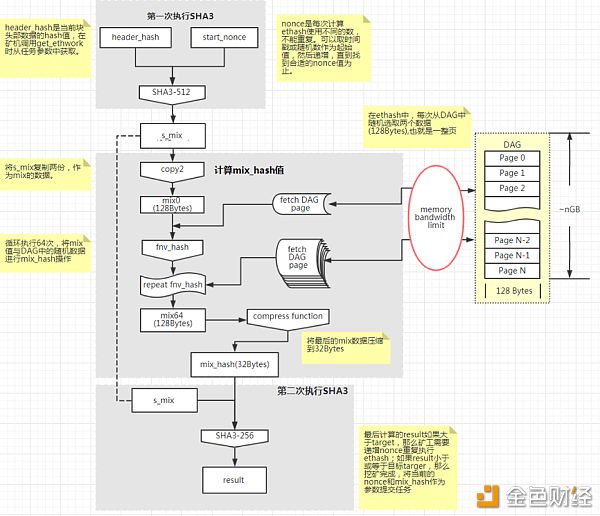
原本计划要在伊斯坦布尔硬分叉中实施的ProgPow终于又有消息了,但是什么时候升级仍然悬而未决。 据CryptoBriefing报道,以太坊核心开发者正在推进ProgPoW,暂定在7月进行硬分叉升级。自从矿机制造商比特大路和芯动科技分别于2018年4月和7月发布专用集成电路(ASIC)的以太坊ASIC矿机E3和A10以来,为避免专业ASIC矿机制造商垄断以太坊算力,保护以太坊网络的去中心化和网络安全,以太坊社区在过去两年中一直在讨论将以太坊算法转换为ProgPoW的问题。新算法可以使以太坊挖矿具有抗ASIC性。 但是,最新消息是,硬分叉协调员James Hancock谈到ProgPoW是否应该跟 EIP-1962放到同一次分叉中,但是以太坊社区核心人员如Spankchain的Ameen Soleimani、Gnosis的MartinK?ppelmann、Uniswap的Hayden Adams、ConsenSys的Igor Lilic以及众多以太坊开发人员表示反对ProgPoW。也就是说,以太坊核心开发者并未就ProgPoW达成一致意见,也没有暂定硬分叉的时间。 那么ProgPoW到底是个啥?ProgPoW何以能缩小GPU挖矿与ASIC之间的差距? ProgPoW主要是根据GPU的特性对以太坊的Ethash算法做了修改,缩小GPU与专用ASIC之间的算力差距。 一句话解释,用ProgPoW开发团队IfDefElse的话是:“PoW挖矿,通常是设计硬件让算法更高效。但ProgPoW相反,先有硬件,然后再修改算法来匹配它。” Ethash算法 PoW是一个概念统称,有很多种算法实现。目前以太坊使用的具体PoW算法是Ethash,它是Dagger—Hashimoto算法的变种。 Hashimoto算法采用IO饱和策略来对抗ASIC,使内存读取成为PoW挖矿过程中的限制因素。Dagger算法使用DAG(directed acyclic graphs—有向无环图)来同时实现内存难解和内存易验证两个特点。主要原理是挖矿过程需要存储完整的DAG数据,同时在计算每个nonce时需要抽取DAG中的部分数据。 选取这个算法的结果使得,挖矿计算性能的瓶颈在于内存大小和内存带宽,而和哈希计算能力关系不大。比如NVIDIA GTX1070执行Ethash时,内存在达到88.3%的利用时,作为显卡计算核心的SM(streaming multiprocessor)只有27.7%的利用率。 同时使得通过大规模部署共享内存的ASIC矿机并不能带来在挖矿效率上同比例线性增长。 Ethash算法的一般流程如下: 1、首先根据块信息计算一个种子; 2、使用这个种子,计算出一个16MB的cache数据。 3、通过cache,计算出一个1GB(初始大小)的数据集(DAG),DAG可以理解为是一个完整的搜索空间,全客户端和矿工需要存储完整的DAG, 4、挖矿:需要从DAG中重复随机抽取64次数据拿去和其他数据计算mixhash(如下图)
在早期Ethereum和Solidity智能合约代码中,Keccak和SHA3是同义词。在2015年8月NIST标准化SHA3后,标准的SHA3和Keccak算法有所区别。为了避免和NIST标准的SHA3混淆,现在的代码直接使用Keccak作为函数名。 每次Ethash从DAG中随机取64128 bit=8192 Bytes数据。以GTX 1070显卡为例,带宽为256GB/s,那么每秒能承受256*1024*1024*1024/8192=33554432次Ethash运算,即33MH/s算力。 针对Ethash的专用ASIC 可以根据需要执行的命令量身定制专用硬件来解决,比如在Ethash开始和结束时调用的哈希函数Keccak在ASIC上可以更有效执行。 