来源 |pintail.xyz 作者 |Pintail 我可以赚多少?  以太坊权益共识机制的核心部分于 2020 年 12 月启动了,最终交付了从工作量证明过渡的第一阶段——这是在 2014年就提出的愿景,比以太坊主网上线早了整整一年。在以太坊的权益共识机制里,区块链的安全由验证者来提供,他们需要存入 32 个 ETH 作为保证金,且负责对新的区块链(即信标链) 状态达成共识。他们诚实履行职责的话会得到奖励,失职的话则会遭受相应的惩罚。如果验证者被证明有恶意行为,他们还会受到严重的惩罚,即罚没。 与工作量证明型区块链的区块奖励相比,这些验证者的奖励与惩罚会相对复杂一点。尽管有一些优秀资源,例如 beaconcha.in,可以帮助验证者更好了解他们能赚多少,但并没有明确解释是怎么来的。本文将尝试给验证者解释清楚他们可以赚多少,以及收益差异是怎么来的。 读者可能已经看过运行一个验证者节点的“APR (年化率)估值”,比如在权益证明 launchpad上的图表,并好奇这些数值是否现实——这些数值到底怎么来的?事实上,目前所有的 APR 估值都是基于一系列的假设 (通常没有说明),有些估值甚至用的是旧版本的信标链规范。首先,让我们看一下如果所有验证者都完美参与的话,验证者可以赚取多少。我将依据 Ben Edgington 的注释规范来做预估。请注意:我们将使用 2020 年 12 月信标链上线所用的主网规范。即将要进行的 Altair 信标链分叉将对验证者奖励和惩罚进行完善。 可获得的奖励 以太坊验证者参与网络的每个 epoch (6.4 分钟) 都会获得奖励。他们收到的奖励是base_reward(基础奖励) 的倍数。信标链有三方面的值需要投票,每个验证者对其中一个当前值投了正确的票 (或用行话说,做了证明) 就会得到一份base_reward。我会把这三项奖励组合起来称为\"正确率奖励 (accuracy reward)\"。如果他们的投票 (证明) 马上被打包到信标链区块里,他们还会有第四项奖励——打包奖励 (inclusion reward)。因此,一个验证者在每个 epoch 里可获得的最高奖励是4 * base_reward。为了搞清楚验证者可赚取多少,那么我们需要了解base_reward是如何确定的。 base_reward的水平是由网络里的活跃验证者数决定的,然后调整为激励合适规模的验证者集。我们希望激励足够多的验证者加入到验证者集里,而不需要支出超过必要的发行量。如果没有那么多的验证者,协议需要提供更高得回报,以鼓励更多验证者加入。但是,如果已经有大量的验证者了,协议可以支出更少,节省发行量。信标链计算这点的函数是一个平方根倒数——也就是说,奖励水平是由除以当前质押的 ETH 数的平方根得出的 (选择使用平方根倒数关系的原因在 Vitalik Buterin 的设计原理文件中有解释) 根据注释规范: base_reward = effective_balance * BASE_REWARD_FACTOR // integer_squareroot(total_balance) // BASE_REWARDS_PER_EPOCH 规范就是用上面的公式来计算每个验证者的base_reward,以 Gwei (=10-9 ETH) 为单位,这些术语代表的意义如下:  在理想情况下,一切都会简化,因为所有验证者的有效余额都是 32 个 ETH。因此,n个验证者的理想基础奖励为: base_reward = 512e9 // integer_squareroot(n * 32e9) (再次提醒,在信标链规范里,计算单位是 Gwei。我们可以除以 10^9 来换算成 ETH) 理想情况 根据上面的信息,如果所有验证者都完美参与 (即验证者在每个 epoch 里获得4*base_reward,我们可以计算可得奖励的最大值,然后用它来乘一年的 epoch 数,就可以算出一年的理想奖励金额。