近半年来,ChatGPT 所带来的 AI 热度是大家能直观感受到的。  图片来源:由无界AI 生成 其实,在不那么直观的地方,数据也在悄然发生变化:斯坦福大学发布的「2023 年 AI 指数报告」显示,2022 年采用 AI 的公司比例自 2017 年以来翻了一番以上。这些公司报告称,采用 AI 之后,它们实现了显著的成本降低和收入增加。 虽然 2023 年的数据还没出来,但仅凭被 ChatGPT 带火的 AIGC 领域就不难推测,上述数字将在今年迎来新的拐点。AIGC 大有掀起第四次产业革命之势。 但与此同时,这些企业在构建 AI 基础设施方面也迎来了新的挑战。 首先,就算力而言,AI 领域算力需求激增和供给不足形成的矛盾在今年变得尤其激烈,就连 OpenAI CEO Sam Altman 都坦言自家公司正被算力短缺问题困扰,其 API 的可靠性和速度问题屡遭投诉。此外,大批公司还面临这波需求高涨带来的算力成本上升问题。 其次,在模型的选择上,不少企业发现,当前讨论热度最高的大模型其实还没有一个成熟的商业模式,其安全性等方面还存在问题。以三星设备解决方案部门为例,他们在启用 ChatGPT 不到一个月的时间内,就发生了三起数据泄露事件,这让原本打算直接调用 OpenAI API 的企业打了退堂鼓。此外,自己训练、部署超大模型同样很劝退:想象一下,仅仅简单地向一个大模型发送一次请求,可能就需要昂贵的 GPU 卡进行独占性的运算,这是很多企业都难以承受的。 不过,话说回来,像 ChatGPT 那样「无所不知」的超大模型真的是企业所必需的吗?运行 AI 模型辅助业务就意味要疯狂扩充 GPU 规模吗?那些已经利用 AI 提升效益的企业是怎么做的?在分析了一些企业的最佳实践之后,我们找到了一些参考答案。 那些已经用上 AI 的公司:性能与成本的艰难抉择如果要分析最早应用人工智能提升效益的行业,互联网是绕不开的一个,其典型工作负载 —— 推荐系统、视觉处理、自然语言处理等 —— 的优化都离不开 AI。不过,随着业务量的激增,他们也在性能和成本等层面面临着不同的挑战。 首先看推荐系统。推荐系统在电子商务、社交媒体、音视频流媒体等许多领域都有广泛的应用。以电子商务为例,在每年的 618、双十一等购物高峰,阿里巴巴等头部电商企业都会面临全球庞大客户群发出的数亿实时请求,因此他们希望满足 AI 推理在吞吐量与时延方面的要求,同时又能确保 AI 推理精确性,保证推荐质量。 接下来看视觉处理,仅美团一家,我们就能找到智能图片处理、商户入驻证照识别、扫码开单车、扫药盒买药等多个应用场景。AI 已经成为其业务版图中很重要的一部分。不过,随着美团业务与用户量的高速增长,越来越多的应用需要通过视觉 AI 构建智能化流程,美团需要在保证视觉 AI 推理精度的同时,提升视觉 AI 推理的吞吐率,以支撑更多的智能化业务。  