 玩币族移动版
玩币族移动版




直接压缩一切!OpenAI首席科学家Ilya Sutskever这么看无监督学习
时间:2023-08-21 来源:区块链网络 作者:AI之势
原文来源:机器之心  图片来源:由无界 AI ?生成 近日,OpenAI 首席科学家 Ilya Sutskever 在专注于计算理论研究的 Simons Institute 作了一次讲座,一句话总结就是我们可以通过压缩的视角来看待无监督学习。此外他还分享了不少其它有趣的见解。机器之心整理了该演讲的大体内容,希望借此帮助读者更深入地理解无监督学习。 Sutskever 首先谈到了自己的研究方向的变化,他说:「不久前,我将全部的研究重心都转移到了 AI 对齐研究上。」这说的是 OpenAI 前段时间成立的「Superalignment(超级对齐)」团队,由他与 Jan Leike 共同领导。Sutskever 表示他们已经在 AI 对齐方面取得了一些研究成果,但这并非这次演讲关注的话题。 这次演讲的主题为「An observation on Generalization(对泛化的一种观察)」,而 Ilya Sutskever 具体谈论的重点是一种解释无监督学习的理论。  首先,Ilya Sutskever 提出了一连串有关「学习」的广义问题:学习究竟是什么?为什么学习有用?为什么学习应该有用?计算机为什么应该具备学习能力?为什么神经网络可以学习?为什么机器学习模型可以学习到数据的规律?我们能否用数学形式来描述学习? 监督学习Sutskever 先从监督学习谈起。他表示,监督学习方面已经有了重要的形式化工作,这是多位研究者在多年前得到的成果;这些成果通常被称为统计学习理论。 监督学习的优势在于能提供一个学习必定成功的精确数学条件。也就是说,如果你有一些来自某数据分布的数据,然后你能成功实现较低的训练损失并且你的训练数据足够多(多于数据分布的自由度),那么你的测试误差必定很低。 从数学上讲,如果能在一类函数中找到能实现较低训练损失的函数,那么学习就必定成功。也因此,监督学习非常简单。 研究者在相关研究中已经发现了一些定理,如下便是一例。Sutskever 表示解释这个定理大概需要五分钟,但很显然他的演讲时间有限。  总而言之,这个定理很「优雅」,只用三行数学推导便能证明监督学习过程。 所以相对而言,监督学习已经得到很好的理解。我们知道其必定会成功的原因 —— 只要我们能收集到大规模的监督学习数据集,那么就完全可以相信模型必定越来越好。当然另一点也很重要,也就是保证测试分布和训练分布一致;只有这样,监督学习理论才是有效的。  所以监督学习的概念是很简单的。我们也已经有了监督学习为什么有效的答案 —— 我们知道语音识别和图像分类为什么可以实现,因为它们都基于有效且有数学保证的监督学习。 这里 Ilya Sutskever 顺带提了提 VC 维度。他提到很多统计学习理论的研究者都认为 VC 维度是一大关键组件,但 VC 维度被发明出来的目的是为了让模型有能力处理有无限精度的参数。  举个例子,如果你的线性分类器的每个参数都有无限精度,而现实中的浮点数的精度都是有限的,而且精度会收缩,那么你可以通过 VC 维度实现一些函数,将这个线性分类器归约成前面公式描述的监督学习形式。 无监督学习是什么?接下来看无监督学习。