


要点提炼 永久性分片链(persistent shard chain)的概念将不复存在,相反,每个分片区块都直接就是一个交联(crosslink)。提议人发出提案,交联(crosslink)委员会负责批准,一锤定音。分片数量从之前的 1024 减少到 64,分片区块大小从(目标值 16,上限值 64)kB增加到(目标值 128,上限值 512)kB。分片总容量为 1.3-2.7 MB/s,具体值取决于时隙(slot time)。如果需要的话,分片数量和区块大小可随时间的推移而增加,比方说 10 年后最终达到 1024 个分片,以及 1 MB 区块。在 L1 和 L2 层实施了诸多简化方案:(i)所需的分片链逻辑更少,(ii)因为 “原生的” 跨分片通信可以在 1 个时隙内完成,所以无需通过 Layer-2 为跨分片通信加速,(iii)无需通过去中心化交易所来促进跨分片交易费手续的支付,(iv)执行环境能够进一步简化,(v)无需再混合序列化和哈希;主要劣势:(i)信标链的开销更大,(ii)分片区块产生时间更长,(iii)对 “突增性” 带宽需求更高,但对 “平均” 带宽的需求更低。 序言/理念 当前的以太坊 2.0 架构过于复杂,尤其是在手续费市场层面,有些人就想到要用 Layer-2 的应变方法来解决 Eth2 基础层的主要问题:虽然分片内的区块时间是非常短的(3-6s),然而分片间的基础层通信时间特别长,需要 1-16 个 epoch(如果超过 1/3 的验证者离线,则要花费更长时间)。这就亟待 “乐观” 的解决方案:一个分片内的子系统通过某种次等安全的机制(如轻客户端),“假装” 提前知道其它分片的状态根,并使用这些不确定的状态根来处理交易,以此来计算自己的状态。一段时间后,一个 “rear-guard” 进程遍历所有分片、检查哪些计算使用了其他分片状态的 “正确” 信息,并抛弃未使用 “正确” 信息的所有计算。 但这个过程是存在问题的,虽然它在很多情况下都能够有效地模拟出超高速通信时间,但是 “乐观” ETH 和 “真实” ETH 之间的区别衍生出了其他复杂情况。具体而言,我们不能假设区块提议者 “知道” 乐观的 ETH(译者注:即完全知晓乐观 ETH 的确定状态),因此,如果分片 A 上的用户向分片 B 上的用户发送 ETH,则分片 B 上的用户要隔一段时间才能收到协议层 ETH(也是唯一能用于支付交易手续费的 ETH)。如果想避免延迟,要么需要去中心化交易所(存在复杂性和低效率问题),要么需要中继市场(又使人担心垄断中继者可能会审查用户的交易)。 此外,目前的交联(crosslink)机制大大增加了复杂性,实际上它需要一整套区块链逻辑,包括奖惩计算、单独存储分片内奖励的状态以及分叉选择规则等,这些都需要被纳入分片链中作为阶段1的组成部分。本文档提出了一个大胆的替代方案,用以解决所有这些问题,使以太坊 2.0 能够更快地投入使用,同时降低风险,其中还有一些折中方案。 方案细节 我们把?SHARD_COUNT?(分片数量)从 1024 减少到 64,并将每个时隙处理的分片数上限从 16 增加到 64。这意味着现在的 “最优” 工作流是:在每一次信标链生成区块的期间,每个分片都会产生一个交联(为了清楚起见,我们不再使用 “交联”(crosslink)一词,因为并没有 “连接” 到分片链,直接使用 “分片区块” 更合适)。
