


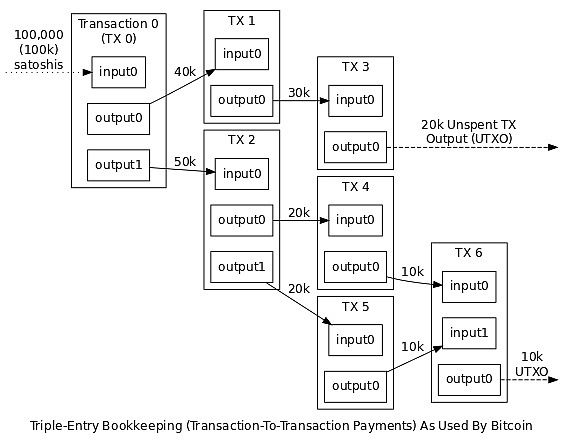
尽管以太坊的许多理念在早先的密码学货币(如比特币)上已经运用并测试了5年之久,但从某些协议功能的处理方法上来说,以太坊与常见方式仍有许多不同。而且,以太坊可用于开发全新的经济工具,因为它具有其他系统不具备的许多功能。本文会详细描述以太坊所有的潜在优点,以及在构建以太坊协议过程中某些有争议的地方。另外,也会指出我们的方案及替代方案的潜在风险。 原则 以太坊协议的设计遵循以下几点原则: 三明治复杂模型(亦可译为 “复杂度分层模型” ):我们认为以太坊的底层协议应尽可能的简单,接口设计应易于理解(不论是面向开发者的高级编程语言接口,还是面向用户的使用接口)。那些不可避免的复杂部分应放入中间层。中间层不作文核心共识的一部分,且对最终用户不可见,它包含:高级语言编译器、参数序列化和反序列化脚本、存储数据结构模型、leveldb 存储接口以及联网协议等。当然,区分的界线不是绝对明确的,有时候需要酌情调整。 自由:不应限制用户使用以太坊协议,也不应试图优先支持或不支持某些以太坊合约或交易。这一点与 “网络中立” 概念背后的指导原则相似。比特币交易协议就?没有?遵循这一原则:比特币交易协议并不鼓励区块链的 “非常规用途(off-labal purpose)” (如,数据存储,元协议)(校对注:off-labal 的原意为将药物用在其经过批准的适应症之外的症状上,例如使用止咳药来治疗头痛。此处意译为 “非常规用途” );而且,有时候还有人用 准-协议层 的变更(例如将 OP_RETURN 字段的长度限制在 40 字节)来攻击以 “未经授权” 的方式使用区块链的应用(校对注:此处是在讽刺比特币的社区有审查比特币区块链用法的倾向)。因此,在以太坊,我们坚定支持仅使用交易手续费来达成大体激励相容的办法 —— 用户消耗整个网络越多资源,需要付出的代价就越高,也即使其自己承担成本(即庇古税)。 泛化:以太坊协议的特性和操作码应最大限度地体现低层次的概念(就像基本粒子一样),以便它们可以随意组合,包括组合出今天看来没什么用、但未来可能有用的东西。而且,通过剥离那些不需要的功能,低层次的概念可以更加高效。遵循这一原则的例子是,我们选择 LOG 操作码作为向 dapp 提供信息的方式,而不是像之前那样记录下所有交易和消息。在早先,“消息(message)” 的概念完完全全是多种概念的集合,它包含 “函数调用(function call)” 和 “外在观察者感兴趣的事件信息(event)” ,而两者是完全可以分离开来的。 没有特点就是最大的特点:为了遵循泛化原则,我们拒绝将那些高级用例内嵌为协议的一部分,哪怕是经常使用的用例,也绝不这么做。如果人们真的想实现这些用例,可以在合约内创建子协议(如,基于以太坊的子货币,比特币/莱特币/狗币的侧链等)。比如,在以太坊中就缺少类似比特币中的 “时间锁” 功能。但是,通过以下协议可以模拟出这个功能:用户发送签名数据包到特定的合约中处理,如果数据包在特定合约中有效,则执行相应的函数。 不厌恶风险:如果风险的增加带来了可观的好处,我们愿意承担更高的风险(例如,通用的状态转换,出块时间减低 50 倍,共识效率,等等)。 这些原则指导着以太坊的开发,但它们并不是绝对的;某些情况下,为了减少开发时间或者不希望一次作出过多改变,也会使我们推迟作出某些修改,把它留到将来的版本中去修改。 区块链层协议 本节对以太坊中区块链层协议的改变进行了描述,包括区块和交易是如何工作的、数据如何序列化及存储、账户背后的机制。 账户 ,而非 UTXO?1 比特币及其许多变种,都将用户的余额信息存储在 UTXO 结构中,系统的整个状态由一系列的 “未花费的输出” 组成(可以将这些 “未花费的输出” 想象成钱币)(校对注:更好的一个比喻可能是 “支票”。)。每个 UTXO 都有拥有者和自身的价值属性。一笔交易在消费若干个 UTXO 同时也会生成若干个新的 UTXO;而交易受到下列有效性要求的约束:1.每个被引用的输入必须有效,且未被使用过;2.交易的签名必须与每笔输入的所有者签名匹配;3.输入的总值必须等于或大于输出的总值。因此,比特币系统中,用户的 “余额” 是该用户的私钥能够有效签名的所有 UTXO 的总和。下图展示了比特币系统中交易输入输出过程:
