 玩币族移动版
玩币族移动版




老黄深夜炸场,AIGC进入iPhone时刻,Hugging Face接入最强超算,神秘显卡胜过A100
时间:2023-08-09 来源:区块链网络 作者:AI之势
来源:“新智元”(ID:AI_era),作者:新智元 昨天深夜,重返SIGGRAPH舞台的老黄,再次给全世界带来了「亿点点」震撼。 生成式AI的时代已经来临,属于它的iPhone时刻到了! 就在8月8日,英伟达CEO黄仁勋,再次登上了世界顶级计算机图形学会议SIGGRAPH的舞台。  一系列重磅更新接踵而至——下一代GH200超级芯片平台、AI Workbench、OpenUSD…… 而英伟达也借此将过去数十年的所有创新,比如人工智能、虚拟世界、加速、模拟、协作等等,一举融合到一起。 在这个LLM大爆炸的时代,老黄依然敢大胆放话:「买得越多,省得越多!」 英伟达最强AI超算再升级在5年前的SIGGRAPH上,英伟达通过将人工智能和实时光线追踪技术引入GPU,重新定义了计算机图形学。 老黄表示:「当我们通过AI重新定义计算机图形学时,我们也在为AI重新定义GPU。」 随之而来的,便是日益强大的计算系统。比如,集成了8个GPU并拥有1万亿个晶体管的NVIDIA HGX H100。  就在今天,老黄再次让AI计算上了一个台阶—— 除了为NVIDIA GH200 Grace Hopper配备更加先进的HBM3e内存外,下一代GH200超级芯片平台还将具有连接多个GPU的能力,从而实现卓越的性能和易于扩展的服务器设计。 而这个拥有多种配置的全新平台,将能够处理世界上最复杂的生成式工作负载,包括大语言模型、推荐系统和向量数据库等等。 