玩币族移动版
玩币族移动版




超越GPU租赁,Prime Intellect如何让去中心化AI训练成为可能
时间:2024-08-15 来源:区块链网络 作者:区块律动BlockBeat
原文标题:《Prime Intellect: Making Magic to Scale AI Training》 原文作者:Teng Yan 原文编译:思维怪怪 译者注:随着英伟达市值在年中突破 3 万亿美元,GPU 算力租赁成为 2024 年加密 AI 领域最热门的赛道。然而,大多数项目仅停留在算力资源聚合阶段,未能解决去中心化 AI 训练的核心难题——跨分布式 GPU 集群的模型训练。新锐项目 Prime Intellect 正试图打破这一瓶颈。加密研究员 Teng Yan 撰文探讨了 Prime Intellect 的创新方案,以及它如何有望引领去中心化 AI 训练的未来。 大多数 GPU 市场平平无奇,往往只是重复相同的产品体验,仅通过添加一个代币来补贴成本。 但去中心化 AI 训练则是一个全新的游戏,具有变革性潜力。Prime Intellect 正在为大规模去中心化 AI 训练构建关键基础设施。 以下是他们超越普通 DePIN 项目的原因:
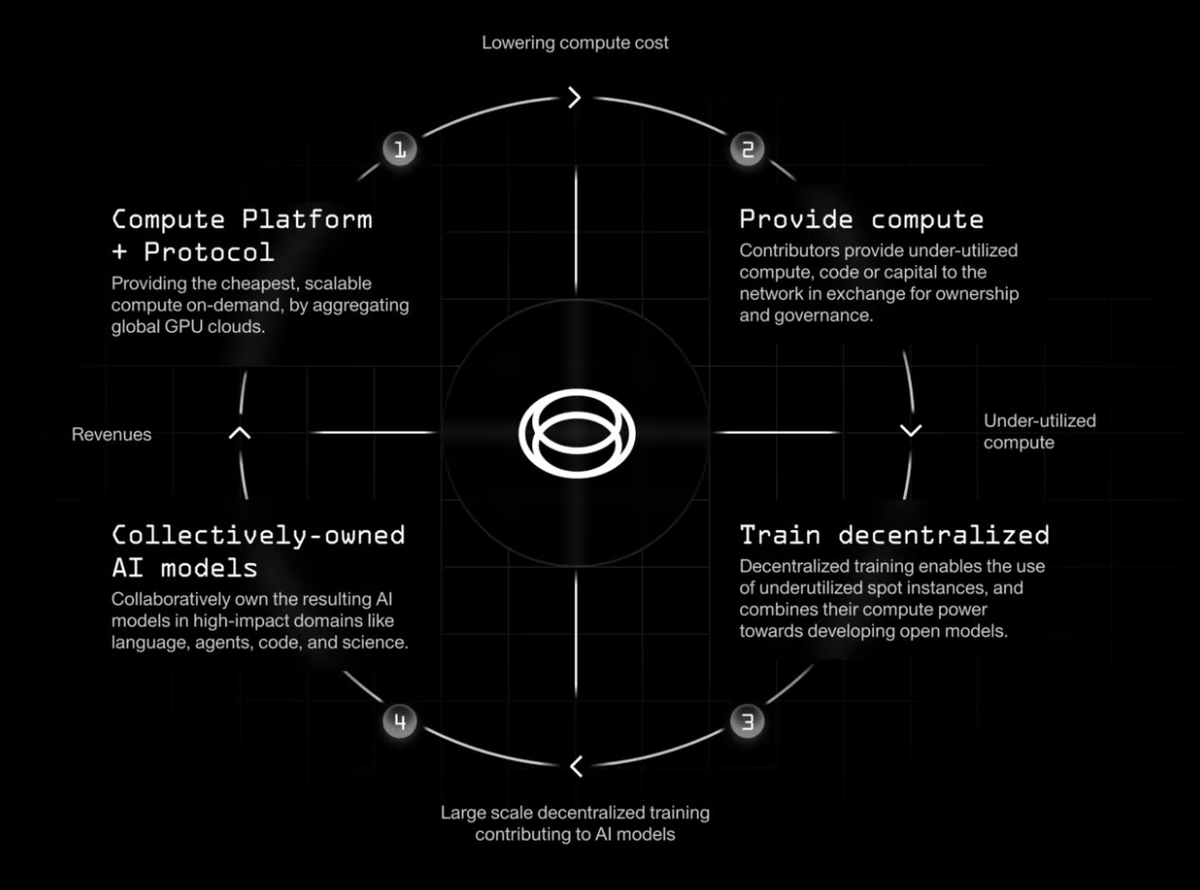
