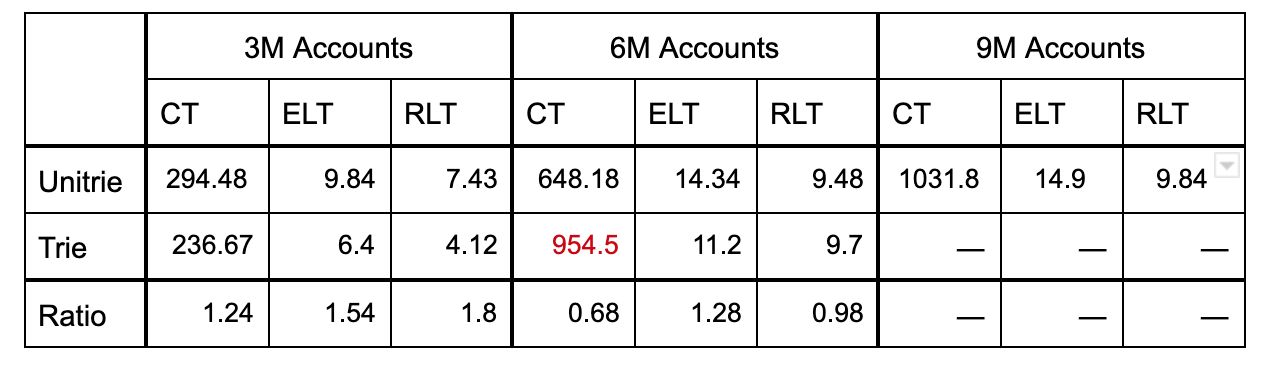
简介 在2016年,RSK 提议以Unitrie替代 Merkle Patricia Trees,用于建模以太坊的世界状态(请参阅附录D中的《以太坊黄皮书》)。自2020年1月起,我们已将Unitrie作为可选功能添加到 RSK 的Rif 共识节点(以Besu的代码为基础)中。因此,Besu 用户现在可以在两个世界状态实施之间进行选择: Besu 世界状态(或经典世界状态),如《黄皮书》中所述。Unitrie 世界状态,由 Unitrie 提供支持。有机会从两个不同的世界状态实施中运行一个 Rif 共识节点,我们将能够比较每种世界状态的优点。在本文中,我们将比较这两种实施方式,分析这两种实施方式在耗尽可用存储空间之前的构建/查找时间和帐户分配容量。 实验1:构建和查找时间 为了分析构建和查找时间,我们执行了一个基准测试,包括向最初为空的以太坊世界状态添加给定数量的帐户,并在基准测试执行期间进行五十次更改(即,将创建的帐户存储在世界状态的 trie/Unitrie 中) 。对所有帐户进行就位后,我们会以两种方式查找一百万个帐户: 查找一百万个现有帐户(找到所有帐户)。查找一百万个随机帐户(操作时找不到帐户)。该基准测试最终报告构建和查找时间。我们在 4Gb Java 堆上执行基准测试,间隔为3百万个到1千万个外部拥有的帐户。我们通过对每个帐户数量运行六次基准测试以处理差异。下表显示了3百万、6百万和9百万个帐户的平均构建和查找时间。CT代表构建时间,ELT代表现有帐户查找时间,RLT代表随机帐户查找时间。所有时间都以秒为单位。
表1。构建和查找时间 我们的 Unitrie 实现旨在提高内存效率,在大多数情况下,我们很乐意为降低内存占用而牺牲执行时间。这种选择使 Unitrie 在查找时间方面劣于以太坊的 trie,Unitrie 的速度慢了1.2到1.8倍。但是考虑到分配的帐户数量,这是有利的。Unitrie 可以处理内存中的9百万个帐户,而Besu的世界状态实施几乎无法突破6百万的极限。确实,使用6百万个帐户构建 trie 的速度比传统 trie 慢1.47倍。这表明Besu正在破坏JVM以使其在6百万个帐户极限下运行。