比如,双核心方案就包括一台配备了144个Arm Neoverse核心并搭载了282GB HBM3e内存的服务器,可以提供8 petaflops的AI算力。 其中,全新的HBM3e内存要比当前的HBM3快了50%。而10TB/sec的组合带宽,也使得新平台可以运行比上一版本大3.5倍的模型,同时通过3倍更快的内存带宽提高性能。 据悉,该产品预计将在2024年第二季度推出。  RTX工作站:绝佳刀法,4款显卡齐上新 这次老黄的桌面AI工作站GPU系列也全面上新,一口气推出了4款新品:RTX 6000、RTX 5000、RTX 4500和RTX 4000。 如果H100以及配套的产品线展示的是英伟达GPU性能的天际线的话,针对桌面和数据中心推出的这几款产品,则是老黄对成本敏感客户秀出的绝佳「刀法」。  在发布这新GPU的时候,现场还出现了一个意外的小花絮。 老黄从后台拿出第一块GPU的时候,似乎不小心在镜面面板上沾了指纹。 老黄发现后觉得可能是自己搞砸了,就很不好意思地和现场观众说对不起,表示这次产品发布可能是有史以来最差的一次。 看来就算开发布会熟练如老黄,也会有翻车的时刻。 而如此可爱的老黄,也惹得在场观众不断发笑。  言归正传,作为旗舰级专业卡,RTX 6000的性能参数毫无疑问是4款新品中最强的。 凭借着48GB的显存,18176个CUDA核心,568个Tensor核心,142个RT核心,和高达960GB/s的带宽,它可谓是一骑绝尘。 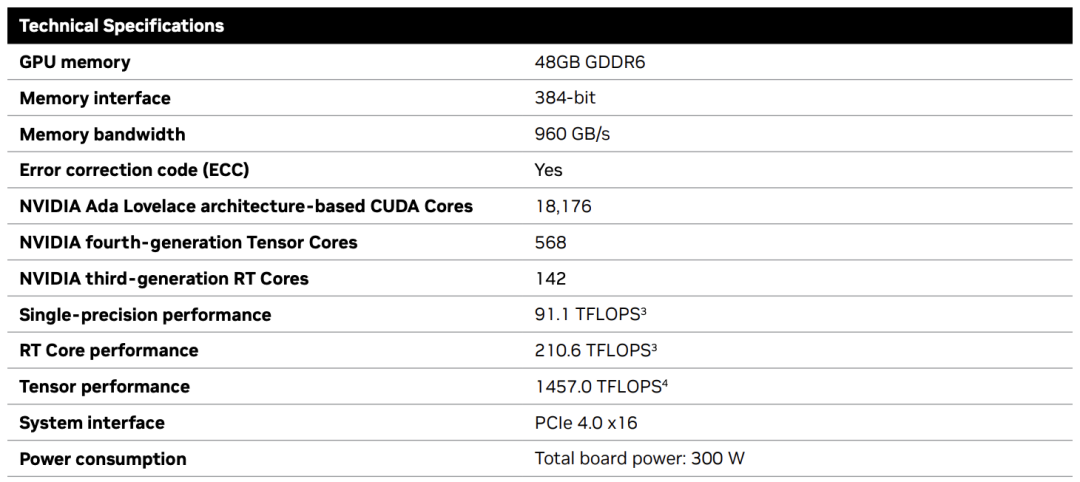 RTX 5000配备了32GB显存,12800个CUDA核心,400个Tensor核心,100个RT核心。  RTX 4500配备了24GB显存,7680个CUDA核心,240个Tensor核心,60个RT核心。  