来源:新智元 导读:黄老板又赢麻了!在最新的MLPerf基准测试中,H100成功创下8项测试纪录。而外媒透露,下一代消费级显卡或在2025发布。 最新MLPerf训练基准测试中,H100 GPU在所有的八项测试中都创下了新纪录! 如今,NVIDIA H100几乎已经统治了所有类别,并且是新LLM基准测试中使用的唯一 的GPU。  3,584个H100 GPU群在短短11分钟内完成了基于GPT-3的大规模基准测试。 MLPerf LLM基准测试是基于OpenAI的GPT-3模型进行的,包含1750亿个参数。 Lambda Labs估计,训练这样一个大模型需要大约3.14E23 FLOPS的计算量。  11分钟训出GPT-3的怪兽是如何构成的 11分钟训出GPT-3的怪兽是如何构成的在LLM和BERT自然语言处理 (NLP) 基准测试中排名最高的系统,是由NVIDIA和Inflection AI联合开发。 由专门从事企业级GPU加速工作负载的云服务提供商CoreWeave托管。 该系统结合了3584个NVIDIA H100加速器和896个Intel Xeon Platinum 8462Y+处理器。  因为英伟达在H100中引入了新的Transformer引擎,专门用于加速Transformer模型训练和推理,将训练速度提高了6倍。 CoreWeave从云端提供的性能与英伟达从本地数据中心运行的AI超级计算机所能提供的性能已经非常接近了。 这得益于CoreWeave使用的NVIDIA Quantum-2 InfiniBand网络具有低延迟网络。  随着参与训练的H100 GPU从数百个扩展到3000多个。 良好的优化使得整个技术堆栈在要求严苛的LLM测试中实现了近乎线性的性能扩展。 如果将GPU的数量降低到一半,训练相同的模型时间会增加到24分钟。 说明整个系统的效率潜力,随着GPU的增加,是超线性的。 最主要的原因是,英伟达从GPU设计之初就考虑到了这个问题,使用NVLink技术来高效实现了GPU之间的通信。 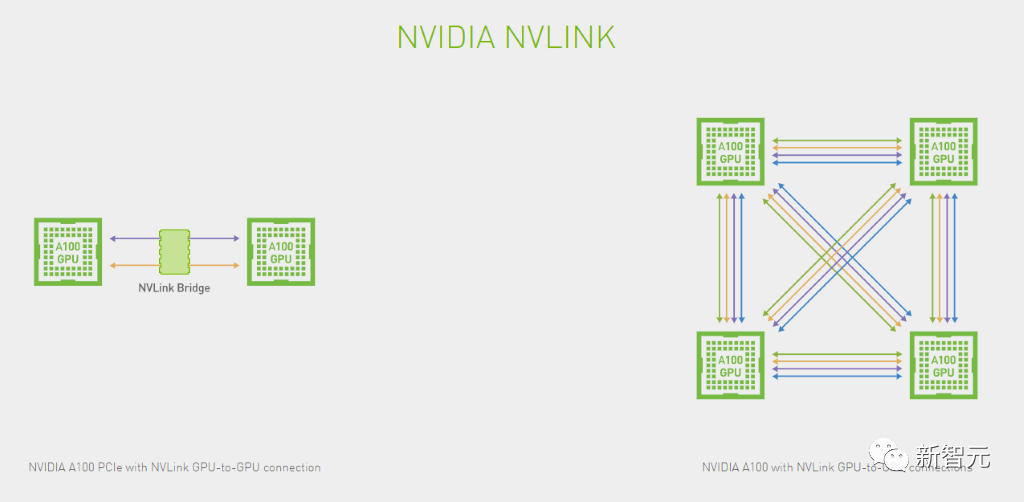 在参与测试的90个系统中,有82个系统都使用了英伟达的GPU进行加速。 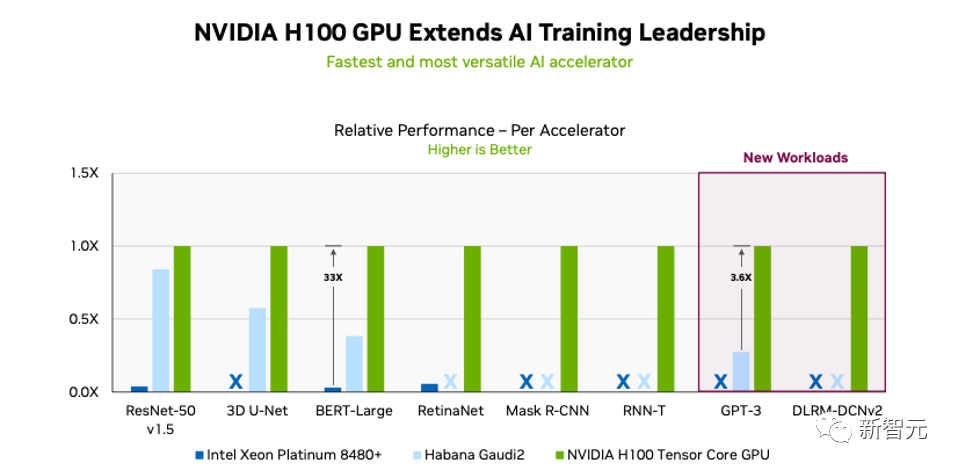 单卡训练效率 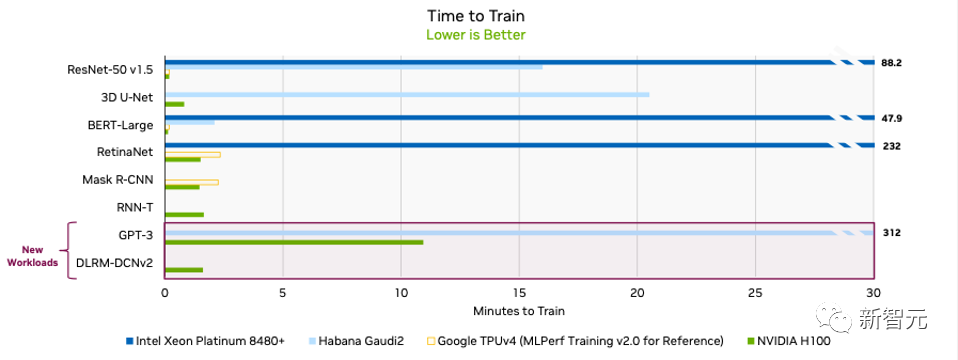 系统集群训练时间对比 英特尔参加测评的系统使用64到96个不等的Intel Xeon Platinum 8380 处理器和256到389个不等的Intel Habana Gaudi2加速器。 