现阶段,AI 智能体仿佛无所不能,玩游戏、模仿人类完成各种任务,而这些智能体基本是在复杂环境中训练而成的。不仅如此,随着学习任务变得越来越复杂,模拟环境的复杂性也随之增加,从而增加了模拟环境的成本。 即使拥有超级计算规模资源的公司和机构,训练好一个可用的智能体也可能需要数天的时间才能完成。 这阻碍了该领域的进展,降低了训练先进 AI 智能体的实用性。为了解决环境模拟的高成本问题,最近的研究努力从根本上重新设计模拟器,以在训练智能体时实现更高的效率。这些工作共享批量模拟的思想,即在单个模拟器引擎内同时执行许多独立的环境(训练实例)。 本文,来自斯坦福大学等机构的研究者,他们提出了一个名为 Madrona 的强化学习游戏引擎,可以在单个 GPU 上并行运行数千个环境,将智能体的训练时间从几小时缩减到几分钟。  论文地址:https://madrona-engine.github.io/shacklett_siggraph23.pdf论文主页:https://madrona-engine.github.io/? 论文地址:https://madrona-engine.github.io/shacklett_siggraph23.pdf论文主页:https://madrona-engine.github.io/?具体而言,Madrona 是一款研究型游戏引擎,专为创建学习环境而设计,可以在单个 GPU 上同时运行数千个环境实例,并且以极高的吞吐量(每秒数百万个聚合步骤)执行。Madrona 的目标是让研究人员更轻松地为各种任务创建新的高性能环境,从而使 AI 智能体训练的速度提高几个数量级。 Madrona 具有以下特点: GPU 批量模拟:单个 GPU 上可运行数千个环境;实体组件系统 (ECS) 架构;可与 PyTorch 轻松互操作。 Madrona 环境示例:  上面我们已经提到,该研究利用了 ECS 设计原则,其具体过程如下: 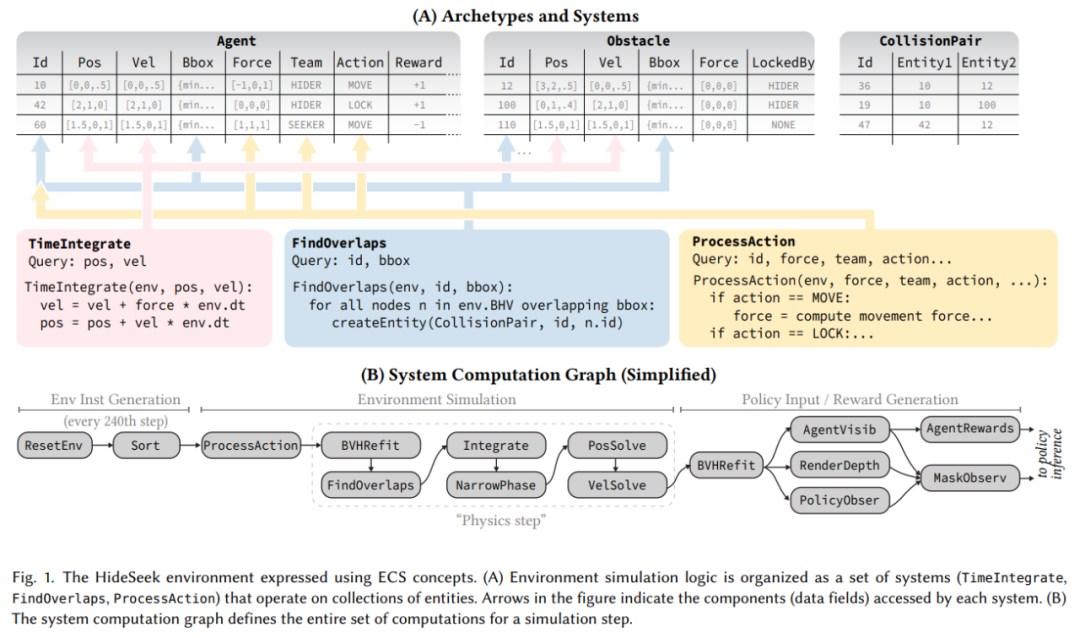 研究者借助 Madrona 框架,实现了多个学习环境,结果表明,相较于开源 CPU 基线,GPU 的速度提升达到了两到三个数量级,相较于在 32 线程 CPU 上运行的强基线,速度提升为 5-33 倍。此外,该研究还在该框架中实现了 OpenAI 的「hide and seek 3D」环境,每个模拟步骤都执行刚体物理学和光线追踪,在单个 GPU 上实现了每秒超过 190 万个 step 速度。 作者之一、斯坦福大学计算机科学副教授 Kayvon Fatahalian 表示,在一款让多个智能体玩烹饪游戏 Overcooked 上,借助 Madrona 游戏引擎,模拟 800 万个环境步骤的时间从一小时缩短到三秒。  