| 本文详细说明了路印协议在zkSNARK证明生成上的一些优化措施,我们成功地将生成零知识证明的成本降低为每笔交易仅0.03分RMB(100万笔交易成本大约300RMB),与目前我们线上的版本相比,成本降低了15倍。再加上其他一些优化手段,最终路印协议每笔撮合交易总成本仅仅只需0.09分RMB(100万笔交易成本大约900RMB)。 生成零知识证明需要超大量的内存,大约每100万个门限制电路就要5GB内存。对我们路印协议来说,最大1024笔撮合交易的电路就会需要6400万个门限制,这意味着需要一个超级强劲超大内存的服务器才能生成出证明。 如果不做优化的话,基本就意味着不太可能实际使用,因此我们决定去优化libsnark库。我们尝试了很多种优化方法,有大有小,最终取得的成果还是挺不错的。因此我们很高兴的在这分享给大家,希望能对大家有些帮助。话不多说,我们先来看最终效果! 优化结果 我们现在只用少于1GB的内存,就可以同时处理100万个门限制电路,而且能达到一个CPU核每秒为4万个门限制电路生成证明的效果。一笔基于zkRollup的转账大约需要3万个门限制,一笔基于路印协议的交易需要约6万个门限制,因此,一个16核的CPU每秒就能处理20笔转账或者10笔交易。 比如,现在只要用55GB的内存,16核的CPU就可以在104秒内生成一个有6400万个门限制电路的证明(路印协议所设计的最大容纳1024笔交易的电路)。也就是,只需要消费者级别的电脑,就可以每秒为635,000个门限制电路生成证明,而1台16核CPU加64GB内存的电脑也就大约7000RMB。这也就意味着购买一些普通机器来生成电路证明具有可行性,这种方式非常适用于我们路印去中心化交易所,应该也能适用于任何基于零知识证明的去中心化解决方案。 当然,使用云计算也是另外一种可选项。在AWS上我们就可以用每小时10.5RMB的价格租一台c5.9xlarge型号专门适用于计算的云机器(18核CPU和72GB内存),同时我们发现租用m5型号云机器也能达到同样的性能表现。这台c5.9xlarge云机器就可以每小时为35,000笔交易生成零知识证明,换算下来也就是1笔交易仅花费0.03分RMB(100万笔交易也就300RMB)。正如路印协议的设计文档[7]所解释的,每笔交易的链上成本最低可以到375个GAS,如果以以太坊1500RMB的价格计算,同时采用1Gwei的GAS价格,那么链上每笔交易成本仅仅为0.06分RMB(100万笔交易也就600RMB)。链上和链下两项成本加起来也就才0.09分RMB(100万笔交易也就900RMB)。
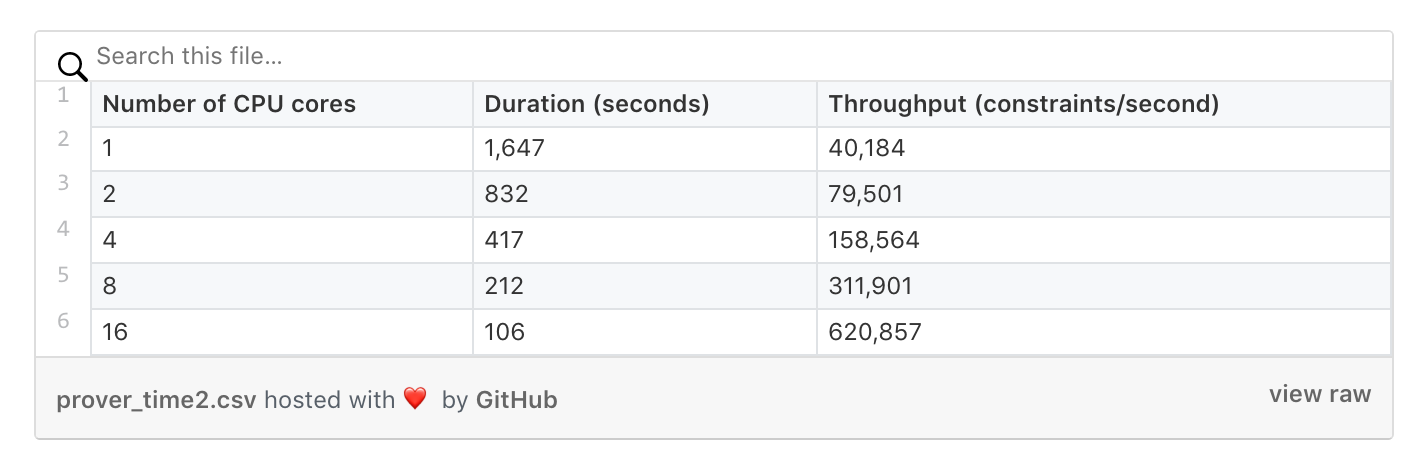
使用AWS生成证明每笔交易成本 就像下图所揭示的,生成证明的性能先是随着CPU核数线性增长,但超过16核之后性能提升就不明显了(我们后续还会进一步研究为什么超过16核就不起作用了)。
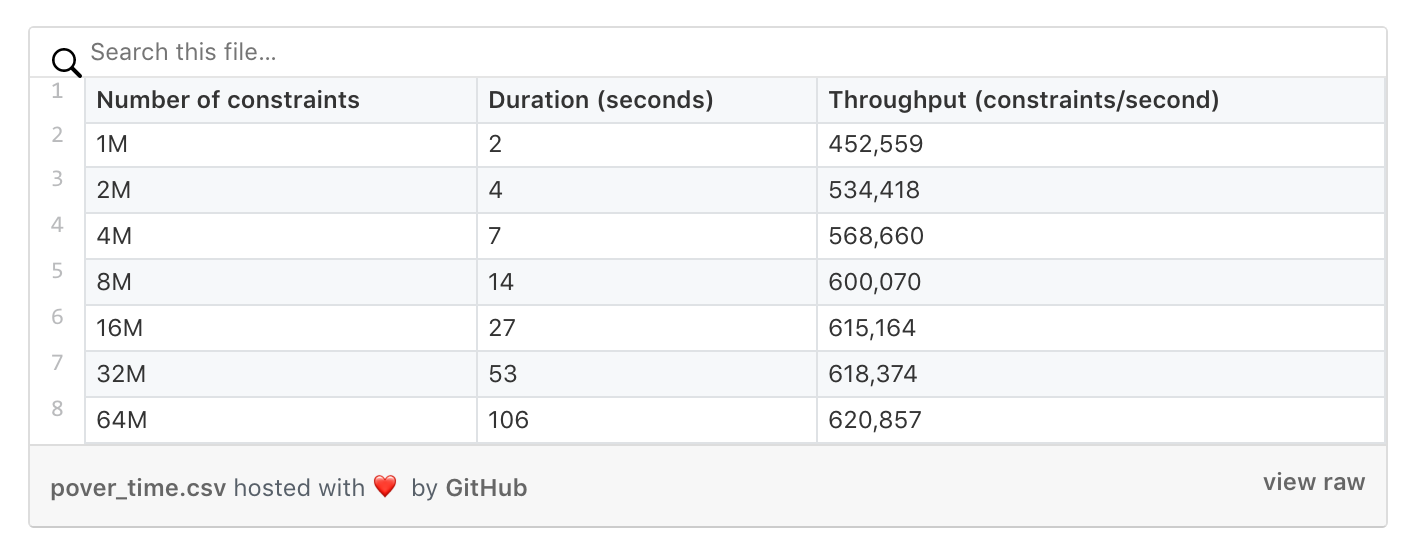
以上数据是在c5.9xlarge云机器上调整CPU的核数而采样得到的,16核下性能数据稍微有点出入,是因为测试时没有打开CPU的超线程功能。 同样地,在处理门限制电路的性能上也呈现出线性增长,这个有一点点奇怪,因为理论上快速傅立叶变换FFT算法复杂度是O(n*log(n)),但实际采样是线性增长的。下面的数据是在c5.9xlarge云机器上采用16核但禁止了CPU超线程功能而测得的。