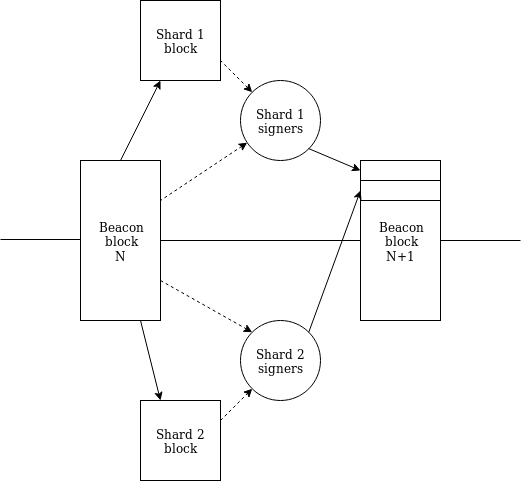
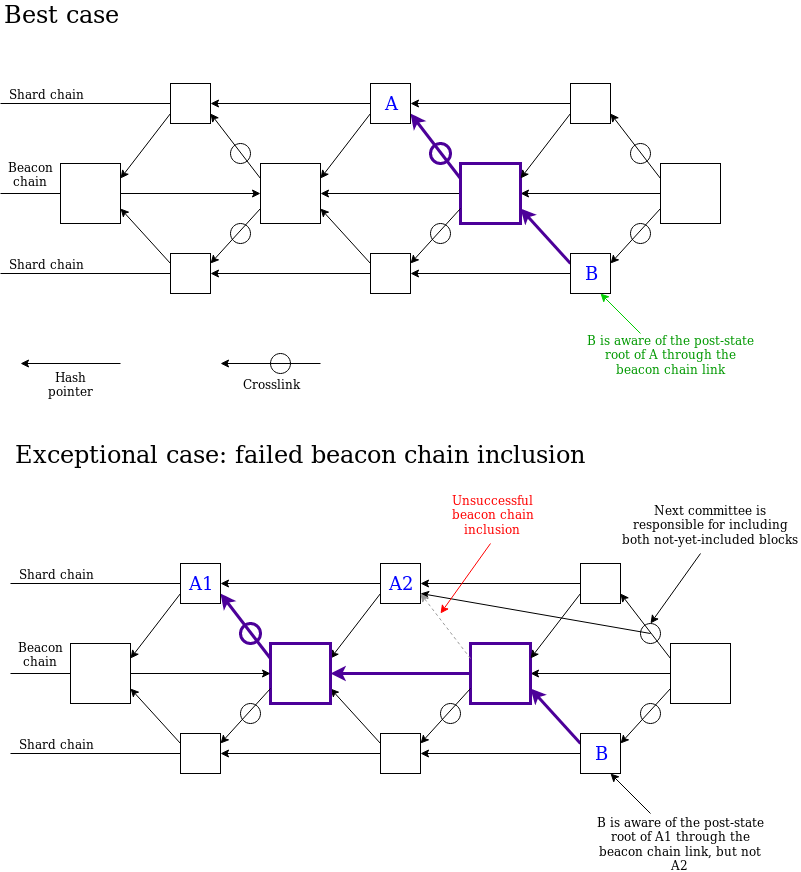
请注意一个关键细节:现在任何分片位于时隙 N+1 处的区块都可以通过一条路径知道所有分片的在时隙 N 处的区块。因此,我们现在有了一流的单时隙跨分片通信(通过 Merkle 收据)。
-现状(近似)-
-新提案- 在这个提议中我们改变了见证消息(attestation)所连接对象的结构:在原先的方案中,见证消息中包含着 “交联”(crosslink),交联中包含着以某种复杂序列化形式表示的许多分片区块的 “数据根”;但在新提案中,见证消息只包含着一个数据根,该数据根代表着一个区块内的内容(内容完全由“提议者”决定)。分片区块还将包括来自提议者的签名。为了促进 p2p 网络的稳定性,计算提议者的方式依然使用之前基于常设委员会的算法(persistent-committee-based algorithm)。如果没有可用提案,交联委员会成员也可以就 “零提案” 进行投票。 我们依然在状态中存储一个映射?latest_shard_blocks: shard -> (block_hash, slot)?,不同的是参数由 epoch 变为时隙。在理想状况下,我们希望每个时隙这个映射都能够得到更新。 将?online_validators?定义为活跃验证者的子集,活跃验证者即在过去 8 个时段(epoch)中至少有一个 epoch 包含其见证消息。只有 2/3 的?online_validators?(以总余额计算比例)都对给定分片的同一个新区块达成共识,上述映射才会进行更新。 假设当前时隙是?n?,但对于给定分片?i,latest_shard_blocks.slot < n-1(即在前一个时隙中该分片有一个区块被跳过),我们则需要对该分片的见证消息来提供范围?[latest_shard_blocks.slot + 1….min(latest_shard_blocks.slot + 8, n-1)]?内所有时隙的数据根。
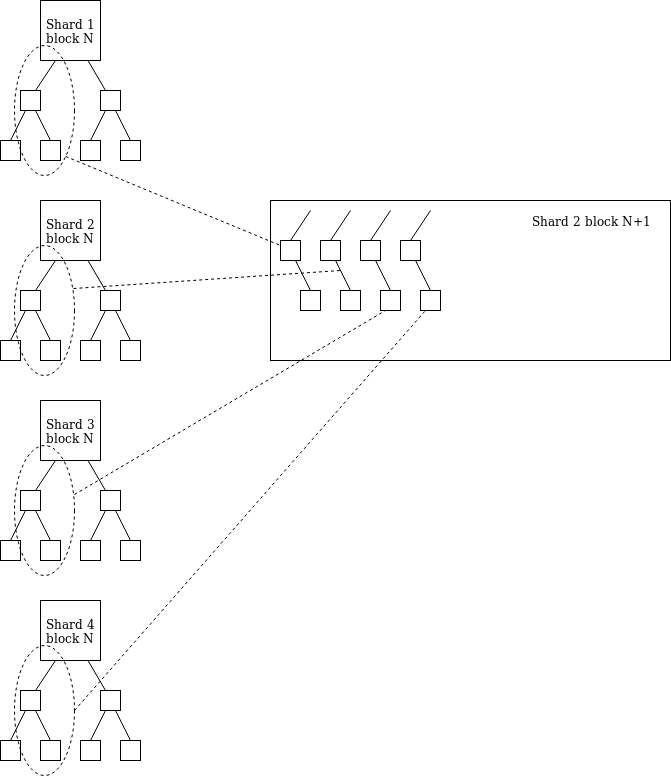
分片区块仍需指向 “先前的分片区块”,我们还是要强制保证一致性,因此该协议就要求多时隙的见证消息来保证一致性。委员会采用以下“分叉选择规则”: 对于每个有效且可用的分片区块 B(该区块的祖先区块也必须有效且可用),计算其最新消息支持 B 或 B 的后代的验证者总权重,暂且将该权重称为分片区块 B 的 “得分”。即使是空白的分片区块也可以有得分。在?latest_shard_blocks[i].slot + 1?处根据最高得分选出相应区块在?latest_shard_blocks[i].slot + k?(k > 1)处选择区块时,也根据最高得分来选,但仅考虑其父块已在?latest_shard_blocks[i].slot + (k-1)?处被选择的区块 概述 从信标区块 N 到信标区块 N+1 的发布过程如下: 信标区块 N 发布;对于任何给定的分片 i,分片 i 的提议者提议一个分片区块。