来源:光锥智能 作者:郝鑫 编辑:刘雨琦、王一粟 AI 的应用一直以来都有两个极端: 一类是在数据中心,用最强的算力跑最复杂的模型;一类是在智能终端,用最小的模型实现最普适的应用。 除了追求大算力带来的智能涌现,如何把 AI 模型压缩,运用到各种智能终端上,也是工业界不断追求的“极限挑战”。 在 AI 的各种世界顶会中,有一类顶会比赛的项目,就是如何将 AI 高性能又高效地使用到终端。 ICCV 2023 是 AI 计算机视觉领域的三大顶会之一,每两年举办一届,代表了人类在计算机视觉领域的最先进技术,堪称“地表最强”。 8月底,走出“技术自嗨”,带着一身“硬本事”,首次参加CV建模推理和训练赛的支付宝xNN团队,分别拿下2项赛事的3个冠亚军。其中“推理挑战赛”上,shanwei_zsw 和 zhaoyu_x 两支小组分别获得冠亚军,比分大幅领先第三名45%以上。在“训练挑战赛”上,shanwei_zsw 则以0.04的些微差值位居亚军。  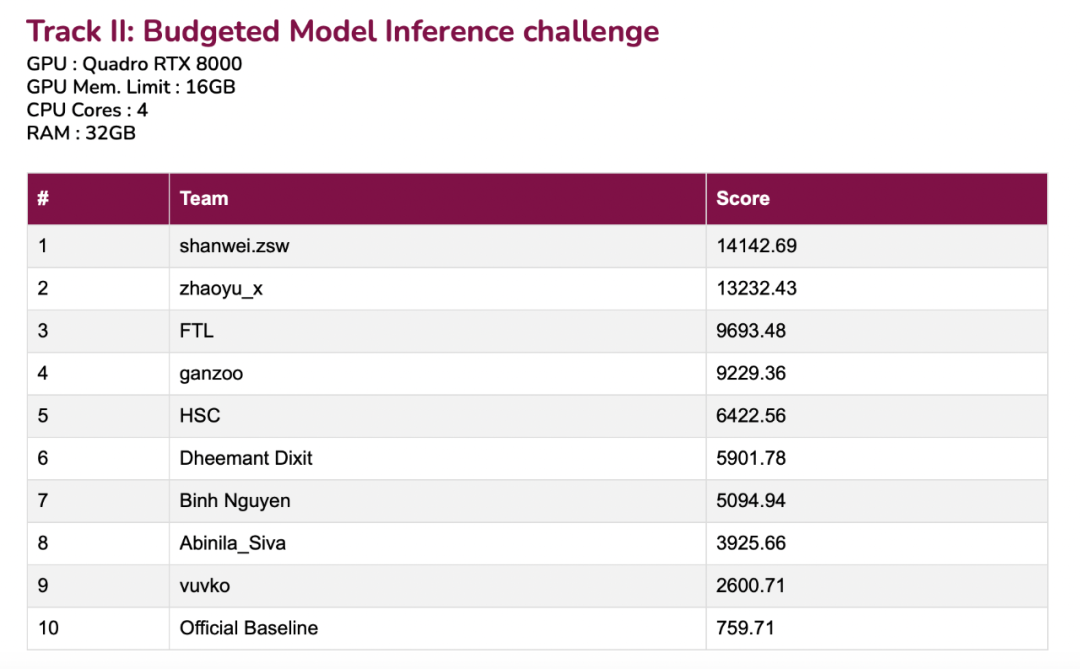 赛事的难点在于,要在有限的计算资源条件下发挥模型的最大效能。例如在运行时,GPU内存限制在6GB以下,训练成本控制在九个小时以内,在这些条件限制下,图像识别精准度还要达到95%以上,在1分钟之内完成几千张图片推理的效果。 “投入时间比较短,参赛也很从容,比赛的课题就是我们日常的工作”,参加挑战的支付宝xNN引擎工程师王世豪道。 通过 xNN 团队在技术实践上的探索,我们也能够一窥当前 AI 在终端落地方面的最新进展:从 1.0 跨越到 2.0,目前端侧 AI 技术已经攀登到一个“小高峰”,“又好又快”成为技术抵达的主逻辑。 历史的齿轮重新开始转动,随着大模型的降临, AI 在智能终端的落地,又迎来一个全新阶段。 端侧部署难题:有限资源VS大参数AI模型或许大家并不了解 xNN 团队,但一定用过他们的技术。 扫码付款、春节扫五福、理财推荐、短视频直播……这些再熟悉不过的场景中都有 xNN 团队的影子。 xNN团队负责人周大江告诉光锥智能,他们主要负责蚂蚁集团内的所有端智能的应用,为蚂蚁集团提供端侧技术引擎支持。 2016年深度学习刚刚爆发,2017年基于计算机视觉的“扫五福”就正式应用在支付宝 APP 里上线,这也成为了xNN 技术团队组建的起点。 “扫福活动最早在云端测试,即在服务端上用 AI 能力识别福字,但最终发现成本和效果都差强人意,这才转向了端上去做”,周大江表示。  “扫五福”这个动作,经过了扫描、识别、判断、计算、推理、反馈一系列 AI 步骤。如果通过云的路径实现,摄像头要先扫描,然后传到服务端,云服务端处理完成后再返回结果。这里面包括了网络通信的开销、云计算传输耗费的时间、判断反馈的时间,总体下来,用户等待时间长且体验感较差。 xNN团队经过摸索后发现,云端根本无法满足用户的实时需求,要想让应用飞入寻常百姓家,还得部署到端侧。 