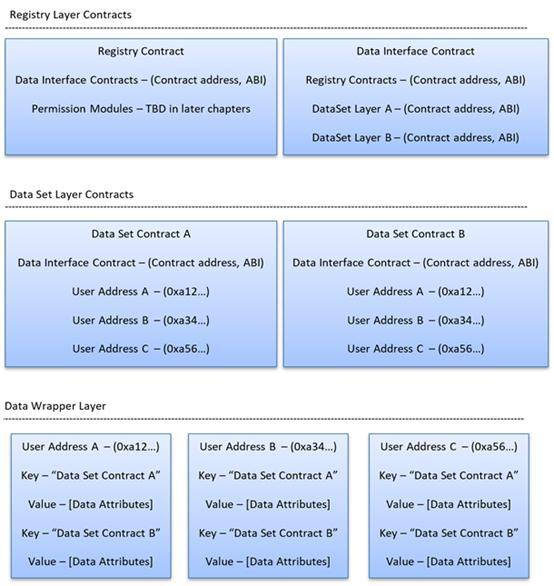
原文标题:《释放数据经济:将基于以太坊的区块链作为持久性存储解决方案-下篇》 背景 在中心化系统中,用户对自己的数据没有支配权。Facebook、Twitter 和谷歌等中心化系统拥有用户数据的所有权。他们可以掌控,处理和售卖中心服务器中的用户数据。在你不知情的情况下,中心化系统可以将你的隐私和公开数据卖给第三方公司。 所有中心化系统容易受黑客攻击,因为它们只有单一故障点。任何中心化服务器都无法 100% 避开黑客攻击。据估计,仅在 2018 年上半年,就有大约 450 万个数据记录被攻破。最近的「剑桥分析」(Cambridge Analytica)丑闻曝光了 Facebook 利用了数百万用户数据,一个典型的中心系统无法保护用户数据的案例。据估计,到 2020 年,每年的数据泄露成本将达到 2.1 万亿美元。 在基于以太坊的区块链中,数据所有权和安全性大为改观,没有拥有注册和保存用户数据的中心化机构网络,因此用户的数据归实际用户所有。根据设计,基于以太坊的区块链生态系统在数学上也不受黑客攻击的影响。要攻击像以太坊这样著名的区块链协议,黑客必须超过整个区块链网络的 51% 算力。以太坊大约有 25,000 个分散节点,因此攻击以太坊网络的成本很高,而且不切实际,因为黑客必须超过整个以太坊网络至少 51% 的算力。目前,还没有出现针对一个成熟的区块链网络发起 51% 攻击的。 真正基于许可的数据架构 系统要做到始终保护用户的隐私权,使用数据必须经过用户同意,让用户控制谁能读取和使用他们的数据。不是所有数据都必须公开。例如,如果用户不希望与任何人共享个人信息,那么该用户的个人信息很可能对所有人有害无利。 为了保护用户对数据的所有权,在设计基于以太坊的生态系统时,我们必须考虑用户许可。可以在智能合约的不同层上建立许可权,这些智能合约会强制执行查看和处理用户数据的权限。经过许可,用户可以决定是否将其数据共享给第三方公司。公司也可以在用户提供自己的数据做处理和分析,给与一定奖励。这样,用户可以出售自己的数据获得报酬。 实现真正的基于许可的数据架构,我们必须避开中心化服务器。如果我们真的想实现数据的完全自主权,就不能有中心化机构管理用户数据。通过基于以太坊的区块链,我们可以构建一个永久层,在点对点存储系统(如 IPFS)中注册和管理用户数据。 方法 我建议在基于以太坊的区块链地址上注册数据,通过诸如 IPFS 之类的链下存储方式存储数据。通过定义一个永久层来解决在基于以太坊的区块链地址上注册数据问题。永久模型由负责数据管理与许可的智能合约层组成。 基于以太坊的区块链开发永久模型的方法有永久层智能合约。永久层将处理单个用户地址注册以及链下点对点的存储网络,例如 IPFS。我们将借鉴在上篇中讨论的可靠且真实的关系数据库原则来实现稳定的数据管理。 架构 永久层由三种智能合约组成,每一种合约都有不同的责任集。所有商业智能合约都需要与永久层合约交互,从而存储和检索信息。流程如下图。 注册表-数据接口-数据集-用户地址
永久层一览
永久层合约
企业图示
永久层将支持 5 大用户:数据主体、数据分析师、数据提供者、数据管理员和数据消费者(即数据使用者)。这些角色根据自己特定的需求,以各自的方式与基于以太坊的区块链生态系统交互。数据生态系统将与不同的应用程序和管理系统交互。以下是他们的职责描述。
数据管理员
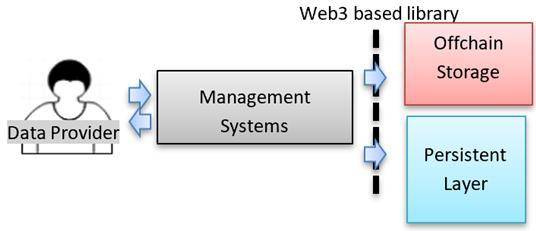
数据管理员来自 IT 团队,他们将管理基于以太坊的区块链基础设施。数据管理员将通过数据管理系统和工具与区块链交互,管理和维护基础设施。通过两个应用程序来管理基础设施: 1. 数据管理系统:提供管理区块链数据的 CRUD 功能。此外,数据管理系统将以表格的形式提供可视化数据和模式,方便数据管理。 2. 数据分析工具:提供监测和审计交易的能力。区块链交易的所有标记和分类器都将进行不对称加密,以防数据泄漏。 组件 数据管理员有 3 大组件:管理应用程序、基于 Web3 的库和数据层。 1. 管理系统和工具:开发的应用程序,如数据管理系统和数据分析工具,以方便管理的基础设施。 2. 基于 Web3 的库:用于与基于以太坊的区块链交互的库。将根据用于开发管理系统和工具的编程语言而有所不同。 永久层:数据管理。
