 玩币族移动版
玩币族移动版




卷入大模型,手机厂商的新叙事
时间:2023-08-16 来源:区块链网络 作者:Model进化论
作者|武静静 编辑|栗子 来源:甲子光年 小米的大模型在雷军2023年年度演讲中首次公开亮相。 雷军提到,和很多互联网平台的思路不同,小米大模型的重点突破方向是轻量化和本地部署,能在手机端侧跑通。 他称,目前,13亿参数规模的MiLM1.3B模型已经在手机上跑通,且效果可以媲美60亿参数的大模型在云端运算的结果。在他晒出的成绩单中,小米端侧大模型在CMMLU中文评估的各项主题中都比智谱AI的ChatGLM2-6B模型表现好,和百川智能的Baichuan-13B大模型的得分差距约在5分左右。 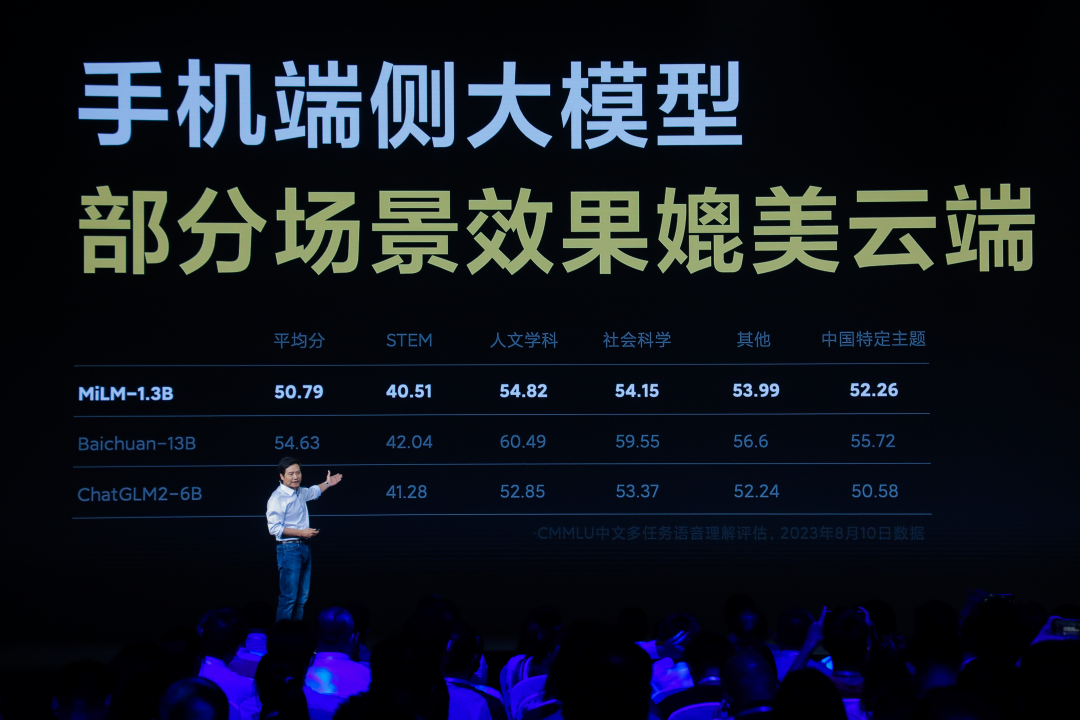 (图源:小米) 此前,小米开发的大规模预训练语言模型MiLM-6B/1.3B已经登陆代码托管平台GitHub,并在C-Eval总榜单排名第十、同参数量级排名第一,在中文大模型基准“CMMLU”上,“MiLM-6B”排名第一。 当然,由于这些测试榜单的维度都是公开的,根据测试任务进行刷榜刷分对于很多大模型公司并非难事,所以这些测评结果只能作为参考,并不意味着效果上的绝对优秀。 同时,雷军也宣布小爱同学作为小米大模型第一个应用的业务,已经进行了全新的升级,并正式开启邀测。 这是从今年4月宣布新设立大模型团队以来,小米在4个月时间中做出的阶段性大模型成果。 小米的实践给大模型落地带来什么新思考?对于借助新技术迭代的手机厂商而言,又意味着什么? 1.小米不做通用大模型,核心团队约30人小米在大模型路线上属于理性派——不追求参数规模,不做通用大模型。 此前在财报电话会上,小米集团总裁卢伟冰就对外称,小米会积极拥抱大模型,方向是与产品和业务深度结合,不会像OpenAI一样去做通用大模型。 根据深燃此前的报道,小米集团AI实验室主任王斌博士曾说,小米不会单独发布一款类ChatGPT产品,自研大模型最终会由产品带出来,相关投入约几千万人民币级别。 他说:“对于大模型,我们属于理智派。小米有应用场景优势,我们看到的是大模型跟场景结合的巨大机会。” 他透露,在ChatGPT诞生之前,小米内部做过大模型相关的研发和应用,当时是通过预训练+下游任务监督微调的方式来做人机对话,参数规模在28亿到30亿。这主要是在预训练基座模型的基础上,通过对话数据的微调实现的,并非现在所说的通用大模型。 根据公开资料,目前小米大模型团队负责人为AI语音方向专家栾剑,向技术委员会副主席、AI实验室主任王斌汇报。整个大模型团队有30人左右。 栾剑曾是智能语音机器人“微软小冰”首席语音科学家及语音团队负责人,曾任东芝(中国)研究院研究员、微软(中国)工程院高级语音科学家。加入小米后,栾剑曾先后负责语音生成、NLP等团队,以及相关技术在小爱同学等产品中落地。王斌2018年加入小米,2019年起负责AI实验室,加入小米前曾是中国科学院信息工程研究所研究员、博导,在信息检索与自然语言处理领域有近30年研究经验。 做大模型也依托于小米背后的AI团队,雷军称,小米的AI团队经过7年时间,6次扩展,已经超过3000人,覆盖了CV、NLP、AI影像、自动驾驶、机器人等多个领域。  (图源:小米) 2.谷歌、高通、华为纷纷入局小米之外,让大模型跑在手机上是很多科技公司当前的重点目标。 科技公司正在想象大模型带来这样一种可能性:不管你打开的是WPS、石墨文档还是邮件,只要输入写作等指令,手机就可以调用本地能力生成完整的一篇文章或者一封邮件。手机端,所有的App都可以随时调用本地的大模型来帮忙处理工作和解决生活问题,人和手机上各种App的交互也不再是频繁的点击,而是通过语音就能进行智能召唤。 很多公司正在想方设法地压缩模型体积,让大模型在手机上的本地运行变得更实用且经济。在今年5月的Google I/O大会上,谷歌发布PaLM2时,按照规模大小分为四种规格,从小到大依次为Gecko、Otter、Bison和Unicorn,其中体积最小的Gecko可以在手机上运行,并且速度很快,每秒可处理20个标记,大约相当于16或17个单词,也可支持手机离线状态运行。但当时谷歌没说这款模型会具体用在哪一款手机上。 目前已经拿出具体成绩的是高通。在今年3月的2023MWC上,高通在搭载第二代骁龙8的智能手机上,运行了超过10亿参数的文生图模型Stable Diffusion。演示中,工作人员在一部没有联网的安卓手机上用Stable Diffusion生成了图像,整个过程用了15秒。 6月的计算机视觉学术顶会CVPR上,高通又展示了在安卓手机上运行15亿参数规模的ControlNet模型,出图时间仅用了11.26 秒。高通产品管理高级副总裁兼AI负责人Ziad Asghar称:从技术上,把这些超10亿参数大模型搬进手机,只需要不到一个月的时间。 最新的动作是高通宣布和Meta合作,探索基于高通骁龙芯片,在不联网的情况下,在智能手机、PC、AR / VR头显设备、汽车等设备上,运行基于Llama 2模型的应用和服务。高通称,和基于云端的LLM相比,在设备本地运行Llama 2 等大型语言模型,不仅成本更低,性能更好,且不需要连接到在线服务,服务也更个性化、更安全和更私密。 尚未官宣任何大模型动作的苹果也正在探索大模型在设备端侧的落地。据《金融时报》报道,苹果正在全面招聘工程师和研究人员来压缩大语言模型,以便它们能够在iPhone和iPad上高效运行,主要负责的团队是机器智能和神经设计 (MIND) 团队。 目前,在Github上,一个热门的开源模型MLC LLM项目就可以支持本地部署,它通过仔细规划分配和积极压缩模型参数来解决内存限制,可以在iPhone等各类硬件设备上运行AI模型。该项目是由CMU助理教授,OctoML CTO陈天奇等多位研究者共同开发的,团队以机器学习编译(MLC)技术为基础来高效部署AI模型。MLC-LLM上线不到两天,GitHub的Star量已经接近一千。有人已经测试了在iPhone的飞行模式下本地跑大语言模型。 和国外谷歌、高通强调大模型在端侧本地部署,可以离线运行不同,目前国内手机厂商优先考虑的是将大模型落地在手机语音助手或者现有的图片搜索功能上,这种升级本质还是调用更多云端能力来使用大模型。 此次,小米就是将大模型用在了语音助手小爱同学上。但由于目前小米端侧大模型相关信息尚未披露,无法准确判断之后小米大模型的发展路径。