RTX 4000配备了20GB显存,6144个CUDA核心,192个Tensor核心,48个RT核心。  基于新发布的4张新的GPU,针对企业客户,老黄还准备一套一站式解决方案—— RTX Workstation。  支持最多4张RTX 6000 GPU,可以在15小时内完成8.6亿token的GPT3-40B的微调。 还能让Stable Diffusion XL每分钟生成40张图片,比4090快5倍。 OVX服务器:搭载L40S,性能小胜A100而专为搭建数据中心而设计的NVIDIA L40S GPU,性能就更加爆炸了。  基于Ada Lovelace架构的L40S,配备有48GB的GDDR6显存和846GB/s的带宽。 在第四代Tensor核心和FP8 Transformer引擎的加持下,可以提供超过1.45 petaflops的张量处理能力。 对于算力要求较高的任务,L40S的18,176个CUDA核心可以提供近5倍于A100的单精度浮点(FP32)性能,从而加速复杂计算和数据密集型分析。 此外,为了支持如实时渲染、产品设计和3D内容创建等专业视觉处理工作,英伟达还为L40S 还配备了142个第三代RT核心,可以提供212 teraflops的光线追踪性能。 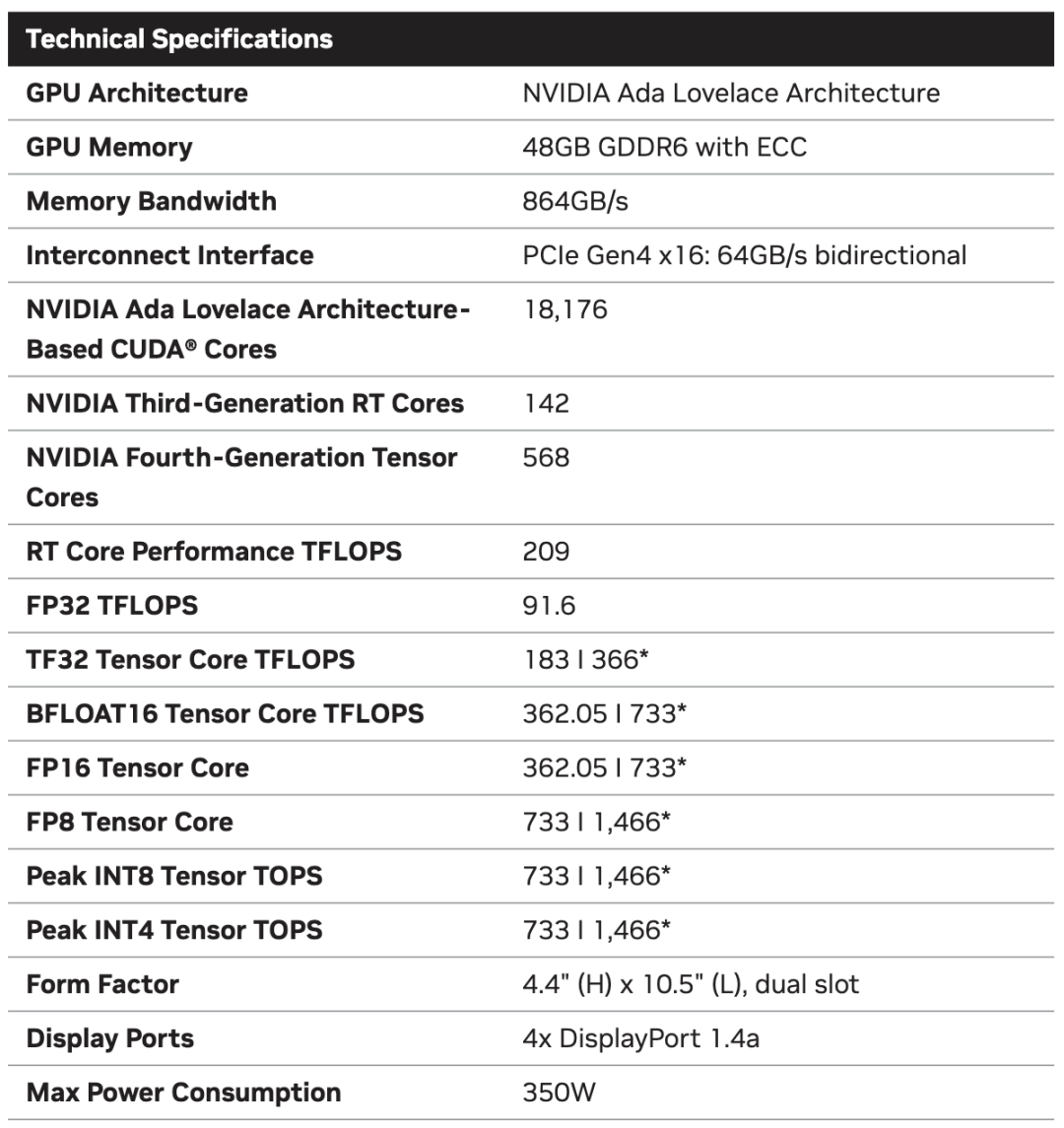 对于具有数十亿参数和多种模态的生成式AI工作负载,L40S相较于老前辈A100可实现高达1.2倍的推理性能提升,以及高达1.7倍的训练性能提升。 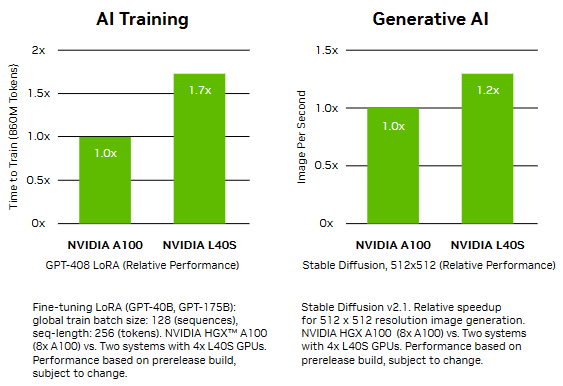 在L40S GPU的加持下,老黄又针对数据中心市场,推出了最多可搭载8张L40S的OVX服务器。  