首先什么是无监督学习?Ilya Sutskever 表示他目前还没看到令人满意的对无监督学习的阐释,我们也不知道如何从数学上推理它 —— 最多只能在直觉上做点推断。 无监督学习是机器学习领域长久以来的梦想。Sutskever 认为这个目标已经在实验研究中达成,即模型在不被告知数据内容的前提下观察数据并发现其中存在的真实有用的隐藏结构。 这是怎么发生的?我们能确保这一定会发生吗?Sutskever 表示我们不能,毕竟我们在无监督学习方面没有在监督学习方面那样的理论保证。  人们早在上世纪 80 年代就在探究无监督学习了,当时使用的术语也是类似。在实验中,人们观察到,当数据量较小时,不会出现无监督学习现象,但是一些现在流行的开发思路已经出现了,比如 BERT、扩散模型、老式的语言模型等。当时的无监督学习也能生成一些很酷的样本,但当然是比不上现在的技术。 但因为我们不知道无监督学习的工作方式,所以它一直都让人困惑。  比如当你针对某个目标(比如图像重建或预测下一个词)进行优化时,你可能也在意另一个目标(比如图像分类或文档分类),而模型可能在这个未经优化的目标上也能取得不错的表现。但为什么会这样呢?不知道,实验结果就是如此。Sutskever 说这就像是魔法。 难道我们就要放弃理论,在实证主义上一路走下去吗?  我们知道无监督学习是学习输入分布中的结构,然后从中获得有助于实现目标的东西。但如果输入分布是均匀分布(uniform distribution)呢?这时候各种无监督学习算法都会失效。我们应该怎么看待这种现象呢?Sutskever 表示我们需要做些假设。 一种无监督学习方法:分布匹配接下来,Sutskever 展示了一种思考无监督学习的潜在方式。他说这种无监督学习方式一直没有成为主流,但却非常有趣。它有与监督学习类似的特征,也就是必然有效。为什么会这样?这涉及到一种名为分布匹配(distribution matching)的无监督学习流程。  接下来简单说明一下。假设有两个数据源 X 和 Y,它们之间并无对应关系;模型的目标是找到函数 F,使得 F (X) 的分布与 Y 的分布近似 —— 这是对 F 的约束(constraint)。 对于机器翻译和语音识别等许多应用场景,这个约束可能是有意义的。举个例子,如果有一个英语句子的分布,使用函数 F 后,可以得到接近法语句子分布的分布,那么就可以说我们得到了 F 的真实约束。 如果 X 和 Y 的维度都足够高,那么 F 可能就有大量约束。事实上,你甚至有可能从那些约束中恢复完整的 F。这是无监督学习的监督学习(supervised learning of unsupervised learning)的一个示例,它必定有效,就像监督学习必定有效一样。 此外,替代密码(subsitution cipher)也符合这一框架。 Sutskever 表示自己在 2015 年时独立发现了这一现象。这让他不禁思考:也许我们能用某种有意义的数学形式来描述无监督学习。 当然,上面描述的机器翻译场景是简化过的人工场景,并不符合真实的应用情况,对应的无监督学习场景自然也是如此。 接下来,Sutskever 将阐述他提出的方法 —— 其能从数学上为无监督学习提供说明以及确保无监督学习的结果优良。 众所周知,压缩就是一种预测,每个压缩器都可以转换为一个预测器,反之亦然。全体压缩器与全体预测器之间存在一一对应关系。 Sutskever 指出,为了能更清晰地说明对无监督学习的思考,使用压缩方面的论述方式更具优势。  