撰文:郑嘉梁,HashKey Capital 研究总监 本篇我们探讨一下区块链世界里的数据供应,以及以数据为核心产品的服务商如何形成一定的市场规模,即他们如何产生价值和捕获价值的。 区块链本质上是一个分布式数据库,虽然有着公开、透明、可追溯等特点,但是直接访问或者获取这写数据并不便利,需要特定的接口、进行格式化、以及转变保存类型。大部分区块链使用的是键-值类型的数据库,方便多写少读,而普通用户比较习惯的是关系型数据库。关系型数据库可以用像 SQL 那样的查询语句来进行查询, 像 Dune Analytics 这样的服务商就是把链上数据变成关系数据库,方便调取,这中间的流程还包含了数据的存储和再加工的过程。 一般有两类有价值的数据: 链上数据:链相关数据(哈希、时间戳、难度等)、转账、普通交易、智能合约事件等,这类数据被分布式数据库所维护,可靠性由共识保证。即区块链的核心数据。 非链上数据:与链上相关,准确性依靠中心化或去中心化的节点验证的数据,如交易所、预言机等,类似于 Web2.0 服务。交易所数据介于链上链下之间,是链上数据的链下计算,然后经链上验证,也产生了很大的数据量。 我们认为数据市场需求爆发的驱动来自于: 多链宇宙(含 Layer2)的成型应用的增加和用户的增加应用带来的数据需求的增加(如开发、分析、交易、金融产品的使用等)用户行为复杂化数据市场参与者交易者 交易者根据各类数据信息判断可交易的方向,比如观察某条链的活跃程度,某个 DEX 的成交情况、某个借贷协议的借出贷款等。他们会需要有可靠的数据源,一些高级用户会使用付费的数据服务。 数据的提供者 被动的产出方(不以数据盈利为目的):如区块链的节点,交易所,普通用户主动地产出方(以数据盈利为目的):API 提供者,数据搜索引擎,定制化数据包。他们往往是原始数据的加工者。 开发者 开发者查询、调用链上数据,与区块链交互。由于节点服务商的存在,开发者不需要搭建自己的节点,就可以直接和链上进行交互。众多 dApp 以及第三方钱包应用都依赖于 Infura 这样的节点服务商,与区块链进行交互。开发者的需求来自于:网络状态监控、交易执行状况监控、稳定的执行环境、市场和竞品趋势信息、产品和市场策略指定、根据客户偏好提升产品性能等。 需要不停监听网络状态的应用和中间 比如借贷协议需要监控账户状态,一些自动化中间件要及时反馈价格变化等。 区块链数据结构、存储、和访问-以 Ethereum 为例键值数据库区块链本质上是个数据库,和比较为大众熟悉关系型数据库不同,以太坊使用的键值(K-V)类型数据库,其底层基于 Google 的 Level DB,适用于写多读少的场景。关系型数据库历经多年发展,被程序员所接受,也非常利于普通人理解。关系型数据库的结构是一系列的表。 键值数据库是新发展出来的非关系型数据库,结构相对简单:键作为唯一的标识符,值存储数据,值可以是任何东西,不需要遵循表的结构,灵活多变且扩展性强。键值和关系数据库相比扩展性好,可以提供大数据量的读写,常被用于缓存。大部分分布式数据库采用键值数据库,依靠 LMS-tree 的结构进行有效的数据写入和查询。少部分选用关系型数据库,如 Ripple。 区块链的数据根据状态和交易的抽象结构如下: 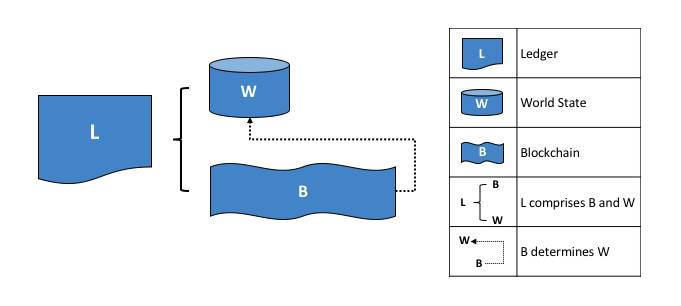  来源:HyperLedger 以太坊的区块数据包括区块头和区块体,区块头包含许多字段。从结构来看,以太坊的主干就是三棵树:状态树、交易树和收据树。 以太坊的主要字段是 State Root(状态树),包含了账户余额、声明、随机数等,状态树采用的是 Merkel-Patrica 结构,需要不断的更新。而交易树和收据树不需要更新,所以采用了 Merkel 的数据结构:交易数据是永久数据,永久数据已经记录不会被改变。状态树储存每个以太坊账户的地址余额,一经发生交易就会修改。以太坊的数据结构总结起来就是这一张图:  来源:Lucas Saldanha 永久储存与临时储存 如前所述,以太坊的底层数据是以 K-V 形式储存在底层 LevelDB 里的。