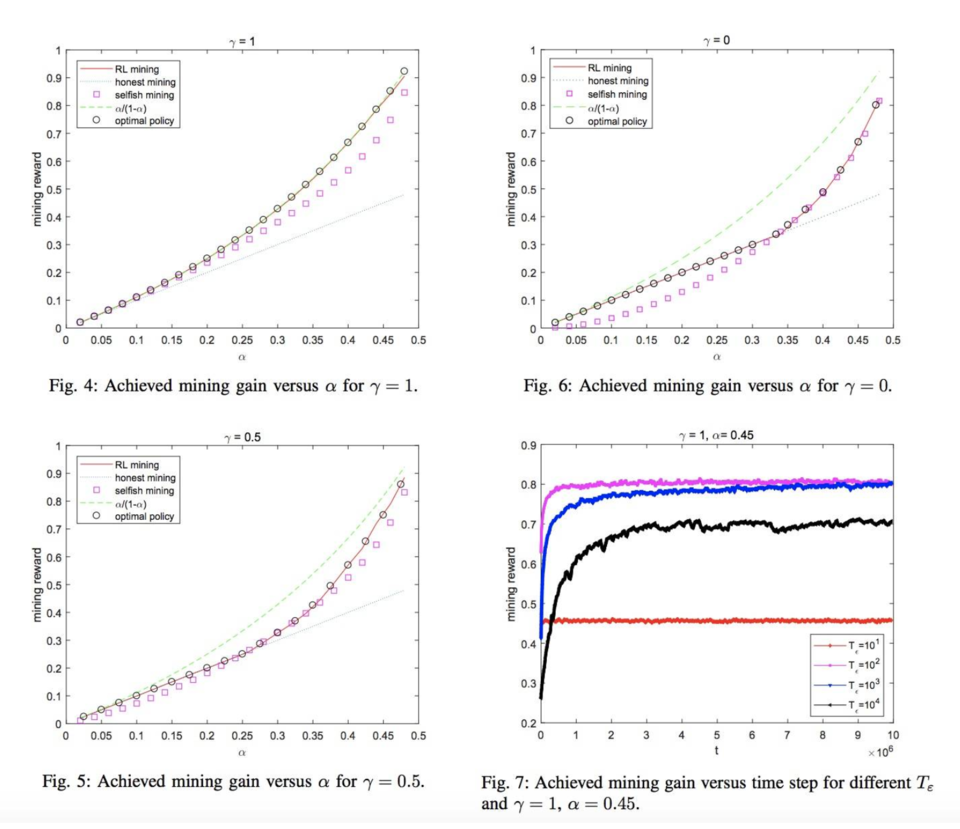
节选自《洒脱喜一周评丨 AI 算法跨界参与比特币挖矿?以太坊成功完成伊斯坦布尔升级》 我们知道,激励机制是无许可区块链(公链)的核心:它们激励参与者运行和保护基础共识协议。 然而,设计与激励相容的激励机制,实际上是非常具有挑战性的。具体而言,用户要么是拜占庭式的,要么是诚实的,而具有强大理论安全保证的系统,也常常会排除对理性用户的分析,而他们可能会因为激励而偏离诚实行为。 因此,如今大多数公链所使用的激励机制,它们的安全属性并非是绝对的,而且很多都未经过考验。 矿工们投入计算资源来解决 PoW 问题,在早期的时候,人们认为最有利可图的挖矿策略就是诚实挖矿,其中矿工一旦解决了 PoW 问题,其就会尽快广播这个新生成的区块。 后来,在 13 年的时候,康奈尔大学的 Emin Gün Sirer 教授和 Ittay Eyal 助理教授提出了一种称为自私挖矿(selfish mining)的挖矿策略,这种策略在一定条件下可以实现比诚实挖矿更高的回报。此后,关于激励攻击的研究如雨后春笋般涌现出来。 采用自私挖矿的矿工不会立即广播其挖得的区块,其通过秘密地将其未来挖得的区块与其扣留的区块连接起来,然后实施一次扣块攻击。 到了 2015 年,微软研究院以及以色列耶路撒冷希伯来大学的研究者 Ayelet Sapirshtein 等人将挖矿问题描述为具有大状态行为空间的一般马尔可夫决策过程(MDP),然而,挖矿 MDP 的目标并不像标准 MDP 那样是奖励的线性函数,因此,无法使用标准 MDP 解码算法解决挖矿 MDP。为了解决这个问题,研究者首先将具有非线性目标的挖矿 MDP 转化为具有线性目标的 MDP,然后在这个 MDP 上使用标准的 MDP 解码算法来寻找最优的挖掘策略。 而这种方法,在建立 MDP 之前,必须要知道各种参数值,而在真实的区块链网络中,精确的参数值是很难获得的,并且可能随着时间的推移而改变,从而阻碍了这种解决方案的实际采用。 论文 1: 《当区块链遇到 AI:基于机器学习的最优挖矿策略》 而香港中文大学教授、IEEE FELLOW (院士)刘绍强,深圳大学助理教授、博士后王滔滔以及深圳大学教授、博导张胜利则在最近提出了一篇新的研究论文。 论文链接:https://arxiv.org/pdf/1911.12942.pdf 在这篇名为《当区块链遇到 AI:基于机器学习的最优挖矿策略》的论文中,研究者使用到了强化学习(RL)算法,通过观察和与网络交互,动态学习一个性能接近最优挖矿策略的挖矿方式。 强化学习(RL)算法是一种机器学习范式,在这种范式中,代理学习成功的策略,并从与环境的反复试验中获得最大的长期回报。 目前,Q-learning 是最流行的强化学习(RL)算法,它可以通过更新一个状态动作值函数来学习一个好的策略,而不需要环境的操作模型,强化学习(RL)算法已成功地应用于许多具有挑战性的任务中,例如玩电子游戏、围棋以及控制机器人的运动。 但是,原有的强化学习(RL)算法并不能处理挖矿问题的非线性目标函数。 因此,论文作者们提出了一种新的基于 Q-learning 的多维 RL 算法,而这种算法能够成功地找到最优挖矿策略。
