来源:量子位 没想到时至今日,ChatGPT竟还会犯低级错误? 吴恩达大神最新开课就指出来了: ChatGPT不会反转单词!比如让它反转下lollipop这个词,输出是pilollol,完全混乱。  哦豁,这确实有点大跌眼镜啊。 以至于听课网友在Reddit上发帖后,立马引来大量围观,帖子热度火速冲到6k。 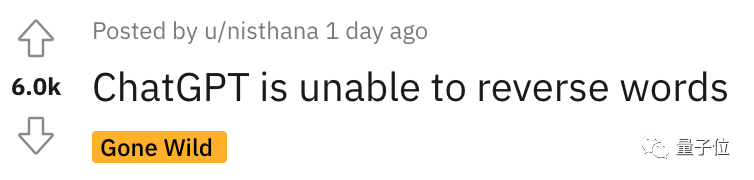 而且这不是偶然bug,网友们发现ChatGPT确实无法完成这个任务,我们亲测结果也同样如此。  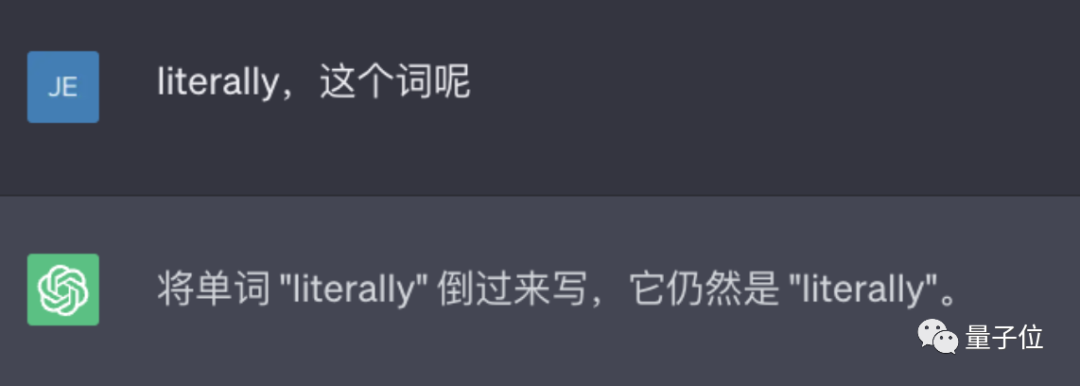 △实测ChatGPT(GPT-3.5) 甚至包括Bard、Bing、文心一言在内等一众产品都不行。 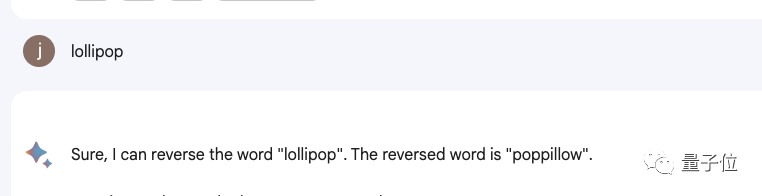 △实测Bard  △实测文心一言 还有人紧跟着吐槽, ChatGPT在处理这些简单的单词任务就是很糟糕。 比如玩此前曾爆火的文字游戏Wordle简直就是一场灾难,从来没有做对过。 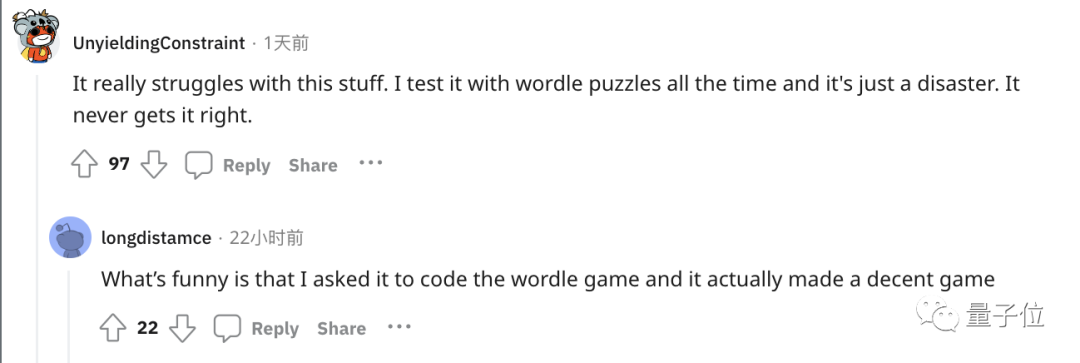 诶?这到底是为啥? 关键在于token之所以有这样的现象,关键在于token。token是文本中最常见的字符序列,而大模型都是用token来处理文本。 它可以是整个单词,也可以是单词一个片段。