比特币所用的三式记账法 但是,以太坊抛弃了 UTXO 的方案,转而使用更简单的方法:采用状态(state)的概念存储一系列账户,每个账户都有自己的余额,以及以太坊特有的数据(代码和内部存储器)。如果交易发起方的账户余额足够支付交易费用,则交易有效,那么发起方账户会扣除相应金额,而接收账户则计入该金额。某些情况下,接收账户内有需要执行的代码,则交易会触发该代码的执行,那么账户的内部存储器可能会发生变化,甚至可能会创建额外的消息发送给其他账户,从而导致新的交易发生。 尽管以太坊没有采用 UTXO 的概念,但 UTXO 也不乏有一些优点: 较高程度的隐私保护:如果用户每次交易都使用一个新的地址,那么账户之间的相互关联就很困难。这样做适用于对安全性要求高的货币系统,但不是对任何 dapp 都合适。因为 dapp 通常需要跟踪用户复杂的绑定状态,而 dapp 的状态并不能像货币系统中的状态那样简单地划分。 潜在的可扩展性:理论上来说,UTXO 与某些类型的可扩展性方案(scalability paradigm)更契合,因为只需持币者拥有能够证明自己货币所有权的默克尔证明即可,即使所有的人(包括 TA 本人)都遗忘了这一数据,真正受损也这个人,其他人不受影响。在以太坊账户系统中,如果所有人都丢失了某个账户对应的默克尔树部分,那么该账户将无法处理任何能够影响它的消息,包括发送给它的消息,它也无法处理。不过,并非只有 UTXO 能够可扩展,也存在不依赖 UTXO 就能扩展的方式(此处没有扩展开来讲,译者注)。 账户的好处有以下几点: 节省大量空间:如果一个账户有 5 个 UTXO,则从 UTXO 模式转成账户模式,所需空间会从 300 字节降到 30 字节。具体计算如下:300 = (20+32+8)* 5 (20 是地址字节数,32 是 TX 的 id 字节数,8 是面额占用的字节数); 30 = 20 + 8 + 2 (20 是地址字节数,8 是账户余额值字节数,2 是 nonce?2?字节数);但实际节约并没有这么大,因为账户需要被存储在帕特里夏树中。另外以太坊中交易也比比特币中的更小(以太坊中 100 字节,比特币中 200-250 字节),因为每次交易只需要生成一次引用,一次签名,以及一个输出。 可互换性更强:UTXO 结构并没有区块链层的概念,所以不管是在技术还是法律上,通过建立一个红名单/黑名单,并依据的这些 “有效输出” 的来源区分它们并不是很实际。 简单:以太坊编码更简单、更易于理解,尤其是在涉及到复杂脚本时。尽管任何去中心化应用都可以用 UTXO 方式来(勉强)实现,但这种方式实质上是赋予脚本限制给定的 UTXO 所能输出的 UTXO 的种类及其使用条件(比如需要包含默克尔树证明来帮助脚本所对应的应用更改状态根)的能力。因此,UTXO 实现方式比以太坊使用账户的方式要复杂的多。 轻客户端:轻客户端可以随时通过沿指定方向扫描状态树来访问与账户相关的所有数据。在 UTXO 范式中,每笔交易需要用到的引用都不同,这对于长时间运行并使用了上文提到的 UTXO 根状态传播机制的 dapp 应用来说,无疑是繁重的。 我们认为,账户的好处大大超过了其他方式,尤其是对于我们想要支持的、可包含任意状态和代码的 dapp 应用而言。另外,本着 “没有特点就是最大的特点” 的指导原则,我们认为如果用户真的关心私密性,则可以通过合约中的签名数据包协议来建立一个加密 “混币器(mixer and coinjoin)” 混淆支付路径。 