 玩币族移动版
玩币族移动版




进退两难的AI“百模大战”:A股首批玩家业绩“全军覆没”,后勤资金补给加速
时间:2023-07-24 来源:区块链网络 作者:AI之势
来源:财联社 编辑 俞琪 由ChatGPT带起飞的AI大模型无疑是上半年最火热的赛道。在GPT-4发布后,互联网巨头、科技公司等纷纷加入这场大模型混战。仅在国内市场,过去几个月间大模型就已密集“涌现”。华西证券刘泽晶在6月5日研报中指出,腾讯、百度、阿里、华为、科大讯飞、三六零、昆仑万维、澜舟科技等公司的AI大模型在上半年发布,浪潮信息的“源1.0”大模型于21年9月发布,云从科技“行业精灵”大模型处于研发阶段。 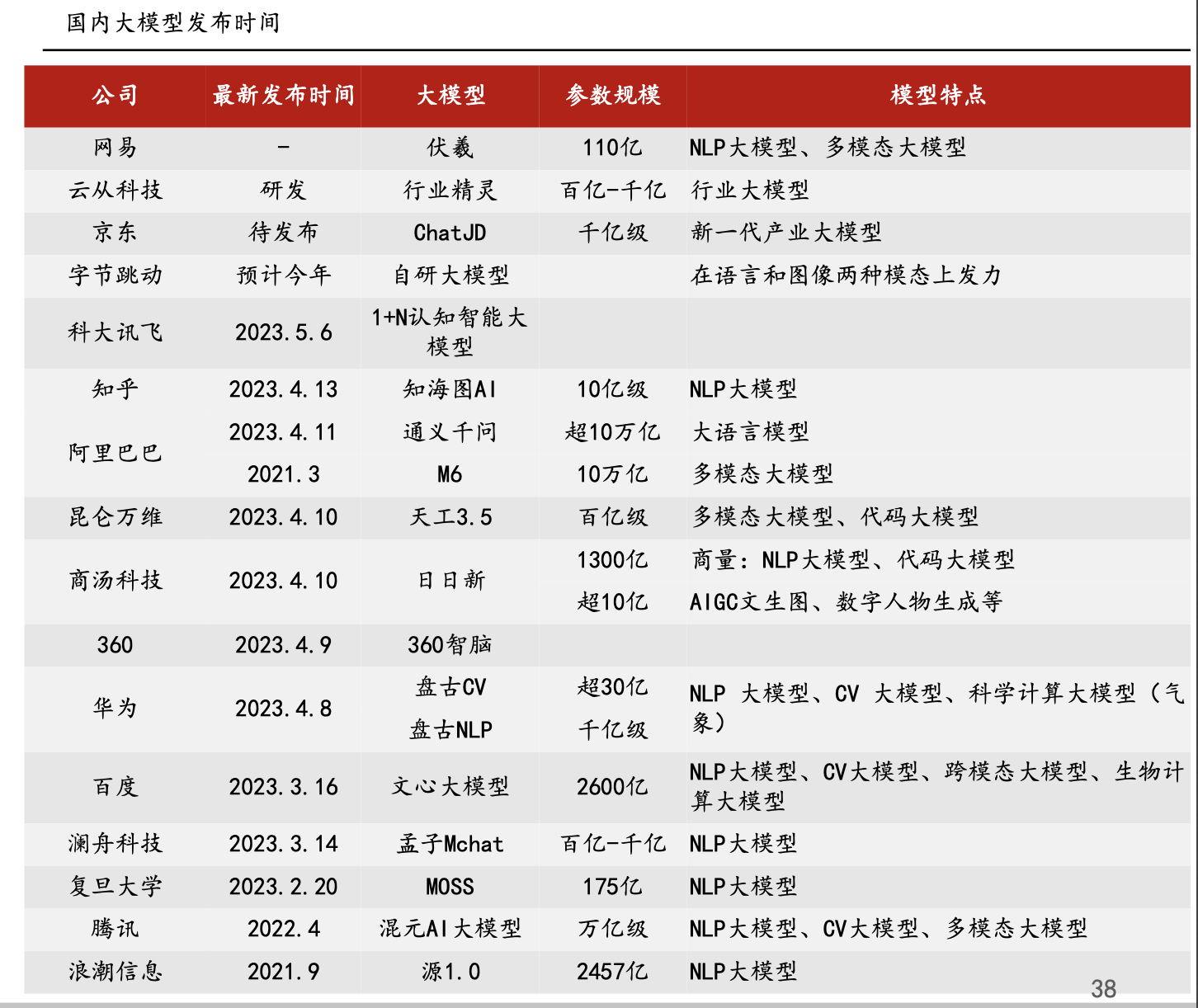 与此同时,这轮由大模型主导的AI浪潮吸引资本市场疯狂涌入。