 玩币族移动版
玩币族移动版




咖啡厅监控流出百万人围观,马斯克惊呼太可怕!你喝了几分钟咖啡,AI一清二
时间:2023-08-20 来源:区块链网络 作者:AI梦工厂
文章来源:新智元 编辑:Aeneas 好困  这家咖啡厅里,顾客待了多长时间,店员做了几杯咖啡,在AI摄像头下是一清二楚。百万网友围观称太可怕,马斯克都震惊了。 这家咖啡厅里,顾客待了多长时间,店员做了几杯咖啡,在AI摄像头下是一清二楚。百万网友围观称太可怕,马斯克都震惊了。我们生活的世界,越来越没有隐私。 今天,网上流出的这段视频,把许多人都吓到了。 在一个咖啡店里,每个顾客进店待了几分钟,每个服务员给顾客端了几杯咖啡,都在视频里显示得一清二楚!  视频发布才十几个小时,已经有100多万网友围观了。  发布视频的网友表示:这个概念展示了咖啡店是如何使用AI分析咖啡师和顾客的。请在咖啡店充分「享受」您的隐私吧。???? 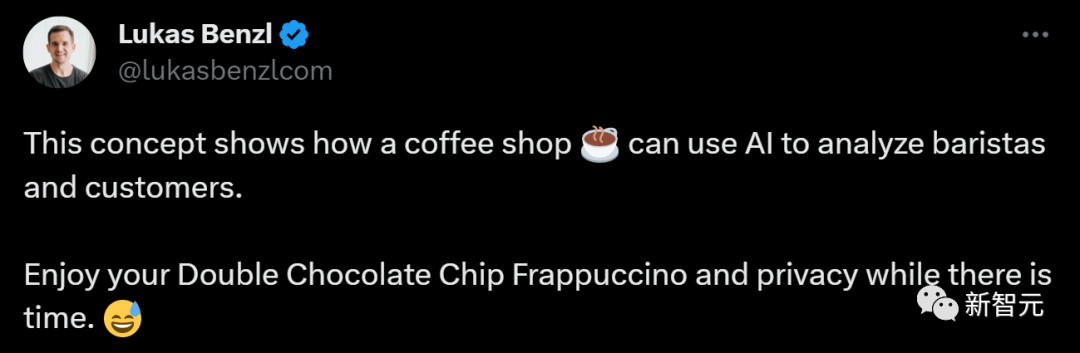 另一位网友表示,这没什么大惊小怪的。作为消费者,你应该知道很多商店在你进去的一瞬间,就对你的一切了如指掌。 相比之下,「剑桥分析事件」只是小巫见大巫罢了。 (2018年,Facebook承认,这家英国数据分析公司在2016年违规获得了5000万Facebook用户的信息,利用这些资料构建了一个软件程序,从而预测和影响了投票箱结果,成功地帮助特朗普赢得总统大选。) 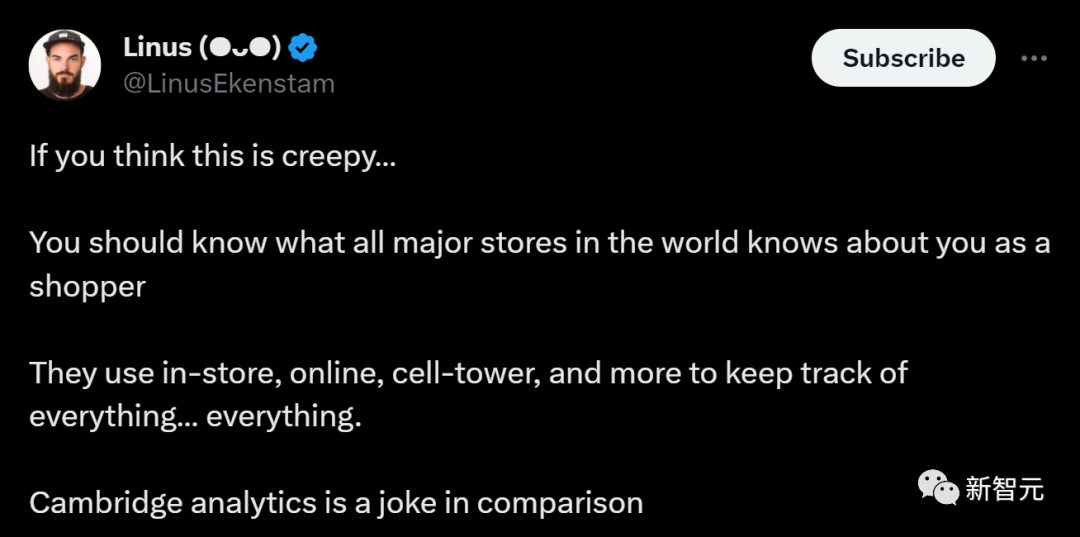 连马斯克本人都现身评论区,连续留下了两个惊叹号。 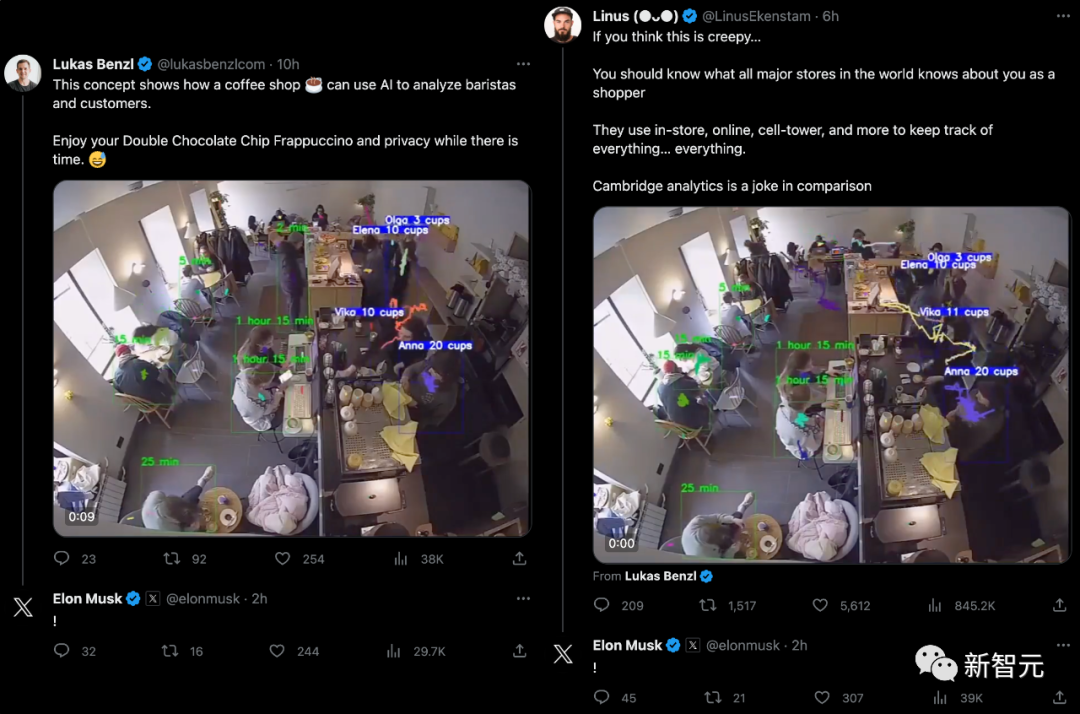 如果你觉得在咖啡馆里用AI监视员工和顾客已经够可怕了,现实就是,如果不考虑成本,空中可以有数千架无人机向监管部门发送实时跟踪数据,一切都会被跟踪和记录。 