但是 LevelDB 适合于写多读少的场景,所以真正用于读取、查询的数据库是 StateDb,它管理着所有账户的集合,账户的呈现形式是 stateObjectStateDB。其直接面向业务,是底层数据库(LevelDB)和业务模型的之间的存储模块。它采用两级缓存机制,以满足查询、更新、调用等功能。第一级缓存为 map 形式,存储 stateObject,二级缓存以 MPT 形式存储。当 stateObject 有变动的时候,实例化的 stateObject 会更新,当 IntermediateRoot() 被调用后,他们会被提交到 MPT 上,当 CommitTo() 被调用后,他们会被提交到底层 levelDB 中。这就形成了三级缓存结构。使用多存数据库的好处是,当需要回滚的时候,直接调用 stsateDB 中 MPT 树的根节点进行数据还原即可。 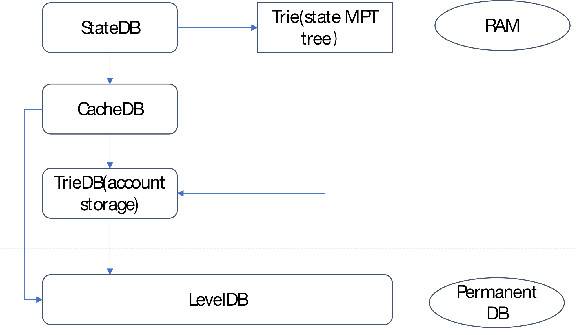 来源:网络,HashKey Capital 整理 但是要是将这些数据变成可用的数据,就是将这写数据变成可用的查询字段,比如 Blockheader 包含的字段,Block Body 包含的字段,智能合约的 Log 的字段等,交易的 Trsaction 字段等,不同字段对应着不同类型。  Dune Analytics 提供的以太坊可查询数据字段 Log 是非常重要的数据,因为以太坊的智能合约运行在 EVM 中,与外界隔离,EVM 发生的事件就是通过 Log 传输到外面并记录在区块链上。实际上,像 Etherscan 这样的浏览器就是用过 Parity 客户端回放 EVM,拿到智能合约交易的记录(内部交易)。 许多区块链的结构也可以存储非交易数据,但是容量有限。比如比特币的 output 中的 OP_RETURN 字段就可以存储不超过 40 字节的数据。限制的原因在于放大增加这部分会影响区块链的性能。以太坊的区块头也有 Extra 字段可以用来写入数据,如这样的:  来源:https://etherscan.io/block/12912176 区块链并不合适进行文件的存储,以 IPFS 作为存储底层和区块链结合的方式是比较认可的,比如数据储存在 IPFS 中,但是数据的 Hash 值存在以太坊的状态数据库中。 缓存 除了上链的交易外,以太坊还有一个保存在缓存中的数据,即 mempool 里面的排队数据。各个节点提交的交易都会被放入 mempool 交易池中,经过序列化、交易验证、过滤等步骤,最终选择合适的交易被矿工打包。交易池中有 Queue 和 Pending 两个 map,用来存储未验证交易和已验证交易。Queue 和 Pending 清理结束后,根据不同节点提交的交易,交易池要进行重构(由于分布式的原因),防止出现分叉。 以前交易池的数据没有那么重要,但是随着智能合约的交易占比提升,交易的排序有了更多的经济意义,所以已经有项目开始做类似的工作。 趣味性强的的比如 Txstreet真实提供交易池数据接口的比如 Blocknative提供 MEV 解决方案的如 Flashbot访问 如何访问以太坊上的数据呢?一般是两种方式 : 远程访问以太坊的节点 使用 web3 或者是 JSON-RPC 的方式。JSON-RPC 是无状态的轻量级跨语言远程调用协议,文本传输的数据是 JSON 格式,传入和传回都是 JSON 格式。使用 JSON-PRC, 客户端发送 PRC 请求,就可以直接通过以太坊客户端,传回相应数据,比如使用对应字段,eth_gasPrice, eth_blocknumber 等。 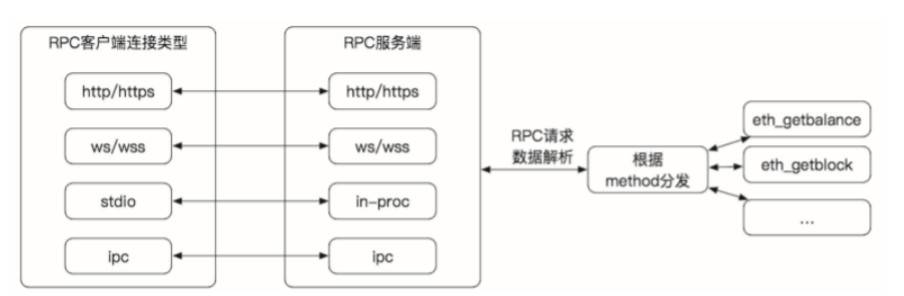 来源:《深入理解以太坊》 如果不使用 JSON-PRC 方式,可以以太坊基金会提供的 javascript 库,即 web3.js。