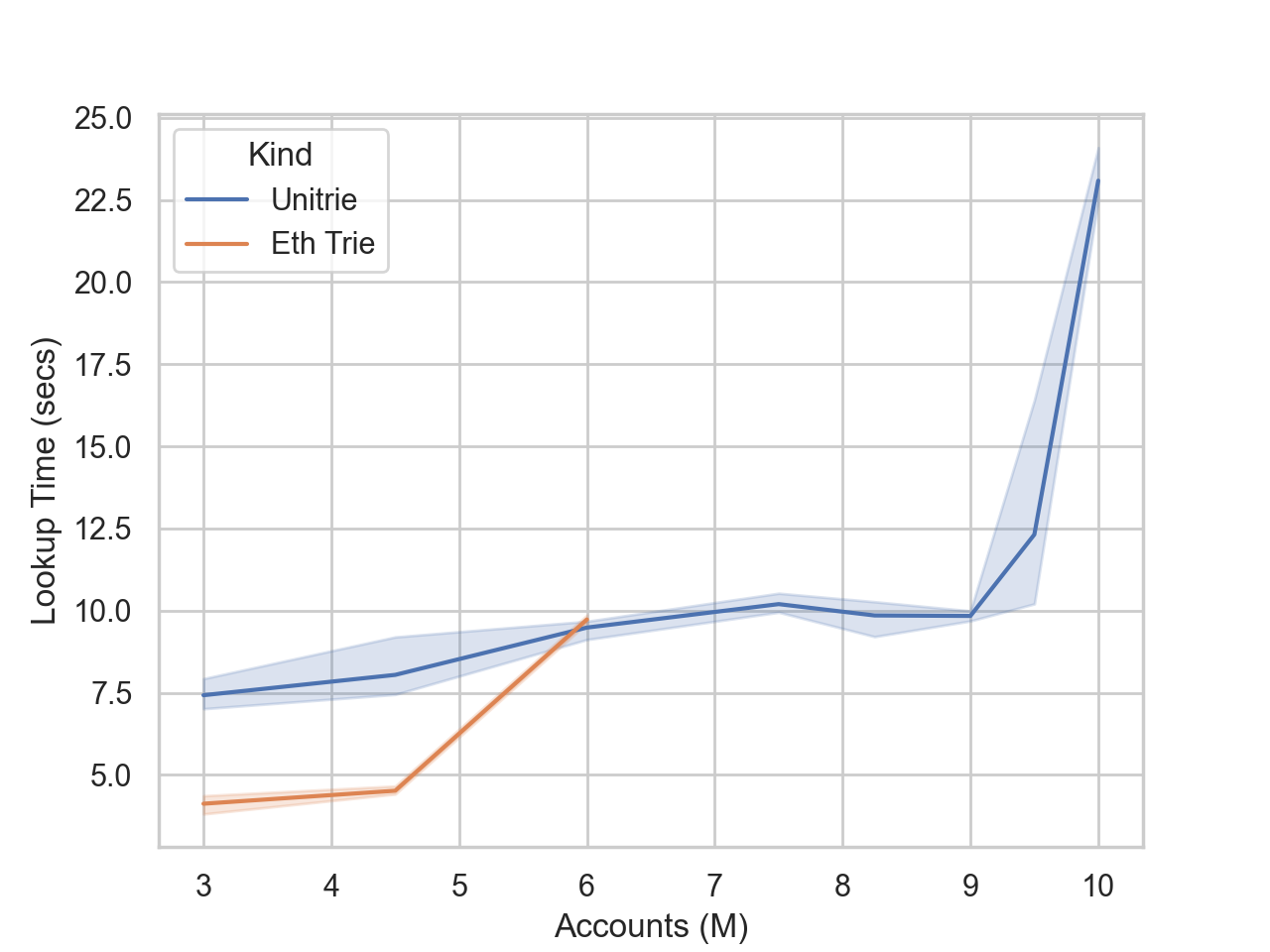
表2。构建和查找吞吐量 表2概述了构建和查找吞吐量。CTp是构建吞吐量(Construction Throughput)的缩写,用于测量每秒Unitrie/Ethereum世界状态的更新次数。同样,ELTp和RLTp分别表示现有帐户查找和随机帐户查找吞吐量(每秒查找数量)。一般来说,在给定的时间内,Unitrie可以执行Besu世界状态执行操作量的55%-80%。值得注意的是,由于存在颠簸现象,当输入6百万个帐户时,Unitrie的吞吐量则为Besu世界状态吞吐量的1.5倍。此外,对于该数量的帐户,Unitrie的一百万个随机元素的查找吞吐量与Besu的世界状态相匹配。 请注意,在最坏的情况下(9百万个帐户,现有帐户查找),查找吞吐量为每秒67,000次查找。为使我们自己信服这是可接受的,想想BALANCE操作,其成本为400 Gas。假设680万Gas的RSK区块的当前气体限制,理想情况下,您最多可以在一个区块中执行680万/400 = 17,000 BALANCE操作,甚至每秒可以进行67,000次查找。假设trie存储在内存中,Unitrie将在0.25秒内执行。 图1、2和3分别描述了在[3百万,1千万]范围内分配帐户时的构建和现有/随机帐户查找时间。该图表显示每个数据点的集中趋势和置信区间。请注意,对于4Gb Java堆,Unitrie在9百万个帐户极限时开始出现颠簸现象(请参阅Besu的世界状态,在6百万个帐户极限处发生的颠簸现象)。此外,Unitrie展示了更大的置信区间。这是因为将共享路径作为软引用存储的Unitrie实施,从而非确定地增加了运行时间的路径重新计算支出费用。 实验2:合约帐户 Unitrie将每个帐户存储在从其地址哈希衍生的密钥下。通过构建,帐户密钥具有随机前缀和相等长度,因此平均而言,结果将是支叶上具有帐户的二进制平衡树。这意味着N个外部拥有的帐户将需要2N – 1个节点。 在考虑合同帐户时,Unitrie的存储容量必然会相对于先前的计算降低。这是因为Unitrie将代码存储为相应帐户节点的右子级。因此,对于N个帐户,其中α是合约之间的比率。