数据提供商是为数据对象收集数据集的机构。比如医院、金融机构、学校、特殊利益集团等。数据提供商将通过连接到基于以太坊的区块链的第三方管理系统,与区块链进行交互。 组件 数据提供商有 4 大组件:管理应用程序、基于 Web3 的库、数据层和链下存储。 1. 管理应用程序:为数据对象收集数据的第三方应用程序。 2. 基于 Web3 的库:与基于以太坊的区块链交互的库,根据用于开发管理系统和工具的编程语言而有所不同。 永久层:数据管理,将数据链接到链下存储。 4. 链下存储:任何可以被解析的存储或数据库系统。 数据使用者(数据消费者)
数据消费者是利用数据主体的数据,向数据主体提供特定服务的服务提供者。比如医疗保健提供商、金融机构、教育提供商、特殊利益集团等。数据使用者将使用其终端应用程序与区块链交互,终端应用程序将调用商业智能合约来处理基于以太坊的区块链上的数据。 组件 数据消费者主要有 6 个组件:终端应用、基于 Web3 的库、商业智能合约、数据层、预言机和链下存储。 1. 终端应用程序:调用商业智能合约服务的应用程序。 2. 基于 Web3 的库:用于与基于以太坊的区块链交互的库。根据用于开发管理系统和工具的编程语言而有所不同。 商业智能合约:执行服务从而处理数据的智能合约。 4. 数据层:数据管理,将数据链接到链下存储。 5. 预言机:担当区块链和链下存储之间的桥梁。 6. 链下存储:任何可以被解析的存储或数据库系统。 数据对象
数据对象是数据所有人。他们的数据由像 Enigma 一样的基于以太坊的隐私保护区块链来管理和保护。不同的服务提供商充当数据消费者,可以利用数据对象的数据来为他们呈现特定的服务。由于数据对象拥有自己的数据所有权,服务提供者在处理他们的数据前,必须先征得当事人的同意。 组件 数据对象有 6 大组件:消费者应用、基于 Web3 的库、商业智能合约、数据层、预言机和链下存储。 1. 消费者应用程序:连接到基于以太坊网的区块链的应用程序,访问所有者的数据。 2. 基于 Web3 的库:用于与基于以太坊的区块链交互的库。根据用于开发管理系统和工具的编程语言而有所不同。 3.商业智能合约(可选)执行服务的智能合约。 4. 数据层:数据管理,它将数据链接到链下存储。 5. 预言机 :担当区块链和链下存储之间的桥梁。 6. 链下存储:任何可以被解析的存储或数据库系统。 数据分析师
数据分析师研究数据对象的数据。他们是数据科学家,为数据消费者分析数据,为数据对象提供准确的服务。数据分析师在研究数据之前需要得到数据对象的同意。 组件 数据分析师有 5 大组件:Jupyter Notebook、基于 Web3 的库,数据层和链下存储。 1. Jupyter Notebook:基于 python 的数据科学家平台。 2. 基于 Web3 的库:用于与基于以太坊的区块链交互的库。根据用于开发管理系统和工具的编程语言而有所不同。 3.数据层:数据管理,将数据链接到链下存储。 4. 预言机:担当区块链和链下存储之间的桥。。 5. 链下存储:任何可以被解析的存储或数据库系统。 链下存储 链下存储用于存储用户的原始数据。注意:不限于以下的链下存储选项
添加许可到基于以太坊的区块链的永久层,将构成第二层用于调用者和所有者注册数据的智能合约。调用者是得到数据所有者同意的人。调用者用自己的以太坊地址在注册中心智能合约中注册。所有者是拥有数据的人(数据所有者)。它们也通过以太坊地址在注册中心智能合约中注册。 总结 上篇探索了数据管理经过实践检验的原则历史,还探索了基于以太坊的区块链作为永久数据存储,释放数据经济的局限性和潜力。本文探讨了如何在基于以太坊的区块链中创建一个永久层,使基于以太坊的区块链成为数据经济的永久存储解决方案。 原文链接:https://mp.weixin.qq.com —- 编译者/作者:区块律动BlockBeat 玩币族申明:玩币族作为开放的资讯翻译/分享平台,所提供的所有资讯仅代表作者个人观点,与玩币族平台立场无关,且不构成任何投资理财建议。文章版权归原作者所有。 |
从存储技术历史谈起,探讨以太坊永久性存储方案-下
2020-05-24 区块律动BlockBeat 来源:区块链网络