账户方式的一个弱点是:为了阻止重放攻击(replay attack,指让同一笔交易重复执行),每笔交易必须有一个 “nonce”(流水号)。因此,每个账户都要有一个实时更新的 nonce 值,每一笔新交易都在账户 nonce 值上递增 1 作为自己的 nonce(并在交易处理之后按此值更新账户的 nonce 值)(校对注:在账户模式下,如果交易不附带这种消耗性的标识符,交易就可被重复处理,这样接收账户可以一遍又一遍地收账且不用付出任何代价,而发账的账户会被吸干;以太坊账户的 nonce 随所发起的交易得到处理而递增,就解决了这个问题)。这就意味着,即使不再使用的账户,也不能从账户状态中移除。解决这个问题的一个简单方法是让交易包含一个区块号,使它们在一段时间后就无法再被重放,并且每隔一段时间段重置 nonce。 若要在状态中删除某个账户(比如长期不使用的账户),就必须先 “ping” 出它们来,而完整扫描区块链协议的开销是非常大的。在1.0上我们没有实现这个机制,1.1及以上版本可能会使用这个机制。
默克尔帕特里夏树(MPT) 默克尔帕特里夏树(Merkle Patricia tree/trie),由 Alan Reiner 提出设想,并在瑞波协议中得到实现,是以太坊的主要数据结构,用于存储所有账户状态,以及每个区块中的交易和收据数据。MPT 是默克尔树和帕特里夏树的结合,结合这两种树创建的结构具有以下属性: 任一组 键-值对 所对应的根哈希值都是唯一的,想要谎称某个 键值对 存在于某棵树上是一定会被识破的(除非攻击者拥有约 2^128 的算力)。 增、删、改 一个键值对的时间复杂度是对数级别。 MPT为我们提供了一个高效、易更新、且代表整个状态树的 “指纹” 。关于MPT更详细描述:https://github.com/ethereum/wiki/wiki/Patricia-Tree。 MPT的具体设计决策如下: 有两类节点:KV 节点和离散节点。KV节点的存在提高了效率,因为如果在特定区域树是稀疏的,KV节点可作为一个 “捷径” 来压缩树的高度(阅读 MPT 的详述可了解更多细节)。 离散节点是十六进制,不是二进制:这样让查找更有效率,我们现在认识到这种选择并不理想,因为十六进制树的查找效率在二进制中可以通过批次存储节点来模拟。但是,MPT 树结构的实现是非常容易出错的,最终至少会造成状态根不匹配,所以我们决定搁置变更,等到 1.1 版本再说。 空值(empty value)与非成员(non-membership)之间没有区别:这样做是为了简化逻辑,以太坊中未启用的账户的值(余额)默认为 0,空字符串也用 0 表示。然而,需要强调的是,这样做牺牲了一些通用性,因而也不是最优的。 终节点(terminating)和非终节点的区别:技术上,标识一个节点 “是否是终节点” 是没必要的,因为以太坊中所有的树都被用于存储固定长度(即键的长度)的数据,但为了增加通用性,我们还是会添加这个标识,以期望以太坊的 MPT 的实现方式能够被其他密码学货币原样采纳。 在 “安全树”(状态树和账户存储树)中采用 SHA3(k) 作为键:使用 SHA3(k),想要通过生成许多的账户(账户最多可让状态树高达 64 层!)并重复调用 SLOAD 和 SSTORE 操作码来 DoS 攻击的难度会大大提高。注意,这也让枚举树变得更困难;如果要使你的客户端具备枚举的功能,最简单的方法就是维护一个映射?sha3(k) -> k?的数据库。