甚至不需要专业部门,任何人都可以在业余无人机上进行跟踪,因为目前的物体检测和图像识别技术实在太强大了。  要知道,几年前在独立显卡上运行1080p串流时,最大容量也不过就是6个对象。 无处不在的「眼睛」现实就是,我们现在的世界,到处都是摄像头。 其中,已经有不少企业部署了非常隐蔽的策略,用于追踪消费者,一切都是通过AI和视频源上的视觉识别来完成的。 比如沃尔玛的智能零售实验室内,IRL传感器和摄像头,让工作人员对店里的一切都了如指掌。  快餐店也采用了AI技术进行员工监督。这里规定员工必须戴口罩,如果谁摘下口罩,经理就会立刻知道。  另外,我们的移动位置数据也在出售。  几乎所有手机运营商,都在匿名向零售店售卖数据,可以说这是他们的一部分核心业务。 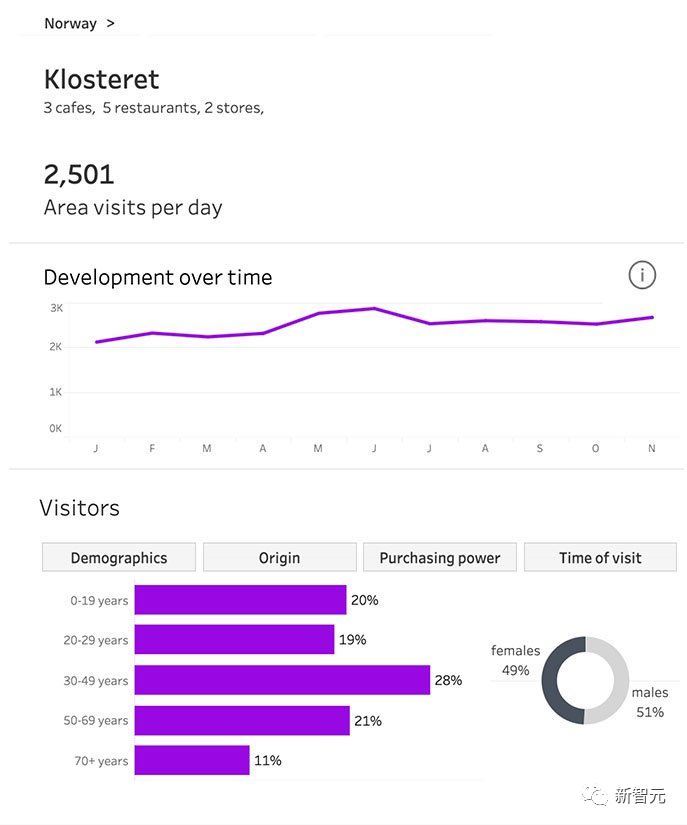 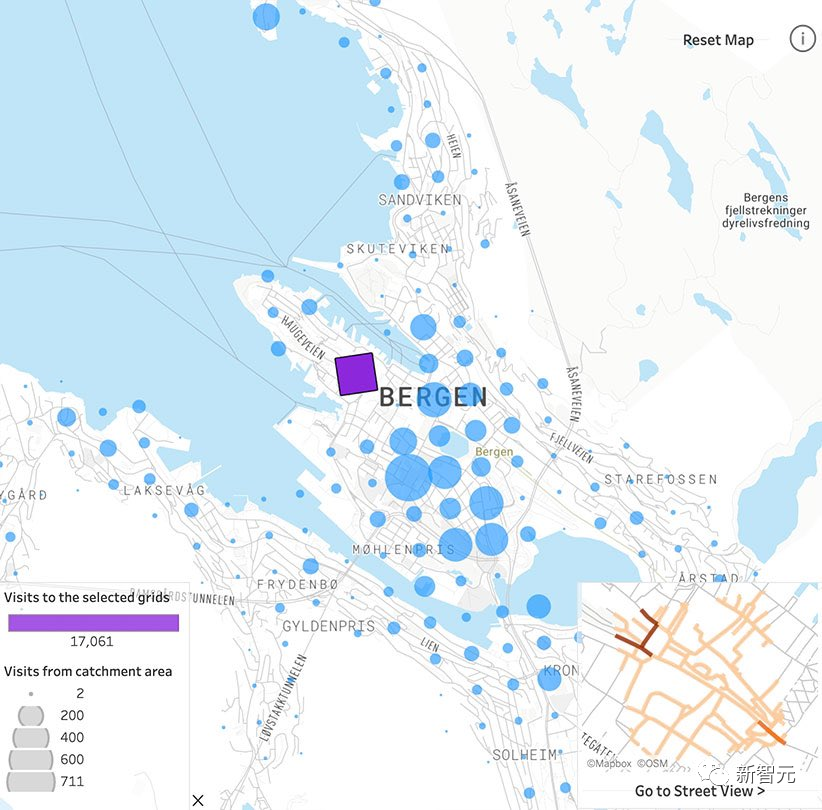 只要谷歌一下「运营商名称+crowd insights(人群洞察)」,得到的结果就会令你惊讶。 「想知道特定时间内经过特定地点的人群数量是多少吗?他们的年龄、收入状况怎样,有多少能够成为潜在客户?」 当然,「人群洞察」服务会强调:数据都是匿名的,收据收集的方式并不会暴露个人隐私。  有人表示:既然我的数据被收集了,我可以要求企业向我付费吗?  关于企业中采用的摄像头,评论区有人现身说法—— 「我在体育场的后端安全摄像头系统工作,我们向公众发布的内容,只有实际数据的1/3。」  「这简直就像在电影中,把自己的脸输进去,系统就会识别出你在哪里。」  