IPFS(星际文件系统)是一种基于区块链内容的去中心化存储解决方案。IPFS主要利用散布在众多电脑以及节点上的点对点(Peer-to-Peer)网络模型来进行文件共享。通过这一网络模型,文件会分解成不同的部分并存储在网络节点上,节点再利用哈希表来对文件进行追踪。当根据各部分的哈希值再一次将零散的信息组合起来时,就相当于原始文件的重建过程。
去中心化文件存储 IPFS的核心创新理念旨在利用分布式哈希表(DHT)进行文件系统的存储和检索。IPFS类似于BitTorrent协议,但在指向共享文件的方式上有所不同。它将以键值对的形式将文件储存在区块链上。所有数据将被分割成256千字节的区块,散布在节点或计算机网络中,只能通过有效协调来支持节点之间的高效访问和查找。BitTorrent并没有采用区块链技术,而是依靠种子文件来指向对应文件。你可以选择使不同的种子文件指向同一文件,但是在IPFS文件系统中,你只需要一个指向文件的哈希地址。 在IPFS上发布文件的方式与云端发布文件的方式有所不同。IPFS上的所有数据都可以通过其哈希地址进行寻址。当有人申请访问数据时,他们是通过访问哈希地址获取数据的,而并非直接接触到实际文件本身。也就是说,IPFS提供了文件实际地址的抽象概念,因此实际储存单元对应用程序都是无关紧要的。这种抽象概念为应用程序的开发人员消除了复杂性。
一般来讲,文件是在网络节点上进行托管的。这一做法受到了IPFS区块链上Filecoin这一类数字资产的启发。节点可以通过在其计算机或服务器上提供存储空间来托管文件,为相关文件提供一个哈希地址,然后将其分布在整个网络上。相同文件可以在不同节点上进行托管,这一过程就相当于对文本进行复制。需要该文件的用户将根据离其位置最近的节点散列来访问该文件。 所有托管文件的节点都将引用根哈希(root hash),也就是对应文件的哈希地址。每当用户提出文件的访问申请时,就可以利用附近节点的哈希散列(根据根哈希对文件进行储存)来下载文件。IPFS系统上不会存在副本文件,因为哈希散列在上传文件时总会引用现成的文件或文件组块。 一旦文件存放至IPFS区块链系统中,它将一直可用,直到通过解除文件固定格式并运行一个垃圾收集程序将其删除为止。不同的节点可以通过哈希值指向文件本身。只要哈希值能指向对应文件,不同节点就可以对其进行储存。IPFS系统可以随时进行更新以指向不同的哈希值,不过只要用户拥有原始哈希值,仍然可以访问该数据,至少有一个节点会永久储存该数据。 存储寻址方案 IPFS系统与典型的基于网络的云存储系统的区别在于,它是以内容为基础的(内容寻址),而不是以地址为基础的(地址寻址)。地址寻址存储系统的一个案例是超文本传输协议(HTTP)。如果存储系统是以地址为基础的,就需要使用域名服务器的主机名来对服务器进行标示。它可以通过映射到友好用户名称的逻辑寻址方案(如IP地址)来跟踪主机。如果主机更改了名称或地址,它还必须在对应的名称服务表中进行修改。 基于内容的寻址存储适用于从网络获取数据。这需要一个内容标识符来确定文件的实际存储位置。在这种情况下,用户是根据密码散列而非逻辑地址对数据进行访问的,这就相当于文件的数位指纹。不管谁上传了文件,上传时间和地点有什么区别,网络都会根据哈希值返回相同的内容。 在速度和可靠性方面,IPFS系统的性能优于HTTP协议。与依赖服务器地址获取文件的方式不同,内容寻址存储系统可以从用户附近的各种服务器(例如,IPFS网络上的对等点或节点)提供文件。换句话说,用户可以简单地对文件进行搜索,而无需搜索引擎提供坐标,即服务器名称或地址。相反,用户可以通过文件的哈希值对其进行引用,而且可以通过网络附近的可用节点获取到相应文件。 IPFS系统的安装 IPFS的常规安装有2个节点选择 1.IPFS桌面——直接从一台计算机(笔记本电脑或台式机)存储或分享文件。用户可以安装一款IPFS配套应用程序,从而可以通过网页浏览器对本地节点进行访问。这是对等网络文件共享的安装形式。 2.IPFS集群——用于大规模地存储和共享文件,该集群允许跨IPFS节点对识别号组合(pinsets)进行编排和协调。通过IPFS集群,用户可以利用分布式节点构建一个大规模的文件存储系统。 在安装基础IPFS桌面之后,节点配置从初始化存储库开始。