Prime Intellect 的宏伟蓝图包含四个部分: 1. 整合全球算力资源 2. 开发用于协作模型开发的分布式训练框架 3. 协作训练开源 AI 模型 4. 实现 AI 模型的集体所有权 GPU 市场聚合器 7 月 1 日,他们通过推出 GPU 市场启动了第一阶段。该市场整合了主要中心化和去中心化 GPU 供应商的算力资源,包括 Akash Network、io.net、Vast.ai、Lambda Cloud 等。目标是通过聚合供应商资源并提供便捷工具,为用户提供最优惠的租赁价格。用户可以直接使用 Prime Intellect 平台,无需再逐一访问 Akash 或 io.net 进行比价。
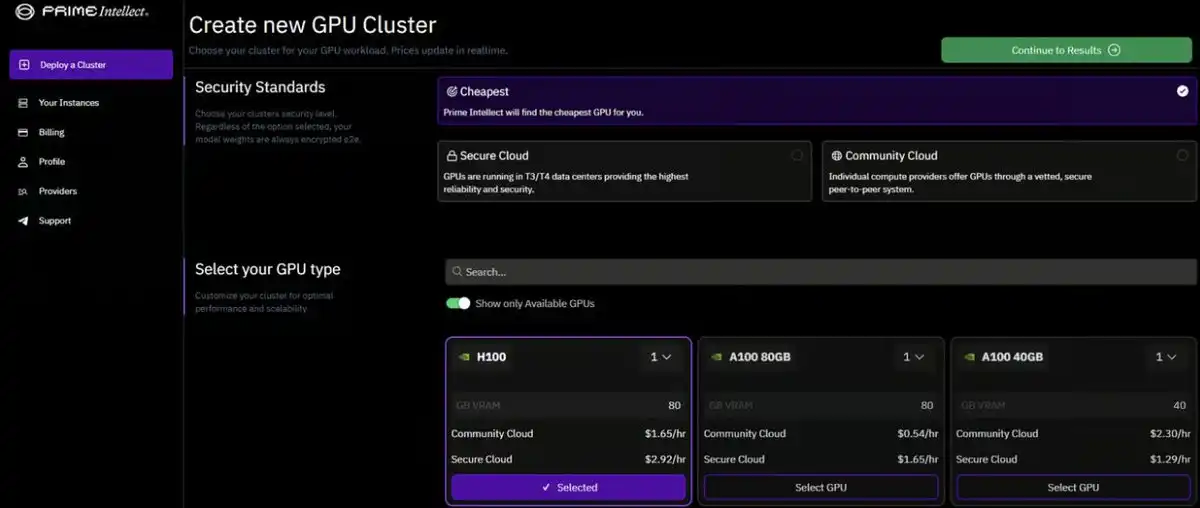
他们的在线测试平台直观且易于使用。用户几分钟内就能启动集群,无需 KYC。你可以选择希望租赁 GPU 的位置和网络的安全级别(如安全云或社区云),此外还有一个「最低价」选项。 从顶级 H100 到 RTX3000 和 4000 系列,他们提供多种 GPU 选择。目前集群规模上限为 8 个 GPU,Prime Intellect 正努力将其扩大到 16-128 个。 