基于此,他给出了一个思想实验。  假设你有两个数据集 X 和 Y,它们是你的硬盘上的两个文件;然后你有一个很棒的压缩算法 C。再假设你对 X 和 Y 进行联合压缩,也就是先将它们连接起来,然后将其馈送给压缩器。 现在的重要问题是:一个足够好的压缩器会做什么? Sutskever 给出了一个非常直觉式的答案:压缩器会使用 X 中存在的模式来帮助压缩 Y;反之亦然。 他表示,预测任务场景其实也存在类似的现象,但在压缩语境中说起来似乎就更直观一点。 如果你的压缩器足够好,那么对连接后文件的压缩结果应该不会差于分开压缩的结果。  因此,通过连接所获得的进一步压缩效果是你的压缩器注意到的某种共有的结构。压缩器越好,其能提取出的共有结构就越多。 两种压缩结果之间的差就是共有结构,即算法互信息(algorithmic mutual information)。 对应地,可以把 Y 视为监督任务的数据,X 视为无监督任务的数据,而你对这些信息有某种形式的数学推理 —— 可以使用 X 中的模式来帮助 Y 任务。  也要注意其如何实现了对分布匹配的泛化。如果是在分布匹配情况下,假如 X 是语言 1,Y 是语言 2,并且存在某个简单函数 F 可从一个分布转换到另一个分布;那么优良的压缩器也能注意到这一点并将其利用起来,甚至可能在内部恢复出该函数。 这样一来,闭环就形成了。那么我们如何用数学形式描述无监督学习呢? 无监督学习的数学形式化注意这一部分的描述会交替使用压缩场景和预测场景的描述。  首先假设我们有一个机器学习算法 A,其作用是压缩 Y。算法 A 能够访问 X。令 X 为 1 号文件,Y 为 2 号文件。我们希望我们的机器学习算法 / 压缩器能对 Y 进行压缩并且其能在合适的时候使用 X。目标是尽可能地压缩 Y。 那么我们要问自己:使用这个算法最大的遗憾(regret)是什么? Sutskever 解释说:「如果我很好地完成了工作并且我的遗憾很低,就意味着我已经从这未标注的数据中获得了所有尽可能的帮助。这些未标注数据已经尽可能地帮助了我。我对此毫无遗憾。」也就是说已经没有更好的预测值可供更好的压缩算法使用了。「我已经从我的未标注数据中获得了最大收益。」 Sutskever 认为这是向思考无监督学习所迈出的重要一步。你不知道你的无监督数据集是否真的有用,但如果你在监督学习算法上的遗憾很低,那么不管有没有用,你都已经得到了最佳结果,不可能会有更好的结果了。 现在进入有些晦涩难懂的理论领域。  将 Kolmogorov 复杂度用作终极压缩器能为我们提供超低遗憾的算法,但这其实并不是算法,因为它不可计算。 先简单解释一下 Kolmogorov 复杂度:就好比你给我一些数据,为了压缩它,我给你提供一个可能存在的最短的程序。Kolmogorov 复杂度就等于这个最短程序的长度。  令 C 是一个可计算的压缩器,那么对于所有 X,Kolmogorov 压缩器的复杂度小于压缩器 C 的任意输出加上实现该压缩器所需的代码字符数。 我们可以使用模拟论证(simulation argument)来证明这一点。假设有一个非常棒的压缩器 C,那么它可能是一个计算机程序,如果将这个计算机程序交给 K 来运行,那么 K 所需的成本就是这个程序的长度。Kolmogorov 压缩器可以模拟其它计算机程序和其它压缩器,也因此它是不可计算的。