以下是用户从Windows Powershell或Mac/Linux terminal shell中输入的指令。 ipfs init > initializing ipfs node at /Users/<username>/.go-ipfs > generating 2048-bit RSA keypair...done > peer identity: Qmcpo2iLBikrdf1d6QU6vXuNb6P7hwrbNPW9kLAH8eG67z > to get started, enter: > 初始化操作是在第一次使用IPFS系统时需执行的步骤。下一步是运行IPFS的程式处理进程,将节点连接到网络。 ipfs daemon > Initializing daemon... > API server listening on /ip4/127.0.0.1/tcp/5001 > Gateway server listening on /ip4/127.0.0.1/tcp/8080 这项指令是指在本地计算机127.0.0.1上初始化并运行程式处理进程。它将启动侦听TCP端口5001的API服务器以及侦听TCP端口8080的网关服务器。现在,通过发出集群指令,用户即可看到网络上的其他IPFS节点。指令如下所示: ipfs swarm peers > /ip4/104.131.131.82/tcp/4001/p2p/QmaCpDMGvV2BGHeYERUEnRQAwe3N8SzbUtfsmvsqQLuvuJ > /ip4/104.236.151.122/tcp/4001/p2p/QmSoLju6m7xTh3DuokvT3886QRYqxAzb1kShaanJgW36yx > /ip4/134.121.64.93/tcp/1035/p2p/QmWHyrPWQnsz1wxHR219ooJDYTvxJPyZuDUPSDpdsAovN5 > /ip4/178.62.8.190/tcp/4002/p2p/QmdXzZ25cyzSF99csCQmmPZ1NTbWTe8qtKFaZKpZQPdTFB 正如IPFS说明中所解释的,对等点所采用的格式是: <transport address>/p2p/<hash-of-public-key> 以下是一个在网络上获取文件的指令示例: ipfs cat /ipfs/QmW2WQi7j6c7UgJTarActp7tDNikE4B2qXtFCfLPdsgaTQ/cat.jpg > cat.jpgopen cat.jpg 该指令将从名为“cat.jpg”的指定对等点获取一个对象,并在本地打开它。 IPFS的脚本语言 以下是利用Runkit NPM和Infura网关(对公众免费开放)向IPFS网络写入数据的测试代码。 const IPFS = require('ipfs-mini' 1.1.5 ); const ipfs = new IPFS({host: 'ipfs.infura.io', port: 5001, protocol: 'https'}); const data = "Writing a test message on the network"; ipfs.add(data, (err, hash) => { if(err){ return console.log(err); } console.log('https://ipfs.infura.io/ipfs/'+hash); }) 在这段代码中,用户通过指令功能在Node.JS上申请“ipfs-mini”程序包,配置Infura IPFS网关的访问渠道“ipfs.infura.io”,将数据指定为字符串“Writing a test message on the network”。然后创建一个条件指令,如果出现问题,则返回错误提醒,如果用户需要获取哈希值,那么控制台会自动录入网关地址以及哈希值。 结果将返回唯一散列:QmQhadgstSRUv7aYnN25kwRBWtxP1gB9Kowdeim32uf8Td 接下来,用户即可输入相应网址链接:https://ipfs.infura.io/ipfs/QmQhadgstSRUv7aYnN25kwRBWtxP1gB9Kowdeim32uf8Td 随后结果则会显示出用户刚刚录入Infura网关的数据。当然,数据并不会永续存在,而是在几天或几周不再活跃之后被清除。用户如需永久的储存数据,那么应该在本地或云上使用专用服务器。 如果整个程序没有出错,那么即可返回该数据的散列值。