大规模去中心化训练 他们蓝图的第二部分——开发分布式 AI 训练框架,最令人瞩目。 目前的情况是:训练大型基础 AI 模型通常需要自建数据中心。这涉及高速网络、定制数据存储、隐私保护和效率优化,这些仅靠租用多个 GPU 难以实现。所以微软、谷歌和 OpenAI 等巨头主导了这一领域毫不奇怪,小型玩家缺乏必要的资源。 而 Prime Intellect 将实现跨多个分布式 GPU 集群的模型训练。 去中心化训练面临多重挑战: · 优化全球节点间的通信延迟和带宽 · 适应这些网络中不同类型的 GPU · 容错能力:训练过程必须能适应 GPU 集群可用性的变化,因为这些集群可能会随时加入或退出 这需要将前沿研究转化为实际生产系统:
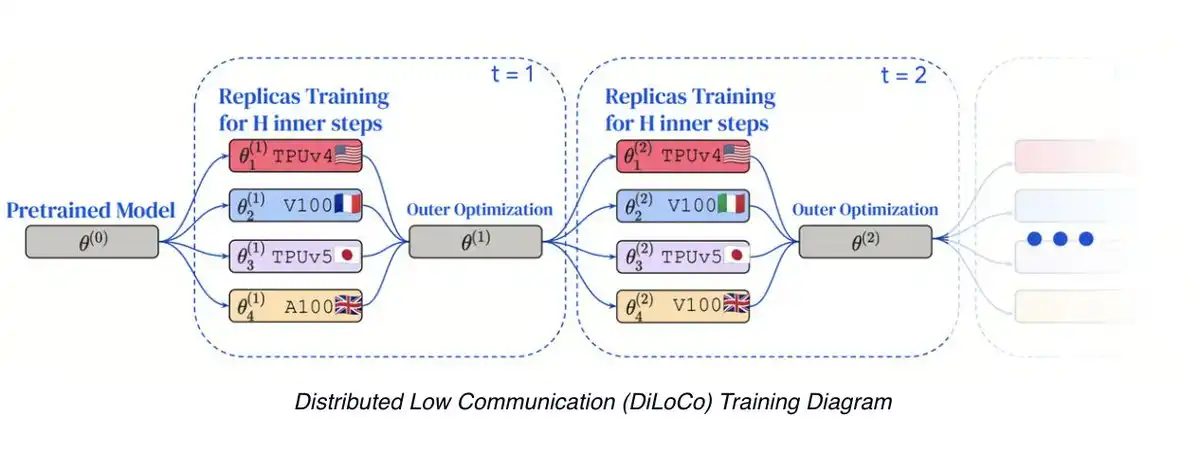
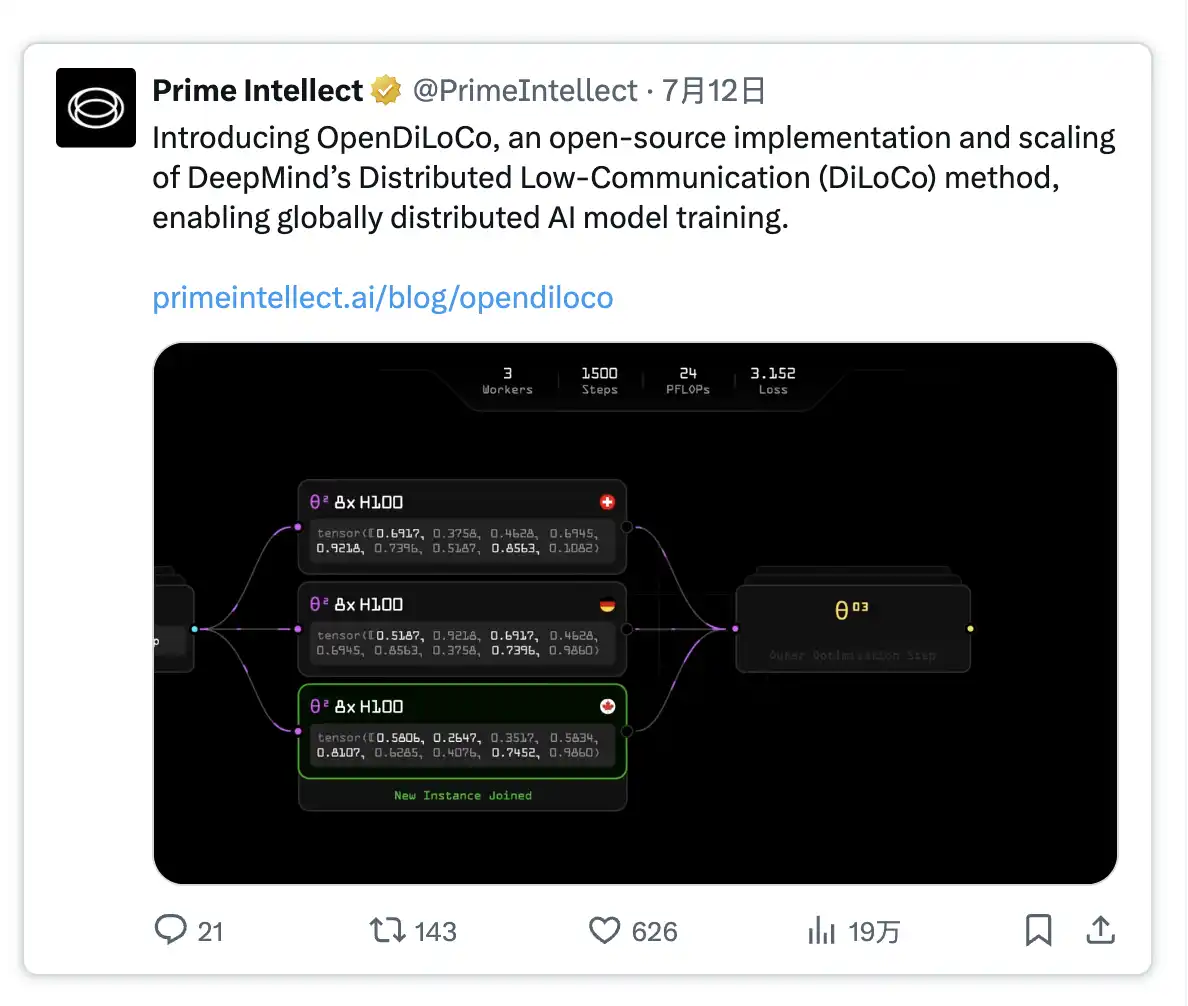
· 分布式低通信训练(DiLoCo):一种在连接不良的设备上进行数据并行训练的方法,每 500 步同步一次梯度,而非每步同步。 · Prime Intellect 最近开源了支持全球分布式 GPU 协作模型开发的框架,任何人都可使用该代码。 · 他们重现了谷歌 DeepMind 的 DiLoCo 实验,在横跨 3 国的情况下训练模型,计算利用率达 90-95%。他们还将规模扩大至原始工作的 3 倍,展示了其在十亿参数模型上的有效性。