图1。世界状态构建时间
图2。查找时间(现有帐户)
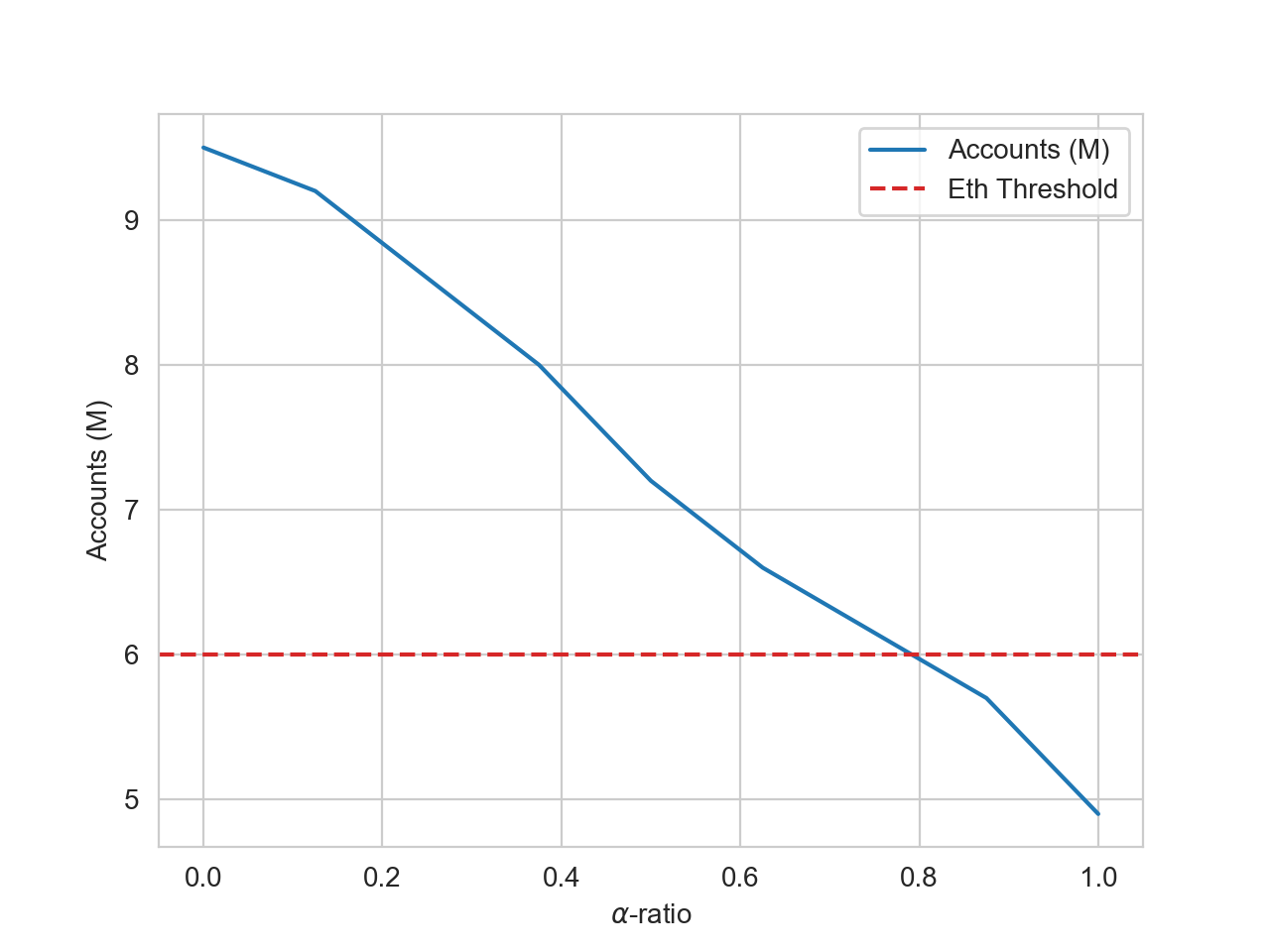
图3。查找时间(随机帐户) 和外部拥有的帐户,Unitrie尺寸变为(2 +α)N – 1个节点。它的范围从当α= 0时的2N – 1个节点(因此包含了N个外部帐户的初始计算)到当α= 1时(所有帐户都是合约)的3N – 1个节点。相反,以太坊的世界状态将帐户代码存储在trie之外,因此在考虑合约帐户时,trie的存储容量不会受影响。 为了测量由不同的α值引起的Unitrie的存储容量变化,我们运行了一个基准测试,在出现颠簸现象之前在4Gb Java堆中分配了尽可能多的帐户。我们对[0,1]区间中的几个α值进行了实验。基准测试使用真实世界2114字节的ERC20合约作为帐户代码。图4描述了结果,精确指出α= 0.8是Unitrie越过Besu以太坊世界状态的最大存储容量的点。它还显示了4Gb堆上的Unitrie操作范围:它可以存储950万/900万个外部拥有的帐户(α= 0)和490万个合约帐户(α= 1)之间任何数量的帐户。
图4。合约帐户引起的存储容量变化 结论 Unitrie牺牲计算时间以获取内存占用量。图2和图3显示,对于[3百万,5百万]范围内的帐户,Unitrie查找时间要慢1.5到2倍。但是,在Besu的世界状态最终无法从磁盘读取节点的情况下,这种差异将消失,因为它在内存中无法容纳足够的世界状态。在这种情况下,磁盘输出/输出延时将主导查找时间。我们的实验表明,Unitrie可以在一个4Gb的堆中存储一个由9百万个外部拥有的帐户组成的世界状态,而Besu的世界状态在6百万个帐户极限时性能会开始下降。总体而言,与Besu的世界状态相比,Unitrie具有避免磁盘输入/输出延时的更大潜力,但其代价是查找速度慢1.8倍(在最坏的情况下)。 在考虑合约帐户时,存储容量由α(合约帐户与外部帐户之间的比率)确定。α值越低,可以在内存中容纳的节点越多,这又可以最大限度地避免磁盘输入/输出延时。