IPFS系统的优势 去中心化——文件存储在网络节点上,可以根据哈希表进行引用。通过Filecoin的激励机制,可以刺激节点储存文件。 容错性——如果某一节点发生故障,只要还有其他节点存储了该文件,那么文件仍然可用。不会出现单点故障。 可伸缩性——存储文件的节点越多,网络用户获取信息的能力就会越快、越迅速。 永续存储——IPFS系统的核心内容是数据存储:只要原始数据对应的对象以及任何新的版本可以访问,那么所有文件的历史记录都可以进行检索。由于各数据区块是通过网络本地储存的,并且可以无限期地缓存,这也就意味着IPFS的任何数据都可以永续储存,而无需修改。 抵制审查——一旦内容被上传到IPFS系统,任何中央机构都无法做删除处理,因为它是在整个网络中进行传播的。仅删除一个节点的数据并不能完全删除该文件,也就是说,在其他节点上仍然储存有备份文件可供使用。 IPFS系统的劣势 对用户不太友好 对用户来讲,在IPFS网络上建立文件索引的方式并不是很友好。例如,通过哈希地址访问文件需要输入: 数据开发人员可以通过链接共享文件,不过就过程而言,这是非常乏味而且耗时的。IPFS利用星际命名系统(IPNS)来查找文件。IPNS系统会尝试着使名字解析更便于用户使用,就像互联网上的域名服务系统(DNS)一样。 另一方面,系统中还带有一个图形用户界面(GUI)和基于网络的衍生IPFS应用程序,从而使得用户的访问更加轻松、便捷。然而,相较于任何一款普通的智能手机应用程序,它的用户友好度和操作简易性仍然有待提升,因为它的学习曲线更加陡峭。它并不只是点击网页链接那么简单。用户必须了解IPFS的工作原理才能使用它。 数据隐私与合规性 实际上,利用IPFS系统将客户数据(如“了解你的客户(KYC)”等个人识别信息)储存在共享存储系统上并非最佳实践。首先,它违反了数据存储的合规性原则,即“了解你的客户”等数据是不能也不应该在公共云或共享存储空间上公开的,这里当然也包括了IPFS系统。在公共云上,对数据管理的组织和控制力度更小。对金融机构的严格要求是指将数据和数据备份保存在一个受监管而非共享的存储系统上。另一方面,由于所有的数据都位于公共网络上,所以任何节点都可以承载“了解你的客户”数据。这进一步违反了严格把控数据存储对象和存储地点的法律法规。 第二个问题是,如果所有节点必须遵守整个金融体系的规则和规定,这意味着它们必须拥有备份、强大的安全性和容错能力等。在公共网络上,节点是随机散布的,它们不必建立在任何人类设定的系统之上,也无需按照规则行事。即便有些数据是加密的,这些节点还是能够向网络上的其他用户共享该数据,所以我们无法阻止恶意参与者访问这些数据。他们可以自行解密,然后将其用于其他非法途径。 数据不一致性 在整个IPFS网络系统中,节点势必没有动力长期备份和维护数据,所以它可以选择清除缓存数据以节省空间。这意味着从理论上讲,如果没有其他节点存储相关数据,那么该文件可能会随着时间的推移而“消失”。根据目前的采用率水平,它暂时算不上一个棘手的问题,但从长远来看,备份大量数据需要强有力的经济激励。 这里的问题就在于,如果一个公司选择使用公共的IPFS网络来存储文件,那么在未来,节点可以随时选择不再存储该文件。如果所有节点都做出相同的选择,那么该文件就无法长期保存在网络上,除非在私有网络上运行IPFS系统。根据IPFS协议,如果用户上传到IPFS网络的文件无法获得高访问量,它就会自动消失。换句话说,用户的数据需要在网络上更受欢迎,才能永久保存。如果用户不希望自己的数据从IPFS网络中消失,那么必须将数据固定在节点上,也就是说必须确保整个网络上,至少自己的节点拥有该数据。 由于IPFS系统是去中心化的,因而所有的存储节点都将拥有上传文件的副本。通常来讲,如果该文件并不活跃或者不经常使用,那么就会被慢慢剔除。这无疑是一个非常有争议的问题,因为有的时候,文件需要归档并且不会经常使用,而有的时候需要立即删除。