正如王世豪所言,端侧机器学习有很多优势:首先可以降低部署成本,从模型推理到模型决策一切都在端侧搞定,节省云端运维资源;其次,一次加载资源后,不需反复请求服务端传递数据量以及获取 AI 分析结果,非常适合图像识别等高频 AI 分析场景;最后,调用数据无需传输上云,有助于提升用户的隐私性。 技术方向被验证了正确性,但实现过程却充满了复杂。 以扫五福场景为例,汇集了图像识别、语音识别、自然语言处理、传感器数据融合等多种 AI 技术。例如最常涉及的图像识别技术,用于快速、准确地识别用户扫描的福字图像,判断是否正确;传感器融合技术,结合手机运动传感器等辅助无障碍用户进行福字扫描;语音合成、识别技术,支持语音互动的各种创新玩法,如“语音打年兽”等。 端侧部署的难点也十分突出,相比云服务器,端侧设备资源极其有限,无法载入过于复杂的模型。 资源对端侧的限制体现在全过程中,识别靠摄像头,而手机的摄像头质量参差不齐,有的清晰,有的模糊;模型训练、推理所用到的GPU和CPU,决定了数据传输、反馈的处理速度;存储空间有限,决定了模型大小。 但 AI 模型规模又很大,一个简化的模型就好比中学的三元一次联立方程,模型训练推理的过程可以理解为解方程的过程,只不过要解的是几百万元的方程。其中,每个元就是“参数”,联立方程式称之为一层的“神经网络”,一般而言,常用的简单模型可能有3-6层,复杂模型甚至有50+层,这足以证明模型参数有多大。 “于是,有限的资源和大参数的 AI 模型之间形成了鸿沟”,支付宝终端技术部负责人李佳佳进一步明确了xNN团队的方向,把 AI 模型放到端上就是要在“螺蛳壳里做道场”。 可对于一款十亿级用户的国民级APP而言,技术要解决的难题还远不止于此。 支付宝服务对象面向全年龄段的各类人群,10亿用户中,来自三四线城市的比例超过55%。在很长一段时间内,几百元的低端机成为主流,这意味着从技术设计上不能设置过高的门槛,要能适配各种老版的手机硬件和操作系统。 支付宝的应用还经常存在海量并发场景,譬如春节扫福等促销活动,动辄超几亿人参与,据统计,每2-3个中国人里就有一个参与过扫福活动,瞬时涌入的巨大流量也给端侧带来了考验。 基于端侧 AI 技术本身和支付宝国民级应用的属性,两座沉重的大山压在了 xNN 团队肩上。 从 AI 1.0到2.0,找寻端侧模型最优解进一步拆解任务,xNN 团队决定先解决端侧 AI 技术共性问题,再去解决支付宝自身的个性化问题。基于该逻辑,其技术迭代经历了 AI 1.0 模型轻量化阶段和 AI 2.0 可伸缩建模时期。 模型轻量化,顾名思义,主要任务就是把AI模型优化得尽可能小,为此,xNN 团队研发了“模型压缩技术”。 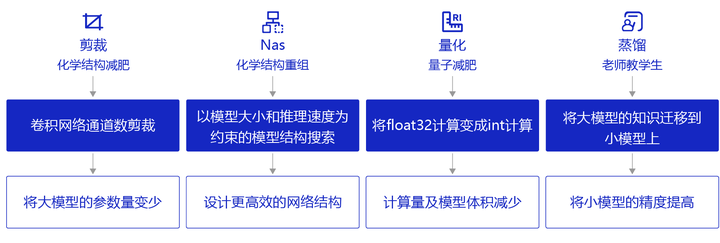 (图:模型压缩的几种基本方法) “模型压缩最核心的就是让模型尽可能得小,只有小了才能装进手机里”,王世豪表示道。 虽然 AI 模型被压缩小了,但并不意味着运行的性能要降低。