A股大模型进度较快的企业中昆仑万维股价年内累计最大涨幅接近四倍,云从科技和三六零股价累计最大涨幅分别超300%和200%,科大讯飞、浪潮信息股价亦翻倍。 然而,热闹异常的市场背后也有着残酷现实,ChatGPT用户增速放缓、大模型应用不及预期、多家公司陷入业绩和股价颓势等,市场开始不断有声音认为大模型或许已经涨到头了。 ▌A股一众玩家业绩暴雷、股价暴跌 龙头突遇减持利空后又遭北向净卖出上亿元虽然近期各公司围绕AI大模型的消息依旧不断,浪潮信息透露,源2.0将会在文生图、Chat、多模态、工具链等方面进行升级提升;云从科技宣布推出云从行人基础大模型,该模型使用了超过20亿的数据;广联达称,公司构建了建筑行业领域的语言大模型和图像生成大模型。但是,更多的信号似乎预示着整个赛道正在转冷。 从多家A股上市公司业绩公告来看,上半年科大讯飞、浪潮信息、三六零业绩均让市场大跌眼镜。其中,浪潮信息上半年实现归母净利润2.86亿元至3.82亿元,同比下降60%-70%。据计算,Q2净利环比下降22%-64%。科大讯飞上半年净利润预降71%-80%。而相较于前两家业绩明显下滑,三六零则是直接预计上半年净亏损2.3亿元。据计算,Q1和Q2分别预亏1.86亿元和4400万元。 此外,因部分公司未披露半年报预告,若从一季度业绩看,Wind数据显示,一季度,整个AI板块的上市公司中,有近半数公司归母净利润同比下降。云从科技一季度净亏损1.42亿元,昆仑万维净利润同比下滑43%,广联达单季净利润环比下滑64%。能够看出,上半年在AI大模型上动作频频的A股玩家虽然各个都说的很好,但在业绩方面基本上“全军覆没”。 