从雷军强调的本地部署和轻量化的方向来看,未来小米可能会尝试大模型在手机端离线运行。 华为也在尝试大模型在手机端的落地,不过重点瞄准的依旧是手机语音助手和搜图场景。此前4月,华为新发布的手机P60上,智慧搜图新功能背后就是多模态大模型技术,过程中在手机端侧对模型进行小型化处理。近期,华为新升级的终端智能助手小艺也基于大模型进行体验优化,可以根据语音提示推荐餐厅、进行摘要总结等新功能。 OPPO、vivo也在这个方向发力,8月13日,OPPO宣布,基于AndesGPT打造的全新小布助手即将开启体验,从资料中可以看到,小布助手集合大模型能力之后,在对话、文案撰写等方面的能力会有所加强。AndesGPT是OPPO 安第斯智能云团队打造的基于混合云架构的生成式大语言模型。 对于手机厂商而言,不管是本地部署,还是调用云端能力,大模型之于手机,都是一个不可错失的新机会。 3.大模型跑在手机上,关键难题在哪儿?让大模型跑在手机上不是一件容易的事。 算力是首要问题。在手机端使用大模型,不仅需要调用云端算力还需要调用终端设备的算力,由于大模型的大资源消耗,每一次的调用都意味着很高的成本。Alphabet董事长John Hennessy曾提到,用大语言模型的搜索成本比此前的关键词搜索成本高出10倍。去年,谷歌有3.3万亿次搜索查询,成本约为每次五分之一美分。华尔街分析师预测,如果谷歌用大语言模型来处理一半的搜索问题,每次提供的答案为50个单词左右,到2024年,谷歌可能面临60亿美元的支出增长。 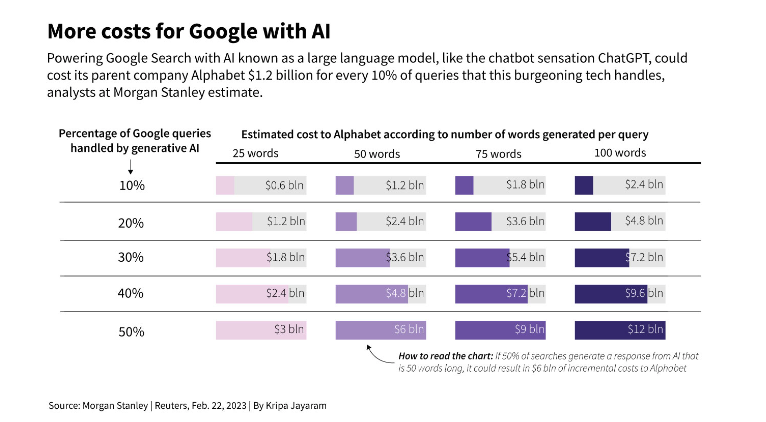 (图源:路透社) 手机端运行大模型面对类似的成本难题,在高通发布的《混合AI是AI的未来》报告中提到,就像传统计算从大型主机和客户端,演变为当前云端和边缘终端相结合的模式一样,端侧运行大模型也需要混合AI架构,让云端和边缘终端之间分配并协调AI工作负载,从而能让手机厂商利用边缘终端的计算能力降低成本。让大模型实现本地部署就是出于这一成本问题的考量。 此外,手机作为每个人的私人物品,是数据产生的地方,本地也存放着大量的私人数据,如果能够实现进行本地部署,在安全性、隐私等方面为个人提供了保障。 这就带来了第二个难题,如果想更多地调用端侧能力来运行大模型,如何让手机的能耗很低,同时还能让模型的效果很强? 高通曾对外称,之所以能将大模型部署到手机等本地设备上,关键能力在于高通软硬件全栈式的AI优化,其中包括高通AI模型增效工具包(AIMET)、高通AI引擎和高通AI软件栈等相关技术,可以压缩模型体积,加速了推理,并降低运行时延和功耗。高通全球副总裁兼高通AI研究负责人侯纪磊曾提到,高通在高效能AI研发中,一个重要的部分是整体模型效率研究,目的是在多个方向缩减AI模型,使其在硬件上高效运行。 单模型压缩就是一个不小的难点。有的模型压缩会对大模型的性能造成损失,有一些技术方式可以做到无损压缩,这些都需要借助各种工具进行不同方向的工程化尝试。 这些关键的软硬件能力对于手机厂商而言都是很大挑战。如今,很多手机厂商都迈出了在手机上跑大模型的第一步。接下来,如何让更好的大模型,更经济、更高效地落在每一部手机中反而是更难、更关键的一步。 冒险才刚刚开始。 |