RLP RLP(recursive length prefix):递归长度前缀。 RLP 编码是以太坊中主要的序列化格式,它的使用无处不在:区块、交易、账户状态以及网络协议消息。详见 RLP 正式描述:?https://github.com/ethereum/wiki/wiki/RLP RLP 旨在成为高度简化的序列化格式,它唯一的目的是存储嵌套的字节数组?3。不同于?protobuf、BSON?等现有的解决方案,RLP并不定义任何指定的数据类型,如 Boolean(布尔值)、float(浮点数)、double 或者 integer(整数)。它仅仅是以嵌套数组的形式存储结构体,由协议来确定数组的含义。RLP 也没有显式支持 map 集合,半官方的建议是采用?[[k1, v1], [k2, v2], ...]?的嵌套数组来表示键值对集合,k1,k2 ... 按照字符串的标准排序。 与 RLP 具有相同功能的方案是 protobuf 或 BSON,它们是一直被使用的算法。然而,以太坊中,我们更偏向于使用 RLP,因为:(1)它易于实现;(2)绝对保证字节的一致性。 许多语言的键值对集合没有明确的排序,并且浮点格式有很多特殊情况,这可能造成相同数据却产生不同编码和不同哈希值。通过内部开发协议,我们能确保它是带着这些目标设计的(这是一般原则,也适用于代码的其他部分,如虚拟机)。BitTorrent 使用的编码方式 bencode 也许可以替代 RLP。不过它采用的是十进制的编码方式,与采用二进制的 RLP 相比,稍微逊色了点。 压缩算法 网络协议和数据库都采用了一个自定义的压缩算法来存储数据。该算法可描述为:对 0 使用行程编码?4?并同时保留其他值(除了一些特殊情况如?sha3(' ')?),举例如下: 压缩算法存在之前,以太坊协议的许多地方都有一些特殊情况,例如,sha3 经常被重定义使得?sha3(' ')=' ',这样不需要在账户中存储代码,可以节省 64 字节。然而,最近所有这些使得以太坊数据结构变得臃肿的特殊情况都被删除了,取而代之的是将数据保存函数添加到区块链协议之外的层,也就是将其放入网络协议以及将其插入用户数据库实现。这样增加了模块化能力,简化了共识层,使得对压缩算法的持续更新部署起来相对简单(例如:可通过网络协议的版本号来区别、部署)。 树(trie)的使用 提醒:理解这部分的知识需要读者了解布隆过滤器?5?的原理。简介可见:http://en.wikipedia.org/wiki/Bloom_filter 以太坊区块链中每个区块头都包含指向三个树的指针:状态树、交易树、收据树。 状态树代表处理完该区块后的整个状态; 交易树代表区块中所有交易,这些交易由 index 索引作为key;(例如,k0:第一个执行的交易,k1:第二个执行的交易) 收据树代表每笔交易相应的收据。 交易的收据是一个 RLP 编码的数据结构: 其中: medstate:交易处理后,状态树的根; gas_used:交易处理后,gas 的使用量; logs:是许多?[address, [topic1, topic2...], data]?元素的列表。这些元素由交易执行期间调用的操作码?LOG0?...?LOG4?生成(包含主调用和子调用);address?是生成日志的合约的地址;topics 是最多 4 个 32 字节的值;data 是任意大小的字节数组; logbloom:交易中所有 logs 的 address 和 topics 组成的布隆过滤器。 区块头中也存在一个布隆过滤器,它是区块中交易的所有布隆过滤器的或运算(OR)结果。这样的构造使得以太坊协议对轻客户端友好得无以复加。 注释: UTXO:unspent transaction outputs,字面理解是:未花费的交易输出,也即未被任何交易引用为输入的交易输出。它是比特币协议中用于存储价值(所有权)信息的数据结构。—— 校对注 Nonce,Number used once 或 Number once 的缩写,在密码学中 Nonce 是一个只被使用一次的任意或非重复的随机数值,在加密技术中的初始向量和加密哈希函数都发挥着重要作用,在各类验证协议的通信应用中确保验证信息不被重复使用以对抗重放攻击(Replay Attack)。