对于拥有8.6亿token的GPT3-40B模型,OVX服务器只需7个小时就能完成微调。 对于Stable Diffusion XL模型,则可实现每分钟80张的图像生成。  AI Workbench:加速定制生成式AI应用 AI Workbench:加速定制生成式AI应用除了各种强大的硬件之外,老黄还重磅发布了全新的NVIDIA AI Workbench,来帮助开发和部署生成式AI模型。 概括来说,AI Workbench为开发者提供了一个统一且易于使用的工具包,能够快速在PC或工作站上创建、测试和微调模型,并无缝扩展到几乎任何数据中心、公有云或NVIDIA DGX Cloud上。 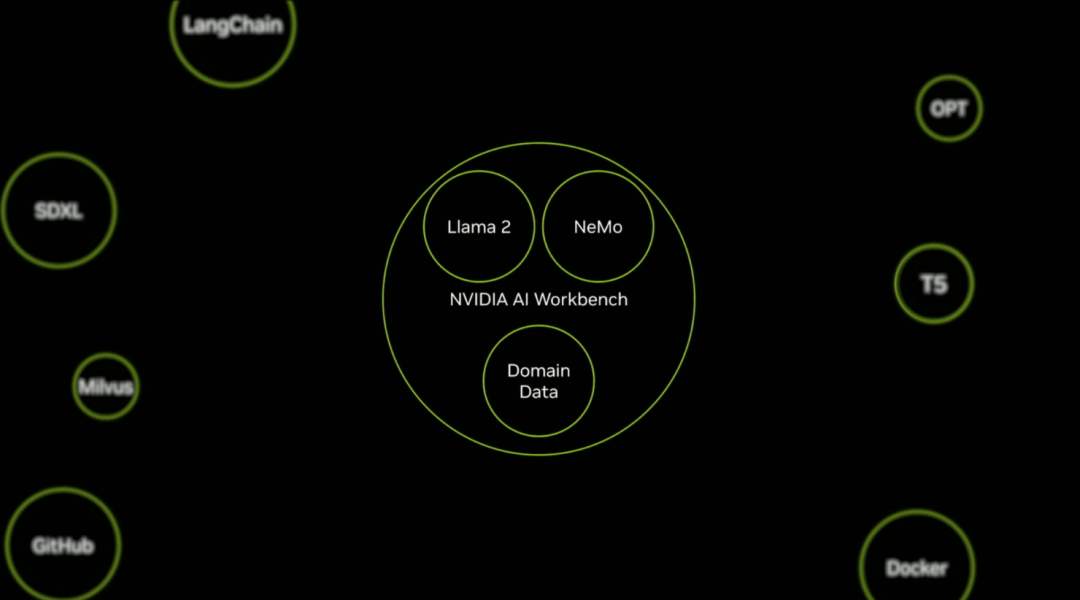 具体而言,AI Workbench的优势如下: -易于使用 AI Workbench通过提供一个单一的平台来管理数据、模型和计算资源,简化了开发过程,支持跨机器和环境的协作。 - 集成AI开发工具和存储库 AI Workbench与GitHub、NVIDIA NGC、Hugging Face等服务集成,开发者可以使用JupyterLab和VS Code等工具,并在不同平台和基础设施上进行开发。 - 增强协作 AI Workbench采用的是以项目为中心的架构,便于开发者进行自动化版本控制、容器管理和处理机密信息等复杂任务,同时也可以支持团队之间的协作。 - 访问加速计算资源 AI Workbench部署采用客户端-服务器模式。团队可以现在在本地计算资源上进行开发,然后在训练任务变得更大时切换到数据中心或云资源上。 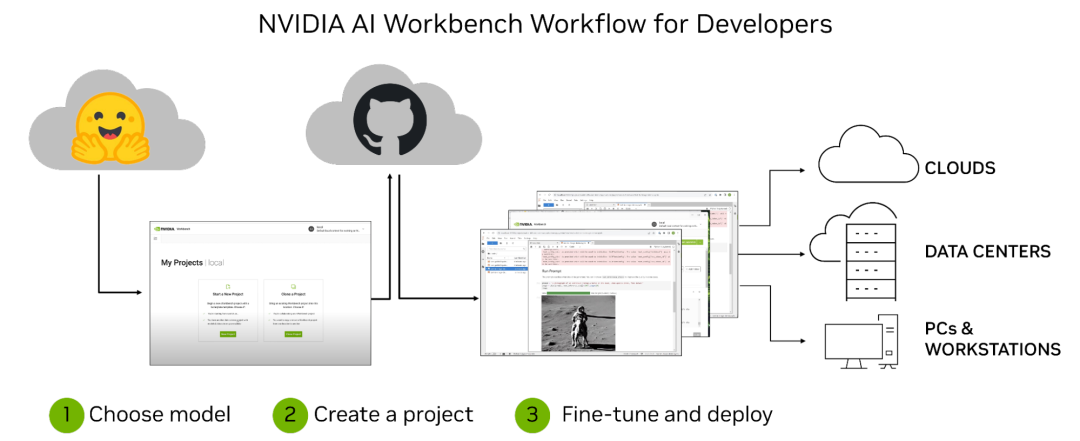 Stable Diffusion XL自定义图像生成 Stable Diffusion XL自定义图像生成首先,打开AI Workbench并克隆一个存储库。 