目前,Madrona 需要使用 C++ 来编写游戏逻辑。Madrona 仅提供了可视化渲染支持,虽然它可以同时模拟数千个环境,但可视化器一次只能查看一个环境。 基于 Madrona 搭建的环境模拟器有哪些? Madrona 本身不是一个 RL 环境模拟器,而是一个游戏引擎或框架。开发者借助它可以更容易地实现自己的新的环境模拟器,从而通过在 GPU 上运行批次模拟并将模拟输出与学习代码紧密结合来实现高性能。 下面是基于 Madrona 搭建的一些环境模拟器。 Madrona Escape Room Madrona Escape Room 是一个简单的 3D 环境,使用了 Madrona 的 ECS API 以及物理和渲染功能。在这个简单任务中,智能体必须学习按下红色按钮并推动其他颜色的箱子以通过一系列房间。  Overcooked AI Overcooked AI 环境是一个基于协作电子游戏的多智能体学习环境(多人协作烹饪游戏),这里对它进行了高通量 Madrona 重写。  图源:https://store.epicgames.com/zh-CN/p/overcooked? Hide and Seek 2019 年 9 月,OpenAI 智能体上演了捉迷藏攻防大战,自创套路与反套路。这里使用 Madrona 对「Hide and Seek」环境进行了复现。  Hanabi Hanabi 是一个基于 Madrona 游戏引擎的 Hanabi 纸牌游戏的实现,也是一个协作式 Dec-POMDP。该环境基于 DeepMind 的 Hanabi 环境,并支持部分 MAPPO 实现。 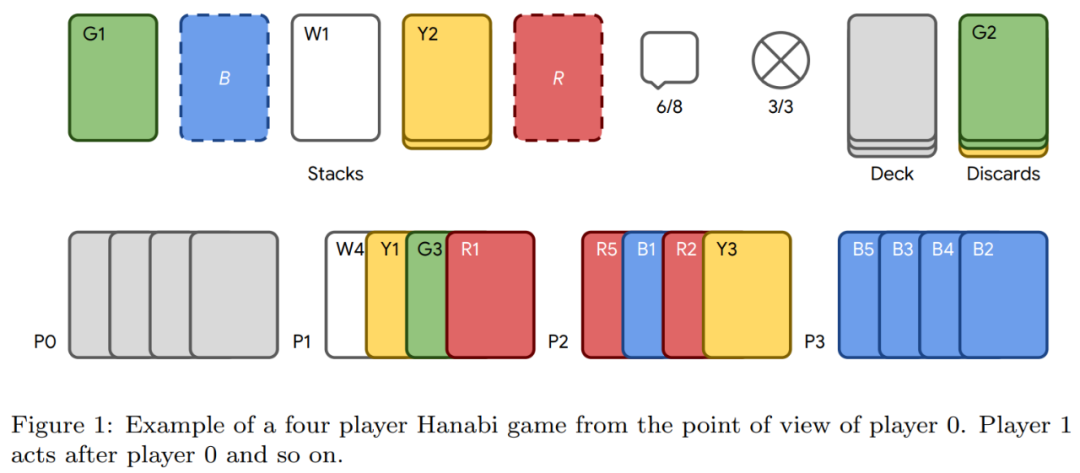 Cartpole Cartpole 是一个典型的 RL 训练环境,它与构建在 Madrona 游戏引擎之上的 gym 实现有相同的动力学。 GitHub 地址:https://github.com/shacklettbp/madrona? Overcooked 烹饪游戏:一分钟内训练最佳智能体 Overcooked in Thousands of Kitchens: Training Top Performing Agents in Under a Minute 论文作者之一、斯坦福大学本科生 Bidipta Sarkar 撰写博客详细介绍了训练智能体玩 Overcooked 烹饪游戏的过程。Overcooked 是一款流行的烹饪游戏, 也可以作为协作多智能体研究的基准。  在 Sarkar 的 RL 研究中,模拟虚拟环境的高成本对他来说始终是训练智能体的一大障碍。 就 Overcooked 烹饪游戏而言,大约需要 800 万步的游戏经验,才能训练一对在 Overcooked 狭窄房间布局(下图)中收敛到稳定均衡策略的智能体。