—— 译者注 嵌套数组:创建一个数组,并使用其他数组填充该数组。如数组 pets:var cats : String[] = ["Cat","Beansprout", "Pumpkin", "Max"];var dogs : String[] = ["Dog","Oly","Sib"];var pets : String = [cats, dogs];—— 译者注 行程编码(run-length-encoding):一种统计编码。主要技术是检测重复的比特或字符序列,并用它们的出现次数取而代之。(百度百科)—— 译者注 布隆过滤器:由 Howard Bloom 在 1970 年提出的二进制向量数据结构,它具有很好的空间和时间效率,被用来检测一个元素是不是集合中的一个成员。(百度百科)—— 译者注 叔块(uncle blocks)奖励 GHOST 协议是一项不起的创新,由 Yonatan Sompolinsky 和 Aviv Zohar 在 2013 年 10 月首次提出的。它是解决快速出块伴生问题的第一个认真尝试。 GHOST 的用意是解决这样一个难题:更短的出块时间(因此确认速度会更快)会导致有更多区块 “过时” 因而安全性会下降 —— 因为区块在网络中传播需要一定时间,如果矿工 A 挖到一个区块并向全网广播,在广播的路上,B 也挖出了区块,那么 B 的区块是过时的,且 B 的本次挖矿对网络的安全没有贡献。 此外,还有一个中心化问题:如果 A 是一个矿池,有 30% 的算力,B 有 10% 的算力。A有 70% 的时间产生过时的区块(因为另外的 30% 时间会产生最新区块,可认为 TA “立即” 得到了最新块的数据而无需等待区块传播),而 B 有 90% 的时间产生过时区块。如果区块的产出时间间隔很短,那么过时率就会变高,则 A 凭借其更大的算力使挖矿效率也更高。所以,区块生成过快,容易导致网络算力大的矿池在事实上垄断挖矿过程。 根据 Sompolinsky 和 Zohar的描述,GHOST 解决了在计算哪个链是最长的链的过程中,因产生过时区块而造成的网络安全性下降的问题。也就是说,不仅是父区块和更早的区块,同时过时的旁支区块(在以太坊中,我们称之为 “叔块”)也被添加到计算哪个块具有最大的总工作量证明中去。 为了解决第二个问题:中心化问题,我们采用了另一种策略:对过时区块也提供区块奖励:挖到过时区块的奖励是该区块基础奖励的 7/8;而包含过时区块的侄子区块将收到 1/32 的基础奖励作为赏金。但是,交易费不会奖励给叔块和侄块。 在以太坊中,过时区块只能被其兄弟区块的 7 代以内的直系后代区块包含为叔块。之所以这样限制是因为,首先,GHOST 协议若不限制过时区块的代际距离,将会花费大量开销在计算过时区块的有效性上;其次,无限制的过时区块激励政策会让矿工失去在主链上挖矿的热情;最后,计算表明,过时区块奖励政策限制在 7 层内提供了大部分所需的效果,而且不会带来负面效应。 度量中心化风险的一个模拟器可见此处:https://github.com/ethereum/economic-modeling/blob/master/ghost.py 一个更高层次的讨论可见此处:https://blog.ethereum.org/2014/07/11/toward-a-12-second-block-time/ 校对注:此处的 “包含” 在技术上的形式是:侄块在区块头中引用叔块的区块哈希值,然后把叔块的区块头包含在区块体内。 区块时间算法的设计决策包括: 区块时间 12s:选择 12 秒是因为这已经是长于网络延迟的最短时间间隔了。