 玩币族移动版
玩币族移动版




导演消失了!Midjourney+妙鸭相机+Gen2新玩法:10块钱创造马斯克宇宙,一键图生视
时间:2023-07-24 来源:区块链网络 作者:AIGC
来源:新智元 导读:Gen-2又双叒更新了。这次,不用一句话,只要一张图,秒生大片。与Midjourney、妙鸭相机联动后,效果简直炸裂。 生成式AI的大爆发,带来了无限可能。 近来,在国内,秒鸭相机火遍全网,服务器几度被挤爆,堪比羊了个羊。 只需上传一张照片,分分钟得到一套AI写真,让许多人惊呼海马体们要失业了。 与此同时,在国外,初创公司Runway刚刚宣布,不用文本,一张图,Gen-2就能生成视频。  最最最重要的是,网页版免费用,iOS即将上线。  这意味着,一部大片,只需要图片就够了,岂不是人人都能成为好莱坞导演。 这不,已经有网友用Gen-2,结合PS修图,MusicGen、AudioLDM等工具配音,做出了「机器人总动员」翻版影片。 几张场景人物图片,一段电影内容就出来了!真是有手就行!  还有,穿越山海的龙之恋,爱了! 有人把Midjourney和Gen-2混搭,视频画面高级质感简直让人惊掉下巴。  网友表示,这简直就是神圣的地狱之王,Midjourney 5.2+Gen-2太炸裂。这是一个很深很深的兔子洞,我会迷失一段时间。  接下来,继续看一波体验吧。 好玩到停不下来!一句话总结下Gen-2,好玩到停不下来!  有人用时4小时,制作了一部「火焰之旅」预告片,没有任何提示,只是图像!  有了Gen-2,重拍一部「狮子王」,绝对是不可想象的!   Anomaly Z(第一季)预告片。  我完全被Gen2震撼了,动作是如此自然。    文本提示生成,和图片提示生成的对比。  有网友找到了,让Gen-2输出更长时间视频的方法。 方法是用Midjourney生成的图像作为初始图像,然后使用Gen-2输出的最后一帧作为下一张的图像提示。   路人视角,从街市,走到建筑楼中。  再看个手的细节,虽有些不完美,但已经很厉害了。  机械姬效果来一波。   晶莹剔透的深海水泡。  Q版的钢铁侠,还是大叔气质的。  Stability AI家的SDXL生成图片后,再用Gen-2生成视频。  AI的多元宇宙来了。   一些小bug。有人也喜欢Gen2奇怪的客串,和消失的肢体吗?   呆萌的大熊猫。  手把手教程 手把手教程这么炫酷的效果,估计大家已经忍不住想上手试试了,小编就来给大家来亲手实测一波。  首先通过网页https://research.runwayml.com/gen2注册登录runway的账号,进入runway的编辑界面. 