它底层封装了 RPC, 使用起来和 JSON-RPC 方法一样,先创建一个 web3 对象,就可以使用库里提供的方法获取各种数据。比如,显示账户的余额: var balance_1 = web3.eth.getBalance(web3.eth.accounts[0]); console.log(balance_1.toString()); 使用 web3.js 有一系列好处,在于他们有非常细致的模块: web3-eth?用来与以太坊区块链及合约的交互;web3-shh?Whisper 协议相关,进行 p2p 通信和广播;web3-bzz?swarm 协议(去中心化文件存储)相关;web3-utils?包含一些对 DApp 开发者有用的方法。JavaScript 库还可以通过读取 Application Binary Interface (ABI) 来直接和复杂的智能合约进行交互。ABI 就是 json 形式的智能合约函数,因为智能合约是以 solidity 写的,json 形式就可以通过 JavaScript 直接使用了。可以做的事情包括:向合约发送交易、估计使用 EVM 的 gas fee、部署智能合约等等。 除了 web3.js 库外,还有 ether.js 库这样的 javascript 库。 使用 web3.js 的一个实例就是区块链浏览器:使用 web3.js 访问以太坊,获得的数据进行加工,通过中心化的接口加入非链上信息(如标签,项目名字),然后循环调用 web3.js 查询链上数据,不断更新区块。 自己搭建节点,本地访问 自己搭节点就是自己将所有的以太坊全网数据全部下载下来,这需要大量的成本,以及安全技术,大部分用户和开发者都不会选用这样的模式去使用数据,一般会使用第一类方法或者直接从去找到更好的 API 服务商。 流转过程 以太坊的本质是交易驱动的状态机,一切变化皆由交易开始,变化的记录就是数据,API 从头到尾串起了数据的流转。整个区块链数据流转的过程是这样的:  数据服务者类型 数据服务者类型节点服务层 节点服务商可以说已经变成了以太坊运行的根基,比如最有名的 Infura,本身运行以太坊节点并提供 IaaS 服务,省去了建立以太坊节点的过程 , 应用可以直接靠 Web3 访问。API 成为管道,需要使用数据的话,对管道进行付费。 底层数据服务(和链进行交互)和上层数据服务可以紧密合作,底层提供节点,上层提供数据的查询。比如 Quicknode 和 Dune Analytics 的合作就是这样的例子。Dune 为数据分析这提供一个可以应用 SQL 语句查询的数据库,还可以将数据可视化。在 Dune 出现之前,没有一个统一的数据格式可以将项目之间进行比较。Dune 是 Quicknode 的主要客户,之前是使用自建的 Parity 节点。经常需要担心节点的内存泄露(memory leak)、磁盘空间不够等,而且成本较高,使用 Quicknode 后后大大降低了成本,每月成本 1000 美元降到每月 35 美元。此外 Quicknode 还提供类似 CDN 的服务,这可能是另外一个可以促进 dapp 应用体验的方向。还可以帮助访问 mempool 的数据。还可以提供私有节点。Quicknode 有一些业内知名的用户,比如 Nansen, PayPal, DappRadar, Chainlink。 Alchemy 把区块链的底层架构进行梳理,可以提供典型的 JSON-RPC API,还可以提供增强型的 API,将日常请求简单化,简化开发人员的成本等。Alchemy 对许多知名项目也进行了支持,比如 CryptoKitties, Formatic, Bancor, Celer。 Infura, Alchemy 和 Quicknode 均各自有一些知名用户:  处在这一赛道的还有 Crypto API,Blockchair,Blockdaemon 等。 查询索引服务层 数据服务再往上进一层就是应用类的服务,比如 Dune Analytics。