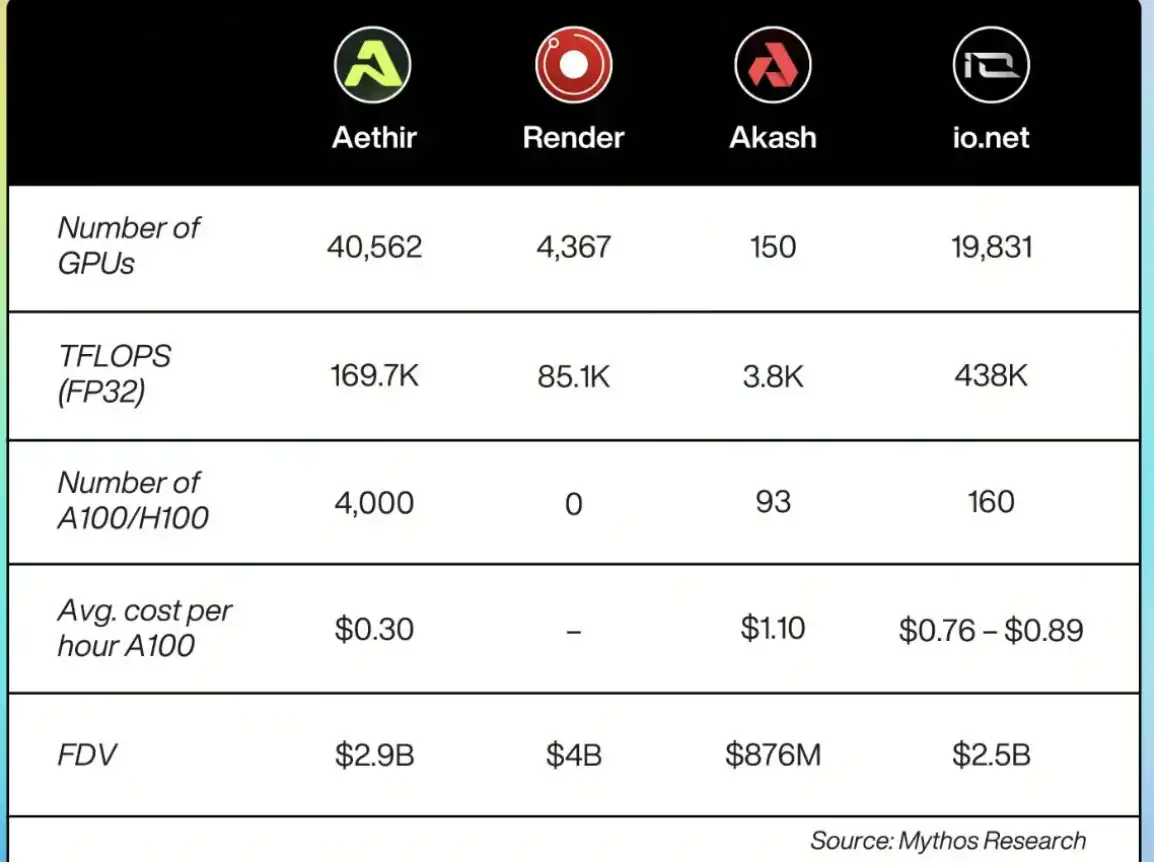
如果 Prime Intellect 能解决这些问题,将极大影响模型训练方式和资源利用效率。 Prime Intellect 正在开发的最后一项功能是一个协议,用于奖励贡献算力、代码和资金的参与者,并实现 AI 模型的集体治理。这契合去中心化 AI 理念,鼓励用户参与其中。预计他们可能会使用加密货币作为交易和所有权媒介。 我的看法 · 当前 GPU 市场同质化严重,缺乏吸引力。尽管一些市场通过代币激励聚集了供应,但由于去中心化训练的挑战,需求端仍然疲软。 · 全球去中心化 GPU 市场竞争激烈。(以下是几个 GPU 提供商的价格比较:)
· 如果 Prime Intellect 能提高去中心化 AI 训练的效率,将为 GPU 需求打开大门。 · Prime Intellect 拥有知名投资者支持,如 Clem Delangue(Hugging Face 联创兼 CEO)、Erik Voorhees(Shapeshift 创始人兼 CEO)和 Andrew Kang(Mechanism Capital 联创兼合伙人)。 |