来源:AIGC开放社区 9月14日,著名开源平台Stability AI在官网发布了,音频生成式AI产品Stable Audio。(免费使用地址:https://www.stableaudio.com/generate) 用户通过文本提示就能直接生成摇滚、爵士、电子、嘻哈、重金属、民谣、流行、朋克、乡村等20多种类型背景音乐。 例如,输入迪斯科、鼓机、合成器、贝司、钢琴、吉他、欢快、115 BPM等关键词,就能生成背景音乐。 目前,Stable Audio有免费和付费两个版本:免费版,每月可生成20个音乐,最大时长45秒,不能用于商业;付费版,每月11.99美元(约87元),可生成500个音乐,最大时长90秒,可用于商业。 如果你不想付费可以多注册几个账号,可以通过AU(一种音频编辑器)或PR将生成的音乐拼接起来可达到同样效果。  Stable Audio简单介绍 Stable Audio简单介绍在过去几年,扩散模型在图像、视频、音频等领域获得了飞速发展,可显著提升训练和推理效率。但音频领域的扩散模型存在一个问题,通常会生成固定大小的内容。 例如,音频扩散模型可能在30秒的音频片段上进行训练,并且只能生成30秒的音频片段。为了打破这个技术瓶颈Stable Audio使用了一种更先进的模型。 这是一种基于文本元数据以及音频文件持续时间,和开始时间调整的音频潜在扩散模型,允许对生成音频的内容和长度进行控制。这种额外的时间条件使用户能够生成指定长度的音频。 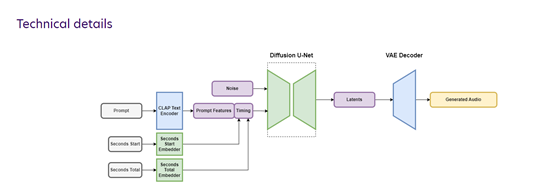 与原始音频相比,使用大幅度下采样的音频潜在表示可以实现更快的推理效率。通过最新稳定音频模型,Stable Audio能在不到一秒的时间内,使用NVIDIA A100 GPU渲染出95秒的立体声音频,采样率为44.1 kHz。 训练数据方面,Stable Audio使用了一个超过80万个音频文件组成的数据集,包含音乐、音效以及各种乐器。 该数据集总计超过1.95万小时的音频,同时与音乐服务商AudioSparx进行合作,所以,生成的音乐可以用于商业化。 潜在扩散模型Stable Audio所使用的潜在扩散模型(Latent Diffusion Models)是一种基于扩散的生成模型,主要在预训练的自动编码器的潜在编码空间中使用。这是一种结合了自动编码器和扩散模型的方法。 自动编码器首先被用来学习输入数据(例如图像或音频)的低维潜在表示。这个潜在表示捕捉了输入数据的重要特征,并且可以被用来重构原始数据。 然后,扩散模型在这个潜在空间中进行训练,逐步改变潜在变量,从而生成新的数据。 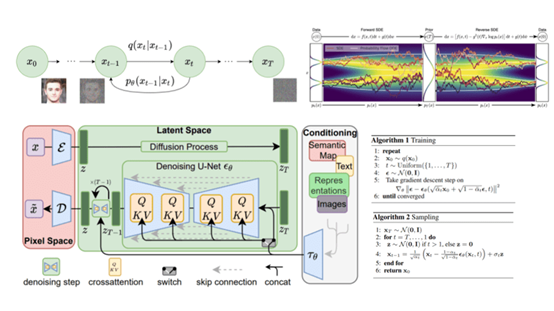 这种方法的主要优点是可以显著提高扩散模型的训练和推理速度。因为扩散过程在一个相对较小的潜在空间中进行,而不是在原始数据空间中进行,因此可以更高效地生成新的数据。 此外,通过在潜在空间中进行操作,这种模型还可以提供对生成数据的更好控制。例如,可以通过操纵潜在变量来改变生成数据的某些特性,或者通过对潜在变量施加约束来引导数据生成过程。 Stable Audio使用和案例展示「AIGC开放社区」体验了一下免费版Stable Audio,使用方法与ChatGPT差不多直接输入文本提示即可。提示内容包括细节、心态、乐器和节拍四大类。 需要注意的是,如果想生成的音乐更细腻、有律动性和节奏,输入的文本也需要更细化。也就是说,你输入的文本提示越多,那么生成的效果就约好。  Stable Audio使用界面 以下是生成音频案例展示。 恍惚、岛屿、海滩、太阳、凌晨4点、渐进、合成器、909、戏剧和弦、合唱、欢快、怀旧、动态。 柔软的拥抱,舒适,低合成,闪烁,风和树叶,环境,和平,放松,水。 流行电子、大混响合成器、控鼓机、大气、穆迪、怀旧、酷、流行乐器、100 BPM。 3/4,3拍,吉他,鼓,明亮,快乐,拍手 本文素材来源Stability AI官网,如有侵权请联系删除 END —- 编译者/作者:AIGC 玩币族申明:玩币族作为开放的资讯翻译/分享平台,所提供的所有资讯仅代表作者个人观点,与玩币族平台立场无关,且不构成任何投资理财建议。文章版权归原作者所有。 |
文本直接生成20多种背景音乐,免费版Stable Audio来了!
2023-09-14 AIGC 来源:区块链网络
相关阅读:
- AI 智能化社交平台“BenBen”完成千万级种子轮融资2023-09-14
- 美国加州参议员提出一项法案以规范生成式 AI 模型2023-09-14
- 亚马逊推出人工智能生成工具,可帮助卖家撰写产品描述2023-09-13
- Adobe 宣布推出 Firefly 商业版本2023-09-13
- 诺奖得主莱维特称 ChatGPT 提高个人智力 50%,可“取代人类”2023-09-13