区块链的数据虽然是公开透明的,但是缺乏工具的情况下,数据都是杂乱的,需要编写各类脚本来访问区块,遍历信息等,然后再进行格式化。 Dune 先把区块链上的数据(主要是以太坊)进行解析,然后填充到数据库中,变成一个 PostgreSQQL 的数据库。用户无需写脚本,只要会使用简单的 SQL 语句就可以进行查询。Dune 起了一层将数据进行解析和格式化的作用,还提供了可视化工具。以太坊是键值数据库,Dune 把它变成一个关系型数据库,SQL 语句就是关系型数据库的接口。Dune 提供的数据表有: 原始交易数据,提供区块链上所有活动的详细记录项目级数据表,返回预处理后数据,用于解码的项目抽象表,一种更高级的表,返回相关行业 / 主题的聚合数据。目前支持 Ethereum 和 xDai (以太坊的测链)两个链。以太坊的原始数据包括 Block,Log,Transaction,Trace 等四大类数据,Dune 把他们解码成 human readable 的格式。 The Graph 提供了一个数据的搜索引擎,借助于 GraphQL API,用户可以通过 subgraph (子图)直接访问获得信息。而且 The Graph 是去中心化的,受到很多 DeFi 项目的支持。其也提供一些列成型的 subgraph (类似于 Dune Analytics 用户的 query 或者 dashboard),供代码能力一般的用户直接使用。 数据查询的流程遵循以下步骤 : Dapp 通过智能合约上的交易将数据添加到以太坊。Graph Node 持续扫描以太坊的新块和它们可能包含的子图数据。Graph Node 在这些块中为子图查找以太坊事件,并运行映射处理程序。(映射是一个 WASM 模块,用于创建或更新 Graph Node 存储的数据实体,以响应以太坊事件。)去中心化的应用程序使用节点的 GraphQL 端点向 Graph Node 查询从区块链索引的数据。Graph Node 反过来将 GraphQL 查询转换为对其底层数据存储的查询,以便获取该数据,并利用存储的索引功能。Dapp 将这些数据显示在终端用户的前端中。用户通过前端进行交易活动。由于是去中心化的模式,The Graph 设计了 GRT 代币机制,以鼓励多方参与这个网络,涉及到委托人(Delegator)、索引者(Indexer)、策展人(Curator)、开发者(Developer)等四类。简要而言就是用户提出查询需求,索引者运行 The Graph 节点,委托人向索引者质押 GRT 代币,策展人使用 GRT 来指引哪类子图有查询价值。 快速和节约资源:The Graph 的价值在于,他可以非常快速的用数据回答很具象的问题。他们举了个例子:对于 CryptoKitties, 可以查询在 2018 月之间 1 月到 2 月诞生的 Kitties 的所有者是谁的问题,这就需要遍历智能合约的 birth 事件,以及 ownof 方法。这样一个问题可能需要几天时间才可以。The Graph 的子图就是解决这些问题的索引。 类似于 The Graph 的项目还有 Covalent,提供了一个数据查询层,让工程师可以快速的以 API 的形式调用数据。一个简单的 API 就可以解决所有 Covalent 支持的链的数据。Covalent 的数据集比较完备,可以多链多项目的一起查询,不需要很强的 coding 基础。Covalent 也有自己的代币 CQT,代币持有者可以用来抵押、投票(数据库上新)。Covalent 有两类 endpoints,一类是区块链全体数据类型,如余额、交易、日志类型等;另一类是对某一个协议的 endpoint,如查询 AAVE 的日志。Covalent 最有特点的是跨多链查询,不想需要重新建立类似子图的索引,二是通过改变 chain ID 就可以实现,query 的可扩展性大大增强了。 SubQuery 是专注于波卡生态的数据提供方,可以转换和查询 Web3.0 生态数据。