AI 大模型开发公司 MosaicML 近日发布了新的可商用的开源大语言模型 MPT-30B,拥有 300 亿参数,其功能明显比前一代 MPT-7B 语言模型(70 亿参数)更强大,并且性能优于 GPT-3。  图片来源:由无界AI生成 此外,他们还发布了两个经过微调的模型:MPT-30B-Instruct 和 MPT-30B-Chat,它们构建在 MPT-30B 之上,分别擅长单轮指令跟踪和多轮对话。 MPT-30B 模型具有的特点: 训练时的 8k token 上下文(context)窗口通过 ALiBi 支持更长的上下文通过 FlashAttention 实现高效的推理 + 训练性能由于其预训练数据混合,MPT-30B 系列还具有强大的编码能力。该模型已扩展到 NVIDIA H100 上的 8k token 上下文窗口,使其成为第一个在 H100 上训练的LLM。 MPT-30B 强于 GPT-3?MPT-30B 是商业 Apache 2.0 许可的开源基础模型,强于原始的 GPT-3,并且与 LLaMa-30B 和 Falcon-40B 等其他开源模型具有竞争力。  (上图)MPT-30B 与 GPT-3 在九项上下文学习 (ICL) 任务上的零样本准确度。 MPT-30B 在九个指标中的六个指标上优于 GPT-3。 MosaicML 用 2 个月的时间训练了 MPT-30B,使用英伟达的 H100 GPU 集群进行训练。 