然而,英特尔提交的GPT-3的训练时间为311分钟。 成绩和英伟达相比就稍微有点惨不忍睹了。  分析师:英伟达优势过大 分析师:英伟达优势过大行业分析师认为,英伟达的在GPU上的技术优势是非常明显的。 而它作为AI基础设施提供商,在行业中的主导地位还体现在英伟达多年建立起来的生态系统粘性上。 AI社区对英伟达的软件的依赖性也非常强。 几乎所有AI框架都基于英伟达提供的底层CUDA库和工具。  而且它还能提供全堆栈的AI工具和解决方案。 除了为AI开发人员提供支持之外,英伟达还继续投资用于管理工作负载和模型的企业级工具。 在可预见的未来,英伟达在行业的领先地位将会非常稳固。 分析师还进一步指出MLPerf测试结果中所展现的,NVIDIA系统在云端进行AI训练的强大功能和效率,才是英伟达「战未来」的最大本钱。  下一代Ada LovelaceGPU,2025年发布 下一代Ada LovelaceGPU,2025年发布Tom's Hardware自由撰稿人Zhiye Liu也于近日发文,介绍了下一代英伟达Ada Lovelace显卡的计划。 H100训练大模型的能力,毋庸置疑。 只用3584个H100,短短11分钟内,就能训练出一个GPT-3模型。 在最近的新闻发布会上,英伟达分享了一份新路线图,详细介绍了下一代产品,包括GeForce RTX 40系列Ada Lovelace GPU的继任者,而前者,是当今最好的游戏显卡。 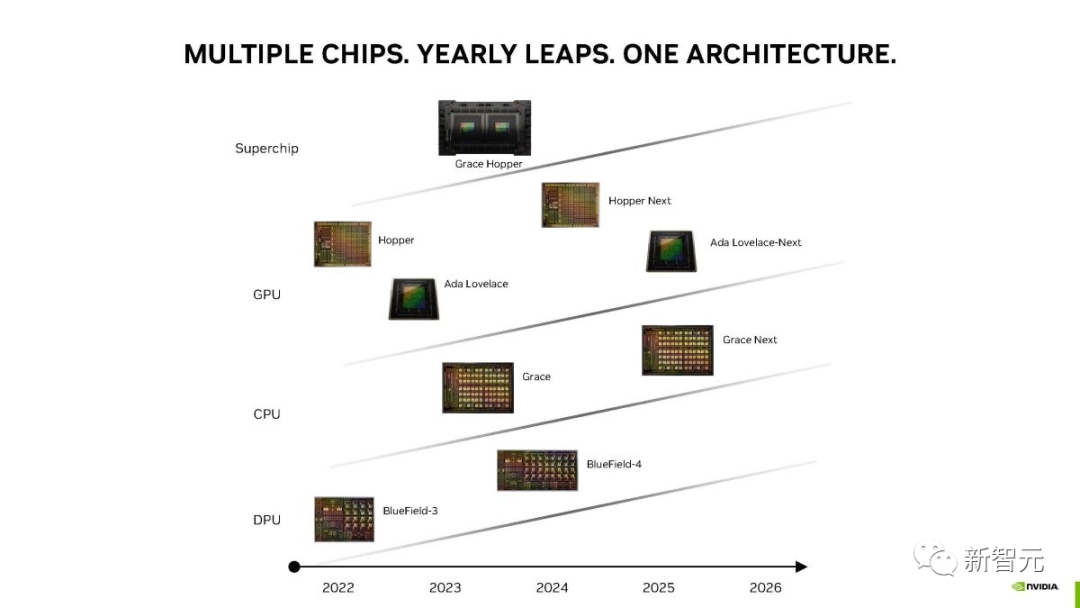 根据路线图,英伟达计划在2025年推出「Ada Lovelace-Next」显卡。 如果继续沿用当前的命名方案,下一代GeForce产品应该是作为GeForce RTX 50系列上市。 根据南美黑客组织LAPSU$得到的信息,Hopper Next很可能被命名为Blackwell。 在消费级显卡上,英伟达保持着两年一更新的节奏。 他们在2016年推出了Pascal,在2018年推出了Turing,在2020年推出了Ampere,在2022年推出了Ada Lovelace。 如果这次Ada Lovelace的继任者会在2025年推出,英伟达无疑就打破了通常的节奏。  最近的AI大爆发,产生了对英伟达GPU的巨大需求,无论是最新的H100,还是上一代的A100。 根据报道,某大厂今年就订购了价值10亿美元的Nvidia GPU。 