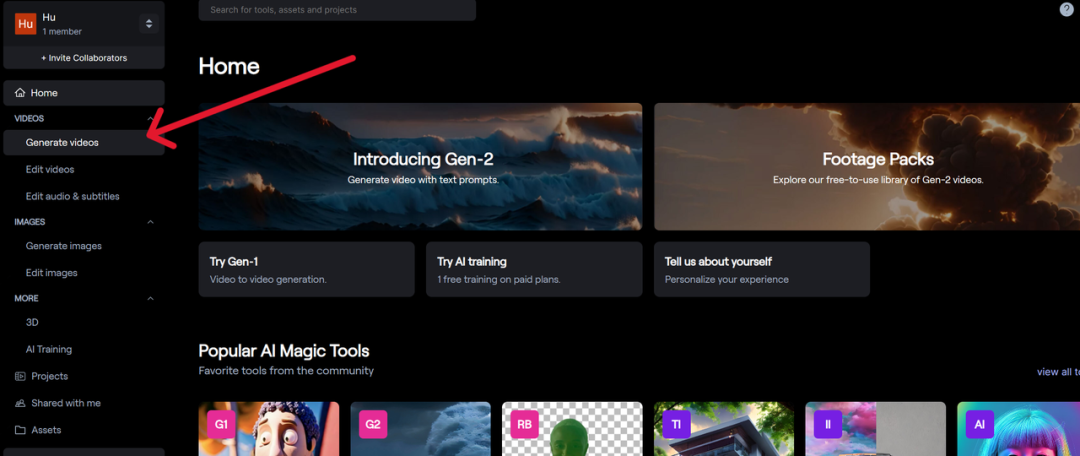 点击左侧的Generate Video。 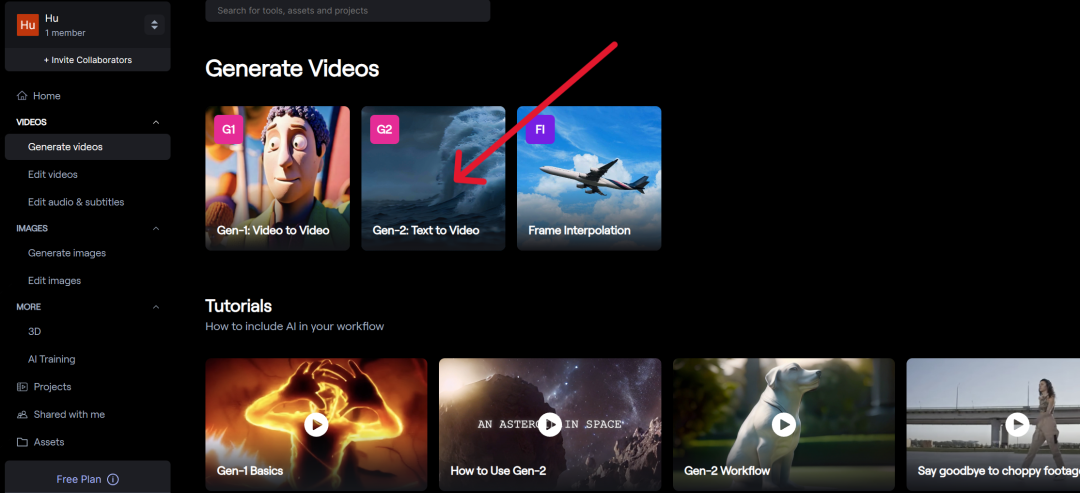 然后点击屏幕中间的Gen-2:Text to Video进入Gen-2。  在左边的区域上传一张照片,小编这里用的是一张由Midjourney生成的机器人的照片。  提示词:Futuristic machine who is a kind robot who wants to save his planet from his human friends, cinematic, digital illustration, stylized, deep depth of field, high definition, --ar 16:9 --v 5.2 然后什么Prompt都不用输入,上传完照片之后就直接点击Generate。大概1分钟之后,一段4秒钟的视频就生成了。  图中的机器人瞬间就动了起来! 小编用最近比较火的妙鸭相机生成了一张地球网红马老板的「美颜证件照」,再用Gen-2的图生视频模式给他来一段视频。  再来看看女装马老板的动态效果  而且小编在使用过程中发现,如果图片本身就有动态效果的元素,那么生成的视频的动态效果会更明显。  ?  而如果原图本来就是一张静物,或者没有太明显的动态效果提示,那生成的视频就几乎不会动,比如下图的猫猫就只会原地不动地坐着。  照片中也只有云朵会有动态效果,其他场景也是原地不动的。  因为现在根据照片生视频的功能本身不能和提示词结合起来,所以动画的动态效果只能根据照片里包含的内容来生成。 开发人员这样的设定应该是要保证生成的动态效果符合图片内容的物理设定,避免生成各种匪夷所思的动态效果。 但是这就对生成视频的原图提出了一些要求,如果是明显的静物图片或者场景,那就几乎不会有明显的动态效果。  梵高、冰雕风格一键切换 梵高、冰雕风格一键切换有了Gen-2生成视频效果,你还可以实现效果转换。 给大家推荐一个最新的TokenFlow模型,能够将视频的风格转换成梵高、海洋奇缘、雕塑等风格。  目前,最先进的视频模型在视觉质量和用户对生成内容的控制方面,仍然落后于图像模型。 这不,研究人员想了个辙,把文生图模型推广到文本编辑视频上,搞了个新框架TokenFlow。 具体来说,在给定源视频和目标文本提示的情况下,研究人员的方法能生成与目标文本一致的高质量视频,同时保留输入视频的空间布局和动态效果。 主要方法是通过强制扩散特征空间的一致性,获得编辑视频的一致性。 