最后看自然语言处理。得益于 ChatGPT 带来的热度,自然语言处理正获得前所未有的市场关注与技术追踪。作为国内 NLP 技术研究的先行者,百度已在该领域构建起完整的产品体系与技术组合。ERNIE 3.0 作为其飞桨文心?NLP 大模型的重要组成部分,也在各种 NLP 应用场景,尤其是中文自然语言理解和生成任务中展现出卓越的性能。不过,随着 NLP 在更多行业中实现商业化落地,用户对 ERNIE 3.0 也提出了更多细分需求,例如更高的处理效率和更广泛的部署场景等。 所有这些问题的解决都离不开大规模的基础设施投入,但困扰这些企业的共同问题是:独立 GPU 虽然可以满足性能所需,但是成本压力较大,因此一味扩充 GPU 规模并不是一个最佳选项。 高性价比的解决方案:英特尔?第四代至强?可扩展处理器 AI 社区存在一个刻板印象:CPU 不适合承载 AI 任务。但 Hugging Face 首席传播官 Julien Simon 的一项展示打破了这种刻板印象。他所在的公司和英特尔合作打造了一个名为 Q8-Chat 的生成式 AI 应用,该应用能够提供类似 ChatGPT 的聊天体验,但仅需一个 32 核英特尔? 至强? 处理器就能运行。 就像这个例子所展示的,用 CPU 承载 AI 任务(尤其是推理任务)其实在产业界非常普遍,阿里巴巴、美团、百度都用相关方案缓解了算力问题。 阿里巴巴:用 CPU 助力下一代电商推荐系统,成功应对双十一峰值负载压力前面提到,阿里巴巴在电商推荐系统业务中面临 AI 吞吐量、时延、推理精确性等方面的多重考验。为了实现性能与成本的平衡,他们选择用 CPU 来处理 AI 推理等工作负载。 那么,什么样的 CPU 能同时顶住多重考验?答案自然是英特尔? 第四代至强? 可扩展处理器。 这款处理器于今年年初正式发布,除了一系列微架构的革新和技术规格的升级外,新 CPU 对 AI 运算「更上层楼」的支持也格外引人关注,尤其是英特尔在这代产品中增添的全新内置 AI 加速器 —— 英特尔高级矩阵扩展(AMX)。 在实际的工作负载中,英特尔? AMX 能够同时支持 BF16 和 INT8 数据类型,能够确保该 CPU 像高端通用图形处理器(GPGPU)一样处理 DNN 工作负载。BF16 动态范围与标准 IEEE-FP32 相同,但精度较 FP32 变低。在大多数情况下,BF16 与 FP32 格式的模型推理结果一样准确,但是由于 BF16 只需要处理 FP32 一半尺寸的数据,因此 BF16 吞吐量远高于 FP32,内存需求也大幅降低。 当然,AMX 本身的架构也是为加速 AI 计算所设计的。该架构由两部分组件构成:2D 寄存器文件(TILE)和 TILE 矩阵乘法单元(TMUL),前者可存储更大的数据块,后者是对 TILE 进行处理的加速单元,可在单次运算中计算更大矩阵的指令。 