对于业绩颓势,有业内分析认为,AI大模型基本上都是“烧钱”的,持续不断的投入却很难盈利,无论是上游卖服务器“铲子”的浪潮信息,还是中游卖算法和软件的科大讯飞,都已证明了这一点。浪潮信息在公告中称,受上半年全球GPU及相关专用芯片供应紧张等因素的影响。公司日前还公告,董事长王恩东辞职。 不过,不论具体原因何种,有市场分析表示,部分公司业绩不及预期似乎是对AI此前爆炒逻辑的证伪,对AI产业链整体而言雪上加霜。从二级市场的反应来看,截至目前,万得ChatGPT指数年内最大回撤将近20%。此前暴涨的牛股一个个也黯然失色。昆仑万维的年内累计最大跌幅接近50%,三六零、浪潮信息年内最大回撤均在四成左右,科大讯飞年内累计最大跌幅超20%。 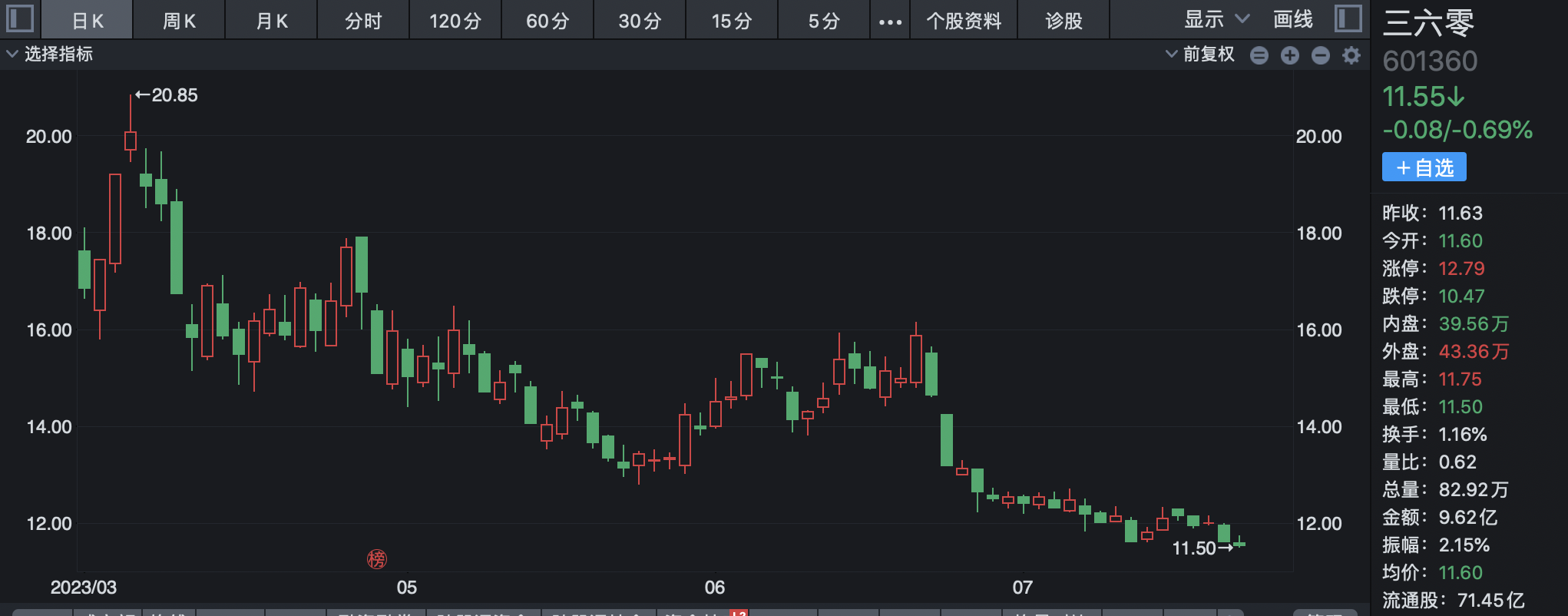 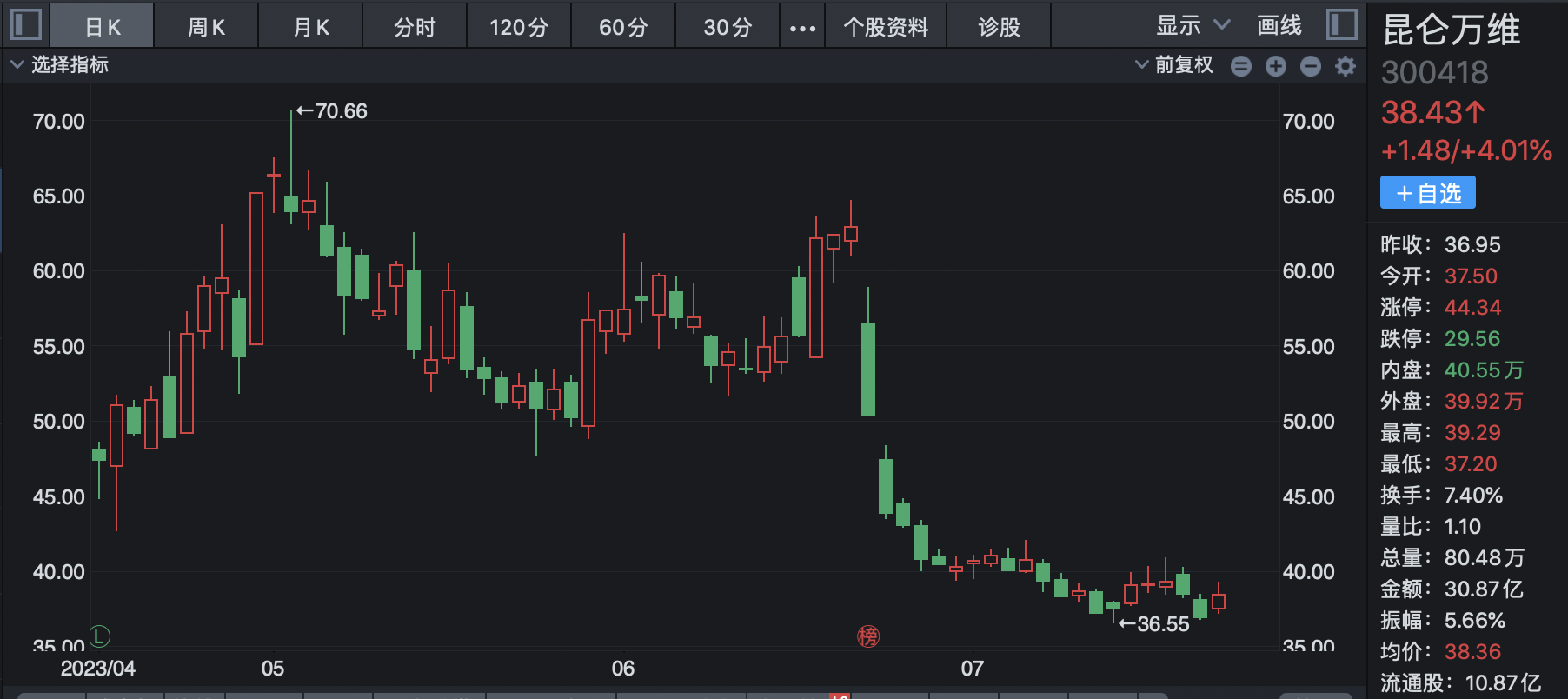 进一步来看,股价大幅震荡的背后,各路资金均在撤退。一方面,北向资金持续减持,根据公开数据显示,昆仑万维最近5日净卖出近3亿元,科大讯飞最近两个月遭净卖出16.24亿元,广联达连续净卖78天,两个月内净卖出额超12亿元。另一方面,wind数据显示,今年24家“AIGC概念股”已经合计遭67笔减持。三六零、昆仑万维、云从科技等公司相继发布减持公告,这其中的周鸿祎90亿分手费及昆仑万维实控人前妻减持“补贴”还让公司陷入高位减持套现舆论漩涡。 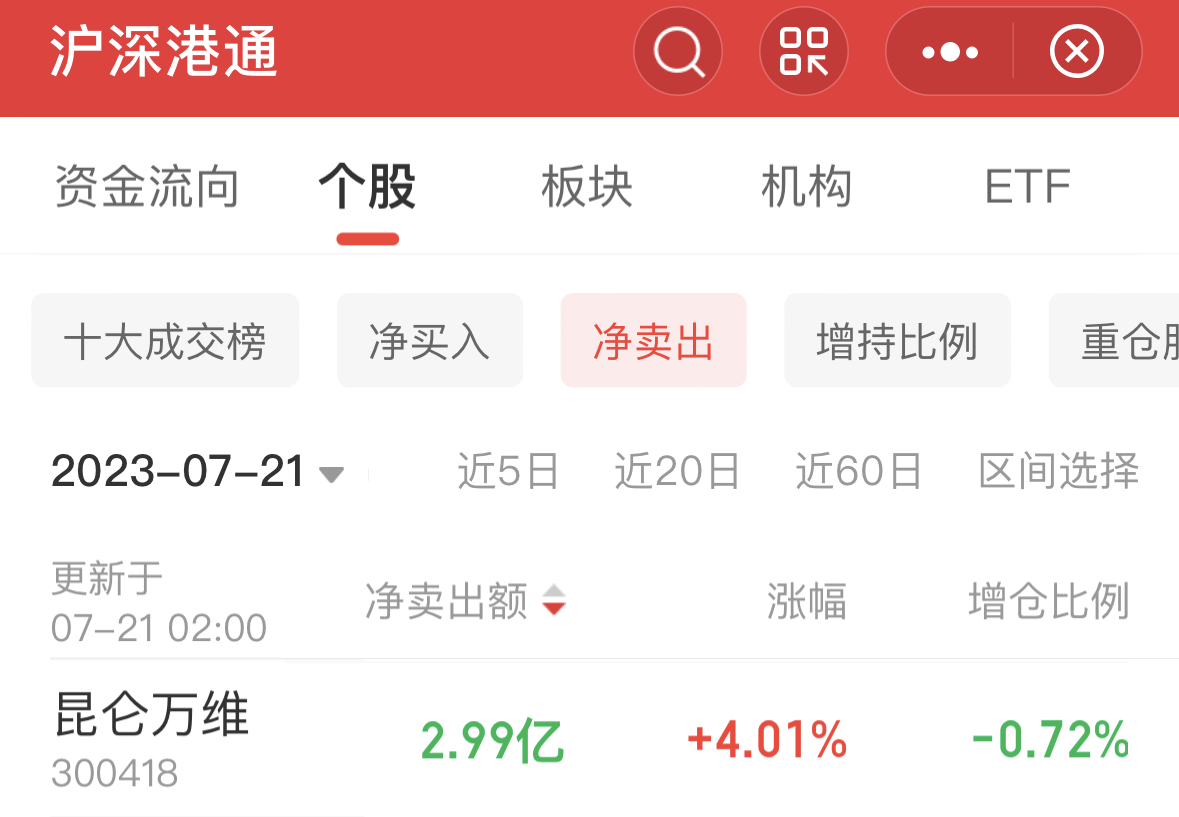 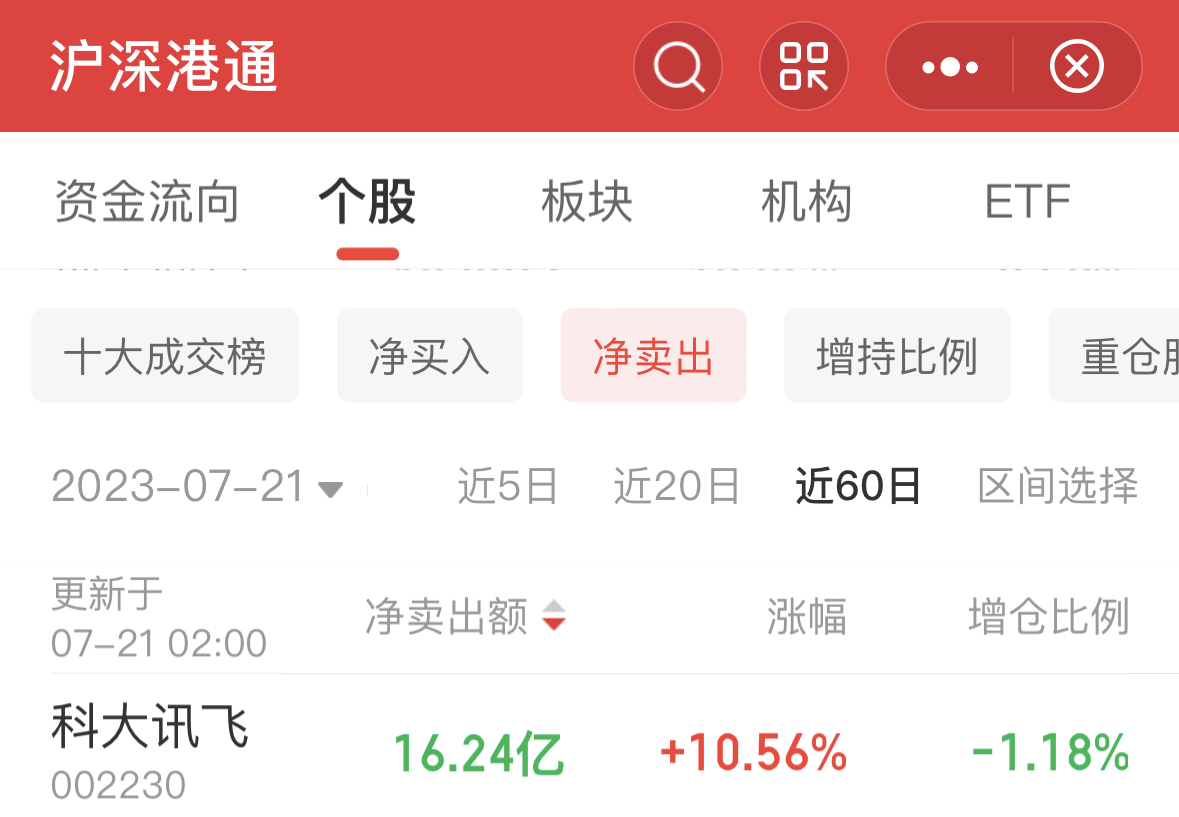 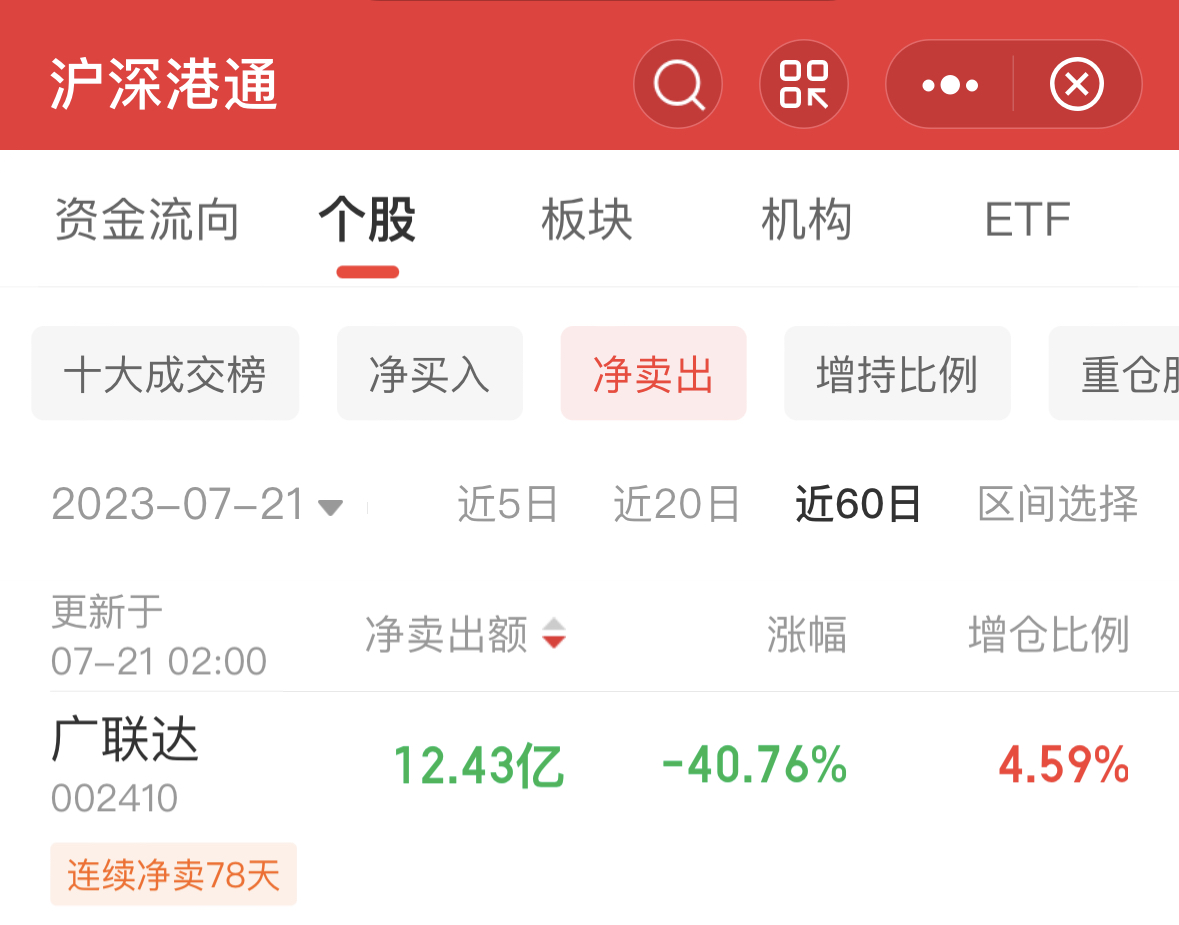 显然,AI大模型赛道在此前一阵爆火后正在逐渐冷。