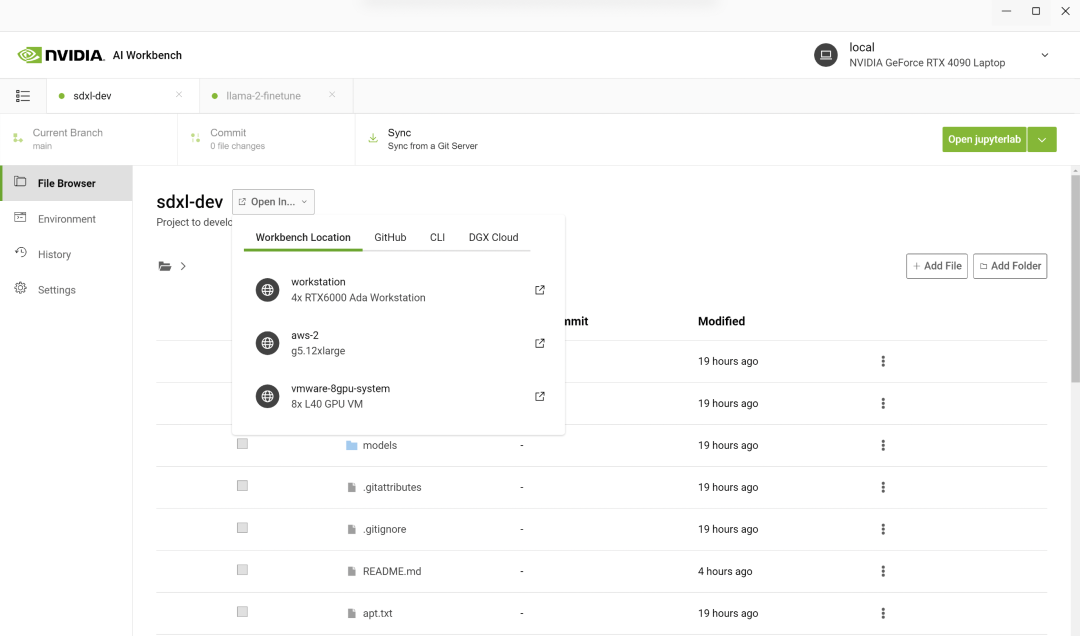 接下来,在Jupyter Notebook中,从Hugging Face加载预训练的Stable Diffusion XL模型,并要求它生成一个「太空中的Toy Jensen」。 然而,根据输出的图像可以看出,模型并不知道Toy Jensen是谁。 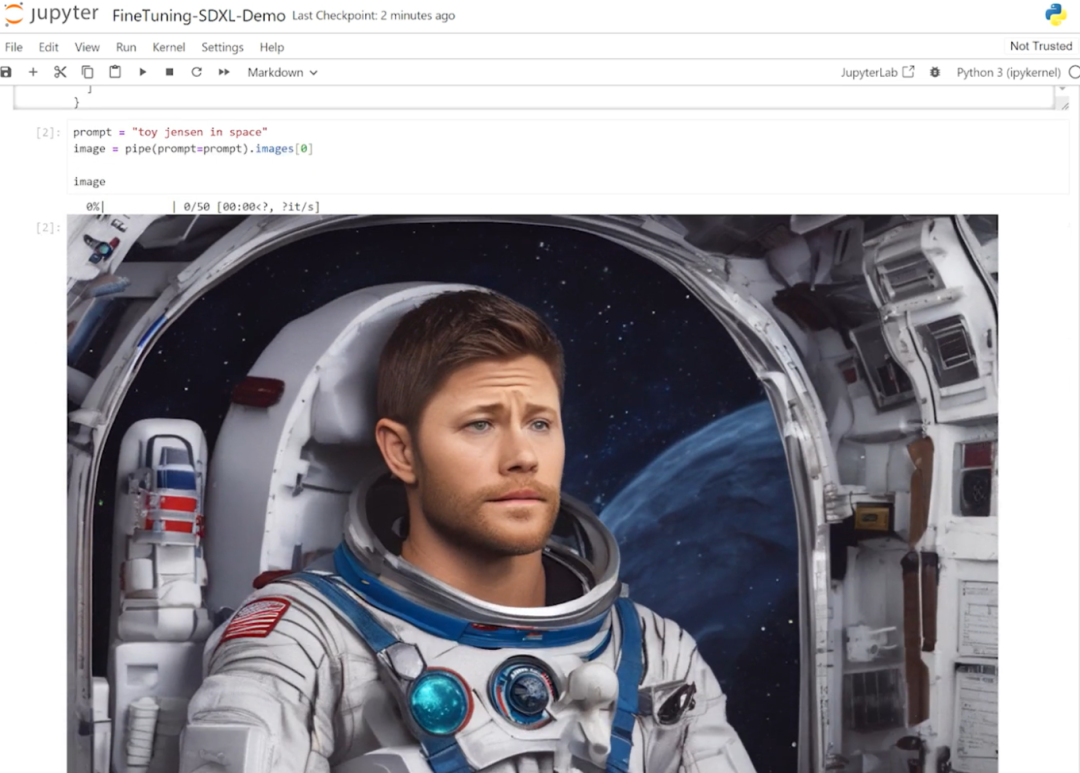 这时就可以通过DreamBooth,并使用8张Toy Jensen的图片对模型进行微调。 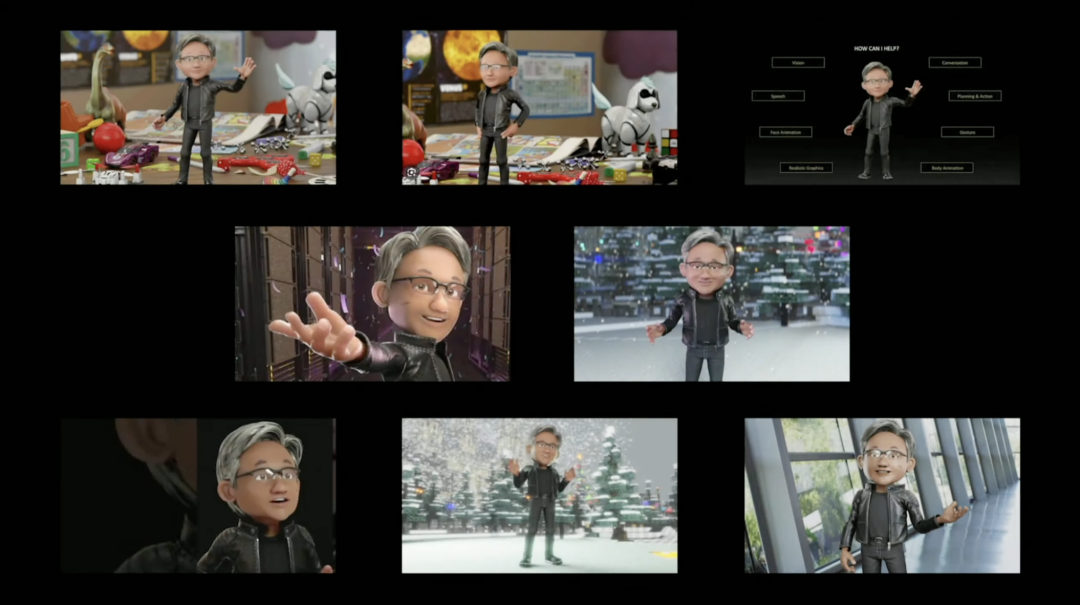 最后,在用户界面上重新运行推理。 现在,知道了Toy Jensen是谁的模型,就可以生成切合需求的图像了。 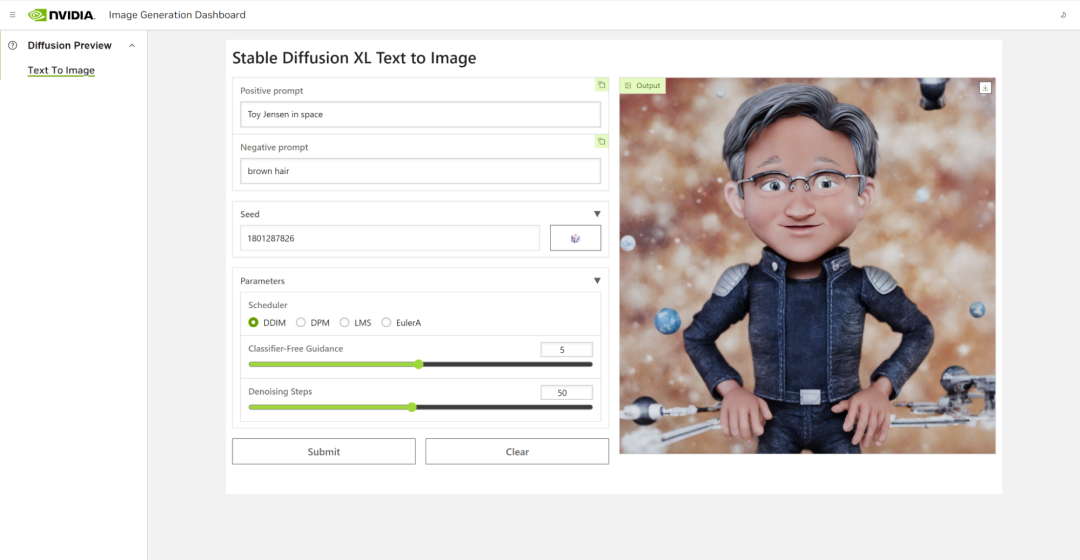 Hugging Face一键访问最强算力 Hugging Face一键访问最强算力作为最受AI开发者喜爱的平台之一,拥有200万用户、超25万个模型,以及5万个数据集的Hugging Face,这次也与英伟达成功达成了合作。 现在,开发者可以通过Hugging Face平台直接获得英伟达DGX Cloud AI超算的加持,从而更加高效地完成AI模型的训练和微调。 其中,每个DGX Cloud实例都配备有8个H100或A100 80GB GPU,每个节点共有640GB显存,可满足顶级AI工作负载的性能要求。 此外,英伟达还将联合Hugging Face推出全新的「Training Cluster as a Service」服务,简化企业创建和定制生成式AI模型的过程。 