玩币族移动版
玩币族移动版




IOSGVentures:深入探讨NewDeFi释放数据的潜力
时间:2023-07-18 来源:区块链网络 作者:IOSG Ventures
原文作者:Momir,IOSG Ventures 智能合约具有局限性,因为它们缺乏与环境交互的能力,这限制了去中心化应用 (dApps) 的发展潜力。为了实现更多更复杂的功能,DeFi 协议有两个选择: 它们可以采用灵活的设计,比如玩家可以个性化处理各种场景;或者它们可以引入 external dependencies——依赖于链下基础设施,如 oracle、keepers 或链下计算——以维持简单的用户体验。 在最近一篇发人深思的题为「为什么 DeFi 被破坏以及如何修复—第 1 部分:无 oracle 协议」的文章中,Dan Elitzer 主张使用零外部依赖的 DeFi 原语(primitives)来最小化攻击向量。这个想法是为了消除对第三方机构的信任需求。然而,一个零依赖的 DeFi 生态系统必将对专业化的要求更高。大多数用户缺乏时间、专业知识或资源,无法成为 Uniswap v3 上的做市商,也无法在没有 external dependencies 的情况下评估协议中的抵押品质量,他们不得不依赖于可信的中介机构参与。 因此,对零依赖的追求可能会让我们回到起点,或者更糟的是,迫使非专业用户信任复杂的实体或将资金存入过渡型智能合约,这会增加不安全因素。与其为完全消除外部依赖关系而奋斗,不如考虑更实用的方法,比如对 external dependencies 进行更严格的审查,并限制潜在的黑天鹅场景。我们必须认识到,某种程度的依赖是不可避免的,甚至对行业的发展至关重要。 在知名的 DeFi 项目中,Uniswap 的早期版本最接近于实现零依赖。然而,最近引入的 Uniswap v4 表明了一种转变趋势,通过高度模块化的方法 (「Hooks」)以推动此领域向前发展。 数据原语 关于外部依赖的讨论主要围绕智能合约与外部数据交互的能力展开。如今,数据交互通常依赖于预言机来访问链下信息,尽管范围有限 ( 主要包括主要加密货币的价格 )。 随着越来越多的活动迁移到区块链,大量有价值的链上数据可以用来以算法和透明的方式增强机制设计。然而,尽管链上数据具有透明度,但将其与智能合约集成并非易事。读取、处理和交付有意义的数据需要建立一个复杂且可信的基础设施。因此,开发人员通常依赖于现有的工具来满足他们的数据需求。然而,大多数现有的数据解决方案都植根于 Web 2.0 框架,甚至更多的 Web 3.0 本地协议也不能保证它们提供的数据的准确性。
Sushiswap 关于 Polygon Sushi-Matic 子图发送不准确数据的讨论 考虑到智能合约甚至可以管理数十亿美元的存款,它们直接连接到一个受信任的 API 源既不可取也不实际,因为这种依赖会破坏区块链生态系统的去中心化性质。 构建防篡改数据解决方案 我们的投资理念围绕着一个基本信念,即防篡改数据将成为下一代 DeFi 协议的基石。然而,实现数据的防篡改不是一项简单的任务,它需要复杂的基础设施和大量的优化,以使其在经济设计上可行。 在这种背景下,Space and Time已经成为建立防篡改的数据基础设施的先锋。一个关键部分是它的 SQL 证明,这是对 SNARK 证明的改进,专门用于从关系数据库查询数据。该方式提供了保证,确保查询及其底层数据不被篡改。此外,在通过 RPC 调用从存档节点检索数据时,它提供了数据有效性的保证。 其他一些有名的无信任数据原语项目包括但不限于Nil Foundation、Axiom、Brevis、Herodotus 等。
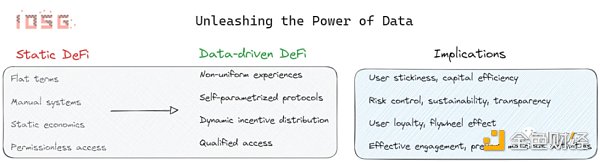