它就像是一个能够模拟所有计算机程序的自由程序,但它也是有可能存在的最好的压缩器。 现在我们泛化 Kolmogorov 压缩器,使其可以使用其它信息。我们知道 Kolmogorov 压缩器是不可计算的,不可判定的,而像是搜索所有程序。这就像是使用神经网络通过 SGD(随机梯度下降)调整参数来搜索程序。这个过程运行在有一定资源(内存、 步骤数)的计算机上,这就像是非常微小的 Kolmogorov 压缩器。这两者存在相似之处。  神经网络可以模拟小程序,它们是小小的计算机,有回路 / 电路。我们可以使用 SGD 训练这些计算机,从数据中找到它的「电路」。 模拟论证在这里也适用。如果你想设计一个更好的神经网络架构,你会发现这很困难,因为增添或修改连接这些操作虽然可以被其它神经网络架构模拟,但实际却难以做到。因为这些是能带来巨大提升的罕见情况。正如从 RNN 到 Transformer 转变。RNN 有一个瓶颈:隐藏状态。但如果我们能找到一种方法,让 RNN 可以拥有非常大的隐藏状态,那么它的性能表现可能会重新赶上 Transformer。 所以我们可以把条件 Kolmogorov 复杂度作为无监督学习的解,如下所示:  其中 C 是一个可计算的压缩器,K (Y|X) 是如果能使用 X,能输出 Y 的最短程序的长度。 这是无监督学习的超低遗憾的解,只不过它是不可计算的,但却能提供一个有用的框架。 直接压缩一切!Sutskever 又进一步提到「直接压缩一切」也是可行的。  条件 Kolmogorov 复杂度 K (Y|X) 在机器学习语境中是不自然的,因为它是基于 X 来压缩 Y,而至少就目前而言,以大型数据集为条件还是基本无法办到的。我们可以拟合大型数据集,但很难以其为条件。  而上式是表示:如果你想要对你监督的东西 Y 进行预测,使用压缩 X 和 Y 连接数据的常规 Kolmogorov 压缩器的表现与条件压缩器一样好。当然实际细节还有更多微妙之处,但这其实就是表示我们可以使用常规 Kolmogorov 压缩器来求解无监督学习 —— 就是将你的所有数据连接起来,然后执行压缩,这样就能在你关心的监督任务上得到很好的结果。 对此的证明要更复杂一些,这里就不再继续深入了。  重点的结论是常规 Kolmogorov 压缩(无需以某个数据集为条件)是「以最好的可能方式使用」无标注数据。这就是无监督学习的解。 联合压缩就是最大似然Sutskever 在演讲中谈到的最后一点是:这种联合压缩就是最大似然,只要没有过拟合。  如果你有一个数据集,那么给定参数的似然之和就是压缩该数据集的成本。你还需要支付压缩参数的成本。而如果你想压缩两个数据集,也没有问题,只需向你的数据集添加数据点即可,也就是向上面的求和运算 sum 添加更多项。 所以通过连接数据来进行联合压缩在机器学习语境中是非常自然的做法。相比而言,通过条件 Kolmogorov 复杂度就麻烦多了。 我们甚至可以将其用于解释神经网络的工作方式。我们可以将用于大型神经网络的 SGD 用作我们的大型程序搜索器。神经网络越大,就能更好地近似常规 Kolmogorov 压缩器。Sutskever 评价说:「也许这就是我们喜欢大型神经网络的原因,因为我们可以以此近似不可实现的无遗憾常规 Kolmogorov 压缩器思想。随着我们训练的神经网络越来越大,遗憾会越来越低。」 