尽管有出口限制,但我国仍然是英伟达在全世界最大的市场之一。 (据说,在深圳华强北电子市场,就可以买到少量英伟达A100,每块售价为2万美元,是通常价格的两倍。) 对此,英伟达已经对某些AI产品做了微调,发布了H100或A800等特定SKU,以满足出口要求。  Zhiye Liu对此分析道,换个角度看,出口法规其实是有利于英伟达的,因为这意味着芯片制造商客户必须购买更多原版GPU的变体,才能获得同等的性能。 这也就能理解,为什么英伟达会优先考虑生成计算GPU,而非游戏GPU了。 最近的报道显示,英伟达已经增加了计算级GPU的产量。 没有面临来自AMD的RDNA 3产品堆栈的激烈竞争,英特尔也没有对GPU双头垄断构成严重威胁,因此,英伟达在消费侧可以拖延。  最近,Nvidia通过GeForce RTX 4060和GeForce RTX 4060 Ti,将其GeForce RTX 40系列产品堆栈又扩大了。 GeForce RTX 4050以及顶部的RTX 4080 Ti或GeForce RTX 4090 Ti等,都有潜力。 如果迫不得已,英伟达还可以从旧的Turing版本中拿出一个产品,更新Ada Lovelace,给它封个「Super」待遇,进一步扩展Ada阵容。 最后,Zhiye Liu表示,至少今年或明年,Lovelace架构不会真正更新。 参考资料: https://blogs.nvidia.com/blog/2023/06/27/generative-ai-debut-mlperf/ —- 编译者/作者:AI之势 玩币族申明:玩币族作为开放的资讯翻译/分享平台,所提供的所有资讯仅代表作者个人观点,与玩币族平台立场无关,且不构成任何投资理财建议。文章版权归原作者所有。 |
11分钟训完GPT-3!英伟达H100 横扫MLPerf 8项基准测试,下一代显卡25年发布
2023-06-29 AI之势 来源:区块链网络
LOADING...
相关阅读:
- 恒生电子首次发布金融大模型 LightGPT2023-06-28
- ChatGPT 板块震荡走低,拓尔思跌超 10%2023-06-28
- 软银 CEO 孙正义:正开发日本版 ChatGPT,如果不能拥抱 AI 便是失去未来2023-06-27
- 朱啸虎:ChatGPT对创业公司很不友好,未来两三年内请大家放弃融资幻想2023-06-26
- 开源且可商用,300 亿参数的 MPT-30B 大模型的成本仅为 GPT-3 的零头2023-06-26