这就是一年的秒数 ((31556952) 除以一个 epoch 的秒数 (384),得出每年有接近 82180 个 epoch。每个验证者每年得到的理想奖励如下图,由关于质押的总 ETH 的函数得到。 输入1 # define annualised base reward (measured in ETH) for n validators# assuming all validators have an effective balance of 32 ETHimport math 输入 2 # plot ideal ETH staking return  现将图中的一些数值制成如下列表,以供参考: 输入 3 # tabulate a few values for validator return 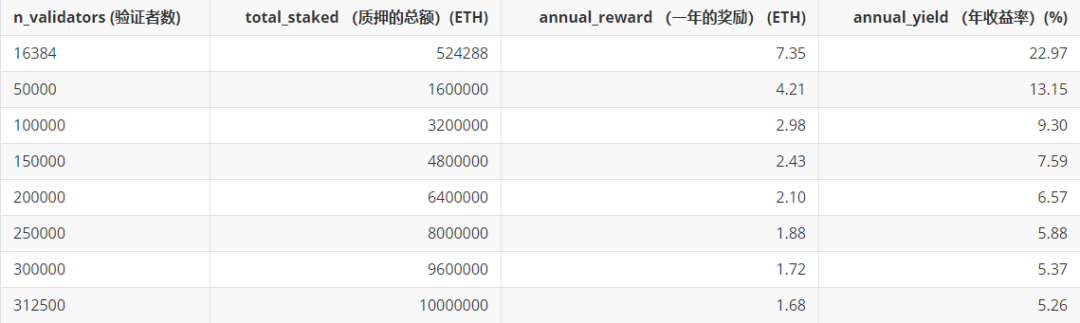 区块奖励 上面的图和表格给了我们一个高度理想化的版本,即当所有验证者都完美参与,所有奖励都平均分配的情况。但是,这个版本其实漏掉了一项重要组成部分,即信标链的区块奖励 (block reward)。 区块奖励并不改变支付给验证者的 ETH 总额,但它意味着部分可得奖励会分配给出块者 (block producer)。负责出块的是每个 slot 里 (一个 slot 是 12 秒,一个 epoch 里有 32 个 slot) 随机挑选的一个验证者。该区块是由其他验证者提交的信标链证明组成的,且出块者获得的奖励占区块证明全部打包奖励的一部分。这意味着出块者有动力将他们能收集到的所有有效证明都打包到区块,以最大化他们的以及所有提供他们打包证明的验证者的收益。 在信标链规范中,给出块者的打包奖励比例由一个叫PROPOSER_REWARD_QUOTIENT(提议者奖励商) 的常数决定,它的值是 8。也就是说,? 的打包奖励 (相当于每个 epoch 全部奖励的 ????) 是给出块者的,? 是给所作证明被打包到区块的验证者的。 由于每个验证者被选出做区块提议的机会是均等的,从长远来说,奖励应该也是均等的,与上图相符。但在任何有限的时间里,验证者获得的奖励会很不一样,因为有些验证者运气比较好,获得比平均水平更多机会提议区块,有些则运气比较差,提议区块的机会更少。 为了计算出运气因素在区块提议频率中的重要性,我们可以应用一些基本的统计数据。每个验证者被选出做提议的机会是均等的——每年31556952 / 12 = 2629746个 slot。如果有 100,000 名验证者,被选出做提议的机会是 10-5 次。每个验证者得到区块提议机会的数量将由二项式分布决定。 下图绘制的概率质量函数图直观地呈现了验证者可期望有多少区块提议机会: 输入 4 # plot pdf output: With 100,000 validators, the mean number of blocks proposed per validator per year is 26.30 输出: 如果有 100,000 个验证者,每个验证者每年平均获得 26.30 次提议区块的机会运气最差的 1% 验证者每年获得的提议区块机会最多 15 次验证者平均每年获得的提议区块机会是 26 次运气最好的 1% 验证者每年获得提议区块的机会是 39 次  因此,我们可以看到,仅基于运气的话每个验证者获得的提议区块机会有相当大的差异。在一年里,运气最好的 1%验证者获得提议区块的机会是运气最差的 2 倍。在足够长的时间里,这个差异会被拉平。但是,随着验证者数量增加,提议区块的概率会降低,不均等的情况会更严重。 为了显示这种效应对验证者奖励的影响,我重新计算了验证者收益图,但现在我将绘制运气最好的 1%和最差的 1%的线条。从另一个角度来看的话,这代表 98% 的验证者的年收益是在这两条线之间。 