有市场人士认为,目前A股市场ChatGPT概念板块已经存在估值泡沫化迹象,整个板块市盈率已接近140倍。有不少AI概念股在相关技术上并没有太多突破,甚至业绩处于亏损状态,股价却先突飞猛进,这是不合常理的。亦有行业专家直言,目前国内大模型团队基本是参考开源大模型,底层技术仍难以突破,市场出现泡沫是大概率事件。 ▌大战下半场:仅有2%能胜出 通用大模型or行业大模型的生死抉择根据第三方网站SimilarWeb监测数据显示,今年6月,ChatGPT网站与移动客户端的全球流量(PV)环比下降9.7%,美国地区的流量环比下降10.3%。有资本市场人士认为,这轮“百模大战”,国内AI大模型最终胜出的不超过2%,这意味着,剩下98%的国内大模型都会消失在竞争中。 目前来看,业内普遍认为AI大模型的难点或是需要克服的焦点即是商业化问题。据媒体报道指出,现在问世的更多是通用大模型,包括百度、华为、阿里、昆仑万维、科大讯飞、云从科技、联汇科技旗下大模型,这类大模型具备强大的自然语言理解、语言生成和语音识别等能力,在聊天、娱乐等通识属性场景表现较好,但这些场景却存在难以实现大规模商业化的难题。 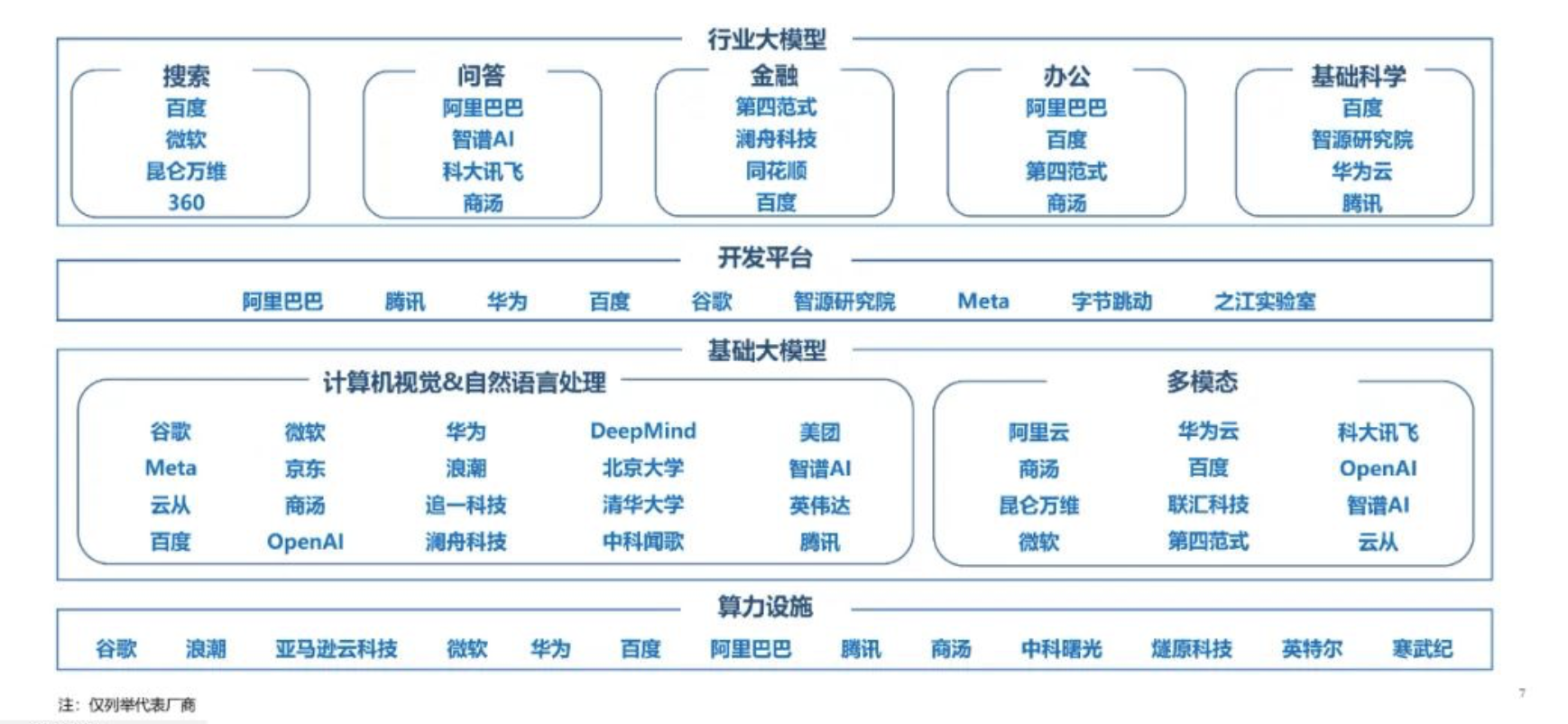 (资料来源:硅谷智库《2023年人工智能大模型体验报告》) 有行业分析进一步介绍,一个千亿级参数的基础大模型需要单机群万卡以上的算力,不仅需要GPU,还要利用起来GPU的集群资源,大部分公司都无法做到。因此,即便是第一梯队大厂,技术落地的前路也依旧漫长。 如此困境下,产业大模型(垂直大模型)成为另一种选择。据悉,其因直接面向垂直领域,所以相对容易落点,除了上述科技大厂外,同花顺、孩子王、江苏银行、中国电信、我爱我家等各个行业的企业也在尝试。 不过,36氪公众号文章指出,垂直大模型在建设难度上实际远高于通用大模型。在产业大模型的训练中,最难获取的是产业数据,这类数据直接影响着产业大模型的技术迭代速度、模型精准度等,然而出于数据安全等考虑,很少有企业愿意将私有数据公开。但这些产业数据往往直接或间接影响着产业大模型的技术迭代速度、模型精准度和业务专业度。 此外,整体来看,有行业分析人士还指出了另一重隐忧,未来底层大模型大量开源有较大可能,或1-2个头部厂商赢者通吃。如此一来,国内大模型的价值与投入将不成正比,一些AI创业者,尤其是应用层公司,将会被陷入左右互搏的困局,即不做直接错过,做了但可能被替代。 |