而实现这一切,你只需要利用任意的摄像头,安装一个300美元的软件,然后开始运行,直到磁盘空间用尽。  利与弊? 利与弊?对此,AI咨询专家Diego San Esteban分享了自己的观点:  他认为,AI监测当然有不少优点,比如能持续监控员工的表现和生产力,让管理人员更好地制定战略。 另外,AI也可以提供客观的绩效数据,避免在评估中出现人为的偏见。 而缺点也不少,最为人诟病的自然是对员工隐私权的侵犯,并且还会在企业内产生不信任的气氛,影响士气和工作满意度。 AI也无法充分理解工作进行的背景,还缺乏人类的同理心。 并且,它很可能会犯错,受到训练数据固有的偏见影响,这对员工是极度不公平的。 目标检测算法其实,这次备受争议的事件背后,就是一种很常见的AI技术——目标检测。 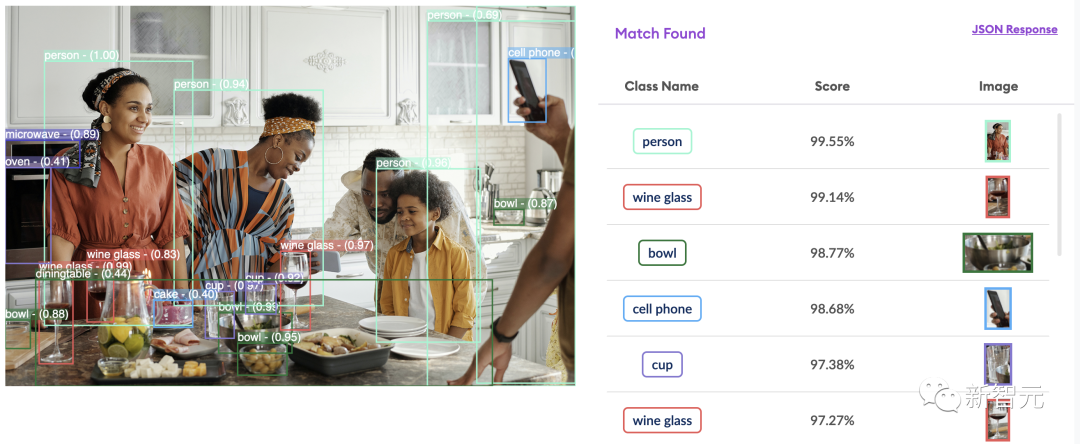 例如,给定一张城市街道的照片,目标检测模型将返回图像中所有不同物体的注释或标签列表:交通信号灯、车辆、道路标志、建筑物等。 这些标签将包含每个物体的适当类别,比如「人」,以及一个「边界框」,即完全包含物体的矩形区域。  行业应用 行业应用目标检测对于人类来说是一项关键任务:当进入新的房间或场景时,我们的第一反应是对其中的物体和人员进行视觉评估,然后理解它们。 与人类类似,目标检测在使计算机理解和与视觉世界进行交互方面发挥着至关重要的作用,并且已经在很多行业中得到了广泛的应用:  - 场所安全: 目标检测模型可以帮助提高工作场所的安全性和安全性。例如,它们可以检测敏感区域中可疑个体或车辆的存在。更具创意性的是,它可以确保工人使用个人防护装备(PPE),如手套、头盔或口罩。 - 社交媒体: 目标检测模型可以帮助识别数字媒体中特定品牌、产品、标志或人物的存在。