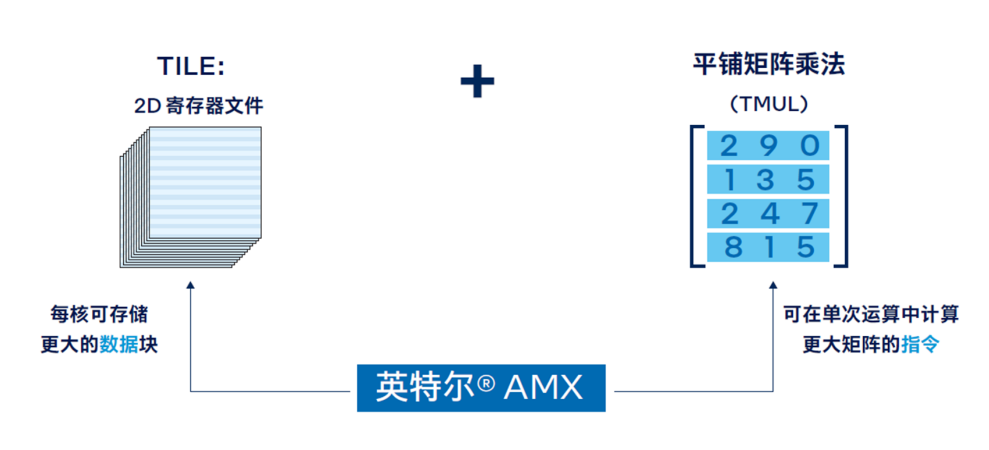 凭借这种新的架构,英特尔? AMX 实现了大幅代际性能提升。与运行英特尔? 高级矢量扩展 512 神经网络指令(AVX-512 VNNI)的第三代英特尔? 至强? 可扩展处理器相比,运行英特尔? AMX 的第四代英特尔? 至强? 可扩展处理器将单位计算周期内执行 INT8 运算的次数从 256 次提高至 2048 次,执行 BF16 运算的次数为 1024 次 ,而第三代英特尔? 至强? 可扩展处理器执行 FP32 运算的次数仅为 64 次。 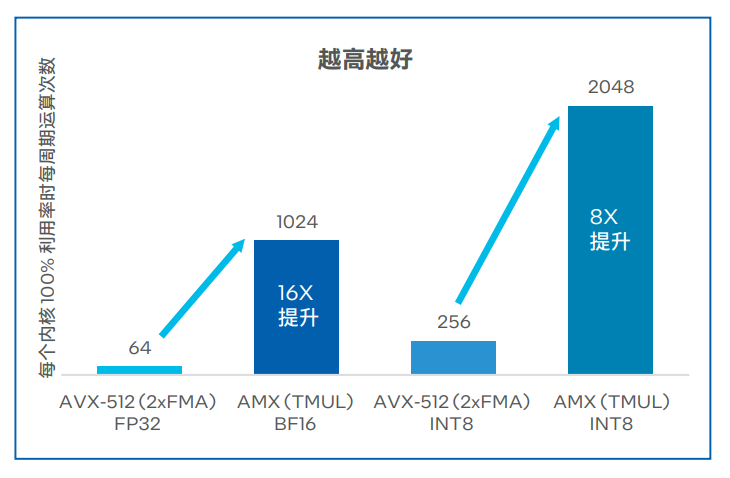 英特尔? AMX 的高级硬件特性为阿里巴巴的核心推荐模型带来了 AI 推理性能突破,并保证了足够的精度。此外,阿里巴巴还使用英特尔? oneAPI 深度神经网络库 (英特尔? oneDNN),将 CPU 微调到峰值效率。 下图显示,在 AMX、BF16 混合精度、8 通道 DDR5、更大高速缓存、更多内核、高效的内核到内核通信和软件优化的配合下,主流的 48 核第四代英特尔? 至强? 可扩展处理器可以将代理模型的吞吐量提升到 2.89 倍 ,超过主流的 32 核第三代英特尔? 至强? 可扩展处理器,同时将时延严格保持在 15 毫秒以下,推理精度依然能够满足需求。 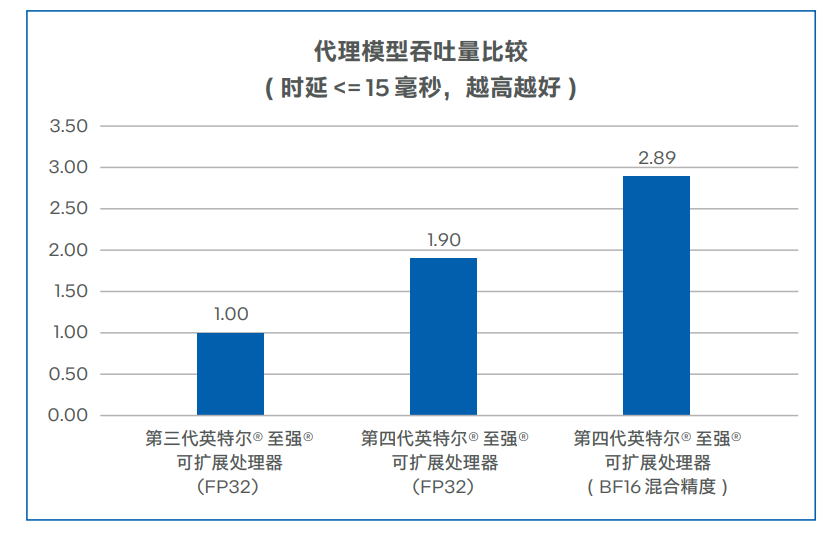 优化后的软件和硬件已经部署在阿里巴巴的真实业务环境中, 它们成功通过了一系列验证,符合阿里巴巴的生产标准,包括应对阿里巴巴双十一购物节期间的峰值负载压力。 而且,阿里巴巴发现,升级为第四代英特尔? 至强? 可扩展处理器带来的性能收益远高于硬件成本,投资收益非常明显。 美团:用 CPU 承载低流量长尾视觉 AI 推理,服务成本直降 70%前面提到,美团在业务扩展中面临视觉 AI 推理服务成本较高的挑战。其实,这个问题并非铁板一块:部分低流量长尾模型推理服务的负载压力与时延要求是相对较低的,完全可以用 CPU 来承载。 在多个视觉 AI 模型中,美团通过采用英特尔? AMX 加速技术,动态将模型数据类型从 FP32 转换为 BF16,从而在可接受的精度损失下,增加吞吐量并加速推理。 为了验证优化后的性能提升,美团将使用英特尔? AMX 加速技术转换后的 BF16 模型,与基准 FP32 模型的推理性能进行了比较。测试数据下图所示,在将模型转化为 BF16 之后,模型推理性能可实现 3.38-4.13 倍的提升,同时 Top1 和 Top5 精度损失大部分可以控制在 0.01%-0.03%。 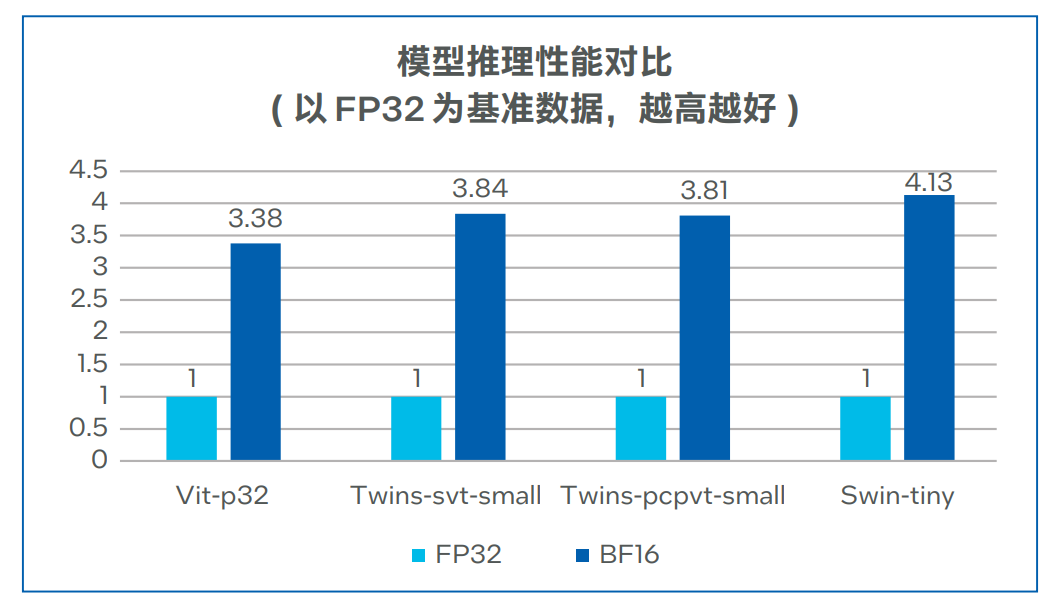 得益于性能的提升,美团能够更加充分地释放现有基础设施的潜能,降低在 GPU 部署与运维方面的高昂成本,并节省 70% 的服务成本。 