| 量化投资依托量化模型与数据,寻找能够带来超额收益的多种“大概率”策略。传统量化投资模式下,所使用的外来数据在质量和安全上存在重大隐患,量化模型效果不稳定,影响量化策略的完整性与精确度。 当多方安全计算技术遇到量化投研,投研机构将怎样借力充分挖掘数据价值?算力隐私数据安全专栏特邀郭嘉,初探大数据量化建模,及多方安全计算技术与量化投研工作的结合方式。 传统的投研数据同质化程度极高,模型效果不具有独特性,美国市场有一群人在挖掘和研究更加互联网化的数据指标,称另类因子。由于第三方数据的开放流通限制,必须遵守数据安全的游戏规则。本文借由投研对数据的安全建模方案,实现了多方数据的投研建模,并实现了投资模型的加密部署。 1 大数据的量化逻辑 我们可以按数据开放程度,简单地把投研信息分为三类:公开数据、半公开数据、以及非公开数据。 公开数据,很好理解,就是股价,K线图等随时可以查看的数据; 半公开数据,指我们可以获取到,但不能全面地获取的数据,如实时的资金流向我们随时可以获取,但是网站并不会公开以往的数据; 非公开数据,即市场上与股票相关的其他公司、证券交易所内部数据,无法对外提供。 引入一个概念——量化投资,量化投资简而言之就是在数据中找规律。大数据为量化投资打开了全新的大门,在量化交易中引入大数据技术,可以充分挖掘海量数据所隐藏的一切信息,来预测金融经济活动,并结合历史预测,及时将预测效果加以反馈,以动态更新交易策略,获得最理想的预测效果。 传统的各类量化指标,无论是基于价格还是基于财务数据都会存在一定的滞后性,无法用更具领先性的手段来了解行业和市场。而采用了大数据技术的行业及个股判断,则可以在一定程度上改善这一情形。利用搜索因子可掌握投资者情绪,利用电商数据可实时得知各行业的基本面动向,利用大V数据集合了集体的智慧,这几种大数据理论上都可以用来预测未来市场情况,将互联网金融的大数据作为选股因子引入模型,代表着资产管理机构在指数投资上重构选股逻辑。 股票市场的信息不对称性是一直存在的问题,量化交易者无法获知市场上非公开数据和互联网数据,且基于大数据与模型的量化交易,往往对操作中的数量与时间节点要求分外严格,丢失或篡改数据均会致使预测与正确结果相偏离,又或致使交易在不对的时刻,以错误的数量来达成。