在 2013 年的一份关于测量比特币网络延迟的论文中,确定了 12.6 秒是新产生的区块传播到 95% 节点的时间;然而,该论文还指出传播时间与区块大小成比例,因此在更快的货币中,我们可以期待传播时间大大减少。传播间隔时间是恒定的,约为 2 秒。然而,为了安全起见,在我们的分析中,我们假定区块的传播需要 12 秒 7 代祖先以内的限制:这样设计的目的是希望只保留少量区块,而将更早之前的区块清除。已经证明 7 代的可引用范围就可以提供大部分所需的效果。 1 代后裔的限制:(例如,设 c = child 且 p = parent,则?c(c(p(p(p(head)))))?是无效的):这也是出于简洁性的设计目标,而且上述的模拟器显示这不会带来很大的中心化风险。(校对注:此句难解;一种可能的意思是:叔块的后代不能作为叔块,即只有主链的一代旁支能作为叔块。) 叔块必须是有效的?:叔块必须是有效的 header,而不是有效的区块。这样做也是为了简化,将区块链模型保持为线性数据结构(而不会变成 DAG)。不过,要求叔块是有效的区块也是有效的方法。 奖金分配:7/8 的挖矿基础奖励分配给叔块,1/32 分给侄块,它们交易费用都是 0%。如果费用占多数,从中心化的角度看,这会使叔块激励机制无效;然而,这也是为什么只要我们继续使用 PoW,以太坊就会不断发行以太币的原因。 难度更新算法 目前以太坊通过以下规则进行难度更新: 难度更新规则的设计目标如下: 快速更新:区块间的时间应该随着 hash 算力的增减而快速调整; 低波动性:如果挖矿算力恒定,那么难度不应剧烈波动; 简单:算法的实现应相对简单; 低内存:算法不应依赖于过多的历史区块,要尽可能少的使用 “内存变量”。假设有最新的十个区块,将存储在这十个区块头部的内存变量相加,这些区块都可用于算法的计算; 不可爆破:算法不应让矿工有过多篡改时间戳或者矿池反复添加或删除算力的激励 我们当前的算法在低波动性和抗爆破性上并不理想。最近,我们计划把时间戳参数改为与父区块和祖父区块比较,所以矿工只有在连续挖 2 个区块时,才有动力去修改时间戳。另一个更强大的模拟公式:https://github.com/ethereum/economic-modeling/blob/master/diffadjust/blkdiff.py Gas 和费用 比特币中所有交易大体相同,因此它们的网络成本用单一一种单位来模拟。以太坊中的交易要更复杂,所以交易费用需要考虑到账户的许多方面,包括网络带宽费用、存储费用和计算费用。尤其重要的是,以太坊编程语言是图灵完备的,所以交易会使用任意数量的宽带、存储和计算成本;而最终会使用多少数量是无法可靠预测的(因为所谓的 “图灵停机问题”)(校对注:即不存在一个可靠的办法,能够断言任意可在图灵机上执行的程序会不会在有限步内终止)。防止有人使用无限循环来实施拒绝服务式攻击是我们的一个关键目标。 以太坊交易费用的基本机制如下: 每笔交易必须指明自身愿意消耗的 gas 数量(即指定?startgas?的值),以及愿意为每单元 gas 支付的费用(即?gasprice?),在交易执行开始时,startgas * gasprice 价值的以太币会从发送者账户中扣除;(校对注:此处的?startgas?就是我们现在惯用的?gaslimit?。) 交易执行期间的所有操作,包括读写数据库、发送消息以及每一步的计算都会消耗一定数量的 gas; 如果交易执行完毕,消耗的 gas 值小于指定的限制值,则交易执行正常,并将剩余的 gas 值赋予变量?gas_rem?; 在交易完成后,发送者会收到返回的 gas_rem * gasprice 价值的以太币,而给矿工的奖励是(startgas - gas_rem)* gasprice 价值的以太币; 如果交易执行中,gas消耗殆尽,则所有的执行恢复原样,但交易仍然有效,只是交易的唯一结果是将 startgas * gasprice 价值的以太币支付给矿工,其他不变; 当一个合约发送消息给另一个合约,可以对这个消息引起的子执行设置一个 gas 限制。