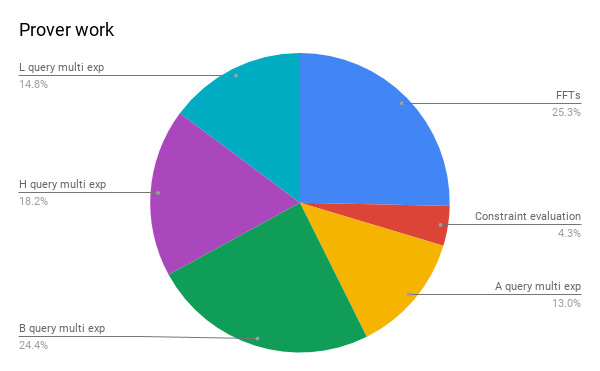
指数运算乘积(multiexp)计算占了生成证明中75%的工作量,下面的饼图显示了具有6400万门限制的电路计算中的工作量占比,更小一点的电路也基本具有同样的占比。
我们没有继续拿未改动过的libsnark和bellman做对比实验。未改动过的libsnark有挺多问题的,和其比对没有意义,但粗略地计算,我们的优化在16核CPU的机器上能达到15倍性能的提升。同时根据一些项目的公开数据表明,和bellman相比,也有4倍性能的提升。在内存消耗上,我们的方案仅仅只是原来的1/5。 举个更有趣也更实际一点的例子,我们来算算如果要在以太坊网络上达到VISA同等级别的性能指标(2000 TPS)的话,会需要多少成本。一笔转账在链上大约消耗200个GAS,根据以上的数据就可以计算得到我们只需要100台16核CPU的机器,以及使用50%左右的以太坊总容量。如果是租用AWS机器的话,使用成本大约是每笔转账0.042分RMB(100万笔转账420RMB)。但如果采用一次性购买全部机器的话,总成本是70万RMB,如果不计算其他运营成本比如电费的话,使用独立机器的成本大约是每笔转账0.028分RMB(100万笔转账280RMB)。 优化细节 基本上生成零知识证明是在执行两种操作:快速傅立叶变换(FFT)和指数运算乘积。之前大部分项目的优化重心也都是放在优化这两种操作上,但是减小内存占用也非常重要(尤其对那些拥有很多门限制的电路来说)。当然,除了优化内存分配,减少不必要的计算也都是需要的。 FFT
FFT算法可能是已被研究的最多的一个算法,因此我们可以利用很多现有的知识去得到一个比较好的实现版本,我们也正是这么去做的。我们提供了一种新的FFT算法的实现版本,它的实现方式和著名的快速FFT库比较接近。尽管这个版本可能还不是那么完美,肯定也还有进一步的优化空间,但是它已经比libsnark里面的实现(和libsnark类似的bellman里面的实现)要更高效些。 零知识证明中FFT算法是作用在域元素上的,每个元素都占用32个字节,这比常规的FFT算法中的浮点数或者整数大多了,因此在其上的操作也都更慢。最开始我们都不太确定常规的快速FFT算法是否能直接应用,但幸运的是,它还是能用的上。 FFT算法本质上是一个递归算法,因此我们的实现采用深度优先的递归算法。之所以选用深度优先,是因为这种方式能最大程度的利用好CPU的缓存机制,从而达到性能最优的效果。 FFT中的旋转因子只需要事先计算一次然后就能被重复使用。两个域元素的乘法是很耗时的操作,如果可能的话就应该尽量重复使用旋转因子。而要把旋转因子放到内存或者缓存中去又会进一步加大内存消耗,因此我们需要把FFT算法划分成不同的阶段,而每个阶段都要尽量保证能在连续的内存中访问使用到的旋转因子,这样的内存排布就很适合CPU缓存预取。 针对目前的划分阶段,我们支持2分法或者4分法。通常来说,越大的分法越好,但是在特定场景下,4分法需要比2分法多一次额外的域乘法操作。