上周阅读到文章《隐私计算S2赛季「谁是真正的王者」》,对其中有一条提到的安全性和误差评测,尤其感兴趣。因为我从数十家客户的实际交付环节,看到审计对安全证明的必要性,同时也看到业务对联邦学习存在误差的“纠结”。证明一件事情正确是很困难的,那叫定理;当定理被大家都公认了,可能就是公理了。联邦学习项目又是一个综合性的复杂工程,证明安全,何其容易?取其名曰:荒岛求生。富数隐私计算平台Avatar从底层密码、算法到通信,完全自主研发,可以事无巨细地进行多维度评测。因此,本文将以富数科技的安全性评估体系为例,希望为行业带来一点小小的参考。 1 Avatar安全评估体系 Avatar安全评估体系方案针对多方联合建模产品的安全性进行验证,涉及模块如图:
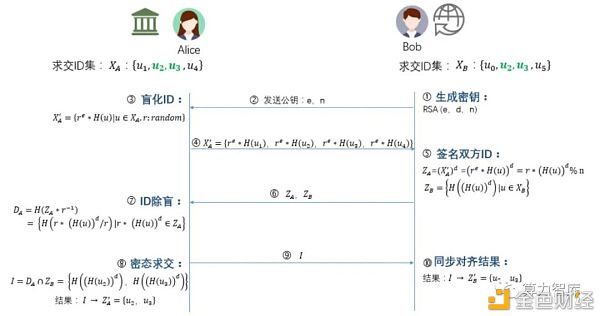
图:Avatar安全体系评估八要素 2 融合过程的安全性检测 1)安全融合原理
3)通信事件抓包这里举例对加密数据进行私钥盲签名,发送方:HOST,事件名称:inter_to_guest_1_0 事件描述:私钥对加密数据进行盲签名 blind_sid,抓包截图:
4)安全性分析为验证算法安全, 对”盲化 ID”和”ID 除盲”两个过程进行断点输出,输出中间临时 数据,以便方便验证算法安全,真实线上环境不会存在该输出动作。GUEST 一方中间数据断点输出两份数据, 即中间结果数据临时输出存储到本地。验证解析对比如下:1) 原始数据 ID + 随机掩码 + HOST 公钥(inter_pubkey 数据 e_data) = inter_to_host_1 数据 e_data;
通过正向逻辑计算 reh 值与步骤4通信的反序列化数据进行对比2) inter_to_guest_1 数据 e_data 进行 ID 除盲 = DA,为 guest 方中间计算结果;
采用线上+线下的对比测试进行验证,分析原理简单,此处略去。 3 联邦学习的误差分析
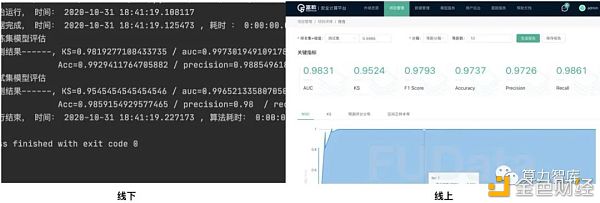
1)安全融合 运行线下验证脚本并进行截图, 得出两方数据对齐后的ID条数为39条, Avatar 运行结果表明对齐ID条数统计(加表头)共计40条,即实际对齐条数39条,与线下对齐结果一致。
下方为本地脚本运行截图,使用等频分箱方式,分箱后对目标变量单一取值的箱进行区间合并,通过结果对比,可知联邦计算与本地计算各指标结果相同。