xNN 团队介绍,能不能让模型在完成同等任务效果的基础上,还能进一步变小,成为了关键。例如,在压缩一个模型后,识别福字的精准度依然很高。 一个问题也随之而来,多小的 AI 模型算小呢? 周大江告诉光锥智能,关于这个问题业界目前还没有形成标准,这意味着每个APP可能都会有自己一个软性的标准。“在实际应用运行中,大一点其实也不是问题,业界一般控制在十兆左右尺寸。但支付宝更倾向于小数量级的模型规模,大部分应用都控制在一兆以内”,周大江称。 把模型压缩变小,主要在解决“好”的问题,使复杂模型可以在端侧设备上运行。而端侧高性能计算引擎技术则专注于解决“快”的问题,通过各种优化手段使模型可以高效计算。 高性能计算引擎技术目的是让模型能够充分利用端侧设备的算力资源,一个核心指标是算力利用率,即模型计算对硬件资源的利用效率。举例来说,假如手机理论上每秒钟可以执行一万次计算,那引擎性能的高低,决定了能不能充分把这一万次给用起来。 得益于“模型压缩+高性能计算引擎”两把“杀手锏”,让 xNN 团队在1.0阶段“实现了绝大多数场景应用的端上部署”,这也为其从1.0的“变小”走向2.0的“灵活”打下了基础。 “以前是一个模型打遍天下,现在是面向不同设备找到最合适的模型”,王世豪道。 可伸缩建模技术,切中了国民级应用的用户人群广泛与多样化的硬件环境的痛点。 一段时间里,不同手机机型都共用一个 AI 模型,这就会出现无法全面覆盖的情况。要么去适配低端机,导致高端机型资源被浪费,业务效果和用户体验打折扣;要么去迎合高端机型,直接丧失一部分低端机用户。 而现在,不只生产一个模型,而是通过技术的手段一次性的生产很多个模型,每一个模型能够去兼容适配不同用户的手机,去最大化它的算力,然后把模型的效果带给用户。这就好比打游戏时的分辨率,既可以选择超高清分辨率,也可以选择低分辨率,深层次诠释了“可伸缩”性的内涵。 模型“又小又快”的实现条件进一步耦合,通过可伸缩建模技术一步到位,快速找到最优解。但同时,里面涉及的工具、参数调节也愈来愈复杂,走过模型轻量化来到 AI 2.0时期,技术比拼才刚刚开始。 随着大模型来临,AI 在智能终端的落地,又将迎来一个全新的技术阶段。 大模型跑在手机上,还有多远?不断优化,把 AI 模型一步步变小,在手机上跑得又好又快。 回溯 xNN 团队技术迭代的历程,这条贯穿其中的主线,也是整个终端智能化的缩影。 然而,到了“更大参数、更加复杂”的大模型应用落地的新阶段,技术既有变,也有不变。 不变的是,xNN 团队对光锥智能表示,即使在大模型的阶段,其核心矛盾仍在于如何利用有限资源,达到又好又快的效果,而大模型只不过进一步加深了矛盾。从具体的评判指标来看,和之前没有本质区别,一旦涉及端上部署,始终逃脱不了模型尺寸、性能、速度等。 最大的变量是几十亿、上百亿参数的大模型。如今端侧的现状是,手机算力、存储等资源并没有跨越式提升,而庞大的大模型已经要迫不及待地成为新时代的主角,这也是导致大模型应用难以打通“最后一公里”的难点所在。  (图:几个预训练模型的参数量统计) “1.0、2.0阶段大部分需要极致优化的任务已经完成,大模型尺寸突然暴涨,成为当前端侧 AI 最大的技术挑战。” xNN 团队认为,从1.0到现在的大模型应用落地阶段,里面存在着技术的延续性。过去技术探索构筑的能力,寻找“又好又快”最优解的经验以及场景运营的积累,皆是走向大模型新阶段的基石。 支付宝终端技术部负责人李佳佳觉得,要站在“巨人肩膀”上,一方面冲着更高的技术标准,继续优化原有的技术;另一方面可能要围绕大模型的特质,做一些新的算法设计和突破。 按图索骥,尽管手握端侧 AI 的钥匙,但要让大模型真正跑在手机端,还需要很长的路要走。 据光锥智能观察,现阶段,手机上使用的大模型应用,基本上算力还是集中在云上,端侧适配仍处于摸索阶段。 目前,华为、小米、Vivo、OPPO等一众手机厂商正在围绕着大模型去做芯片硬件设计和操作系统上的优化,从底层框架到上层应用,尽可能地为大模型跑在手机上提供更多的计算资源支撑。 李佳佳解释称,未来,大模型要以何种姿势降落到手机端还尚在讨论中。 “蚂蚁集团近期对外发布了一系列自研基础大模型,如何将其应用到手机等终端设备上,我们重点攻坚两个关键技术:一方面,进一步强化终端推理引擎的计算效率,充分挖掘手机异构计算资源以提高大模型的执行效率,这对用户体验至关重要;另一方面,通过技术手段推进大模型的压缩,保持大模型效果不降低的前提下,减少运行内存及存储资源的消耗。于此同时,在持续强化引擎计算效能和模型压缩两个关键技术之外,我们同样重视与手机厂商的协作,结合厂商硬件能力迭代与我们自身场景和技术的优势,加速大模型在手机端应用的步伐”。 在技术实现思路、路径走向明了后,究竟何时可以等到大模型真正跑在手机上呢? “未来1-3年内很关键”,支付宝终端技术部负责人李佳佳判断,“关键指标还在模型大小,当前一些大模型仍需消耗几个GB的物理存储/运行内存,基于此,至少应该控制在500MB-1GB以下的水平。” 打通“最后一公里”,同时让14亿人在手机,用上大模型的奇点时刻或许即将到来。 —- 编译者/作者:AI梦工厂 玩币族申明:玩币族作为开放的资讯翻译/分享平台,所提供的所有资讯仅代表作者个人观点,与玩币族平台立场无关,且不构成任何投资理财建议。文章版权归原作者所有。 |
国民级应用,怎么让14亿终端都用上AI?
2023-09-15 AI梦工厂 来源:区块链网络
LOADING...
相关阅读:
- 因赛集团:目前生产经营稳中向好,营销 AIGC 应用大模型研发进度符合2023-09-14
- OpenAI 在都柏林设立办公室,计划与爱尔兰政府合作推进人工智能发展和2023-09-14
- AI 智能化社交平台“BenBen”完成千万级种子轮融资2023-09-14
- 国信证券:随着大模型迭代,2023 年下半年有望出现 AI 爆款应用2023-09-13
- 科大国创:运营商行业大模型目前已在运营商客户中落地应用2023-09-12