因此4分法在大部分场景下是更高效些,但不是所有情况都更好,需要在递归次数和域乘法之间取得一个平衡。我们也很期待在更大的分法下会是什么情况,但到了8分法,事情就已经变得很复杂了。 我们会把树根据CPU核数目拆分成相对应的多棵子树,这样每一个CPU核就只需要采用深度优先去处理一棵子树。每个阶段上我们都会把最顶层的树按这种方式去水平切割。 指数运算乘积 libsnark和bellman库虽然具体的实现方式不太一样,但都是用了Pippenger算法来实现指数运算乘积。 这个算法最基本的一个操作是椭圆曲线加法,因此能快速实现椭圆曲线加法就特别重要,这个是我们所做的最重要也最直观的第一个优化。我们切换到使用MCL库[9]来实现椭圆曲线加法,从而极大地提升性能(这一点上我们要感谢安比实验室,是他们的早期工作让我们想到这个优化点)。 接下来的一个优化是参考bellman的代码在libsnark上采用相对应的实现,通常就是改变下访问数据的方式。但这个改动也带来一些有意思的结果。我们将指数(一个254位的域元素)分成c份,然后用多线程去处理,这样一个线程只需要处理其中的一份。具体拆分成多少份是会直接影响算法效率,同时也会影响到在多核机器上的性能表现。在我们的测试中发现取c=16是最佳的,这个发现也决定了我们最多只需采用16核的CPU。它是恰到好处的一个值,乘以16大于254的数中最小的一个数正好也是16(c*16=256>254)。后面更进一步的优化可以是,在每一份内部再划分成更小的片,从而能利用更多的核,而不用再去调整c的值。但很难预测调整c值和拆分成更小的片,哪种方式能更优。 另外一个bellman实现中比较好的点在于:预先读取特定的一些数据,而这些数据CPU是无法提前预取到缓存中的,因为这个模式完全依赖于数据自身。这个预取动作非常重要,而预取到CPU要用的正确数据也很重要。预取多少数据也是要根据CPU去调整的,这个值可以通过在实际硬件上反复测试得到一个最佳经验值。因此这个值要做成一个可配置项,从而能在不同系统上达到最佳性能表现。另外一个小的优化点是去配置预取的缓存逻辑(配置为1就表现不错)和预取更多的数据(两次循环迭代似乎效果最好)。 内存优化 内存消耗大户有两个:证明钥和电路。电路是最占用内存的,证明钥占用的内存是每100万个门限制小于512MB,相比电路来说,它看起来没那么吃内存。 用一个扁平的列表结构来表示所有的门限制是需要很大内存的。尤其我们路印协议中是用的Poseidon哈希函数,它的门限制个数是最少的,这点很棒;但是它需要用到大量的线性组合,从而需要更多的内存。 一个降低内存消耗最容易的改动点是不要独立的存储系数,转而建立一个能被重复使用的系数池,在门限制中则只存储一个指向实际系数的池子下标。显而易见,存储一个下标(4个字节)要比存储系数(32个字节)更省内存。比如,我们的一个有6400万门限制的电路存储了10亿(你没看错,就是10亿)个系数,而其中只有20569个不同的系数,其他很多系数是重复的。 但是即使我们做了这个优化,门限制扁平的列表结构中仍然还有很多重复数据。在我们的电路结构中大部分门限制是Hash函数,比如Poseidon和SHA256。尽管这些Hash函数被用来处理不同的数据,但在电路中其实就是在不停的重复出现,只是作用于不同的变量而已。