防篡改数据为 DeFi 协议开辟了新的视野,使它们能够突破功能的界限,推动行业进一步增长和创新。 下面我们将在以下情况下讨论数据驱动协议设计优化: 1. 个性化的用户体验 2. 自参数化协议 3. 协议经济 4. 合格访问
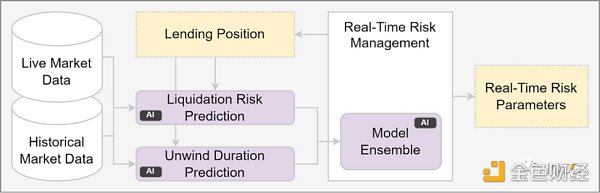
1. 个性化用户体验 在技术业务领域,为用户提供量身定制的服务是司空见惯的。然而,智能合约 ( 本质上是代表某些业务逻辑的代码串 ) 通常会统一用户体验,这通常等同于糟糕的用户体验。比如说某些借贷平台,用户 A 是一个新手,用户 B 是一个长期协议用户,用户 C 是一个交易老手。这种缺乏差异化的做法无法解释用户行为,错失了增强用户粘性、激励积极行为和优化资本利用的机会。 协议在识别用户行为并进行相应调整方面具有既得利益。例如,通过利用信用评级,向表现良好的客户提供更便宜的信贷或更低的抵押率。如此一个项目自然会从具有统一条款的平台吸引用户。此外,这种方法为用户提供了隐性激励,促使他们表现出好的行为,以获得更优惠的条件。 从金融科技领域思考,像 SoFi 这样的公司通过拒绝统一化来获得市场份额,DeFi dApps 也可以学习。例如,SoFi 发现了学生贷款市场的市场效率低下,斯坦福大学的毕业生被收取与其他借款人相同的贷款利率,尽管他们毕业后获得高薪工作的可能性更高。通过调整利率以更好地反映用户的风险状况,SoFi 取得了显著的成功。 同样,在 DeFi 领域,我们设想了一个创新协议的机会,将用户风险纳入利率和抵押因素。然而,必须小心,不要仅仅根据现有历史数据来进行抵押不足的借贷,因为当博弈论改变时,历史数据变得无关紧要。 值得一提的是,Spectral 和 Cred Protocol 等项目正试图从链上数据中建立信用评分模型。然而,这些项目都是在中心化数据库上运行的,因此,只要它们所服务的数据和模型来自中心化数据,并且很容易被篡改,那么主要的 DeFi 协议就不太可能连接到它们的 api。相反,如果这些项目采用防篡改的解决方案,它们就有可能成为无处不在的 DeFi 信用预言机,为一系列创新应用提供动力。 2. 自参数化协议 ( 最小化治理干预 ) 许多 DeFi 协议仍然依赖于人工治理流程,通常由链下咨询公司指导,以调整其参数。比如 AAVE,它向外部咨询公司支付重金以监测和指导协议风险参数。 但是,这种做法产生了几个问题: 1. 缺乏实时支持:系统缺乏对不断变化的市场条件或新出现的风险的响应能力。 2. 手动系统:对人工干预的依赖在调整协议参数时引入了延迟问题和潜在的低效率。 3. 对链下实体的信任:依赖外部咨询公司引起了对透明度和提出建议时使用的方法的担忧。 这种静态方法在对 AAVE 的一次攻击中暴露出来,导致坏账的产生,而这些坏账本可以通过合适的借贷参数来避免,这些参数可以更好地反映借来的代币流动性。此外,在借贷协议中使用流通中代币作为抵押品的风险尚未得到充分解决。 为了解决这些限制,项目应该向实时、自动、透明和无需信任的设计过渡。例如,借贷协议可以利用类似 Space and Time 的基础设施来实时监控数据。这将使他们能够动态地调整抵押品、借贷参数和其他关键参数。 同样,交易所可以引入基于波动率或无常损失的动态收费结构。Uniswap v3 之上的许多流动性池难以实现可持续运营,主要原因是无法对 LP 动态收费。有了 Uniswap v4 的 Hook 或 Valantis 的模块,让动态收费成为可能。 此外,聚合器可以不受人工以及固定费用的干扰,以适应底层协议不断变化的风险和回报。Spool 和 Solity 的合作就是朝这个方向迈出的一步,Solity 使用大数据方法来分析池子的风险回报。 3. 协议经济 数据驱动的方法有可能增强 DeFi 中的协议经济和代币经济模型,其中项目可以与满足条件的用户共享激励。 