经过模拟实验显示,通过这种强化学习(RL)算法的挖矿方式,要比传统的自私挖矿以及诚实挖矿更有利可图。 洒脱喜简评:这又是跨学科研究的最新例子,它也提醒了加密货币世界的原住民,新技术的发展也会引发新的问题,那我们是否要因此而过于担心呢?不急,我们先看下一份研究论文。 论文 2 :《SquirRL: 运用深度强化学习技术实现区块链激励攻击的自动发现》 来自美国卡耐基梅隆大学、北京大学、康奈尔理工学院、斯坦福大学的多位研究者于近日发表了一篇题为《SquirRL: 运用深度强化学习技术实现区块链激励攻击的自动发现》的论文。 论文链接:https://arxiv.org/pdf/1912.01798.pdf 标题似乎有点拗口,大致意思就是:使用深度强化学习(Deep-RL)算法,实现对区块链激励攻击的自动化发现。 在上一篇论文中,我们提到了强化学习(RL)算法,那深度强化学习(Deep-RL)算法又是什么呢? 深度强化学习是一类使用神经网络学习策略的强化学习(RL)算法。 而深度强化学习(Deep-RL)算法在解决具有以下两个性质的问题上是特别成功的: 规则定义良好;状态空间极大(难以控制)。而区块链激励机制,就符合上面的性质,实际上,区块链激励机制问题还有一个额外的优势,那就是区块链奖励是连续处理的。 论文作者:Charlie Hou、Mingxun Zhou、Yan Ji、Phil Daian、Florian Tramèr、Giulia Fanti、Ari Juels 实验的一些细节 研究者使用其提出的 SquirRL 框架,对比特币、以太坊以及 GHOST 的区块链激励机制进行了实验比较,他们对每个区块链协议分别进行了 100 次试验,其中每个试验包含 10000 次状态转换以及主链中至少 5000 个区块,然后又分为单个代理和多个代理进行评估。 下面是该实验涉及的 4 个组成部分: 诚实挖矿(Honest):遵守协议的矿工;最优自私挖矿(OSM);SM1:Emin G¨un Sirer 教授提出的自私挖矿策略;RL:也就是研究者提出的 SquirRL 系统;下面是单个代理的实验结果可视化图形:
我们可以看到,当攻击者持有的算力(或权益)α小于 25% 时,SquirRL 并不是采取“自私挖矿”策略,而是 recover 诚实挖矿策略,而在攻击者算力(或权益)α大于 25% 时,SquirRL 都胜过了其他方案。 最后,SquirRL 得出的结果表明,针对比特币的经典自私挖掘攻击,会在多个攻击者存在的情况下会失去效力。 这些结果揭示了,为何自私挖矿在理论上存在,但它在现实世界中可能是糟糕的攻击策略。 洒脱喜简评:同样是运用 AI 算法的区块链主题研究,与上一篇论文不同的是,这份研究的目的是识别出相关的区块链激励攻击,同时它也证明了当网络当中有多个代理(即攻击者时),相关的激励攻击效果就会减弱,也就是说网络最终还是会达到平衡的状态,因此我们不需要过于担心。 来源链接:www.8btc.com —- 编译者/作者:巴比特 玩币族申明:玩币族作为开放的资讯翻译/分享平台,所提供的所有资讯仅代表作者个人观点,与玩币族平台立场无关,且不构成任何投资理财建议。文章版权归原作者所有。 |
区块链学术前沿:AI 算法挑战自私挖矿策略,攻击区块链激励机制
2020-04-14 巴比特 来源:链闻

LOADING...
相关阅读:
- 趋势解币:BTC突破19年高点后追多还是看好新一轮下跌?2020-10-31
- 老猫论币∶比特币行情趋势布局精准完美多单止盈680个点数据是实力的2020-10-31
- 矿工拒绝“强捐”BCH又要分叉了2020-10-31
- 福布斯:PayPal支持购买比特币的自然语言分析|DeFi代币下跌,但基本面仍2020-10-31
- 归处说币:比特币多头情绪转浓行情一再向上试探突破2020-10-31