输入 5 # plot ideal ETH staking return with interpercentile range output: With 50,000 validators:the luckiest 1% of validators receive 1.0% greater reward than averagethe unluckiest 1% of validators receive 1.0% smaller reward than average 输出: 当有 50,000 个验证者:运气最好的 1% 验证者获得的奖励比平均水平高 1.0%运气最差的 1% 验证者获得的奖励比平均水平低 1.0%当有 100,000 个验证者:运气最好的 1% 验证者获得的奖励比平均水平高 1.5%运气最差的 1% 验证者获得的奖励比平均水平低 1.3%当有 200,000 个验证者:运气最好的 1% 验证者获得的奖励比平均水平高 2.1%运气最差的 1% 验证者获得的奖励比平均水平低 1.7%  从上面的图表和统计数据可以看出,在一年的时间里,奖励的变化幅度可能有几个百分点。请记住,即使在理想情况下也是这样,即每个验证者都完美履行他们的职责。随着验证者集变大,这种影响会更明显,因为在一个 slot 里每个验证者的概率都降低了。 虽然从验证者的投资风险角度来看,这种水平的变化也许并不令人担忧,但我们在深入研究验证者在网络中的实际表现时,这些变化都值得我们关注。表现上的微小差异可以很容易被分配给验证者区块提议机会的随机变化所吞噬——即使是在整整一年的时间里,就像这里的模型。 对非完美参与情况建模 到这里为止,我们的模型都假设所有验证者都完美履行他们的职责。这使我们可以根据上文解释的出块机会差异对可得奖励设一个上限。但是,为了建立更接近现实世界的奖励模型,我们需要考虑不那么完美参与的验证者带来的影响。即使你完美运行你的验证者节点,保持一直在线,你的奖励仍然会因为网络的其他验证者节点无法做到完美而受影响。信标链激励机制的设计理念是:如果整个网络的表现都被优化了,那么给每个人的奖励都会最大化。这有助于抑制恶意行为 (例如试图让其他验证者离线以最大化自己的奖励),但这的确意味着即使自身没做错什么,个人质押者的奖励也会被减少。 有很多原因可以导致验证者无法生成证明、广播证明到网络、出块、或打包区块到网络。用所有这些因素来建模是非常难的,因此我们将尝试简单一点的。我们假设两种情况:验证者保持在线且完美履行职责,和验证者一直离线且完全不履行职责。在我们的模型里,网络表现水平可以用一个简单数字——参与率来体现,参与率对应的是在线上的验证者比例。 完美验证者在不完美网络中的情况 想象一个完美验证者在一个不完美的验证者集中运行,有两个机制可能会减少验证者获得的奖励: 对于准确率的奖励,奖励与投相同票的活跃验证者成比例缩放。因此,如果 99% 的在线验证者都投了正确的票,奖励会按0.99缩放。 如果我们的完美验证者所作的证明被打包晚了——例如,由于在我们做出证明后的第一个 slot 的出块者因离线而没有构建一个区块——那么打包奖励会与打包延迟时间呈反比递减。(即,它的比例会以1/2,然后是 1/3,然后是 1/4 这样递减下去) 因此,很容易算出,如果在一个 epoch 里 99% 的网络验证者都正确参与了,对我们完美验证者的正确率奖励的影响是比理想情况下减少 1%。但打包奖励会相对复杂一点。这归结于运气——如果本应在下一个 slot 打包了我们的证明的出块者碰巧是离线的 1%验证者的一员,那么我们的打包奖励会被砍半。如果我们特别运气不好,这种情况连续发生两次,那么我们的打包奖励会减少到1/3。 通过一个考虑了每种可能的延迟情况的等比数列之和来计算预期 (即平均) 的打包奖励 (这在之前 Herman Junge 的信标链建模里已经解释过)。