该区块的执行过程可知信标区块 N 和先前区块的根(如果有需要,我们可以将可见性降到区块 N-1 和旧区块,这使得我们可以对信标区块和分片区块同时进行提议);被分配到分片 i 的见证者提交见证消息,包括其对时隙 N 处的信标区块和分片 i 区块的意见(在特殊情况中也包括分片 i 中先前的分片区块);信标区块 N+1 发布,其中包括对所有分片的见证消息。区块 N+1 的状态转换函数对这些见证消息进行处理,并且更新所有分片的 “最新状态”。 成本分析 请注意,参与者不需要随时主动下载分片区块数据。相反地,提议者发布提议时,只需要在 3 秒内上传上限为 512 kB 的数据(假设有 400 万个验证者,每个提议者平均 12.8 万个时隙才需要上传一次),随后委员会验证提议时,只需要在 3 秒内下载上限为 512 kB 的数据(要求是每个验证者要在每个 epoch 中下载一次数据,因为我们保留了一个属性:在任意给定时段中, 每个验证者都会在特定时隙中被分配到一个特定的交联)。 请注意,此操作的要求低于目前每个验证者的长期负载要求,即每个 epoch 约 2MB。然而,这对 “突增性” 负载的要求更高:之前是 3 秒内上限 64KB,现在 3 秒内上限会提高到 512KB。 见证消息(attestations)负载的信标链数据更改如下。 每条见证消息有 224 字节的基本开销(其中 128 字节是 AttestationData,96 字节是签名数据),再加上见证者字段(attester bitfield)需要少则 32 字节(正常情况),多则 256 字节(最糟糕的情况)的数据。也就是说,一条见证消息需要 256-280 字节的开销。一个区块最多可以有 256 条见证消息,平均则是约 128 条(猜测),所以单个区块的消息开销在平均条件下是 32768 字节(约 0.03 MB),最糟糕的情况下是 122880 字节(约 0.1 MB)。每个分片状态更新消息需要:(i)区块体 chunk 数据根,每 128 kB 的区块数据(或其一部分)就需要一个数据根,所以平均需要 48 字节,最大需要 128 字节;(ii)分片状态根,128 字节;(iii)区块体长度,8 字节;(iv)custody bits,少则 32 字节,多则 256 字节。因此,平均来看需要 216 字节,最大需要 520 字节。单个区块最多可以有 256 条分片状态更新消息,平均是 64 条。因此平均需要 13824 字节(约 0.01 MB),最大需要 133120 字节(约 0.1 MB)。 每个证明有大约300字节的固定数据,加上一个位字段,即每个epoch 400万bit,每个时隙8192字节。因此,目前方案的最大负载为128 * 300 + 8192 = 46592,平均情况中的负载可能更接近32 * 300 + 8192 = 17792,即使这样还可以通过压缩证明中的冗余信息来降低负载。 出于效率考量,在一个区块中我们仅包含胜出见证消息(winning attestation)中的分片状态更新数据;对所有其它见证消息中的分片状态更新数据都仅保存其哈希值作为替代。这样就可以大幅节省数据开销。 还要注意的是,见证聚合在每个分片中每个时隙的成本为 65536 * 300 / 64 = 307200 字节。这对运行节点提出了一个天然的系统需求门槛,因此要再压缩区块数据的话也没有什么意义。 从计算层面来说,唯一大幅增加的花销是需要更多的配对(更确切地说,是更多的 Miller循环),每个区块的上限从 128 增加到 192,而这将使得区块处理时间延长 200ms。 “基础操作系统” 分片 每个分片都有一个状态,就是一个?ExecEnvID -> (state_hash, balance)?的映射。一个分片区块被分成一组 chunk,每个 chunk 指定一个执行环境。一个 chunk 的执行依靠状态根和 chunk 的内容(即分片区块数据的一部分)作为输入,并输出?[shard, EE_id, value, msg_hash]?元组的一个列表,每个分片最多拥有一个?EE_id( 我们添加两个 “虚拟” 分片:向分片 -1 的转账表示验证者在向信标链存储保证金,而向分片 -2 的转账是向提议支付手续费)。我们也会从该 EE 的余额中减去 value 的总数。 在分片区块头里,我们放置了一个 “收据根(receipt root)”,里面包含了一个映射:?shard-> [[EE_id, value, msg_hash]…]?(每个分片最多8 个 元素;在一个大多数大多数跨分片 EE 转账都是发往同一个 EE 的的转账中,甚至只需要更少元素)。 在分片 i 上的一个分片区块,应有一个默克尔分支,包含所有其它分片的收据,而这棵默克尔分支就是由其它分片的收据根生成的(因此任意分片 i 都可以知道其它任意分片 j 的收据根)。收到的价值会被分配到其 EE,且 EE 可以访问?msg_has?。
这就使得不同的分片可以在 EE 间实现即时的 ETH 转移,此时每个区块的开销为 (32 * log(64) + 48) * 64 = 15360 字节。msg_hash?可以被用于减少伴随 ETH 转移所传递的跨分片信息见证内容的大小,因此在一个高度活跃的系统里,15360 字节数据是必不可少的。 主要益处:更简单的费用市场 我们可以接着修改执行环境(EE)系统:每个分片都有一个状态,该状态包含状态根和执行环境的余额。执行环境将能够发送收据,向其它分片的同一 EE 直接发送货币。这个过程将使用默克尔分支处理机制来完成,每个分片的 EE 状态储存着一个其余每个分片的 nonce,用以抵御重放(replay)攻击。EE 也可以用来直接向区块提交者支付费用。 这提供了足够强大的功能性,使得 EE 能够建立在这样的基础之上:允许用户在分片上存币,并将其用于支付交易手续费;在分片间转移币就如在同一分片内进行操作一样简便,从而消除了对中继市场需求的紧迫性,也不需要让 EE 来承担实现 optimistic 跨分片状态的负担。 完全的和压缩后的见证消息 出于对效率问题的考量,我们还进行了以下的优化。如前所述,指向时隙 n 的见证消息可完整地包含在时隙 n+1 中。但是,如果此种见证消息需要被包含在后续的时隙中,则必须以 “精简形式” 进行嵌套,仅包含信标区块(头部、target、source),而不包含任何交联数据。 这不仅起到了裁减数据的效用,更重要的是,通过强制 “旧见证消息” 保存相同数据,可以减少用于验证见证消息所需的配对数:在大多数情况下,所有来自相同时隙的旧见证消息都可以经由单一配对验证。如果链不分叉,那么在最坏的情况下,用以验证旧见证消息所需的配对数会被限制在 epoch 长度的 2 倍。如果链确实分叉,则要包含所有见证消息的能力就得依赖于一个更高的诚实提议者比例(譬如 1/32,而非 1/64),并且要将更早的证明也包含进去。 