如下图,MPT-30B 的训练数据: 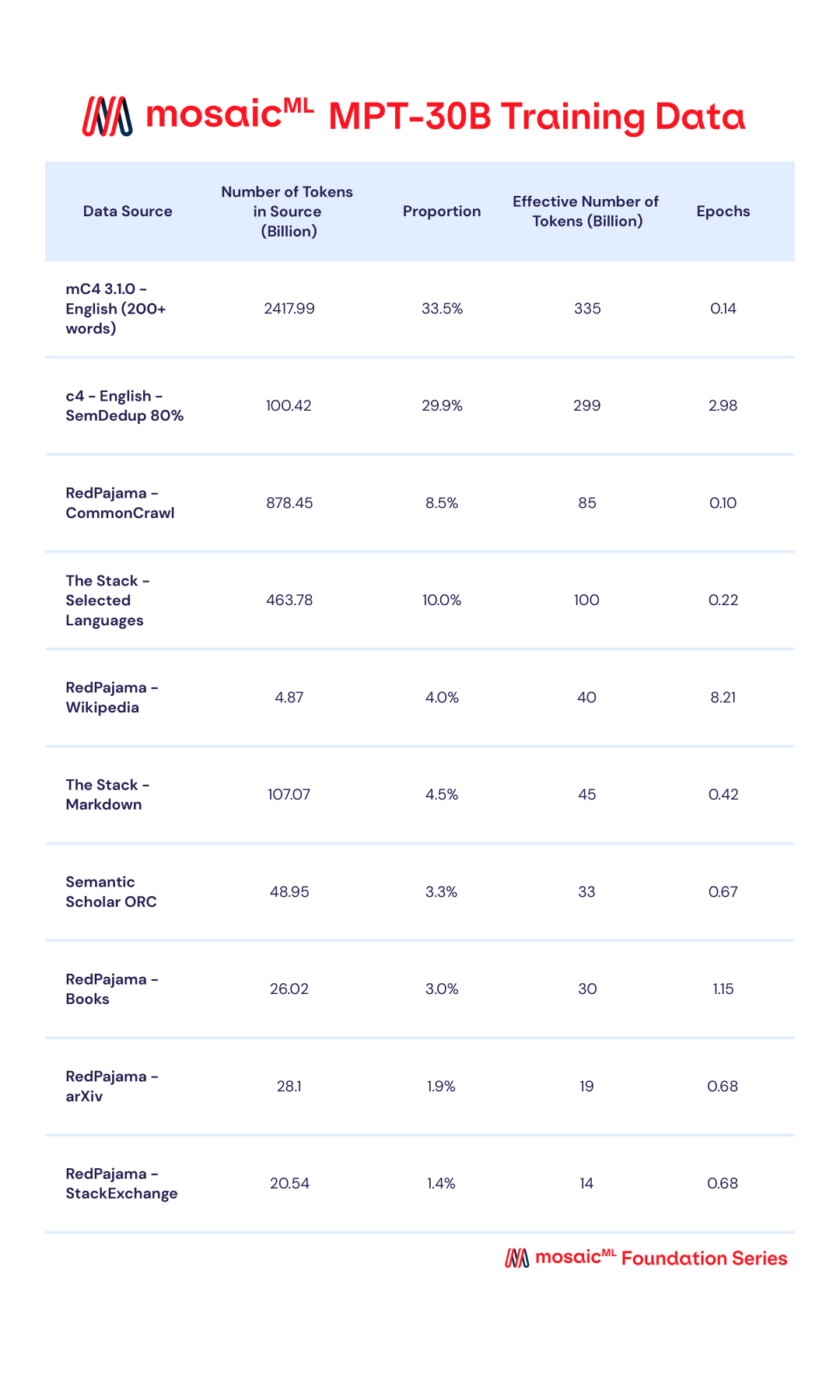 MPT-30B 通过数据混合进行预训练,从 10 个不同的开源文本语料库中收集了 1T 个预训练数据 token,并使用 EleutherAI GPT-NeoX-20B 分词器对文本进行分词,并根据上述比率进行采样。 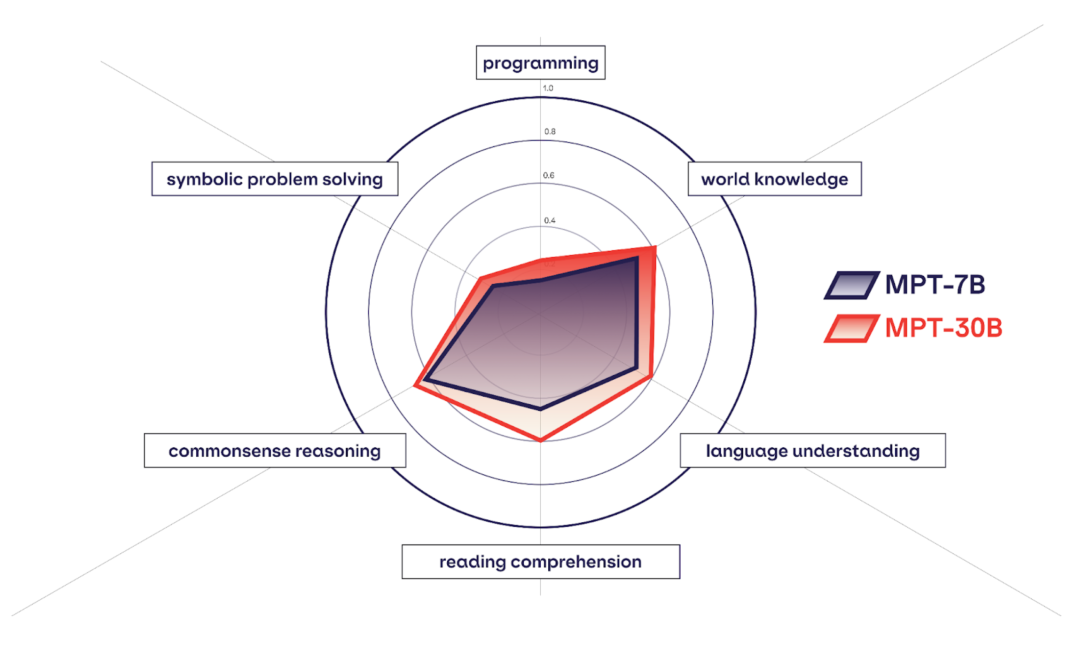 MPT-7B 与 MPT-30B 的对比 MPT-30B 训练成本MosaicML 公司的首席执行官兼联合创始人 Naveen Rao 表示,MPT-30B 的训练成本为 70 万美元(约 502.44 万元人民币),远低于 GPT-3 等同类产品所需的数千万美元训练成本。 训练定制的 MPT-30B 模型需要多少时间和金钱? 让我们从基本模型开始。 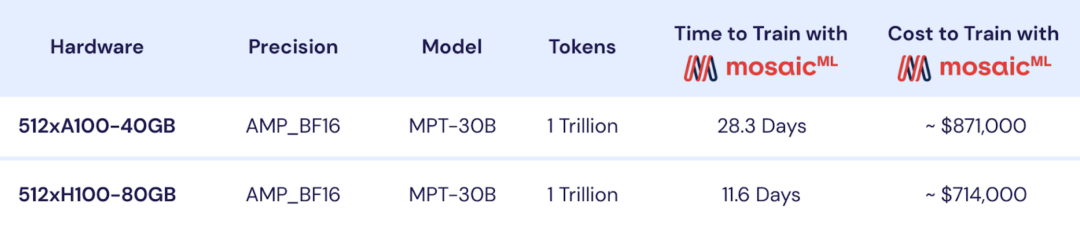 上图显示了使用 A100 或 H100 GPU 从头开始预训练 MPT-30B 的时间和成本。 借助 MosaicML 基础设施,您可以在 2 周内使用 1T token 从头开始训练您自己的自定义 MPT-30B。 如果您不想从头训练,只想微调现有模型呢? 下图详细列出了每个 1B token 微调 MPT-30B 的时间和成本。 