此理论也适用于 GPT 模型吗?Sutskever 对此的答案是肯定的,不过解释 GPT 模型的行为时,无需引述有关压缩或监督学习的说明,你可以说 GPT 的「理论」可以通过对文本的条件分布进行推理而得到。 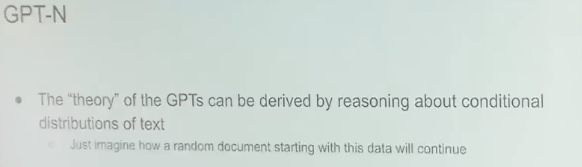 那么,我们能找到其它的直接验证方法来验证这一理论吗?我们能用视觉等其它领域来解释吗?如果我们在像素数据上这样操作,我们能得到优良的无监督学习吗? Sutskever 表示他们已经在 2020 年做过这样的研究,即 iGPT。当然,这主要是一个验证概念的研究,离实践应用还有很大距离,详见论文《Generative Pretraining from Pixels》。 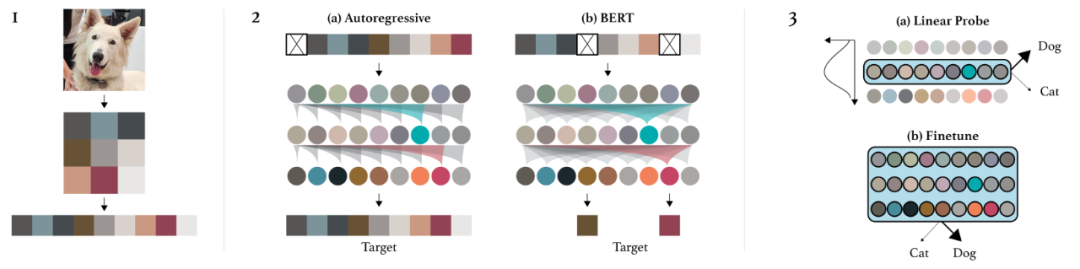 该论文表明:如果你能做出很棒的下一步预测器,那么就能收获很棒的无监督学习效果。这篇论文在图像领域证明了该论断。 简单来说,先将图片转换成像素序列,每个像素都有一个离散的密度值。要做的就是使用同样的 Transformer 来预测下一个像素。这不同于 BERT,就是预测下一个 token,因为这是最大化压缩的似然。 下面来看看结果: 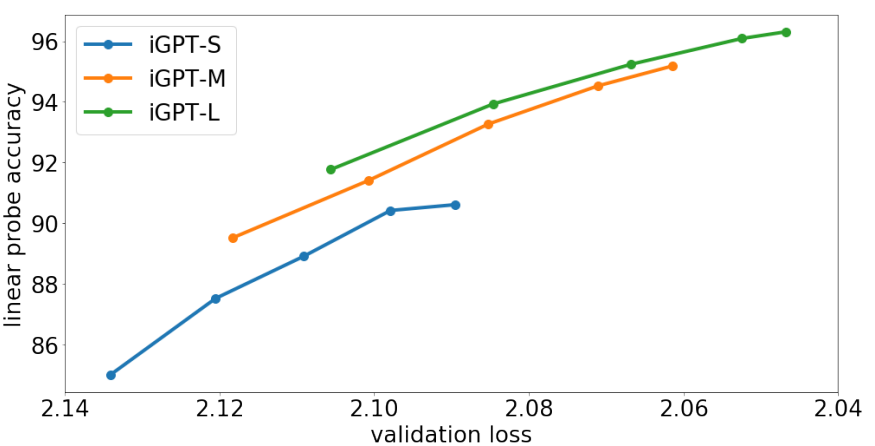 如图所示,这是不同大小的 iGPT 模型在 CIFAR-10 上的线性探查准确度,也就是在无监督学习的像素预测任务上的下一步预测准确度。可以看出,预测下一个像素就和预测下一个词一样有效。当模型规模更大时,无监督学习的效果也更好。 他们进行了实验研究,结果发现在 ImageNet 上,经过多方面扩展的 iGPT 的表现可以接近当今最佳的监督学习,但依然还有些差距。 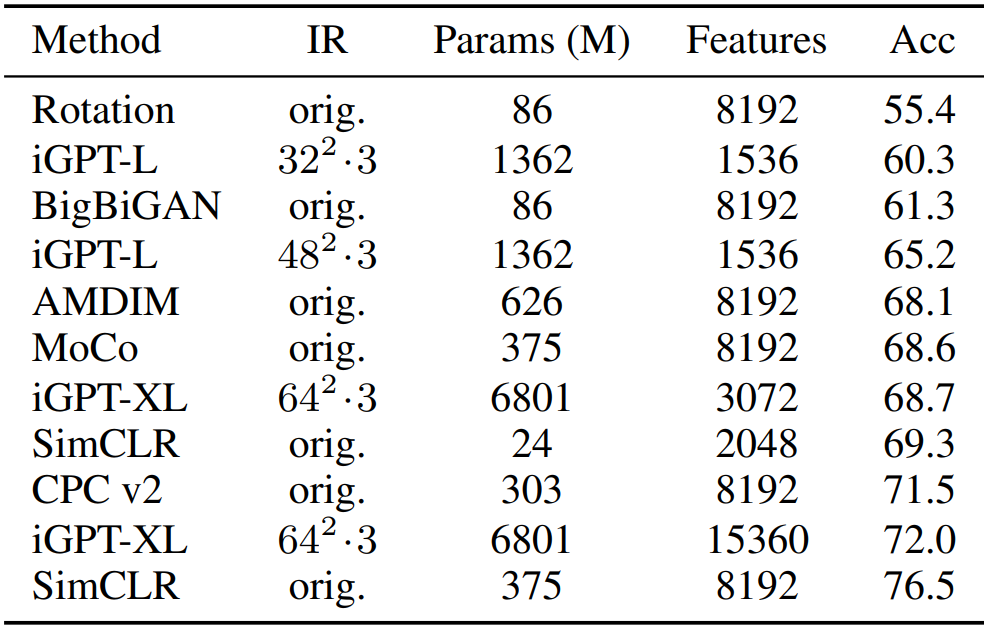 不过 Sutskever 认为这就是个计算问题,因为 SimCLR 等监督学习方式使用的是高分辨率的大图,他们为巨型 Transformer(68 亿参数)提供的是 64×64 的小图。这就像是基于一个大型数据集以无监督的方式预测下一个像素,然后在 ImageNet 上拟合线性探针,得到很好的结果。 而在 CIFAR-10 上,有 13.6 亿参数的 iGPT-L 取得了准确度 99% 的好成绩,如下图所示。 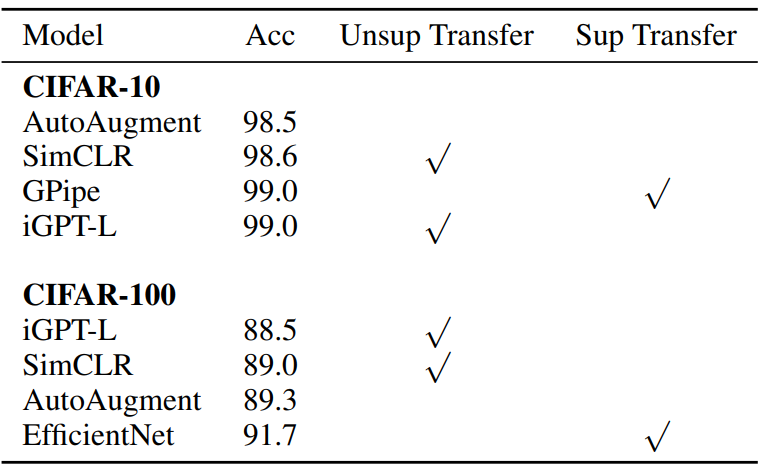 线性表征 线性表征演讲最后,Sutskever 表示他想谈谈线性表征。  他说:「我喜欢压缩理论,因为在此之前还没有以严格方式思考无监督学习的方法。」而现在我们能在一定程度上做到这一点了。但压缩理论不能直接解释为什么表征是线性可分的,也无法解释应该有线性探针。线性表征是无处不在的,它们形成的原因必定很深刻。Sutskever 相信我们能在未来清晰地阐释它。 他觉得另一个有趣的地方是自回归模型在线性表征方面的表现优于 BERT。但目前人们还不清楚其中的缘由。 不过 Sutskever 倒是给出了自己的推测:在根据之前所有的像素预测下一个像素时,模型需要观察数据的长程结构。BERT 在处理向量时会丢弃一些像素 token,通过兼顾地考虑一点过去和一点未来,模型实际上能得到相当好的预测结果。这样一来就去除了所有困难任务,任务的难度就下降了很多。预测下一个像素中最困难的预测任务比 BERT 预测情况中最困难的预测任务难多了。 |