实验2表明,当α<0.8时,Unitrie的存储容量超过Besu。 对α的估计是多少?截至2020年11月,Etherscan报告在Mainnet上有8,028万个唯一帐户。在同一日期,合约帐户数量为1,240万个。得出 α= 0.154。截至撰写本文时,Mainnet具有9,414万个唯一地址。若我们不切实际地假设,如果自2020年11月以来创建的每个帐户都是合约帐户,这为α= 0.28给出了被高估的上限。即使这样,这仍然在Unitrie的轻松处理范围内! 附录A:运行实验 所有实验代码都托管在Github项目rif-consensus-node,中,并且需要JDK 11或更高版本。克隆此项目后,您可以通过转到项目的根文件夹并执行以下命令以运行Unitrie压力测试或以太坊的经典世界状态测试: 其中account_to_create定义了要创建的帐户数量,参数alpha_ratio对应于实验2中定义的合约帐户与外部拥有帐户之间的比率。 我们在配备Intel i5 2.3 GHz双核处理器、16Gb RAM和250GB SSD的MacBook Pro上进行了此次实验。所有实验都使用G1垃圾收集器在最大4Gb的JVM堆上执行。 本文来源:RSKCommunity —- 编译者/作者:RSKCommunity 玩币族申明:玩币族作为开放的资讯翻译/分享平台,所提供的所有资讯仅代表作者个人观点,与玩币族平台立场无关,且不构成任何投资理财建议。文章版权归原作者所有。 |
RIF Consensus Node 世界状态的压力测试
2020-07-01 RSKCommunity 来源:火星财经



LOADING...
相关阅读:
- 尽管围绕ETH 2.0进行了炒作,但技术指标仍对以太坊造成了麻烦2020-08-07
- 带有SEC的灰度级以太坊信任文件将ETHE锁定期减半与GBTC相同2020-08-07
- Celil?ztürk:“比特币是一场革命,以太坊是互补的”2020-08-07
- 加密货币投资论文Redux。 过去十二年来发生了很大变化……| 由Garric2020-08-06
- 陈楚初:8月6日BTC/ETH/BCH午夜金评2020-08-06