大模型了解这些token之间的统计关系,并且擅长生成下一个token。 因此在处理单词反转这个小任务时,它可能只是将每个token翻转过来,而不是字母。  这点放在中文语境下体现就更为明显:一个词是一个token,也可能是一个字是一个token。  针对开头的例子,有人尝试理解了下ChatGPT的推理过程。 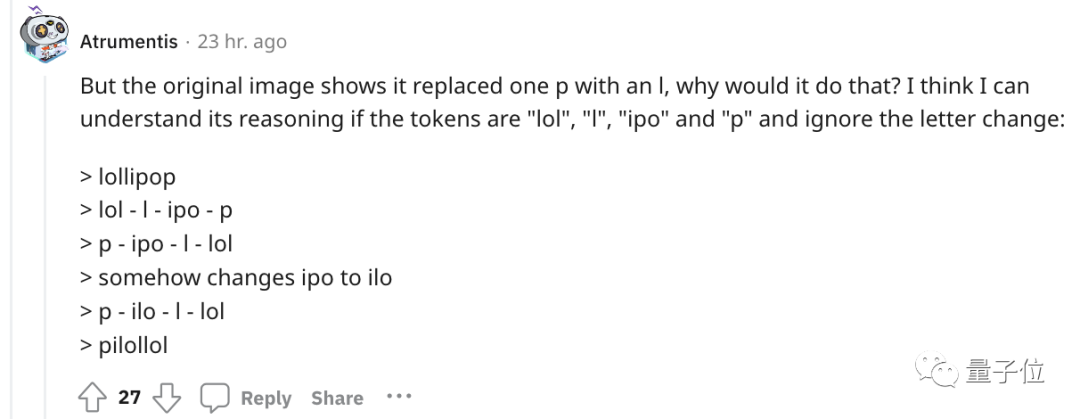 为了更直观的了解,OpenAI甚至还出了个GPT-3的Tokenizer。 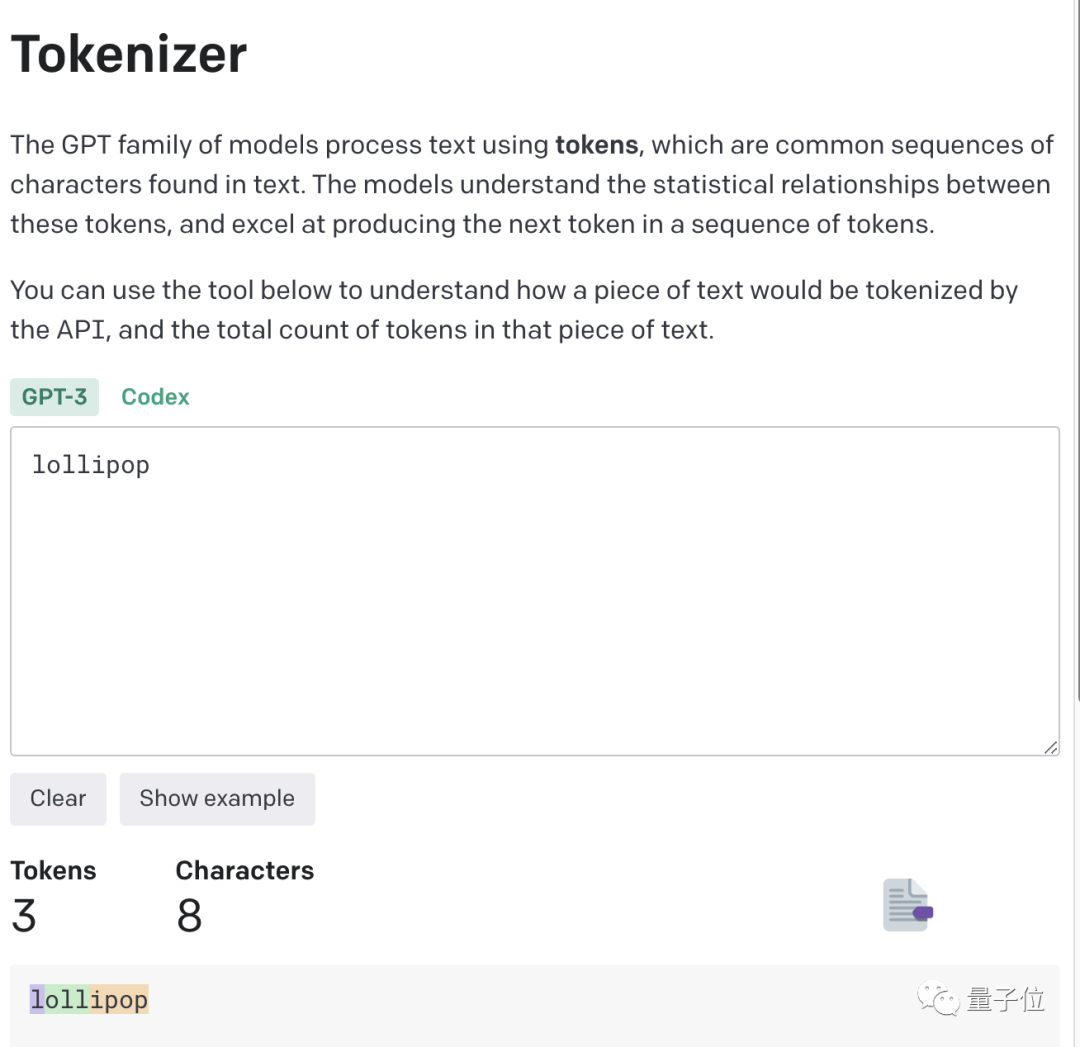 比如像lollipop这个词,GPT-3会将其理解成I、oll、ipop这三个部分。 根据经验总结,也就诞生出这样一些不成文法则。 1个token≈4个英文字符≈四分之三个词;100个token≈75个单词;1-2句话≈30个token;一段话≈100个token,1500个单词≈2048个token;单词如何划分还取决于语言。此前有人统计过,中文要用的token数是英文数量的1.2到2.7倍。 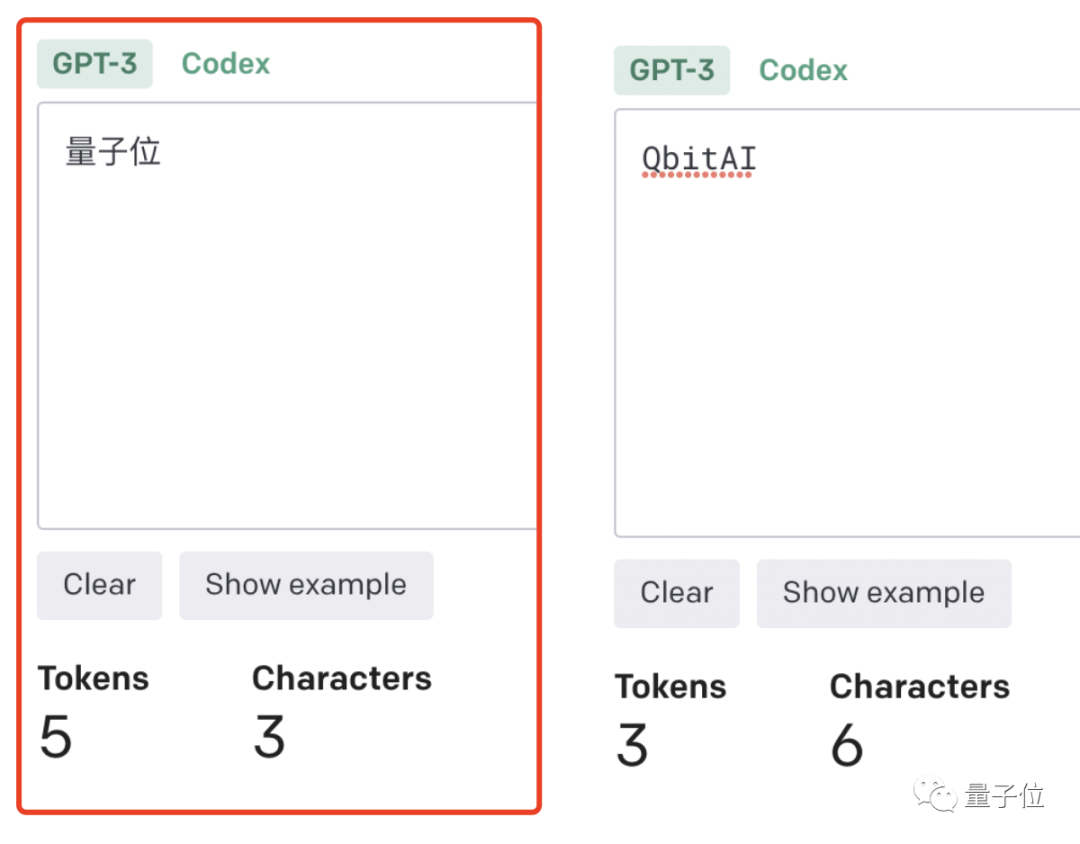 token-to-char(token到单词)比例越高,处理成本也就越高。因此处理中文tokenize要比英文更贵。 可以这样理解,token是大模型认识理解人类现实世界的方式。