若因信息不安全而外泄数据,长时间便可能会致使业内彼此利用这些数据来恶化竞争。2 多方安全计算的量化优势 事实上,有价值的数据往往躺在别人的怀里,如何只进行“精神共享”,不进行“肉体接触”,这是当下对数据应用安全的合规要求。隐私计算技术很好地解决了这个用数难题。多个持有各自私有数据的参与方,共同执行一个计算逻辑(如求最大值计算)并获得计算结果,各方发送的消息中不能推断出各方持有的私有数据信息,在此技术下,各参与者的身份和地位相同,可建立共享数据策略。由于数据不发生转移,因此不会泄露用户隐私或影响数据规范,为了保护数据隐私、满足合法合规的要求。专业术语称之为多方安全计算。
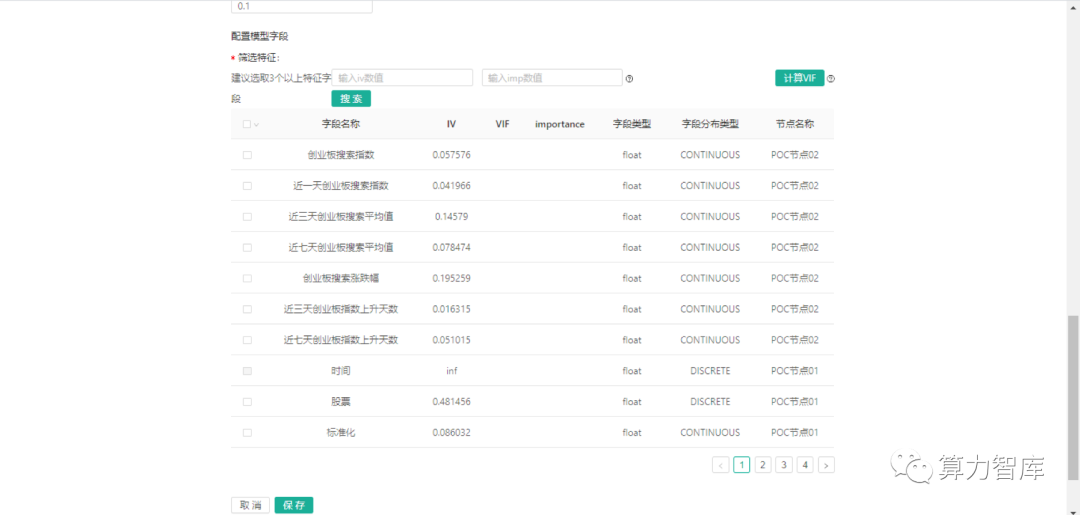
此技术能够在保证信息安全前提下,让投研机构利用非公开数据资讯和信息,更好的发掘和预测股票的波动。本文即尝试通过安全多方计算技术和联邦学习技术,将公开数据和非公开数据进行结合,并进行量化交易分析,希望该案例能够给从事量化交易的专业人士拓展分析思路。 ?3 Avatar的开幕式 “这个case不是为了证明第三方数据有多牛,是表演一下投研对数据的安全建模方案”。 研究标的:2019年8月5日-2020年8月4日创业板中所有股票 研究目标:该策略目标为利用历史数据,预测每只股票当天是否涨幅超8%,即样本集中日股票涨幅超8%,y值为1,否则y值为0。 研究变量 联邦学习中节点A数据:通过股票历史数据(公开数据),构建了当日星期、近三天平均收益率、近七天平均收益率、近三天绝对收益率、近七天绝对收益率、近三天标准差、近七天标准差、近三天平均换手率、近七天平均换手率、近三天平均成交量、近七天平均成交量、近三天上涨天数、近七天上涨天数、近三天涨幅大于5%次数、近七天涨幅大于5%次数、近三天跌幅大于5%次数、近七天跌幅大于5%次数,共17个指标。 