借助 MosaicML 基础设施,您可以对 MPT-30B 模型进行全面微调,而无需担心系统内存限制,而且只需几百美元! 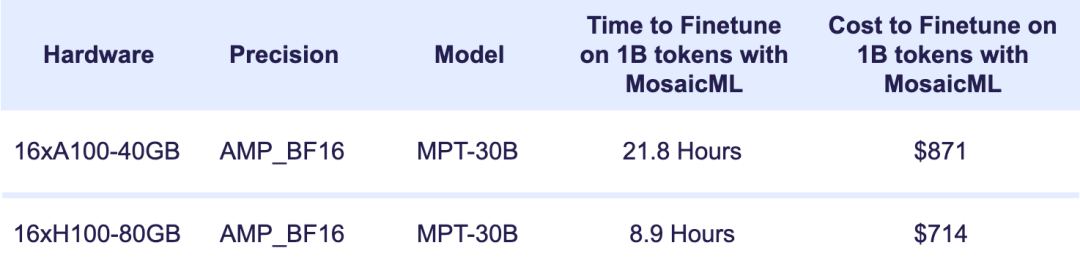 MosaicML 公司表示,将模型扩展到 300 亿参数只是第一步,接下来他们将以降低成本为前提,推出体积更大、质量更高的模型。 参考资料: https://www.mosaicml.com/blog/mpt-30b? —- 编译者/作者:Kyle 玩币族申明:玩币族作为开放的资讯翻译/分享平台,所提供的所有资讯仅代表作者个人观点,与玩币族平台立场无关,且不构成任何投资理财建议。文章版权归原作者所有。 |
开源且可商用,300 亿参数的 MPT-30B 大模型的成本仅为 GPT-3 的零头
2023-06-26 Kyle 来源:区块链网络
LOADING...
相关阅读:
- 李彦宏透露:文心大模型3.5版本训练速度提升2倍,推理速度提升17倍2023-06-26
- 张勇:“构建安全可信的人工智能”逐步成为行业共识,相关法律法规2023-06-26
- 张勇:“通义千问”已有超过 20 万企业用户申请接入2023-06-26
- 调查:AI 已成为近 50% 公司高管的“头号支出”2023-06-26
- 华为盘古大模型将于 7 月 7 日公布重大升级2023-06-26