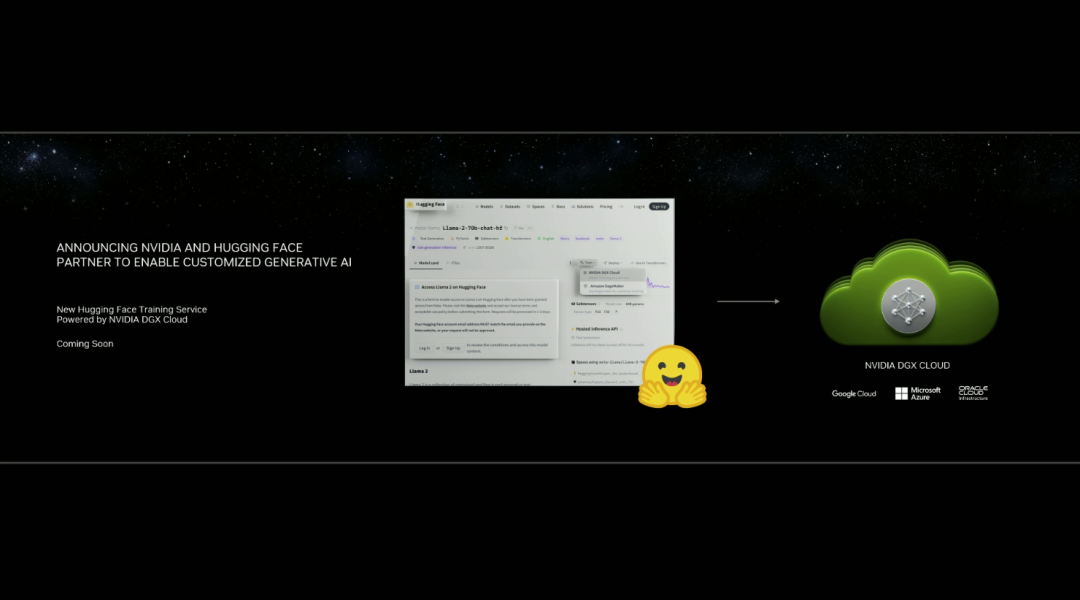 对此,老黄激动得表示:「这次,Hugging Face和英伟达将世界上最大的AI社区与全球领先的云AI计算平台真正地连接在了一起。Hugging Face的用户只需点击一下,即可访问英伟达的最强AI算力。」 AI Enterprise 4.0:定制企业级生成式AI为了进一步加速生成式AI的应用,英伟达也将其企业级平台NVIDIA?AI Enterprise升级到了4.0版本。 目前,AI Enterprise 4.0不仅可以为企业提供生成式AI所需的工具,同时还提供了生产部署所需的安全性和API稳定性。  - NVIDIA NeMo 一个用于构建、定制和部署大语言模型的云原生框架。借助NeMo,英伟达AI Enterprise可以为创建和定制大语言模型应用提供了端到端的支持。 - NVIDIA Triton管理服务 帮助企业进行自动化和优化生产部署,使其在Kubernetes中能够自动部署多个推理服务器实例,并通过模型协调实现可扩展A 的高效运行。 - NVIDIA Base Command Manager Essentials集群管理软件 帮助企业在数据中心、多云和混合云环境中最大化AI服务器的性能和利用率。 除了英伟达自己,AI Enterprise 4.0还将集成到给其他的合作伙伴,比如Google Cloud和Microsoft Azure等。 此外,MLOps提供商,包括Azure Machine Learning、ClearML、Domino Data Lab、Run:AI和Weights & Biases,也将与英伟达AI平台进行无缝集成,从而简化生成式AI模型的开发。 