SubQueary 受到 The Graphh 启发,也是使用的 Facebook 开发的 graphQL 语言。SubQuery 面向所有的 Polkadot 和 Substrate,并且提供一个开源 SDK。相对于 The Graph, 作为开放市场的 SubQuery 中的角色有三个:消费者、索引这和委托人。消费者发布任务,索引这提供数据,委托将空闲的 SQT 代币委托给索引者,激励他们更多的诚实参与工作。代币经济学和 The Graph 类似。 如前所述 Blocknative 专注于实时交易数据的检索功能,提供了 mempool 的数据浏览器。最大的特点是突出了实时性,可以追踪交易相关的相应字段的结果,比如地址的追踪,内部交易的追踪,未成功交易的信息,被替换交易的信息比如被加速或者取消。 主要的产品有:mempool 浏览器、网站 SDK、Gas 平台和模拟平台 Mem 浏览器,通过 API 形式的可以订阅 mempool,可以精确到任何一一个协议中,比如 UniswapV3, Sushiswap 的相关交易在 mempool 里面的表现Gas 平台,通过实时 mempool 数据来预测 gasfee 的工具模拟平台功能,模拟 mempool 中检测可被执行的事务,并根据当前块高度对它们进行模拟,以显示它们的效果。只要符合 Blocknative 检测规则的交易进行模拟SDK 平台,各类网站可以通过 javascript 挂接 Blocknative 的 API,来显示该网站产品的交易执行情况Blocknative 是专门针对 mempool 进行侦测的数据网站,因为 mempool 的数据和最终区块数据不会一致,其及时性和其他数据 indexing 比要求跟高。以太坊有一套复杂的系统来管理 mempool 中的交易,Blocknative 提供的字段查询更加即时和精确。 数据分析层 这一层主要是提供一整套链上或者链下的数据集或 API,方便于交易员进行分析。 链上和链下数据:链上数据的提供者直有很细分的 raw data,但对于非专业的认识不需要,其实很多用户需要的颗粒度并不是很高。这样的选手包括 Coinmetics,Nomics,Glassnode,intotheBlock, CryptoQuant 等。他们本身会拆分每一笔交易,但是提供的产品是一种交易的集合。还有一类是交易所数据的包括:Skew,Kaiko,CoinAPI。他们把各类交易所的交易数据进行集合,打包提供给交易者。包括最近崛起的 Nansen,将标签的精细度加深,这也代表深颗粒度 / 面向特定领域的数据受到重视。 业务很传统:这些服务商体量都不大,经过几年的竞争,上面提到的这些名字已经初步跑出。他们基本都是中心化的项目,估值在几千万美元(市场的需求还没有完全起来)。业务逻辑容易理解,有传统的可比标的,数据合规做得好是很好的收购标的。 交易所也自然的参与其中:除了集中式的 API 供应,交易所本身也提供大量的数据。这部分是中心化交易所私有的,交易所把这部分数据半免费开放给外部,这属于整个区块链里最有价值的一类。对于 trader 来讲,orderbook 和成交量比较有用,orderbook 类似以太坊的内存池数据。而还有一类就是交易所钱包和链上交互的数据,代表了一定的得市场氛围。 数据的合规性还未受到重视:合规是很多服务商较少充实的层面,不仅公司合规,数据也要合规。Kaiko 的数据广度好,而且颗粒度精细,拥有把一整套数据进行标准化的方法,满足传统机构投资人的合规要求,并符合 FIGI (Financial Instruments Global Identifier?)标准,是认证的 FIGI 服务商。在未来机构进场的趋势下是一个很大的优势。 除此以外,还有各类 DeFi 分析面板如 Defi Pulse、Dfilima、DeBank 等,都提供各自擅长的数据集。 数据服务商的价值提升仍然有很大空间可靠性的提升 区块链数据越来越多是一个不可避免的趋势。