根据模型中随时可用的帧间对应关系明确传播扩散特征,从而实现这一目标。因此新框架不需要任何训练或微调,可以直接与任何现成的文本到图像编辑方法相结合来使用,可谓事半功倍。  同时,团队还观察到,视频的时间一致性水平与其特征表示的时间一致性密切相关,这一点可以从下面的特征可视化图中看出。 自然视频的特征具有共享的时间一致性的特点,而当按帧编辑视频时,这种一致性就会被打破。新方法则能保证编辑后的视频与原始视频特征相同的特征一致性。  在编辑过程中,通过强化跨帧内部扩散特征的一致性,可以实现时间上一致的编辑。 为此,研究人员利用原始视频特征之间的对应关系,跨帧传播一小部分已编辑的特征。 即:给定输入视频I,研究人员通过反转每一帧,提取标记的方式,使用最近邻(NN)搜索提取帧间特征对应关系。 在每个去噪步骤中,研究人员会从噪声视频J_t中采样出关键帧,并使用扩展注意模块对其进行联合编辑。编辑后的标记集为T_base。 之后,再根据预先计算的原始视频特征的对应关系,在整个视频中扩散经过编辑的标记。 为了对J_t进行去噪处理,研究人员会将每一帧输入网络,并利用第二步获得的标记来替换生成的标记。 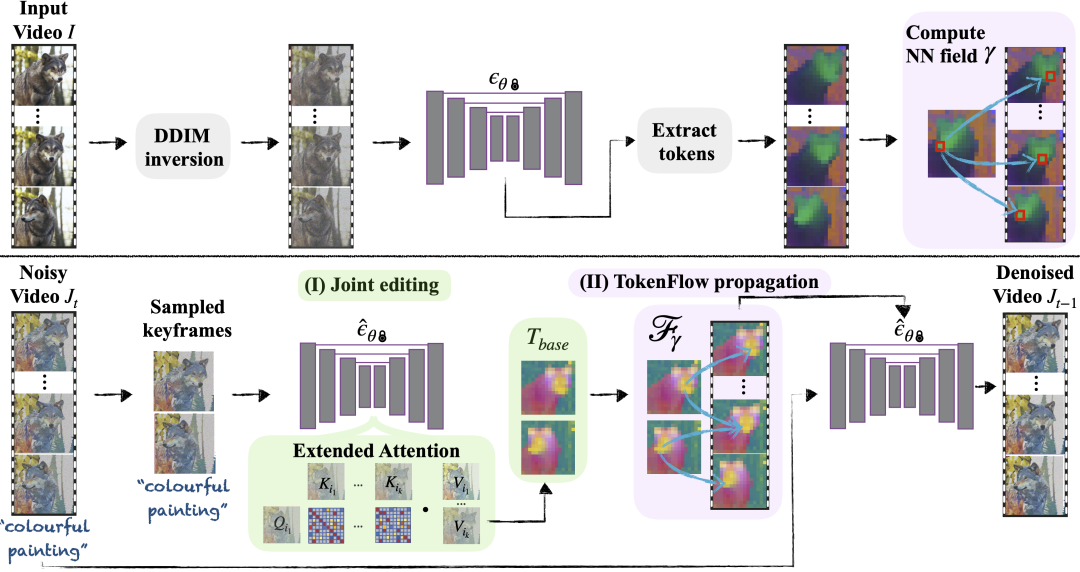 下图是其它的一些定性比较。 RGB传播只能获取光流等低层次的线索,因此在内容展示或动态复杂的视频中会产生视觉假象。 而Text2LIVE则基于CLIP,没有利用扩散模型的生成先验,因此在视觉质量方面受到更多限制。  当然,这套框架也有一些局限性。 研究人员的方法是根据原始视频的特征对应关系来编辑视频,因此无法处理需要有结构偏差的编辑。  妙鸭相机 妙鸭相机昨天在网上有一款AI生成照片的应用火了——妙鸭相机。 首先在微信中搜索小程序「妙鸭相机」,它是一款用个人照片快速生成数(mei)字(yan)分(zhao)数(pian)的应用。  进去以后按照它的要求先传一张个人照片,检测合格之后,突然要求上传20张个人照片!  作为铁直男,小编从有手机以来应该就没有存过20张自己的自拍照,于是呢,出任实测模特的重任自然落到了网红马老板身上。  在花了10块钱,等了一个多小时以后,马老板的「妙鸭相机数字分身」上线!  可以用这个数字分身结合开发者提供的几个模板生成各种不同背景和风格的照片,比如: 少年萌版马斯克:  民族服饰女装马老板  冯唐版马斯克  找工作的时的马斯克  家人们,还在等什么,赶快上手试试吧。 参考资料: https://diffusion-tokenflow.github.io/ https://twitter.com/runwayml/status/1682425654472593409 |