针对Ethash,专用ASIC大致可以采用三个专用功能来提高计算性能: 一个从DAG导入数据的高带宽内存接口(一般来说是GDDR6或者HBM2) 一个用于Keccak哈希计算的keccak引擎; 一个用于执行内部循环FNV和地址模运算的小型计算核心; 由此专门定制的ASIC将比现有GPU体积更小且能耗更低。高配置(GDDR6或者HBM2)的以太坊ASIC矿机可以达到GPU矿机挖矿性能的2倍。 事实上,大矿机商都曾推出过以太坊ASIC矿机。2018年4月比特大陆推出以太坊ASIC矿机E3,芯动科技2018年7月发布以太坊ASIC矿机A10。但因为以太坊社区抵制,威胁可能会修改算法,同时还有部分技术原因,比如比特大陆的E3因为采用的是DDR3内存,ASIC矿机相比GPU并没有多少算力优势。因此,以太坊ASIC矿机并没有得到大规模采用。 ProgPoW做了哪些改变 ProgPoW,是Programmatic Proof-of-Work的缩写。正如IfDefElse所说,为匹配现行主流GPU的硬件特征,ProgPoW算法主要做了如下改进: 1、把keccak_f1600(64字节的字)改成keccak_f800(32字节的字)。32字节是目前主流GPU一次操作处理的实际位数。 2、在主循环环节增加了数学随机序列。目前GPU计算核心内有着大量暂存器,可为高吞吐量可编程数学单元提供信号。Ethash的内部循环先是DAG载入,然后用FNV将数据合并为小的混合状态。ProgPoW添加了一系列随机数学指令和随机缓存读取,进而合并为更大的混合状态。 3、DAG数据读取大小从128 byte增加到256 byte。当前主流GPU DRAM均为32位(32*8=256 byte),这样ProgPoW可以在当前DRAM设备上更有效率地执行; 4、GPU具有少量高速暂存器内存,允许快速处理访问随机地址,ProgPoW也利用了GPU这一特性。 其中迭代运算次数即访问DAG次数保持不变,与Ethash一样仍是64次。 经过优化后,ProgPoW能大幅提高GPU计算能力。Nvidia GTX1070运行ProgPoW测试结果表明,在内存利用率达到87.55%时,GPU计算核心的SM(streaming multiprocessor)利用率能达到87.95%。 ProgPoW大幅缩小了ASIC和GPU间的性能差距 理论上,还是可以制造出专门用于执行ProgPoW的ASIC的。但这种ASIC不仅需要高带宽内存接口和小型Keccak+KISS99引擎;还需要具有大型寄存器、大量随机数学能力的计算核心;高吞吐量、低延迟、大存储的缓存。 造成的实际后果是这种专用ASIC会和与现有GPU的性能非常相似。经过优化后的ASIC计算性能将只有目前GPU的1.1-1.2倍,大幅缩小ASIC和GPU之间的性能差距。 考虑到研发ASIC的巨额成本以及以太坊社区的抵制,研发以太坊ASIC极低的性价比也会让矿机商主动远离以太坊。 事实上,要不要抵制ASIC本身也存在争议。因为在有些人眼里,GPU也是某种形式的ASIC。 —- 编译者/作者:金色财经 Maxwell 玩币族申明:玩币族作为开放的资讯翻译/分享平台,所提供的所有资讯仅代表作者个人观点,与玩币族平台立场无关,且不构成任何投资理财建议。文章版权归原作者所有。 |
金色观察|以太坊ProgPoW升级再度无望?一文读懂ProgPoW
2020-02-25 金色财经 Maxwell 来源:区块链网络
LOADING...
相关阅读:
- M2Pro矿机订购:芯域矿池超级节点助力新基建(附二维码)2020-08-01
- 体验了DFS,说实在的没弄明白2020-08-01
- MXC极域M2Pro网关矿机安装指南和注意事项2020-08-01
- Filecoin挖矿指南之设备性能对证明计算的影响2020-08-01
- Filecoin挖矿指南之系统的证明机制2020-08-01