 玩币族移动版
玩币族移动版




文本、图像、音频和视频......随意组合,微软的跨模态模型 CoDi 究竟有多强大
时间:2023-07-11 来源:区块链网络 作者:Kyle
 图片来源:由无界 AI 生成 微软?Azure?研究团队与北卡罗莱纳大学研究人员发布了一篇论文《通过可组合扩散实现任意生成》,介绍了一种新的多模态生成模型——CoDi(Composable Diffusion)。 CoDi?能够从输入模态的任意组合生成输出模态的任意组合,例如语言、图像、视频或音频。 与现有的生成式人工智能系统不同,CoDi?可以并行生成多种模态,并且其输入不限于文本或图像等模态子集。?CoDi?可以自由地调节任何输入组合并生成任何模态组,即使它们不存在于训练数据中。 CoDi?通过同时处理和生成文本、图像、音频和视频等多模式内容,引入了前所未有的内容生成水平。 使用扩散模型和可组合技术,CoDi?可以从单个或多个输入生成高质量、多样化的输出,从而改变内容创建、可访问性和个性化学习。 CoDi具有高度可定制性和灵活性,可实现强大的联合模态生成质量,并且优于或与单模态合成的最先进的单模态相媲美。 近日,CoDi?有了新进展,已经正式在微软?Azure?平台可用,目前可以免费使用?12?个月。 CoDi?究竟有多么强大CoDi的出现是微软雄心勃勃的?i-Code?项目的一部分,该项目是一项致力于推进多模态?AI?能力的研究计划。CoDi?能够无缝整合各种来源的信息并生成一致的输出,有望彻底改变人机交互的多个领域。 CoDi可以带来变革的领域之一是辅助技术,使残疾人能够更有效地与计算机交互。 通过跨文本、图像、视频和音频无缝生成内容,CoDi?可以为用户提供更加身临其境且易于访问的计算体验。 此外,CoDi有潜力通过提供全面的交互式学习环境来重塑定制学习工具。 学生可以参与无缝集成各种来源信息的多模式内容,增强他们对主题的理解和参与。 CoDi也将彻底改变内容生成。 该模型能够跨多种模式生成高质量的输出,可以简化内容创建过程并减轻创作者的负担。 无论是生成引人入胜的社交媒体帖子、制作交互式多媒体演示,还是创建引人入胜的讲故事体验,CoDi?的功能都有可能重塑内容生成格局。 为了解决传统单模态AI?模型的局限性,CoDi?为组合特定模态生成模型的繁琐且缓慢的过程提供了解决方案。 这种新颖的模型采用了独特的可组合生成策略,可以桥接扩散过程中的对齐,并促进交织模态的同步生成,例如时间对齐的视频和音频。 