广告商可以利用这些信息来收集数据,并向用户展示更相关的广告。它还有助于自动化检测和标记不当或禁止内容的过程。 - 质量控制: 目标检测模型实现了对视觉数据的自动化审查。计算机和摄像头可以实时分析数据,自动检测和处理视觉信息并理解其重要性,从而减少了在需要进行持续视觉审查的任务中的人工干预。这在制造生产质量控制方面尤其有用。它不仅提高了效率,还可以检测到人眼可能忽略的生产异常,从而防止潜在的生产中断或产品召回。  首次达到66 AP,最强SOTA算法霸榜 首次达到66 AP,最强SOTA算法霸榜当前,在目标检测算法的性能上,来自国内团队的「DETRs with Collaborative Hybrid Assignments Training」,凭借了高达66 AP的成绩霸榜COCO。该工作已经被ICCV 2023录用。 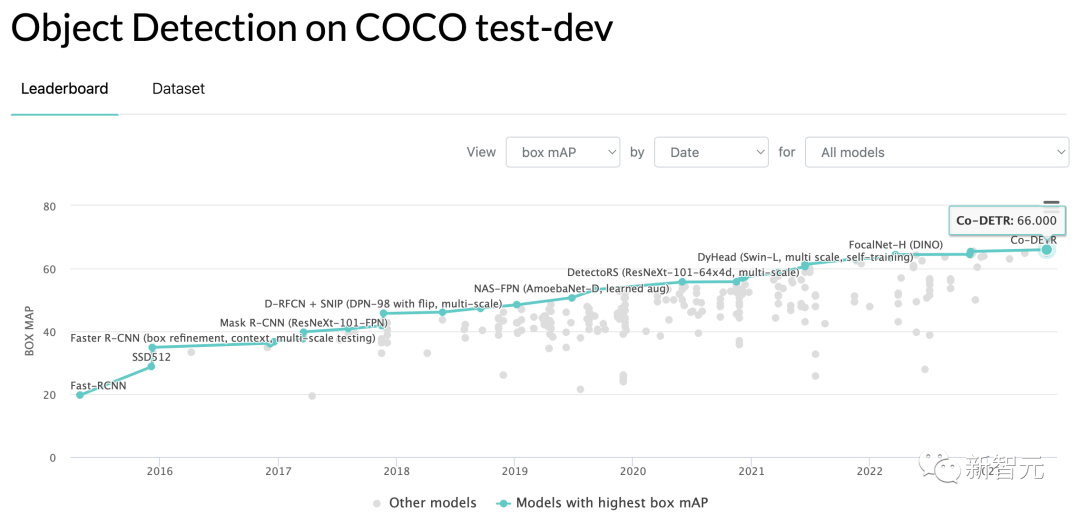 在论文中,作者提出了一种新颖的协作混合分配训练方案——Co-DETR,可以从多样化的标签分配方式中学习更高效且更有效的基于DETR的检测器。 通过训练多个平行辅助头(受到一对多标签分配的监督,如ATSS和Faster RCNN),全新的Co-DETR可以轻松提升端到端检测器中编码器的学习能力。 通过从这些辅助头中提取正坐标来进行额外的定制正查询,Co-DETR还可以提高解码器中正样本的训练效率。 此外,在推理过程中,这些辅助头会被丢弃,因此该方法不会给原始检测器引入额外的参数和计算成本,同时也不需要手工非极大值抑制(NMS)。  论文地址:https://arxiv.org/abs/2211.12860v5 项目地址:https://github.com/Sense-X/Co-DETR - 编码器优化: 训练方案可以通过训练多个平行辅助头,这些头通过一对多的标签分配进行监督,从而轻松提升端到端检测器中编码器的学习能力。 - 解码器优化: 通过从这些辅助头中提取正坐标来进行额外的定制正查询,来改善解码器的注意力学习。 - SOTA的性能: 搭载ViT-L(304M参数)的Co-DETR是第一个在COCO test-dev上实现66.0% AP的模型。  实验结果显示,在Swin-L骨干网络的基础上,Co-DETR方法可以将现有的SOTA模型DINO-Deformable-DETR的性能,从58.5%提高到59.5%(在COCO验证集上)。 在ViT-L骨干网络的支持下,Co-DETR在COCO test-dev上实现了66.0% AP,以及在LVIS验证集上实现了67.9% AP。 此外,与以往方法相比,Co-DETR还在模型规模更小的情况下,取得了更好的性能。 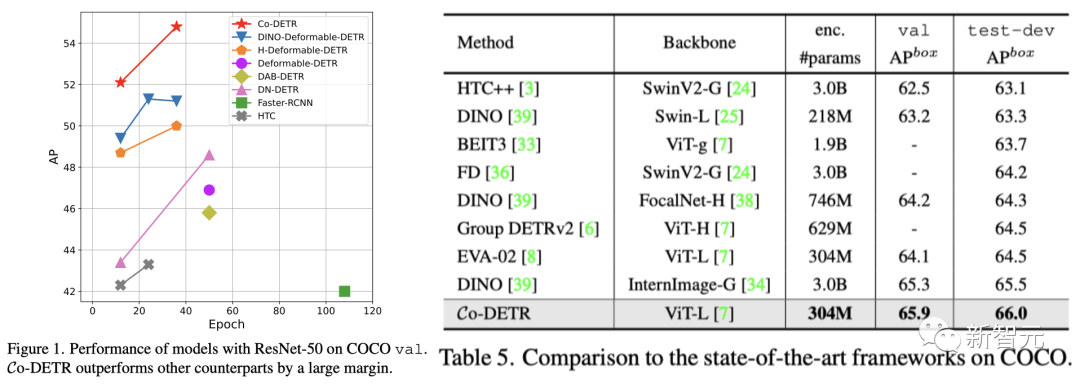 参考资料: https://twitter.com/LinusEkenstam/status/1692602911518343502 https://twitter.com/lukasbenzlcom/status/1692543968829985124 https://www.chooch.com/blog/what-is-object-detection/ https://www.linkedin.com/posts/endritrestelica_ai-tech-activity-7098293527951851520-Mejy?utm_source=share&utm_medium=member_desktop |