联邦学习中节点B数据:通过百度搜索中关键词为“创业板”的搜索次数,构建了当日创业板搜索指数、近一天创业板搜索指数、近三天创业板搜索指数、近七天创业板搜索指数、近三天创业板指数上升天数、近七天创业板指数上升天数、创业板搜素指数涨幅,共7个指标,模拟外部非公开的数据源。 综上,该策略通过上述24个指标的构建,结合动量策略和反转策略原理,并通过百度搜索次数作为外部数据,作为反应市场情绪的变量,之后根据IV等指标筛选入参变量,构建逻辑回归模型,预测当日股票是否上涨超过8%。为验证百度指数作用,策略制定了四个模型作为对照,具体如下: 样本集为全部股票,未用到百度指数构建模型 样本集为全部股票,用到了百度指数构建模型(其他入参变量与对照组1一致) 样本集为华兴源创,未用到百度指数构建模型 样本集为华兴源创,用到百度指数构建模型 (备注,因为百度搜索数据进行了反爬虫的保护,无法爬取全部信息,故全量股票数据建模过程中,只用到了搜索“创业板”的搜索次数,未用到每只股票对应的股票名称搜索次数;仅在样本集为华兴源创的案例中,用到了华兴源创作为关键词的搜索次数。) 模型结论 1)通过IV值可推断百度指数数据对于预测y值有较为重要的作用,其中创业板搜索涨跌幅和近三天创业板搜索平均值效果较为显著,通过模型系数可知创业板搜索涨跌幅和近三天创业板搜索平均值和y值具有正相关关系,即数值越高,越容易涨幅超过8%。(具体信息见下图)
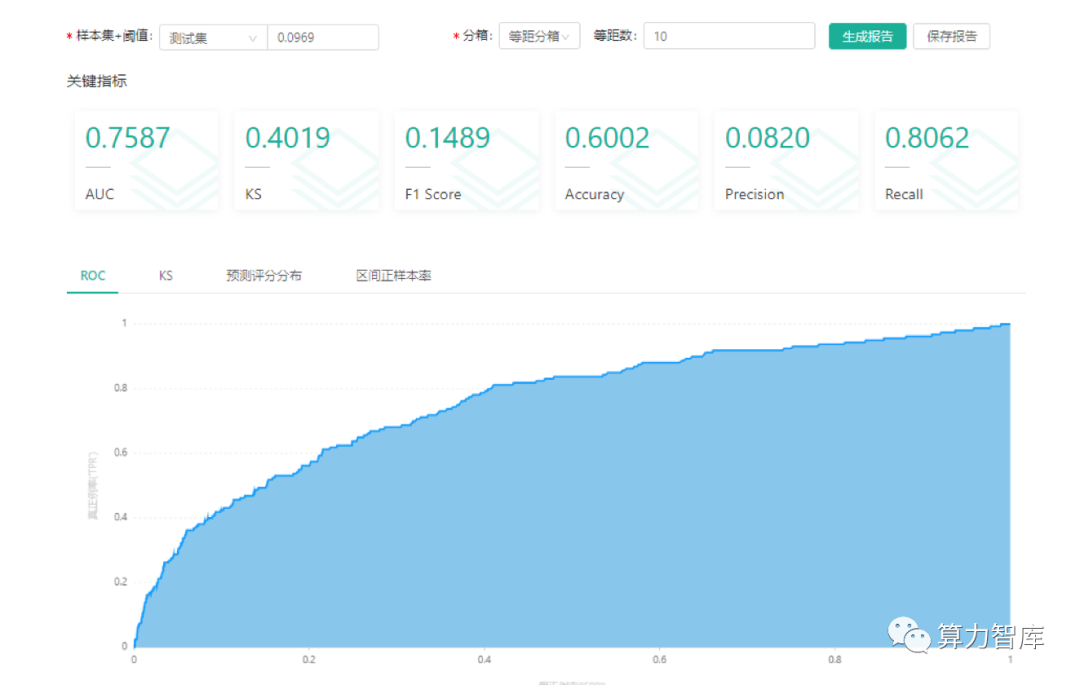
2)样本集为全部股票,用到百度指数构建模型,AUC为0.76,未用到百度指数构建模型(其他入参变量与对照组1一致),AUC为0.72,说明百度指数对应预测有明显提升效果。(具体信息见下图)
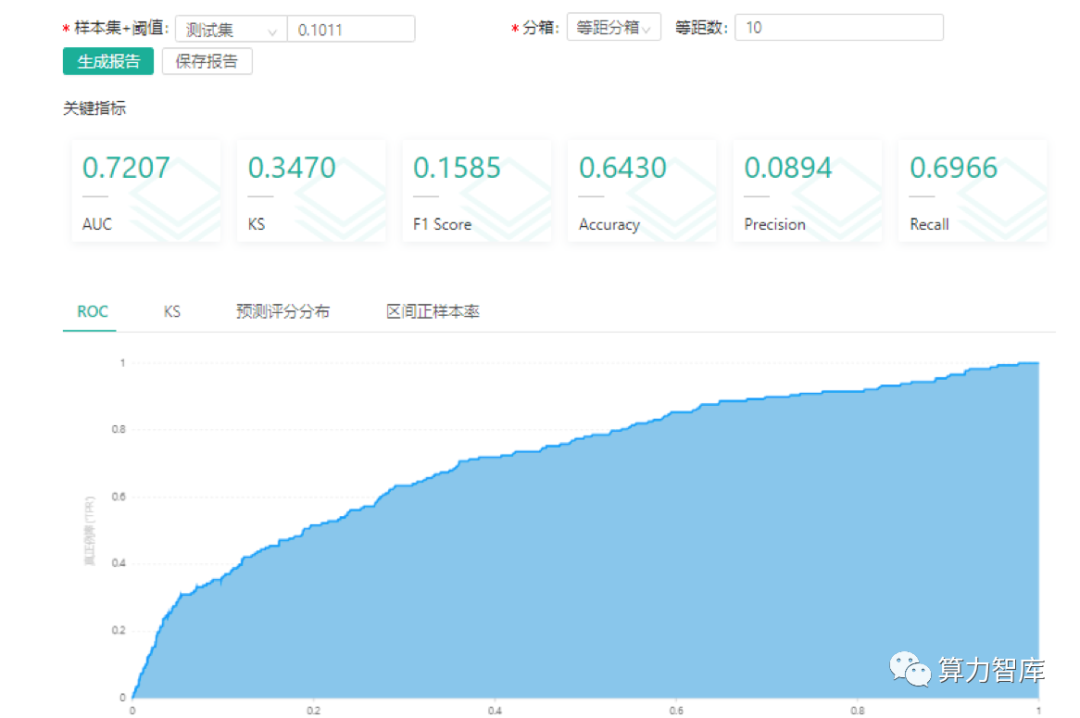
3)样本集为华兴源创,用到百度指数构建模型,AUC为0.74,未用到百度指数构建模型(其他入参变量与对照组1一致),AUC为0.73,说明百度指数对应预测有提升效果。(具体信息见下图)