如果 B 代表base_reward,P 代表参与率,我们可以算出预期奖励: 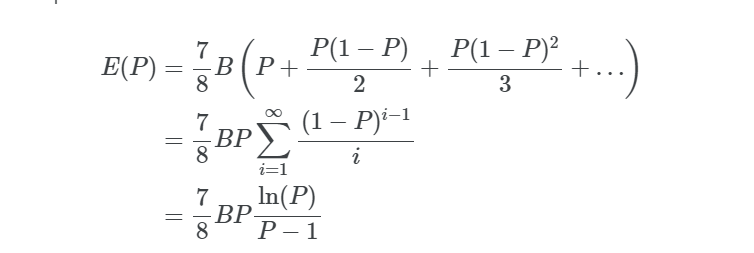 请注意,一个证明最晚可被打包到区块链的时间是 32 个 slot的延迟。因此,正确来说,我们应该把上面公式中的总项数设为 32 而不是无穷大。但是,如果参与率 P 很高 (例如像当前网络的 99%),那么求和到无穷大而不是 32 造成的误差是非常小的。 现在,让我们绘制一个完美验证者在不同参与率情况下的预期奖励线条,请记住,在信标链创世后的四个月里,参与率几乎没有低于 96%。 输入 6 # plot reward for perfect validator in several participation level contexts output: at P = 0.99, rewards fall by 0.89%at P = 0.98, rewards fall by 1.78%at P = 0.97, rewards fall by 2.68%at P = 0.96, rewards fall by 3.57% 输出: 当 P = 0.99,奖励减少 0.89%当 P = 0.98,奖励减少 1.78%当 P = 0.97,奖励减少 2.68%当 P = 0.96,奖励减少 3.57%  如上图和数据所示,我们的完美验证者获得收益下降幅度稍小于总体的网络参与率。 不完美验证者在完美网络里情况 如果我们的验证者实际上会在某些时候是离线的,那么他们将会错失一些奖励,而且也会因为错过做证明而遭受惩罚。每个正确率奖励有相应的惩罚——提供错误证明,或完全没有提供证明,证明中不正确的部分都会受到对应一项base_reward的惩罚。这意味着,错失证明导致的惩罚是3 * base_reward。为了了解这会有什么影响,设想一下你正在运行的验证者节点有时候会离线,但网络的其他所有验证者都表现完美。我们将忽略网络参与率实际上是低于 100% 这个事实,因为全网只有一个不完美验证者,而以完美网络来建模,尽管我们的验证者偶尔会离线。考虑到离线带来的惩罚,我们的收益会有什么影响? 作为一个完美验证者集的一部分,我们的验证者在线时预期会获得4 * base_reward,离线时遭遇的惩罚是 3 * base_reward。因此当用 B 代表base_reward、U 代表在线时间时,可得出净奖励 R: R = 4BU?3B(1?U) = B(7U?3)R 如果净奖励是 0,我们会得到: U=3/7≈43 这意味着只要验证者的在线时间不低于 43%,他就能获得正的净奖励。 输入 7 # plot expected reward for imperfect validator/perfect network at various validator set sizes 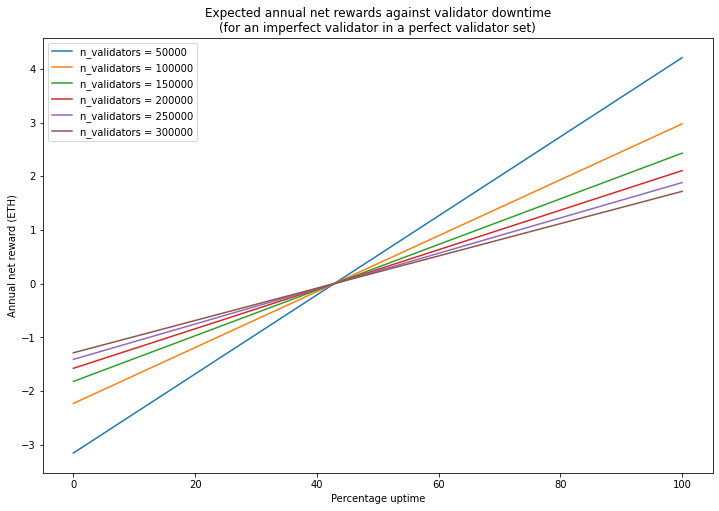 完整模型 把这些放在一起,我们就有了一个不完美验证者在一个不完美验证者集里运行的模型,其中 B 代表base_reward、P 代表参与率、U 代表\"我们的\"验证者的在线时间,我们可以得出: 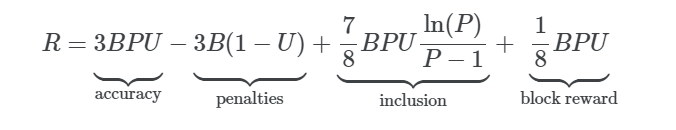 因此,例如如果你在一个有 100,000 个验证者、参与率为 99% 的网络里运行验证者节点,你的在线时间水平是 99%,你可以用这个模型来预估期望的净奖励: 输入8 # calculate annualised expected net reward for given parametersbase_reward = annualised_base_reward(100000)participation = 0.99uptime = 0.99net_reward = 3 * base_reward * participation * uptime \ - 3 * base_reward * (1 - participation) \ + (7/8) * base_reward * participation * uptime * math.log(participation) / (participation - 1) \ + (1/8) * base_reward * participation * uptime output: Net annual reward = 2.90 ETH (9.05% return on 32 ETH stake) 输出: 年净奖励 = 2.90 ETH (质押 32 个 ETH 的回报率是 9.05%) 为了便于实验,请看这个电子表格,从中你可以看到不同的参与率、在线时间水平和验证者数对净奖励的影响。 但是,再提醒一次,这个预期净奖励并没有考虑运气这个因素。随着我们的模型变得越来越复杂,除了一个给定 slot 里分配给区块提议者的随机机会,还有上面公式里的其他因素是受制于机会的。例如,由于下一个 epoch 的区块提议者刚好处于离线状态,就有获得较少打包奖励的风险,或者因为当分配到做区块提议者时你的验证者节点刚好处于离线状态,就会有错失出块的机会。这些额外的因素将稍微增加模型给出的”预期“情况下净奖励的变化。 鉴于打包奖励的非线性特性,把所有因素都放在公式里,像我们得出区块提议者机会般得出概率分布是很难的。通过运行蒙特卡洛模拟 (即使用随机数生成器模拟大量验证者,然后绘制出他们的净奖励图表) 可以对概率分布有一个大概的了解,但在此之前,让我们先把我们的模型与网络的真实情况做对比吧...... 结语 这已经是文章最后了,恭喜你!希望这篇文章能帮你理解信标链的奖励是为什么和怎么样有所不同的——无论是当验证者完美履行职责时,还是当他们并没有那么可靠地履行职责时。 从这个模型中得到的一个关键启示是,尽管可得奖励会依据网络上活跃验证者数产生很大的变化,但少量的离线时间对其影响是有限的。事实上,我们的研究显示在理想的网络里,只要验证者的在线时间水平超过 43%,他们就能获利。我们不会期待最低在线时间水平会比我们今天观察到的信标链的水平 (通常参与率是大约 99%)高很多。如果你在考虑在家质押自己的 ETH,这应该能让你放心——即使是大型的网络或电力中断,也不会对你一年的获利产生重大影响。 致谢 本文是在Ethereum Foundation Staking Community Grant 下写的,非常感谢Lakshman Sankar、Barnabé Monnot 和 Jim McDonald 的建议和反馈。图片由Unsplash的Cookie the Pom提供。 原文链接:https://pintail.xyz/posts/beacon-chain-validator-rewards/ ECN的翻译工作旨在为中国以太坊社区传递优质资讯和学习资源,文章版权归原作者所有,转载须注明原文出处以及ETH中文站。若需长期转载,请联系[email protected]进行授权。 —- 编译者/作者:ECN以太坊中文社区 玩币族申明:玩币族作为开放的资讯翻译/分享平台,所提供的所有资讯仅代表作者个人观点,与玩币族平台立场无关,且不构成任何投资理财建议。文章版权归原作者所有。 |
以太坊信标链验证者奖励
2021-07-04 ECN以太坊中文社区 来源:区块链网络
LOADING...
相关阅读:
- Swarm官方:目前尚未全部开放通道2021-07-04
- 币圈老柯:7.4大饼以太坊行情分析思路与方向2021-07-04
- 简明了解即将到来的以太坊EIP-1559:为何重要?影响几何?2021-07-04
- 王团长区块链日记1333篇:出逃的资金大于进场的资金2021-07-04
- 索罗斯做空或助大牛提前到来,今日短线继续看多,浅谈索罗斯的反身2021-07-04