非线性因果关系 简单的问题往往遵循直接的因果关系。当病人有一系列与流感密切相关的症状时,医生可能会从可观察到的变量中推断出有一个不可见的变量——流感病毒。治疗这个潜在的变量,症状就会消失。 Scott Alexander观察到,他的精神病学同行同样试图将一组相关症状归因于一个潜在变量,例如抑郁症。(注[6])然而,抑郁症引起的症状-例如睡眠障碍、疲劳、内疚——也会对彼此和紊乱本身产生因果影响。这种复杂的关系网,可能包括反馈回路,并不遵循线性因果关系的路径。对于这种性质的复杂问题,节点网络是一个更精确的模型: Nuijten、Deserno、Cramer和Borsboom建立的一个抑郁症(MD)和广泛性焦虑症(GAD)模型。(注[7])这些疾病大致映射到一系列症状上,这些症状经常在一起发生并相互加强,但在这些症状之间没有清晰的“亮线”。 即使从表面价值来看,节点网络也为解决问题提供了一种直观的帮助——鸟瞰各种元素之间的联系。这可能有助于识别不同形态或群集,这些形态或群集可能是违反直觉的,或者当研究微观结构时很难看到整体面貌 。6.2 贝叶斯推理 将贝叶斯推理应用于知识图,可使其成为概率估算、假设评测和决策制定的强大工具。贝叶斯定理是一个概率定律,它告诉我们,当学习一个新的事实或获得新的证据时,我们应该在多大程度上改变我们对某事的看法。该定理在下列方程式中陈述: 其中A是关注的命题,B是观察到的证据, P(A) 和P(B)是先验概率, P(A|B)是A的后验概率。 假设一个医生有一个病人,因为他属于一个高危人群,所以他想知道携带一种潜在病毒的概率, 这是等式左边的“关注命题”。先前的数据表明,总人口中有4%是病毒携带者,因此 P(A) = 0.04。B是观察到的证据, 即32%的总人口是高危人群,P(B) = 0.32。医生知道,在携带该病毒的患者中,80%属于高危人群:B | A=0.8 医生应用了贝叶斯定理: P(A|B) = (0.8 * 0.04)/0.32P(A|B) = 0.1 她的病人只有十分之一的机会成为病毒携带者,这可能低于常人的预期,因为几乎所有的携带者都是高危人群。 虽然这是一个简单的计算,但贝叶斯推理的优势在于可以将看似无法解决的问题分解成小块。即使没有可用的数据,连续的多层估算仍然可以对各种结果的置信水平提供有益的改进。通过将此框架加入到节点之间定义的关系中,网络中任何一点的权重的修改将自动更新到整个知识图中。 贝叶斯概率也为决策制定提供了一个框架。通过评估各种选择的成本和取舍,用户可以计算出哪条路径提供了最高的期望值。同样,即使权重只是个人喜好的简单估计,决策的质量也可以通过多层的正反方论据来改进。评估矩阵允许我们将大量信息集成到最终决策中,而不是默认使用某种简单的推断法。 7. 为意外发现进行优化 正如人类无法随意生成随机数一样,让我们有意识地生成随机想法也很困难 ——以至于我们常常主动尝试“以不同的方式思考”, 但这似乎只会进一步加深现有思维模式的固化。大脑必须面对新的刺激,才能重新组织其感知能力,而不是试图粗暴地强行产生创造力。暴露在一定数量的随机“噪音” (梦境、冥想、塔罗牌阅读、错误)会使思想脱离常理的束缚,进入全新的思维空间。通常,这些洞察发生在两个或多个看似不相关的领域、概念或形态的交界处。 Roam知识图的相互联系可不断地为意外发现创造机会。网络中的每个节点都可以在多个图表显示与查看,用户可以查看相关的想法,上下扫描垂直层次结构,检查附近的节点群集以及观察知识图的形态。 Roam的搜索功能可以根据用户的需要进行校准,以包含尽可能多或尽可能少的“噪音”。在寻找特定的段落或注释时,搜索设置可以足够窄,以准确地找到用户的想法。然而,它也可以扩大到“钓鱼之旅”的范围,目的是使各种想法浮出水面。一些搜索结果将包含用户可能已忘记的注释,一些可能是噪音,而另一些则会激发用户甚至不知道自己在寻找的想法。 来自不同领域思想的交叉融合可为个人和社会带来唾手可得的效益。而成为某个领域一名专家所需的时间和精力投入则很快会进入收益递减。相比之下,积累一系列业余知识或技能的“才华”反而可以捕捉到那些局限在更窄关注点专家们所洞察不到机会。 高度专业化的知识对于开辟新的领域仍然至关重要。然而,面对日益复杂的问题,跨学科的研究方法对科学家、技术专家和决策者也变得愈发必要。 8. 协同问题解决 虽然Roam的单人使用有其自身的优点,但最终目标是创建一个协作研究和学习的平台。