它非常简单,还能大大降低内存和时间复杂度。 但将单词token化存在一个问题,就会使模型很难学习到有意义的输入表示,最直观的表示就是不能理解单词的含义。 当时Transformers有做过相应优化,比如一个复杂、不常见的单词分为一个有意义的token和一个独立token。 就像annoyingly就被分成“annoying”和“ly”,前者保留了其语义,后者则是频繁出现。 这也成就了如今ChatGPT及其他大模型产品的惊艳效果,能很好地理解人类的语言。 至于无法处理单词反转这样一个小任务,自然也有解决之道。 最简单直接的,就是你先自己把单词给分开喽~  或者也可以让ChatGPT一步一步来,先tokenize每个字母。  又或者让它写一个反转字母的程序,然后程序的结果对了。(狗头)  不过也可以使用GPT-4,实测没有这样的问题。  △实测GPT-4 总之,token就是AI理解自然语言的基石。 而作为AI理解人类自然语言的桥梁,token的重要性也越来越明显。 它已经成为AI模型性能优劣的关键决定因素,还是大模型的计费标准。 甚至有了token文学正如前文所言,token能方便模型捕捉到更细粒度的语义信息,如词义、词序、语法结构等。其顺序、位置在序列建模任务(如语言建模、机器翻译、文本生成等)中至关重要。 模型只有在准确了解每个token在序列中的位置和上下文情况,才能更好正确预测内容,给出合理输出。 