当用户对已经存储在IPFS上的数据进行更改时,其对应的散列也必须改变。当然,如果有一个新版本的文件,用户必须重新上传,但它不会覆盖旧版本。这将影响到该文件的现有链接,也就是说原始链接将保持不变,但用户需要为新文件创建一个新链接。 在更新KYC数据(包括护照和驾照)时,这或许是一个挑战。当这些证件信息过期后,用户必须上传一个新版本来替换旧版本。IPFS系统提供了版本控制,但是一旦将其扩大到公共网络上,事情就变得棘手了,因为不同的节点可以有多种版本。旧版本不会自动更新,只能要么存档,要么销毁。IPFS系统不能以AWS或Azure上的相同方式归档文件。 IPFS拥有版本控制系统。这是其Merkle DAG结构的一个特性,它允许用户构建一个分布式的版本控制系统(VCS)。当下最流行的例子是Github,它允许开发者轻松实现项目上的同时协作。Github上的文件利用Merkle DAG结构进行存储和版本控制。它允许用户对同一份文件的不同版本进行独立的复制和编辑,存储这些版本,然后将所有编辑的内容合并到原始文件中。然而,根据多数开发人员的观点,这些内容不过是理论上的,它的实用性尚未经过充分的测试和验证(截至撰写本文时)。如果我们要实现它,还将需要更多的时间和开发成本,这从长远来看是值得期待的。
IPFS系统在Web3Studio SoJourn项目中的使用(图片来源:Consensys) 项目概要 IPFS系统更适合长久性的数据存储,如数字音乐、艺术作品和认证信息(如,证书、文凭、奖励以及捐赠证明)。这些数据都是无需更改的,将其放在基于区块链的存储系统上会更有意义。它为创作者或艺术家提供了一个数字证明,任何人都无法对其进行更改,并且可以通过一个基于散列的系统以及针对性的键值对来证明。 IPFS系统上存储的数据是非常公开的,从而更加需要数据的保密性。这可能会违反某些公开私有数据的数据存储条例(例如,通用数据保护条例)。在AWS和Azure云上也有可扩展的数据存储解决方案,以满足用户的隐私性、安全性和合规性要求。实际上,没有必要像IPFS存储数据那样发布个人信息。对于公开透明的内容信息,IPFS系统可以向内容所有者提供真实性的证明。它可以通过证明创作者的所有权来维护各自的作品版权,比如艺术品,这样我们的用户就可以收取各自应得的版权费,还可以防止不法分子盗用他人作品而获得荣誉。 IPFS系统似乎为内容提供了快速和安全的容错文件存储器。然而,它可能不适用于需要严格规定数据存储和保护方式的财务信息和隐私数据。对于需要频繁更新和改动的文件,比如,持续记录数据信息的活动日志文件,也不建议采用该系统。在区块链上存储数据的目的不同,IPFS系统会提供相应的解决方案。随着IPFS的发展,它可以利用隐私层次来隐藏静态加密的个人数据,力求不会违反任何泄露机密的规定。 文章来源:?小链财经 翻译:Celia —- 编译者/作者:小链财经官方 玩币族申明:玩币族作为开放的资讯翻译/分享平台,所提供的所有资讯仅代表作者个人观点,与玩币族平台立场无关,且不构成任何投资理财建议。文章版权归原作者所有。 |
IPFS在分布式文件存储系统中的运用
2020-07-14 小链财经官方 来源:区块链网络
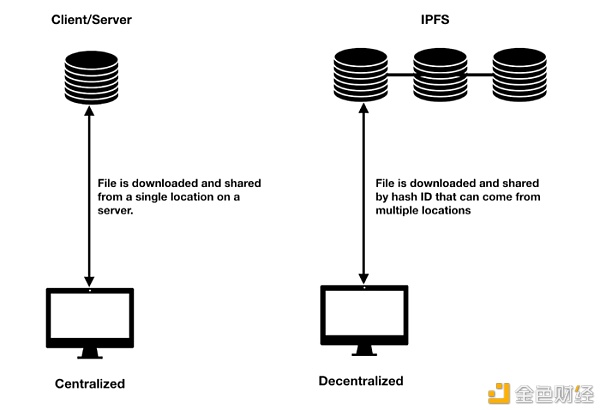 集中式和去中心化文件存储的区别。
集中式和去中心化文件存储的区别。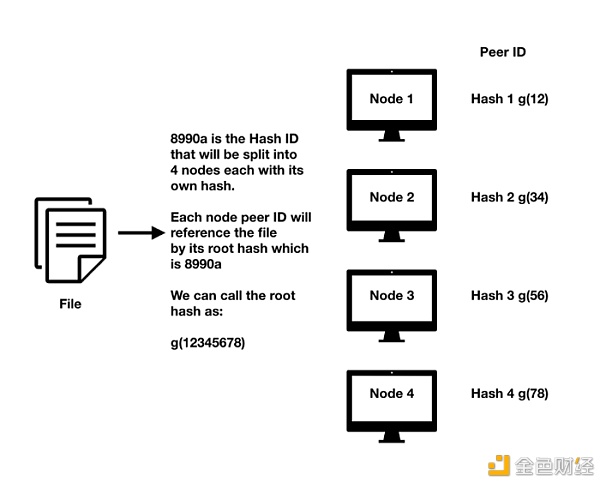 IPFS如何跨节点存储文件。
IPFS如何跨节点存储文件。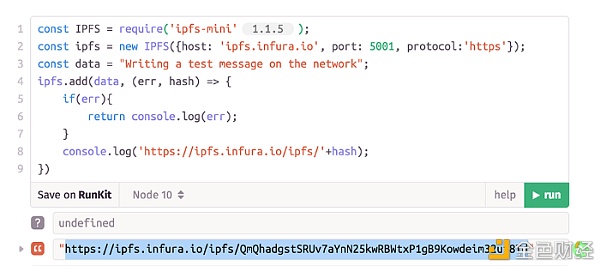
- 上一篇:年中复盘:2020年上半年币圈都有什么变化?
- 下一篇:当今市场的云算力现状
LOADING...
相关阅读:
- 七月去中心化交易所交易量增长174%,突破$ 4.3B,并刷新历史记录2020-08-01
- 基于DeFi的流动性挖矿Yield Farming2020-08-01
- M2Pro矿机订购:芯域矿池超级节点助力新基建(附二维码)2020-08-01
- Filecoin挖矿指南之设备性能对证明计算的影响2020-08-01
- Paydex开启支付新时代,区块链技术到了生产力转化的重要阶段2020-08-01