现有机制常常受到必要共识假设的约束,而知识图库的灵活性允许一种更加多元化的方法,能够在不诉诸专制或民主的情况下,权衡相互冲突的观点,将信号与噪音分离。8.1 在噪音中寻找讯号 随着信息频率的增加,世界变得越来越嘈杂。如第7章所述,在特定情况下,故意暴露于噪音是一种有用的策略,但在其他时候会造成沟通中的含混。(注[8])鉴于我们有把故事和解释强加于随机性的倾向(即叙事谬误),将真正的信号与噪声区分开来变得越来越困难。 假设一个趋势的年化信噪比为1:1(50%的数据是有意义的,50%是随机的)。如果我们每天观察相同的数据,则比例变化为95%的噪声,5%的信号。如果每小时观察一次数据(就像新闻记者和市场狂热追踪者那样),它就会变成99.5%随机-也就是说,噪音是信号的200倍。(注[9]) 负责解释数据的机构包括媒体,学术界和立法机关。这些机构中的某些人可能故意掩盖真相,如“假新闻”,p-hacking和politicking。尽管主动的恶意行为是例外,但即使是最好的记者,研究人员和分析人员也不能幸免被随机性所愚弄。 因此,对大多数人来说,从噪声中分离信号的问题涉及到寻找可靠和准确的辅助信息源。这项困难的任务经常被封闭的科学期刊和搜索引擎算法所阻碍,这些算法越来越被精通搜索引擎优化的内容营销人员操纵。8.2 信息冗余 浏览海量信息会产生大量冗余。大多数人将精力浪费在已经解决了一百万次的问题上。那些解决未解决问题的人们经常在信息孤岛上,而没有意识到彼此的存在。任何给定拼图的所有碎片可能都存在,但没有一个个体或群体持有全部。在无穷无尽的论坛、评论区、网页和书籍中,车轮被一遍又一遍地重新发明 ,信息突然出现,又很快消失得无影无踪。8.3 共识 今天,几乎每种媒体都把所传播的认知当作真理来呈现;假设有默认的共识,且不可分割。维基百科是互联网时代最伟大的奇迹之一,但它同时犯了这两个错误。对于任何给定的语言,任何主题都只能有一篇文章,页面之间的唯一连接是通过链接,而没有文章是在另一篇文章的基础上构建的。 相比之下,我们来看一下Github:库是在其他库上构建的,功能是从其他功能上构建的。开发人员致力于开发可以被其他人拿来做更棒工具的工具。大多数现代互联网都是建立在开源技术之上的,如果程序员只能遵循旧的协议进行智能协作,这是不可持续的。 许多问题可以通过编写代码来解决,但是自然语言仍然是我们确认哪些问题值得解决的方式。自然语言是我们相互解释世界并交流现实模型的方式。它是教育的语言,也是决策的语言。自然语言需要一个跟管理代码的工具链一样好的协作工具链。8.4 协作方法 必要共识的问题是可以由个人或团体根据他们自己的信任网络所提供的数据,并依其所得出的推论图来解决。然而,协作仍然需要一种机制来评估哪些想法是最好的。就像个人给自己的预测和决定赋予权重一样,团队必须能够对任何给定的想法、前提或证据的可信性进行“投票”。如何校验这些集体权重,有多种选择,下面简要介绍其中一些。 a) 群体智慧 一群人可以做出比任何一个个人都更好的某些决定和预测:伟大的统计学家弗朗西斯·高尔顿惊讶地发现,在一个乡村集市上,800人猜测一头牛的均重仅比1198磅的正确数字低一磅。 简单的人气比拼并不总是能让我们更接近事实,但它是有用的,因为它告诉我们什么是我们相信的。这些数据可按人口统计数据来分解,以展示不同的群体如何看待现实,并可能提醒人们注意到其自身群体内的偏见。 b) 可信度评分 对冲基金经理雷达里奥(Ray Dalio)在桥水基金(Bridgewater Associates)开创了一个决策系统,相较民主制度这更像一个智者治国的制度:与那些可信度得分较低的人相比,那些反复证明自己对特定专题或特性有把握的“可信”人的观点更具分量。没有什么可以阻止达里奥的观点被他最年轻的员工推翻,只要员工始终可持续证明比达里奥更正确。在Roam中实现类似的系统将需要跟踪绩效的能力,比如用户对知识图贡献了多少被广泛支持的原创内容,或者他们的预测有多么精准。 c) 预测市场 当人们屈服于同伴的压力和其他偏见,没有足够的专业知识或故意做出错误的预测时,“群体的智慧”最终可能是非常错误的 预测市场背后的洞见是,可以利用市场的力量激励参与者从任何错误中获利。只要有人认为某个共识是错误的,他们随时可以押注该共识是错误的,从而把概率推回到一个更明智的立场。内幕信息不仅被允许,而且受到欢迎。通过这种方式,大量的信息可以被合成为一个不断更新的数据点,且其通常非常准确。 