CoDi的模型训练流程也颇具特色。 它涉及将图像、视频、音频和语言等输入模式投影到公共语义空间中。 这允许灵活处理多模态输入,并且通过交叉注意模块和环境编码器,它能够同时生成输出模态的任意组合。  (上图)CoDi的模型架构:CoDi?使用多阶段训练方案,能够仅对线性数量的任务进行训练,但对输入和输出模态的所有组合进行推理。 丨单个或多个输入——>多个输出CoDi模型可以采用单个或多个提示(包括视频、图像、文本或音频)来生成多个对齐的输出,例如带有伴音的视频。 例如: 1.文本+图像+音频?——>音频+视频 “滑板上的泰迪熊,4k,高分辨率”+纽约时代广场的图片+一段下雨的音频——>经过?CoDi?生成之后,得到一段“一只泰迪熊在雨中在时代广场玩滑板,伴随着同步的雨声和街道噪音。”  如何生成的? CoDi可以通过可组合扩散联合生成视频、图像、音频和文本的任意组合。?CoDi首先接收音轨生成文本字幕,然后再接收图像进行图像+音频——音频,然后接收图像+音频+文本将它们的信息组合起来生成新的联合图像+字幕。最后,?CoDi还可以接收图像+音频+文本并生成视频+音频。2.?文本+音频+图像——>文本+图像 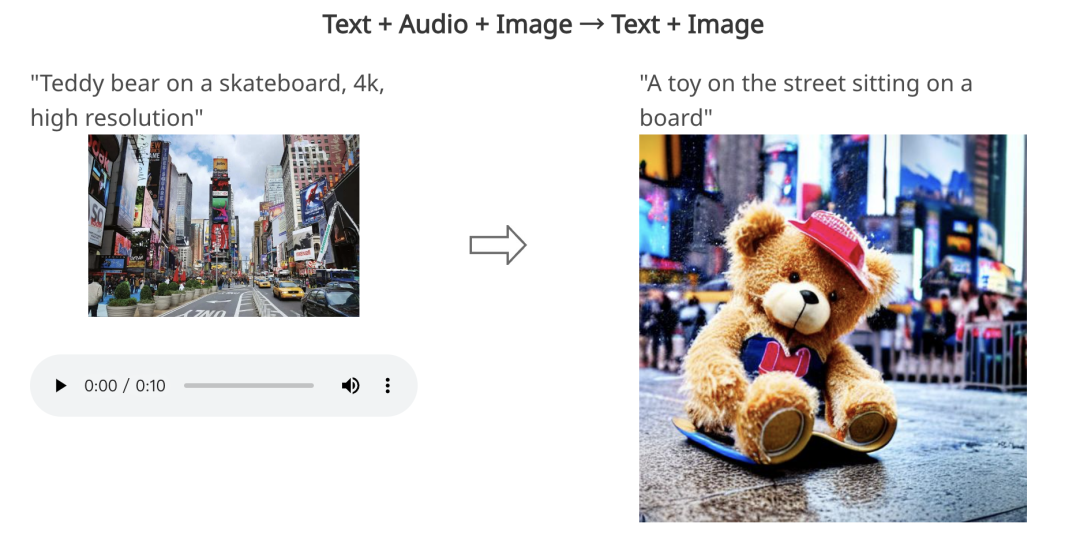 3. 音频+图像——>文本+图像 3. 音频+图像——>文本+图像 4. 文本+图像——>文本+图像 4. 文本+图像——>文本+图像 5. 文本——>视频+音频  6. 文本——>文本+音频+图像  丨多个输入——>单个输出 丨多个输入——>单个输出1. 文本+音频——图像  2.文本+图像——>图像  3.?文本+音频——>视频  4.?文本+图像——>视频  5.还有视频+音频——>文本,图像+音频——>音频,文本+图像——>音频......等 丨单输入——单输出1.?文本——>图像  2.?音频——>图像  3.?图像——>视频  4.?图像——>音频 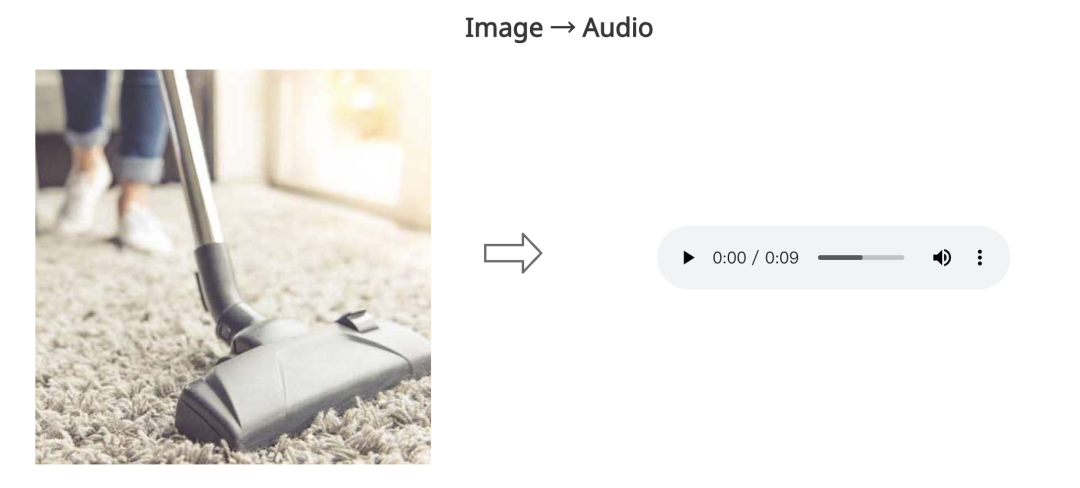 5.?音频——>文本  6.?图像——>文本  参考资料: https://codi-gen.github.io/https://www.youtube.com/watch?v=N2osuAknnXshttps://arxiv.org/pdf/2305.11846.pdf |