百度:将蒸馏后的模型跑在 CPU 上,解锁更多行业、场景众所周知,模型中更多的层数、参数意味着更大的模型体积、更强的计算资源需求以及更长的推理耗时,对于业务响应速度和构建成本敏感的用户而言,无疑提高了引入和使用门槛。因此,在 NLP 领域,模型小型化是一个常见的优化方向。 百度也采用了这一做法,借助模型轻量化技术对 ERNIE 3.0 大模型进行蒸馏压缩,从而将其推广到更多行业与场景 。这些轻量版的模型(ERNIE-Tiny)不仅响应迅速,还有一个重要优势:无需昂贵的专用 AI 算力设备就能部署。因此,引入更强的通用计算平台和优化方案,就成了助力 ERNIE-Tiny 获得更优效率的另一项重要手段。 为此,百度与英特尔展开深度技术合作:一方面将第四代英特尔? 至强? 可扩展处理器引入 ERNIE-Tiny 的推理计算过程;另一方面,也推进了多项优化措施,例如通过英特尔? oneAPI 深度神经网络库来调用英特尔? AMX 指令等,以确保 ERNIE-Tiny 可以更为充分地利用 AMX 带来的性能加速红利。 来自对比测试的数据表明,相比通过英特尔? AVX-512_VNNI 技术来实现 AI 加速的、面向单路和双路的第三代英特尔? 至强? 可扩展处理器,ERNIE-Tiny 在升级使用内置英特尔? AMX 技术的第四代英特尔? 至强? 可扩展处理器后,其整体性能提升高达 2.66 倍,取得了令人满意的效果。 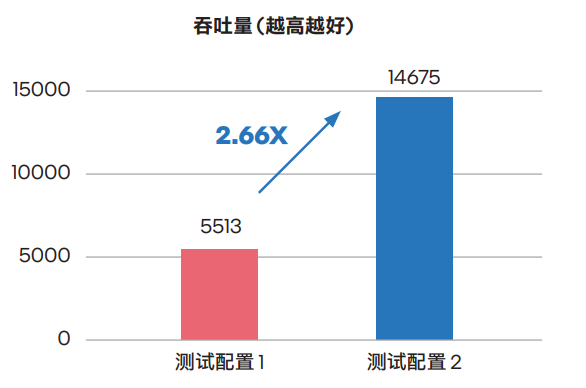 目前,各个 ERNIE-Tiny 不仅已部署在零门槛 AI 开发平台 EasyDL、全功能 AI 开发平台 BML 和 ERNIEKit (旗舰版) 产品中,它们也将与平台和产品的其它能力一起协同,在基于第四代英特尔? 至强? 可扩展处理器的基础设施上,为 使用者提供文本分类、关系抽取、文本生成以及问答等能力。 从阿里巴巴、美团、百度的实践经验可以看到,在真实的生产环境中,真正发挥作用的依然是一些规模没那么大的 AI 模型。这些模型的部署已经有了可借鉴的成熟方案,可以借助英特尔? 至强? CPU 以及配套的软硬件加速方案获得显著的成本效益。 当然,随着 AIGC 的强势崛起,不少企业也将目光瞄准了这类大一些的模型。但正如前面所讨论过的,无论是调用超大模型 API 还是自己训练、部署都有各自的问题,如何选择一种经济、高效又安全的解决方案是摆在企业面前的棘手难题。 AIGC 时代已来,企业如何应对??企业拥抱 AIGC 就意味着一定要有一个「无所不知」的超大模型吗?对此,波士顿咨询公司(BCG)给出的答案是否定的。 他们选择的解决方案是利用自己的数据训练一个行业专用模型。