根据上述案例,我们发现添加外部的非公开信息,确实能够提升股票预测能力。 对量化投资来讲,传统量化投资大部分的时间都浪费在了数据清洗和数据整理上,且对外获取的数据,由于不清楚数据来源,数据质量和数据安全存在重大隐患,量化策略可能因为数据质量(数据更新不及时,数据获取方式非法)而带来反向影响(触犯个人隐私、由于数据缺失造成量化策略不稳健)。 利用安全多方计算的方式,量化公司就可以使用外部数据源直接进行联邦学习,数据方会根据量化投资者需求,前期进行数据的加工和处理,对于量化公司来说,一是可以有效减少数据清洗和整理时间,二是直接对接数据源,确保了数据安全和数据质量,三是可以确保业务合规,保证量化模型效果稳定,四是可以通过外部数据,构建非公开数据相关的量化策略和指标,获取更多的超额收益。 展望 本文只是大数据量化建模的初探,隐私计算技术能够提供给量化交易更为广泛、有效的基础资源、技术支持,有机会促进大数据技术基础下量化交易策略的快速发展。本篇文章仅仅是通过非公开信息,利用安全多方计算技术对量化研究工作进行的初步探究,探究方法还比较粗糙,后期作者将基于安全多方计算对量化交易进行更加深入的探究和分析,希望感兴趣的朋友们持续关注后续相关系列文章。 作者 黄奉孝(郭嘉) 自诩从技术走向业务的小学生。近十年互联网大数据行业经验,先后就职于上海大智慧、平安、挖财,任职大数据架构师、资深分析师等职位,对金融科技有深入研究。 目前任职富数科技高级总监,负责隐私计算的解决方案与业务落地。
文章所载观点仅代表作者本人 且不构成投资建议 敬请注意投资风险 本文来源:算力智库 —- 编译者/作者:算力智库 玩币族申明:玩币族作为开放的资讯翻译/分享平台,所提供的所有资讯仅代表作者个人观点,与玩币族平台立场无关,且不构成任何投资理财建议。文章版权归原作者所有。 |
精准预测市场?当多方安全计算遇到量化投研|算力智库隐私专栏
2020-08-13 算力智库 来源:火星财经




LOADING...
相关阅读:
- 百度超级链,超级多的数据上链2020-08-12
- 数字领域,百度要放大招了,快来围观啊。2020-08-11
- 百度微积分为何能吸引大量资本和投资者?2020-08-06
- 2020年最新百度百科创建方法2020-08-05
- 前哨|百度开放网络白皮书正式发布2020-08-04