为了充分利用这个特征,我们改变了这种简单的扁平结构,尽管表现上仍然是一个列表,但每个门限制可以实现自己特定的逻辑,从而能更加有效的存储在内存中。我们目前为每种门限制只存储一次(放到不同的面包板中),在电路中则直接重复使用已建立好的门限制。而传递给电路的变量则需要在运行时处理一下,转译为指向当前第几个实例的变量。 还是以6400万门限制的电路为例,即使单独为每个门限制存储一个指针(8个字节),也需要512MB内存,因此彻底改变之前用的扁平的列表结构是势在必行的。 还有一些其他零散的小点也都在消耗内存。比如,证明钥有一份完整电路的拷贝,而这个很明显是可以丢弃掉的。libsnark有很多其他的地方也都在重复构造数据,即使数据本身可能只有很小一部分是不同的。 值得注意的是证明钥目前仍然是全部加载到内存中的,而所有的这些改动都可能带来一些微小的影响性能的变化。 其他优化 我们设计了一个生成零知识证明的服务器模式,该模式下会先提前一次性准备好所有必要的数据,这样不需要动态的去搭建电路和加载证明钥,尽管这两步的性能我们也已经有一些优化手段。 我们删除了一些groth16协议中和零知识相关的计算部分,因为我们路印协议主要把zkSnark用于链下扩容,所以这些相关的计算是无关紧要的(这里要特别感谢Kobi Gurkan帮我们指出这一点)。 我们删除在证明函数中几乎所有的内存分配,因为动态分配内存也是很慢的,我们可以采用更快的提前分配内存的方法来改进这一点。 我们在libsnark里面采用了更多的并行化,有些耗时久的函数之前没有充分利用多核性能。 我们现在支持给不同的硬件机器配置不同的参数,尽管默认的值可能已经工作的挺好了,但最好还是特定机器采用专门针对该机器调整过的一套最优参数。如果最终决定用一台机器来不停的生成证明的话,我们给出的建议是最好要自己花些时间去调优到最佳参数。我们实现了测评模式,在该模式下,你就很容易地能比对不同参数配置下的性能数据,从而找出针对特定机器的最优参数配置。 结论 我们对目前优化的效果很满意,但毋庸置疑还能更进一步的提升。采用最新的证明生成优化方案,链下计算部分的成本已经极大地降低了,目前只占到总成本的1/3了。更快地生成证明也就意味着,任何的状态更新也都能更快地被在链上确认,这也能降低在Layer1做聚合zkRollup[10]的成本。同时我们也很期待groth16的进一步发展,能带来比其他零知识证明协议更高的性价比。 目前的方案都是100%基于CPU的,而我们也尝试过用GPU去加速证明的生成,有些其他项目也在用GPU做加速。但是GPU加速更困难一些,尤其考虑到云计算上,租用GPU的机器普遍都价格很贵。我们觉得可能用多CPU并行会比用GPU来加速更节约成本一些。 我们希望这些优化手段也能给其他运用零知识证明的项目带来一些帮助,尽管我们是在groth16的libsnark实现版本基础上做的优化,但是其核心优化思想应该也能运用到其他零知识证明的实现框架上。我们所有的优化代码都已开源,如果你有任何优化的想法或者疑问的话,欢迎随时联系我们!