Omniverse:在元宇宙中加入大语言模型 最后,是NVIDIA Omniverse平台的更新。 在接入了OpenUSD和AIGC工具之后,开发者可以更加轻松地生成模拟真实世界的3D场景和图形。 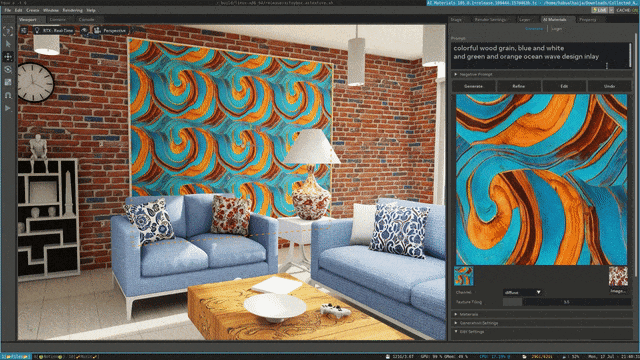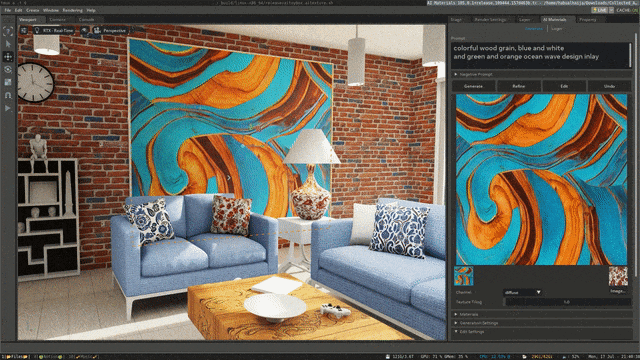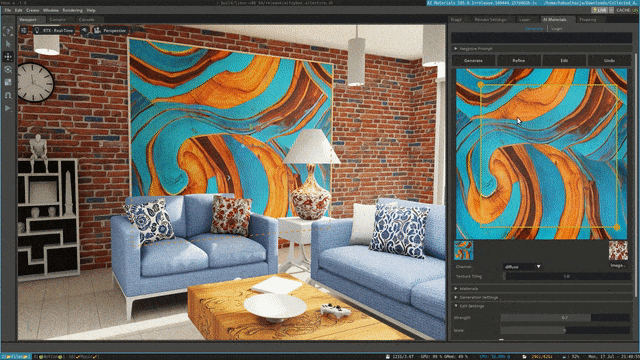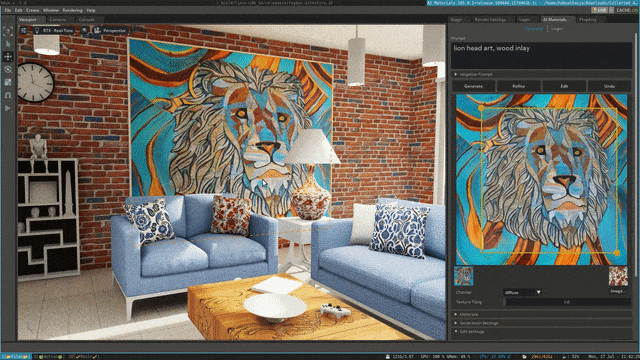 就像它的名字一样,Omniverse的定位是一个集合了各种工具的3D图形制作协作平台。 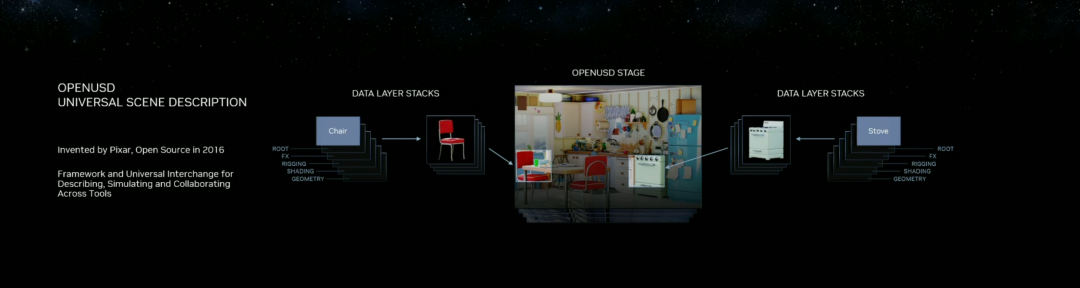 3D开发者可以像文字编辑们在飞书或者钉钉中一样,在Omniverse上共同制作3D图形和场景。 而且可以将不同的3D制作工具制作出来的成果直接整合在Omniverse之内,将3D图形和场景的制作工作流彻底打通,化繁为简。 OpenUSD 而这次更新中,接入的OpenUSD是什么东西?  OpenUSD(Universal Scene Description)提供了一个开源,通用的场景描述格式,使不同品牌、不同类型的3D设计软件可以无障碍的协作。 Omnivers本身就是建立在USD体系之上的,这次Omniverse针对OpenUSD的升级,使得Omniverse能为开发者,企业推出了更多的框架和资源服务。 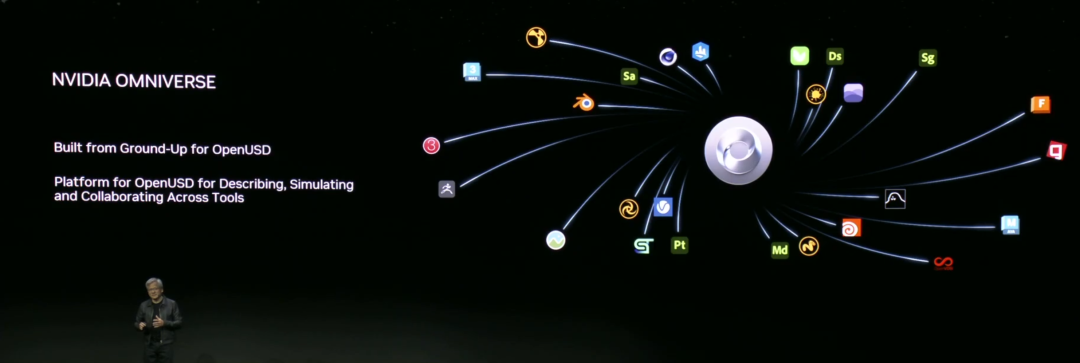 基于OpenUSD这个开源的3D图像编辑格式,5家公司(苹果,皮克斯,Adobe,Autodesk,英伟达)成立了AOUSD联盟,进一步推动了3D图像业界采用OpenUSD格式。 