比如,一个寻求用户粘性和忠诚度的 DEX 聚合器,他们可以将滑点收益分配给满足某些条件的用户,例如执行指定数量的交易并达到最低交易量。 这样的激励大量激励早期用户,在用户群中建立了忠诚度,并直接向现有用户提供激励,以促进协议在他们自己的群体中的使用。 4. 合格访问 虽然区块链有无需许可的性质,但它也允许选择自由。在多个案例中,应用层的许可访问可以确保协议不被用于做恶,或者有效地与目标用户群进行交互。 例如,像 Tornado Cash 这样的隐私协议正受到监管机构的审查,因为它们可能被用于洗钱或其他非法行为。为了防止洗钱,协议开发人员可以采取措施,防止不良行为者与他们的平台进行交互。 另外,对于做市商来说,了解交易对手是非常有价值的,但 dex 通常无法获取此类信息。假设有可能利用数据来构建真人证明,DEXs 可以只允许非 bot 地址交互,那么这类问题也可以得到解决。 可验证计算的需求 通过与无信任数据原语的集成,可以完全实现上述部分讨论的内容。然而,其他的将需要额外的资源来执行统计计算或机器学习。例如,信用评分项目可以利用防篡改数据,但仍然需要机器学习算法来生成信用评分。 或者在 Risk Oracle 的前提下,获取相关特定代币的流通供应、数量、交易计数、持有者数量、自 TGE 以来的时间等的数据对于确定适当的抵押和借贷因素至关重要。但是,机器学习技术需要在这些数据的基础上进行精确的计算。
source:https://chainml.substack.com/p/web3-needs-ai-to-realize-its-potential DeFi 中需要更复杂计算的其他领域包括但不限于: 收益聚合器:估计底层协议的收益和风险,并找到最优分配。 投资组合优化:根据预先确定的标准计算目标投资组合的分配,根据技术指标改变定向敞口等。 衍生品去中心化交易所:系统性风险管理,资金费用调整,衍生品定价等。 高级交易执行算法 流动性金库做市逻辑 清算库 像 ChainML 这样的项目通过提供可验证的链下计算层来满足这一需求,并由专门构建的共识机制提供支持。其他构建分布式机器学习计算层的包括但不限于 GenSyn, Together.xyz, Akash 等。 同样,ZKML 提供了一个有趣的机会,其中 ZK 证明可以将计算压缩为可以在链上验证的简洁证明,或者在不透露其属性的情况下演示特定模型的使用。如 Modulus Labs、Giza 等 ZK 项目。 然而,在 ZK 中实现机器学习目前非常贵,增大了实际实施的挑战性。虽然硬件加速和电路优化可能会在未来提高性能,但人工智能的计算需求预计会以更快的速度增长,这使得 ZKML 仅限于利基计算方法,无法适应最先进的人工智能模型。因此,类似 ChainML 的项目提供的基于共识的 pessimistic approach 或基于欺诈证明的 optimistic approach 等方法可能是将最新的人工智能算法集成到 Web 3.0 中的最佳机会。
总结 防篡改数据、先进的计算能力和数据驱动决策的融合,有可能在 DeFi 生态系统中解锁新的创新、提高效率和用户满意度。虽然本文关注的是可以在链上数据原语的基础上进行的优化,但我们同样看好对通过 zk 证明集成各种链下数据所带来的机会。我们相信,数据将增强链上链下的互操作性,促进去中心化金融与传统金融体系之间的融合。 随着行业的不断发展,协议必须接受新兴技术,与头部项目合作,并优先考虑透明度和去信任化,这不仅可以为 DeFi 建立一个强大和可持续的未来,而且可以为 DeFi 对全球金融格局产生深远影响这一景愿提供可能。 声明:Space and Time、ChainML、Nil Foundation 和 Solity 是 IOSG 的 Portfolio。 查看更多 |