因此,token的质量、数量对模型效果有直接影响。 今年开始,越来越多大模型发布时,都会着重强调token数量,比如谷歌PaLM 2曝光细节中提到,它训练用到了3.6万亿个token。 以及很多行业内大佬也纷纷表示,token真的很关键! 今年从特斯拉跳槽到OpenAI的AI科学家安德烈·卡帕斯(Andrej Karpathy)就曾在演讲中表示: 更多token能让模型更好思考。 而且他强调,模型的性能并不只由参数规模来决定。 比如LLaMA的参数规模远小于GPT-3(65B vs 175B),但由于它用更多token进行训练(1.4T vs 300B),所以LLaMA更强大。 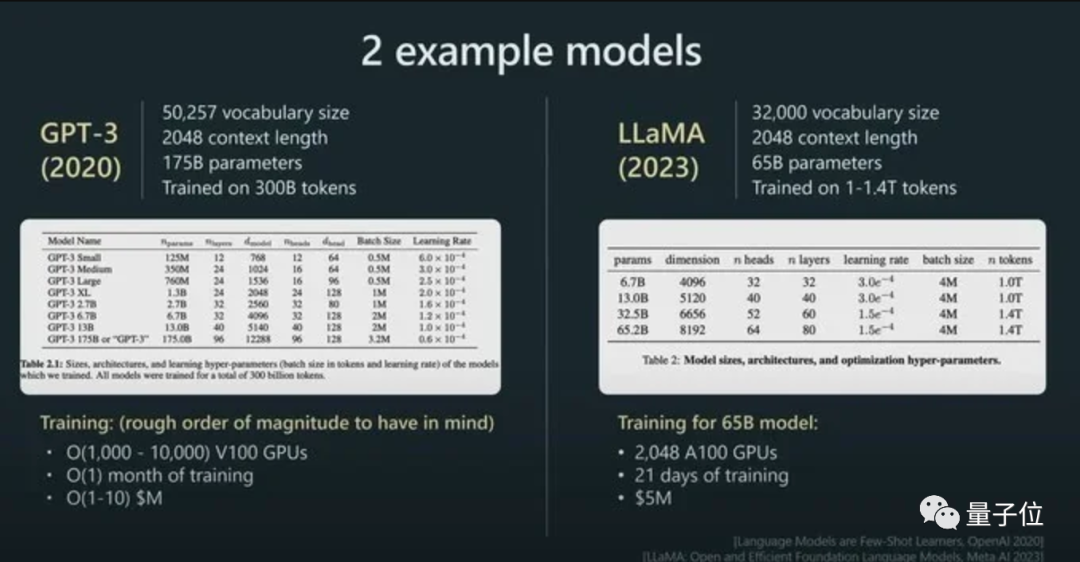 而凭借着对模型性能的直接影响,token还是AI模型的计费标准。 以OpenAI的定价标准为例,他们以1K个token为单位进行计费,不同模型、不同类型的token价格不同。 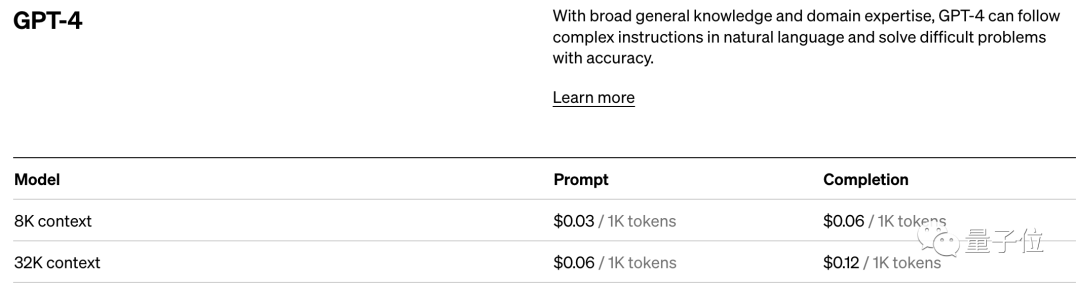 总之,踏进AI大模型领域的大门后,就会发现token是绕不开的知识点。 嗯,甚至衍生出了token文学……  不过值得一提的是,token在中文世界里到底该翻译成啥,现在还没有完全定下来。 直译“令牌”总是有点怪怪的。 GPT-4觉得叫“词元”或“标记”比较好,你觉得呢?  参考链接:[1]https://www.reddit.com/r/ChatGPT/comments/13xxehx/chatgpt_is_unable_to_reverse_words/[2]https://help.openai.com/en/articles/4936856-what-are-tokens-and-how-to-count-them[3]https://openai.com/pricing —- 编译者/作者:AI梦工厂 玩币族申明:玩币族作为开放的资讯翻译/分享平台,所提供的所有资讯仅代表作者个人观点,与玩币族平台立场无关,且不构成任何投资理财建议。文章版权归原作者所有。 |
吴恩达ChatGPT课爆火:AI放弃了倒写单词,但理解了整个世界
2023-06-04 AI梦工厂 来源:区块链网络
LOADING...
相关阅读:
- 姚橙:中国与海外在大模型层面的差距并不大,关键在于底层硬件能力2023-06-04
- 大模型创业潮:狂飙 180 天2023-06-04
- AI领域“语言霸权”?语言差异或成本土人工智能发展关键动力2023-06-04
- 罗斯柴尔德资管公司部分获利了结英伟达持仓,并称“AI 估值太高”2023-06-03
- 首周下载量碾压ChatGPT!谷歌20年老员工叛逃,创立第二个OpenAI?2023-06-03