而且,借助AOUSD联盟的成立,Omniverse的开发者也可以方便的创建各种兼容于苹果的ARKit或者是RealityKit的素材和内容,更新后Omniverse也支持OpenXR的标准,使得Omniverse能够支持HTC VIVE,Magic Leap,Vajio等VR头显设备。  API,ChatUSD和其他更新 此外,英伟达还发布了新的Omniverse Cloud API,让开发者可以更加无缝地部署OpenUSD管线和应用程序。 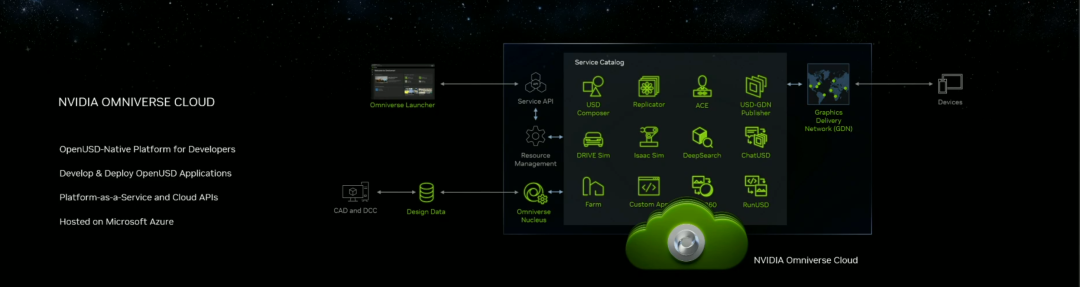 而最引人瞩目的,就是支持基于大语言模型的ChatUSD的支持。 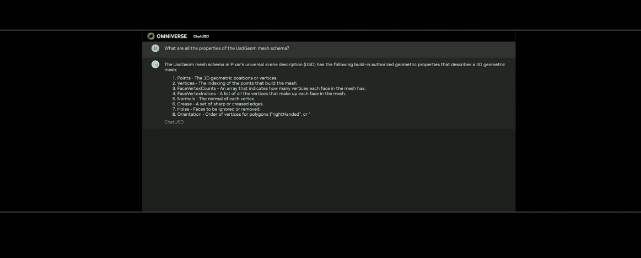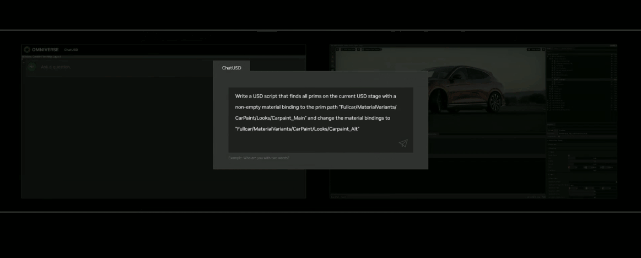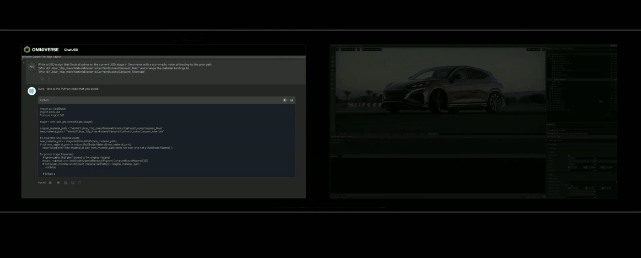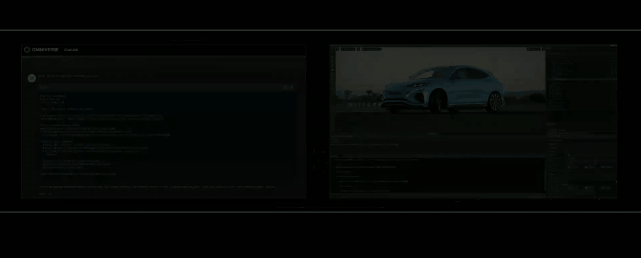 基于大语言模型技术的ChatUSD能像Github Copilot一样,在Omniverse平台中回答开发者的相关问题,或者自动生成Python-USD的代码,让开发人员效率暴增。 总而言之,英伟达再次用暴力的产品,令人惊叹的技术,高瞻远瞩的洞见,让全世界再次看到,它未来将如何引领世界AI和图形计算的新浪潮。 在老黄的经典名言「the more you buy,the more you save!」中,老黄缓缓走下舞台,却把现场气氛推向了最高潮。 参考资料: https://www.nvidia.cn/events/siggraph/ |