监管问题抑制了预测市场的增长与扩大,可能的解决方法包括非法定代币(non-fiat token)或声誉挂钩积分系统。 9. 结论 今天的人类知识体系,是一个浩瀚的信息与思想的海洋,其中很多是不准确的,有些是恶意的,其最佳资源或有看门人限制,或几乎不可能找到。信息量呈指数级增长,如果能够解决潜在的协作问题,这将带来巨大机会。 显然,我们需要一种跟以往本质上不同的方法。Roam对人类知识的愿景是一种集体的、开源的智能,不断地重新排列、迭代和进化以追求真理。我们每个人都将成为这个集体智能中的一个节点,建立联系并创建网络,分享每个人所能提供的最好的东西,在改善他人的同时也在改善自己,推进人类整体前进。 关于 Roam Roam由Conor White Sullivan和Joshua Brown创立。九年多以来,Conor一直致力于集体智能工具的开发,创建了在线小镇common Localocracy(2011年被AOL收购),并在收购之后领导了《赫芬顿邮报》的研发工作。Conor和Josh在免学费的编码大学http://42.us.org相遇,在为期一个月的申请考试期间,乔希在首批1000名进入美国项目的学员中名列前五。该白皮书由商业记者Richard Meadows共同撰写,他对早期原型的试用使他成为Roam的第一位投资者。 本文转自知乎,原文链接请点击阅读原文参考资料 [1] 注释1:现在每天至少产生2.5万亿字节的信息,这与2002年全年产生的信息量差不多。[2] 注释2:科学美国人:New Estimate Boosts The Human Brain's Memory Capacity 10-Fold现在每天至少产生2.5万亿字节的信息,。[3] 注释3:微电子学的先驱卡弗·米德(Carver Mead)创造了摩尔定律一词,他在1990年正确地预测到,如今的计算机在单个指令中的能量消耗要比大脑在突触激活中的能量高一千万倍。[4] 注释4:本示例改编自《the Less Wrong sequence 37 Ways Words Canbe Wrong》[5] 注释5:莫特和贝利(Motte-and-bailey)指的是争论一个容易辩护的、通常是常识性的陈述(Motte),以避免批评人士提出一个难以辩护的、更有争议的陈述(bailey)。该术语由斯科特·亚历山大(Scott Alexander)推广,并在《All in All,Another Brick in the Motte》中进行了解释。[6] 注释6:Slate Star Codex:精神障碍作为网络(Mental disorders as networks)。[7] 注释7:Michèle B. Nuijten,Marie K. Deserno,Angélique O. J. Cramer,Denny Borsboom:精神病理学的网络方法的介绍和概述(An introduction and overview of a network approach to psychopathology)[8] 注释8:正如卡尔·萨根(Carl Sagan)所观察的那样,虽然每天电视节目中播放的数据比历史上所有文字作品的总和还要多,“但并非所有的比特都具有同等的价值”。[9] 注释9:此示例来自塔勒布(Nassim Taleb)《反脆弱》(Antifragile)。 本文来源:胖车库Jessie —- 编译者/作者:胖车库Jessie 玩币族申明:玩币族作为开放的资讯翻译/分享平台,所提供的所有资讯仅代表作者个人观点,与玩币族平台立场无关,且不构成任何投资理财建议。文章版权归原作者所有。 |
Roam白皮书
2020-06-25 胖车库Jessie 来源:火星财经



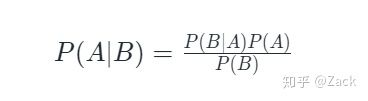
- 上一篇:丁君羡:比特币被打回原因形上涨只是诱多?
- 下一篇:比特币价格跌至9,300美元
LOADING...
相关阅读:
- 关于NerveNetwork主网开放节点和质押挖矿的公告2020-08-05
- 共识实验室宣布成立专注DeFi理财基金,首期保本产品将首发于可可交易2020-08-05
- 社区征文丨当BHP遇上Cosmos,会迸发怎样的火花?2020-08-05
- DNP首届核心共识会议圆满成功2020-08-05
- HKEx.one星火派对等你燎原在长沙邀你一夜狂欢2020-08-05