保证轻客户端的参与 每天,我们随机选择一个由大约 256 个验证者组成的委员会,这个委员会可以在每个区块上进行签名,其中签名被包含的验证者便可以在区块 n+1 中获得奖励。这样做的目的是允许计算能力不高的轻客户端参与。 题外话:数据可用性根 证明一个 128 kB 数据的可用性的操作是多余的,几乎没有价值。与此相反,有意义的是:要求一个区块能够提供该区块接受并组合在一起的所有分片区块数据的串联根(也许这个分片区块数据根以列表形式存在,其中每个根代表 64 kB 数据,这样使得串联更容易)。 然后可以根据此数据创建单个数据可用性根(平均 8 MB,最坏情况下达到 32 MB)。 请注意,创建这些根可能要花费比一个时隙更长的时间,因此,最好用于检查一个 epoch 前的数据的可用性(即,从这些数据可用性根中进行采样将是额外的“确定性检查”)。 其他可能方案 时隙 n 的分片区块必须引用时隙 n-1的信标链区块,而不是时隙 n 处的信标链区块。此种措施将允许以时隙为单位的循环并行发生,而不是串联发生,从而减少时隙时间,这样做的代价是导致跨分片通信时间从 1 个时隙上升到 2 个时隙。如果一个区块提议者试图将区块大小扩大到 64KB 以上(备注:目标128kB),他需要首先生成 64kB 的数据,然后让交联委员会对其进行签名,接着,他们可以添加一个引用第一个签名的 64kB 数据,以此类推。这将鼓励区块创建者每隔几秒提交他们区块的部分完成版本,从而创建一种预先确认的机制。加快秘密领导人选举的发展(简单起见,即使一个约 8 到 16 人的匿名集环签名版本也能有所作用)。与其使用 “强制嵌入” 机制,我们不如寻求一个更简单的替代方案:每个分片为其余的每个分片维护一个 “inbound nonce” 和一个 “outbound nonce”(即 8 * 64 * 2 = 1024 字节的状态),一个分片制造的收据将需要手动进行添加,并由接收的分片按顺序进行处理。收据生成将受限于每个区块每个目标分片的少数收据,以确保一个分片能够处理所有传入的收据,即使是所有分片同时向它分送收据。 原文链接:?https://notes.ethereum.org/@vbuterin/HkiULaluS?from=groupmessage&isappinstalled=0 作者:?Vitalik 本文由?ECN 以太坊中国?社区翻译,EthFans 经授权使用译本。再出版时,根据原文的改动更新了译本。 —- 编译者/作者:以太坊爱好者 玩币族申明:玩币族作为开放的资讯翻译/分享平台,所提供的所有资讯仅代表作者个人观点,与玩币族平台立场无关,且不构成任何投资理财建议。文章版权归原作者所有。 |
干货 | Vitalik:Eth2 分片链简化提案
2019-10-31 以太坊爱好者 来源:区块链网络


相关阅读:
- 意见:DeFi协议的高收益威胁以太坊2.0权益2020-10-28
- 币姥爷:再传以太坊2.0下月启动2020-10-27
- 以太坊2.0即将到来,长线可期,但年底的2.0其实是个“砖头”,波卡和2020-10-25
- Danny Ryan表示,以太坊2.0存款合同“仍迫在眉睫”2020-10-22
- 以太坊2.0将会给ETH带来新的上涨机会,Filecoin创始人回应罢工事件,主要2020-10-21