Overcooked 的开源实现使用 Python 编写,在 8 核 AMD CPU 上每秒运行 2000 步,因此生成必要的智能体经验需要花费 1 个小时以上。  相比之下,在英伟达 A40 GPU 上执行训练所需的所有其他操作(包括所有 800 万个模拟步骤的策略推理、策略训练的反向传播)仅需不到 1 分钟的时间。很显然,训练 Overcooked 智能体受限于 Overcooked 环境模拟器的速度。 考虑到 Overcooked 是一个简单的环境,让模拟速度难住似乎很愚蠢。因此 Sarkar 试着看看 Overcooked 环境模拟的速度是否可以提升,这就需要用到 Madrona 游戏引擎。 利用 Madrona 游戏引擎,Sarkar 得到了一个原始 Overcooked Python 实现的即插即用的 GPU 加速版替代。当并行模拟 1000 个 Overcooked 环境时,GPU 加速后的实现在 A40 GPU 上每秒可以生成 350 万步经验。 作为结果,模拟 800 万个环境步骤的时间从 1 小时缩短至了 3 秒,从而可以使用 A40 GPU 在短短 1 分钟内训练一个策略。 该模拟器的速度为在 Overcooked 中执行广泛的超参数扫描打开了新的可能性,尤其是在以往训练单个策略所需的时间内有了训练多个策略的可能。 最后,Sarkar 意识到与创建 GPU 加速环境的现有替代方案(如 PyTorch、Taichi Lang、Direct CUDA C++)相比,将 Overcooked 移植到 Madrona 的过程更加地顺利。 博客详情:https://bsarkar321.github.io/blog/overcooked_madrona/index.html? 参考链接:https://madrona-engine.github.io/? —- 编译者/作者:机器之心 玩币族申明:玩币族作为开放的资讯翻译/分享平台,所提供的所有资讯仅代表作者个人观点,与玩币族平台立场无关,且不构成任何投资理财建议。文章版权归原作者所有。 |
单GPU运行数千环境、800万步模拟只需3秒,斯坦福开发超强游戏引擎
2023-08-09 机器之心 来源:区块链网络
LOADING...
相关阅读:
- 丘成桐弟子杨格:ChatGPT时代「乱世出英雄」,下一步要多用数学科学数2023-08-09
- 至少手握8个大模型,AI时代杭州如何趁势而上?2023-08-09
- 360 与 8 家企业签署大模型战略应用合作协议2023-08-09
- 软通动力孙洪军:重视解决金融 AI 大模型应用所有权和安全问题2023-08-06
- Meta商用开源最牛大模型背后:巨头保命式竞争,马斯克、苹果另辟蹊径2023-08-05