


巴比特讯,8 月 12 日,天津大学和信创海河实验室举办“大模型技术与评测研讨会”,会上天津大学发布首份《大模型评测报告》,对国内外主流的 14 个大语言模型进行中文综合能力评测,结果显示,GPT-4 和百度文心一言相较于其他模型综合性能显著领先,两者得分相差不大,处于同一水平。 据了解,参与本次评测的大模型包括 GPT-4、ChatGPT gpt-3.5-turbo、Claude-instant、Sage gpt-3.5-turbo 等国外大模型,以及百度文心一言、阿里通义千问、讯飞星火认知大模型、ChatGLM-6B、360 智脑、MOSS-16B、MiniMax、baichuan-7B 等国产大模型。评测使用一套涵盖知识问答、语言表达、逻辑推理、常识问答、文本问答、机器翻译等不同领域知识、包含多种题型的中文综合性试题,通过多维度得分结果,清楚了解不同模型的擅长领域和综合能力优劣。 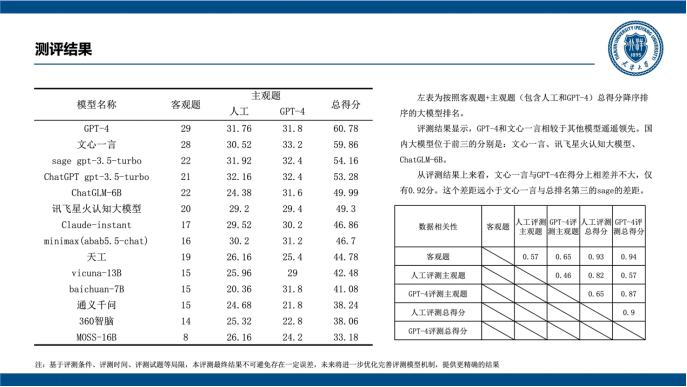
—- 编译者/作者:Yangz 玩币族申明:玩币族作为开放的资讯翻译/分享平台,所提供的所有资讯仅代表作者个人观点,与玩币族平台立场无关,且不构成任何投资理财建议。文章版权归原作者所有。 |
天津大学发布《大模型评测报告》,GPT-4 和百度文心一言排名领先
2023-08-14 Yangz 来源:区块链网络
相关阅读:
- 万兴科技与科大讯飞达成星火大模型战略合作,旗下多产品将入驻星火2023-08-14
- 一周AIGC丨OpenAI可能在2024年破产,中国互联网巨头们豪掷50亿美元疯抢2023-08-14
- 云从科技推出 AI 鼠标“众寻 V1 PRO”,内置从容大模型2023-08-14
- 挑战英伟达,这家独角兽又募了1亿美金2023-08-14
- 腾讯科技在绵阳成立新公司,经营范围含 AI 软件开发2023-08-14