这个模型可能没有那么大,但可以洞察 BCG 过去 50 多年中高度保密的专有数据。同时,所有的 AI 训练和推理都完全符合 BCG 的安全标准。 这套解决方案的背后是一台英特尔 AI 超级计算机,该计算机搭载英特尔??第四代至强? 可扩展处理器和 Habana? Gaudi2? AI 硬件加速器,前者在 PyTorch 上的 AI 训练性能最高能提升到上一代产品的 10 倍,后者在计算机视觉(ResNet-50)和自然语言处理(BERT 微调)方面的表现优于英伟达 A100,在计算机视觉方面几乎与 H100 不分伯仲。二者强强联合,为 BCG 提供了一套经济高效的 AIGC 解决方案。 在一个聊天机器人界面上,BCG 员工能够从冗长的多页文档列表中,通过语义搜索来检索、提取并汇总有效信息。BCG 报告称,这与现有的关键字搜索解决方案相比,其用户满意度提高了 41%,结果准确性增长了 25%,工作完成率提高了 39%。 由此可见,无论是传统的中小规模 AI,还是当前颇有前景的 AIGC 行业大模型,GPU 都不是 AI 加速的唯一选择。但无论是何种规模的模型,英特尔都给出了颇具性价比的软硬件组合解决方案。 对于想要应用 AI 提升效益的企业来说,选择何种规模的模型、搭建怎样的软硬件基础设施都没有标准答案,所谓的超大模型、超大 GPU 算力集群可能都非必需。根据业务特点和属性选择适合自己的技术方案才是实现最优解的重要因素。 参考链接: https://www.intel.cn/content/www/cn/zh/artificial-intelligence/amx-tencent-bert-model-search-applications.html https://www.intel.cn/content/www/cn/zh/cloud-computing/alibaba-e-comm-recommendation-system-enhancement.html —- 编译者/作者:机器之心 玩币族申明:玩币族作为开放的资讯翻译/分享平台,所提供的所有资讯仅代表作者个人观点,与玩币族平台立场无关,且不构成任何投资理财建议。文章版权归原作者所有。 |
成本直降70%的秘密:这些企业找到了一种高性价比的AI打开方式
2023-06-28 机器之心 来源:区块链网络
LOADING...
相关阅读:
- 恒生电子首次发布金融大模型 LightGPT2023-06-28
- 微软用 AI 缩短癌症放疗时间:扫描速度提高 2.5 倍,准确率达 90%2023-06-28
- AI 图像编辑技术 DragGAN 已在 GitHub 中开源2023-06-28
- 中国联通董事长刘烈宏:2 年内 50% 的工作将受到人工智能的深刻影响2023-06-28
- 中国联通发布图文大模型,可实现以文生图、视频剪辑2023-06-28