3)模型训练 两任务以相同参数进行模型训练,通过结果对比可知密文计算较明文计算在保证数据安全的前提下,结果几乎无损。
4 Avatar监控大盘 在富数科技自研创新能力的加持下,Avatar 行业首创安全驾驶舱,让复杂的多方安全计算原理从黑盒变成白盒,让安全可视化,提高了安全的可解释性,让用户掌握更强的系统运营能力。 Avatar 支持参与各方完全直连,无需任何第三方,解决了甲乙两方安全建模找不到合适第三方的问题,让合作双方获得更加自主可信的数字空间。
小结 正如文中所说,隐私计算开始进入了比较白热化的赛季,这种竞赛表现在行业客户对厂商的选型与评测,在我们经历的所有客户,或多或少存在正面交流切磋,“以终为始,客户第一,一定是这个阶段最重要的。隐私计算软件作为一个安全软件的范畴,软件平台自身的安全性也相当重要。快与慢之间、精确与误差之外,只有和业务紧密结合,才可以做到可用。” 文章所载观点仅代表作者本人 且不构成投资建议 敬请注意投资风险 —- 编译者/作者:算力智库 玩币族申明:玩币族作为开放的资讯翻译/分享平台,所提供的所有资讯仅代表作者个人观点,与玩币族平台立场无关,且不构成任何投资理财建议。文章版权归原作者所有。 |
隐私计算S2赛季:安全性与误差评测的「荒岛求生」|算力隐私专栏
2020-11-04 算力智库 来源:区块链网络

 2)安全融合通信
2)安全融合通信
 反序列化的结果:
反序列化的结果: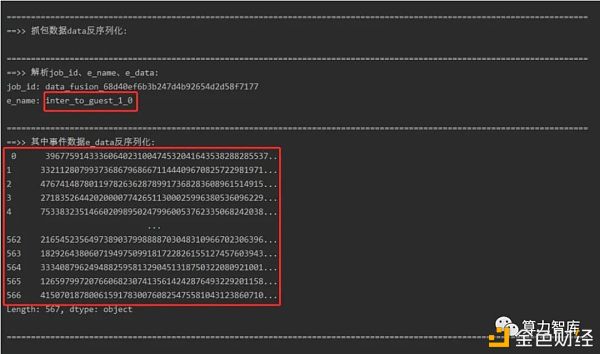

 5)准确性分析
5)准确性分析 Avatar联邦学习过程精度解析
Avatar联邦学习过程精度解析 2)特征工程
2)特征工程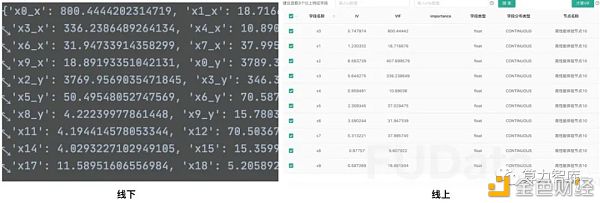
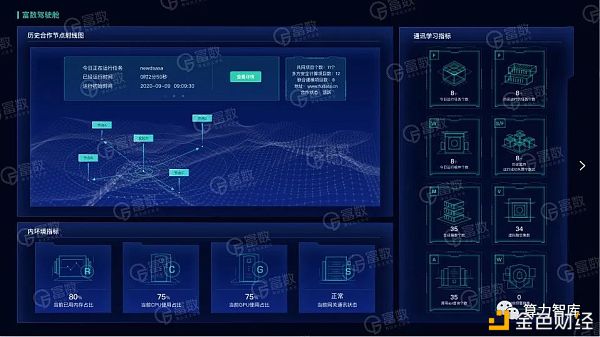 Avatar“驾驶舱” - 安全性监控大盘
Avatar“驾驶舱” - 安全性监控大盘
LOADING...
相关阅读:
- 数据显示,10月份主要DeFi代币暴跌30%至56%2020-11-04
- 华德看法:看盘的这些数据你可看得懂2020-11-04
- 【跟着勇哥柒学知识128】监管到来,大家纷纷将资产提到钱包,密钥成2020-11-04
- 分布式存储:IPFS/Filecoin是如何帮你存储数据的!2020-11-04
- BTC再次带领大盘回暖,中心化交易所频频出事,提币潮兴起,冷热钱包结合2020-11-04