


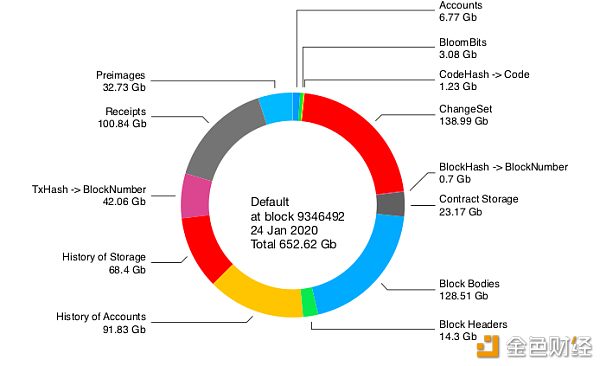
几个月以前,我加入了 Turbo-Geth 团队,开始主动给 Trubo-Geth 客户端贡献代码。Turbo-Geth 客户端是 Geth 客户端的一个另类版本(当前仍在开发),其目标是做得比原有的客户端运行速度更快、更高效。那么 Turbo-Geth 实现这个目标的办法包括下面几项: 进一步优化数据库结构 在需要与状态数据交互的场合,减少对数据库的读、写操作 优化状态树操作的效率(有可能需要改变现有状态树的数据结构) 在本文中,我会着重指出 Turbo-Geth 和 Geth 在数据库上的不同之处。主要的区别在于: 不同的数据库(使用 Bolt,而非 LevelDB) 按桶(bucket)来细分数据库 那么,本文的主要内容也就跟这两点相关。 什么是 Bolt,它跟 LevelDB 的区别在哪里? Bolt 和 LevelDB 其实非常相似,两者都是 “键-值对”(key-value)存储,设计目标都是为不需要完整数据库服务器的项目提供简单、快捷且可靠的数据库。Geth 选用的数据库是 LevelDB,而 Turbo-Geth 选用的是 Bolt。 但两者也有一个关键区别:组织数据的方式。LevelDB 是一个 LSM (Log-Structured Merged-Tree)数据库,而 Bolt 使用 bucket,而且每一个 bucket 都包含着一个 B+- Tree 结构。我们可以把一个 bucket 当作 “大数据库里的一个小数据库”。 那么,两者之间的主要区别在于:LSM 数据库是为重度添加操作(appending)和范围扫描操作(range scanning)优化的,而不是为随机读取的性能优化的;为了提供一致性,它不允许同时对数据库执行读、写操作。也是出于性能考虑,这种数据库是没有实现原子性的。Bolt 则反之,插入操作(inserting)速度较慢,但是随机读取速度较快,实现了原子性,而且可以同时对数据库读写。 我们再稍微解释一下原子性: 原子性:“原子” 意味着不可分割。假设现在我们要给一个数据库存储多个哈希值,而其中一个在插入数据库时失败了,如果此时所有哈希值的操作都会同时撤销,这就叫做原子性。Turbo-Geth 就有这样的特性,只有所有哈希值的插入操作都成功时,这个操作才能成功。而没有实现原子性的数据库(比如 LevelDB)则意味着,必须使用一个 workaround 以安全地将数据插入数据库。换句话来说,在这个点上,我们觉得 Bolt 更好,因为他在给数据库添加数据时更安全。 数据库的组织 如前所述,Turbo-Geth 是切分成多个 bucket 的。每个 bucket 都是大数据库中的一个小数据,各自包含了一个 B+-Tree 结构。 下面便是 Turbo-Geth 数据库在区块高度 9,346,492 处的切分:
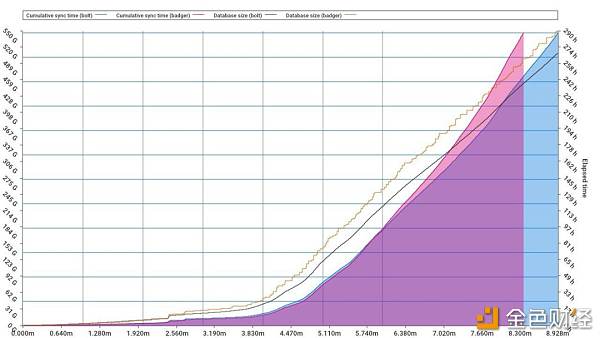
- Turbo-Geth 的 Archive 节点的数据区分(区块高度为 9,346,492)- Geth 客户端的 Archive 大小(区块高度 9346492): 3.7 TBParity 客户端的 Archive 大小(区块高度 9346492): 3.6 TBTurbo-Geth 客户端的 Archive 大小(区块高度 9346492): 652.62 GB 每一个部分都存储在一个 bucket 里面。其中主要部分的简要解释如下: 原象(preimage):哈希值与地址之间的管理,以及存储位置哈希值与存储位置之间的关联 收据(receipt):交易收据 合约存储内容的历史(History of Storage):合约存储内容的变更历史 账户历史(History of Accounts):账户的变更历史 区块头:每个区块的区块头 区块体:每个区块的区块体 合约存储内容(Contract Storage):就是合约存储内容 ChangeSet:数据库变更历史 账户:账户 使用这么多 bucket ,是为了让构成大数据库的各 B+-Tree 树高不至于太高,这样跟数据库的交互就会比较容易。换句话说,这是在使用多个 bucket 来提高读取数据库的性能。 另一种备选方案:Badger DB 在切换到 Bolt 之后,Turbo-Geth 在处理随机键(比如交易哈希值)时遇到了一些问题,因为 Bolt 会在提交数据之前对这些键进行排序(sort),又因为这些哈希值都是随机的,而且数量很多,所以产生了大量的排序需求,然后导致大量的写入放大现象(write amplification,实际写入的物理数据量是写入数据量的多倍)。而 BadgerDB 使用 log-structured-merge(LSM)模式,似乎是一个更好的选择。这个问题仍在研究当中,不过,我们已经实现了一个 workaround 来解决这个问题。 这里有一个图表,显示了 BadgerDB 和 BoltDB 在整体性能上的对比(感谢 Alexey Akhunov 制图):
结语 Turbo-Geth 客户端通过下列(数据库)手段来优化以太坊的性能: 使用多个 bucket,以更迅速地检索某些数据片 使用 B+-Tree 而非 LSM 如果你想给我们捐赠,可以通过 Gitcoin。 —- 编译者/作者:以太坊爱好者 玩币族申明:玩币族作为开放的资讯翻译/分享平台,所提供的所有资讯仅代表作者个人观点,与玩币族平台立场无关,且不构成任何投资理财建议。文章版权归原作者所有。 |
引介:Turbo-Geth客户端:数据库改进
2020-02-27 以太坊爱好者 来源:区块链网络
- 上一篇:比特币技术分析:空头有控制权
- 下一篇:香港和阿布扎比更改密码规定以符合FATF
相关阅读:
- 基于区块链的金融科技希望成为联盟的B32020-11-02
- Celo为开发人员,社区和初创公司启动了Wave III赠款2020-11-01
- Verizon在新闻发布中采用了区块链技术2020-11-01
- Coinfirm集成Chainlink甲骨文与DeFi部门的洗钱斗争2020-11-01
- 矿工拒绝“强捐”,BCH又要分叉了2020-11-01