但只有对数据进行分析,得出可操作的见解,才能利用数据的真正价值。区块链技术在数据分析领域扮演着两个截然不同的角色。首先,存储在区块链和区块链网络中的数据本身提供了丰富的信息来源。第二,通过在数据和派生分析模型中添加保证元素,区块链可以使可信的数据分析环境用于多方数据共享。 虽然规模在增加,但是数据质量还没有受到重视,数据质量即代表数据可用性的问题,数据质量需有以下标准: 一致性-数据没有矛盾且一致。可追溯性-数据可审计,变动可追踪可用性-能够被授权用户和应用程序进行检索。合规性-数据符合标准、惯例或一些已经执行的规定机密性-数据只能被授权用户访问可信度-用户相信数据的真实性区块链的数据就有很好的一致性、可追溯性、可用性,但是缺乏合规性、一定的私密性和可信性,尤其是面对监管的时候。用户相信一些数据,还是需要对方数据交叉验证,自己去链上数据交叉验证并不容易。这是未来需要解决的。 用户数据从里层走向表层 用户数和用户行为的爆发还有一个潜在结果,就是当这个级别开始逐渐接近互联网级别的时候,一些传统的数据挖掘方法就开始体现出价值。Web3.0 上依然可以提供类似 Web2.0 的服务,而有些数据虽然是公开的,但却是只能被部分公司 access 到,者给予对用户行为分析和打标签的能力。一个比较大的 gap 是,现在用户的 Web2.0 和 Web3.0 身份还没有对应上,比如很多项目的用户,也非常积极的在 Discord 里面交流,他们和 Web3.0 的身份没有对应,这里面其实也会让很多机会。像 Nansen 就是把海量的钱包进行打标签,为数据用户提供真实的链上行为分析,尤其是可以看到那些巨鲸的活动。像 Nansen 这样的,未来针对用户数据的再挖掘,会让数据服务上的(服务)再上一个新台阶,比如 Zerion、Zapper、InstaDapp 这样的 DeFi 聚合层,也是可以很好发掘用户数据的平台。Covalent 也提供了对钱包的查询功能。 价值的体现 数据的可靠性是一方面(客观),价值捕获依靠的是可用性(客观)和认可(主观)。数据变得有值钱我们可以从这类项目的融资可以看出,2021 年是数据真正开始体现价值的一年,以上提及的项目今年发生了多次融资: 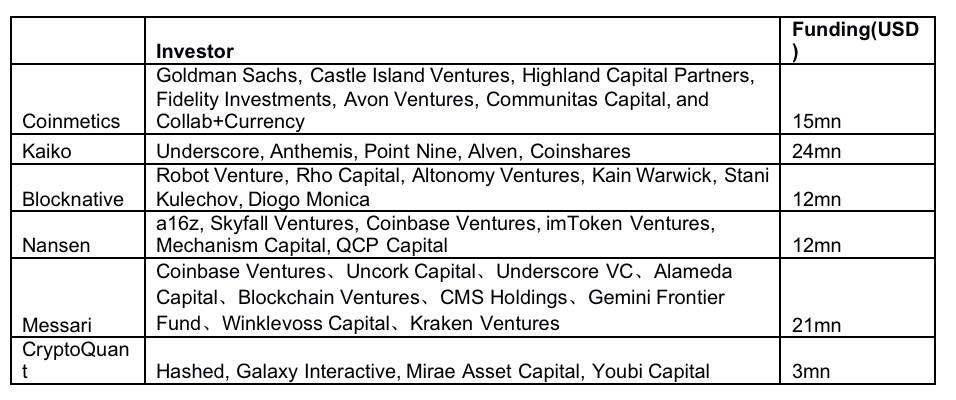 Skew 和 Zabo 直接被 Coinbase 收购,传统领域的资金也在参与。随着多链时代的开启,数据量会成倍的增加。多链时代对行业是个考验,但对于数据公司来说,则打开了宝藏之门。The Graph 提供的统计显示,2020 年 6 月,每天只有 3000 万的 query,到了 2021 年的 6 月份,每天的 query 达到了 6.75 亿。 未来数据市场的驱动力主要有四个:多链宇宙(含 Layer2)的成型, 应用的增加和用户的增加,应用带来的数据需求的增加(如开发、分析、交易、金融产品的使用等),用户行为复杂化。但是数据状态也不会爆炸下去,也会经过一波整合,和 Gartner 发展曲线类似。 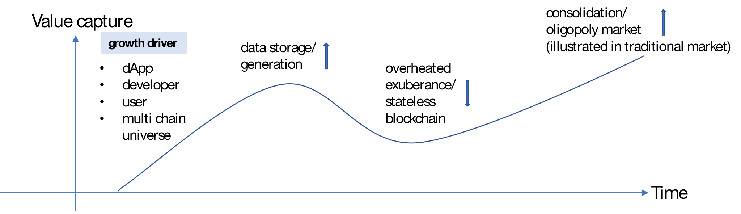
—- 编译者/作者:Hashkey Capital 玩币族申明:玩币族作为开放的资讯翻译/分享平台,所提供的所有资讯仅代表作者个人观点,与玩币族平台立场无关,且不构成任何投资理财建议。文章版权归原作者所有。 |
深入解读区块链数据行业:如何产生价值和捕获价值?
2021-08-10 Hashkey Capital 来源:区块链网络
LOADING...
相关阅读:
- CloudRush—助力区块链新发展2021-08-10
- 觅新|SpacePoggers:为以太坊添把“火”2021-08-10
- IOST主网OlympusV3.7.0版本正式上线2021-08-10
- XRP 诉讼:Ripple 在 SEC 的紧急动议后要求延期2021-08-10
- 引领未来潮流投资量化领头2021-08-10