你能在下面一些项目上找到这些优化: https://github.com/Loopring/libfqfft/tree/opthttps://github.com/Loopring/libff/tree/opthttps://github.com/Loopring/libsnark/tree/opthttps://github.com/Loopring/ethsnarks/tree/opthttps://github.com/Loopring/protocol3-circuits/tree/opt 路印交易所 路印协议已上线公测版本,大家可以去https://loopring.io体验。如果一切顺利的话,我们会在2个月内把我们做的优化方案更新到线上运行。 路印交易所是一个高性能、非托管、基于订单模式的以太坊上的去中心化交易所,欢迎关注我们的微信公众号路印 Loopring,访问我们的官网https://loopring.org,或者直接去https://loopring.io体验。 相关链接 [1]https://medium.com/loopring-protocol/zksnark-prover-optimizations-3e9a3e5578c0 [2]https://medium.com/loopring-protocol/loopring-testing-phase-1->[3]https://loopring.io/ [4]https://github.com/HarryR/ethsnarks [5]https://github.com/scipr-lab/libsnark [6]https://github.com/matter-labs/bellman [7]https://github.com/Loopring/protocols/blob/master/packages/loopring_v3/DESIGN.md [8]https://en.wikipedia.org/wiki/Fast_Fourier_transform [9]https://github.com/herumi/mcl [10]https://medium.com/loopring-protocol/composability-between-ethereum-layer-1-and-2-10650b7411e5 访问下方链接关注更多内容 推特:https://twitter.com/loopringorg Reddit:https://www.reddit.com/r/loopringorg 中文电报:https://t.me/loopringfans 长按关注  —- 编译者/作者:路印协议 玩币族申明:玩币族作为开放的资讯翻译/分享平台,所提供的所有资讯仅代表作者个人观点,与玩币族平台立场无关,且不构成任何投资理财建议。文章版权归原作者所有。 |
重大突破:路印协议将交易成本再降15倍!
2020-03-05 路印协议 来源:区块链网络


LOADING...
相关阅读:
- 门罗币价格逼近100美元的关键阻力位2020-07-31
- 抑制2019年比特币公牛的意外因素现在消失了2020-07-31
- V神演讲内容曝光Defi挖矿行业应用更多主题大揭秘2020-07-31
- 分布式金融支柱的DIA了解一下?2020-07-31
- 点亮红海上的灯塔霍比特携手殿堂级预言机NEST开启DeFi新航路2020-07-31