如果子执行耗尽了 gas,则子执行恢复原样,但 gas 仍然消耗。(校对注:截至本文校对之时(2021 年 7 月 9 日),这一点还未改变,但它在未来有可能会改变。见《值得考虑删除的 EVM 功能》) 上述提到的几点都是必须满足的,例如: 如果交易不需要指定 gas 限制,那么恶意用户就会发送一个有数十亿步循环的交易。没有人能够处理这样的交易,因为处理这样的交易花的时间可能很长很长;但是谁也无法预先告知网络上的矿工,这就会导致拒绝服务的漏洞产生。 一种替代严格 gas 计数的方法是时间限制,但它不可能有用,因为它们太主观了(某些计算机比别人的更快,即使大家的计算机都一样也仍然有可能出现差池)。 startgas * gasprice 的整个值,在开始时就应该设置好,这样不至于在交易执行中造成该账户 “破产”、无力继续支付 gas 费用。一边执行一边检查余额也不行,因为账户可以把余额放到别的地方。 如果在 gas 不够的情况下,交易执行不会完全复原(回滚),合约就必须采用强有力的安全措施来防止合约发生变化。 如果子限制不存在,则恶意账户可以对其他合约实施拒绝服务攻击。攻击者可以先与受害合约达成一致意见,然后在计算过程开始时插入一个无限循环,那么发送消息给受害合约或者受害合约的任何补救尝试,都会使整个交易死锁。(校对注:此句亦难解。) 要求交易发送者而不是合约来支付 gas,这样大大增加了开发人员的可操作性。以太坊早期的版本是由合约来支付gas的,这导致了一个相当严重的问题:每个合约必须实现 “门卫” 代码,确保每个传入的消息为合约提供了足够的以太币供其消耗。 gas 消耗计算有以下特点: 对于任何交易,都将收取 21000 gas 的基本费用。这些费用可用于支付运行椭圆曲线算法所需的费用(该算法旨在从签名中恢复发送者的地址)以及存储交易所花费的硬盘和带宽空间。 交易可以包括无限量的 “数据” 。虚拟机中的某些操作码,可以让收到这样交易的合约访问这些数据。数据的 “固定消耗量” 规则是:每个零字节 4 gas,非零字节 68 gas。这个公式的产生是因为用户向合约发送的交易中,大部分的交易数据由一系列的 32 字节的参数组成,其中多数参数具有许多前导零字节。该结构看起来似乎效率不高,但由于压缩算法的存在,实际上还是很有效率的。我们希望此结构能够代替其他更复杂的机制:这些机制根据预期字节数严格包装参数,从而导致编译阶段复杂性大增。这是三明治复杂模型的一个例外,但由于成本效益比,这也是合理的模型。 用于设置账户存储项的操作码 SSTORE 的消耗是:1)将零值改为非零值时,消耗 20000 gas;2)将零值变成零值,或非零值变非零值,消耗 5000 gas;3)将非零值变成零值,消耗 5000 gas;此外,交易执行成功(即未耗尽 gas 交易就执行完了)后会退回 15000 gas。退款金额上限是交易消耗 gas 总额的 50%。这给了人们小小激励去清除存储项。我们注意到,正因为缺乏这样的激励,许多合约的存储空间没有被有效使用,从而导致了存储数据的快速膨胀。这一设计既能提供 “为存储项持续收取租金” 模式的大部分好处,又不会失去合约一旦确立就可以永久存在的保证。延迟退款机制是必要的,因为可以阻止拒绝服务攻击:攻击者可以发送一笔含有少量 gas 的交易,循环清除大量的存储项,直到用光 gas,这样消耗了大量的验证算力,但实际并没有真正清除存储,也不需要付出很多 gas。50% 的上限的是为了确保打包交易的矿工依然能够确定执行交易的计算时间的上限。 (校对注:首先,SSTORE 等状态访问操作码的 gas 消耗量已经随着以太坊的硬分叉而多次更改。截至 2021 年 7 月,最新的数值可见《柏林升级内容概览》;在可预见的未来,这个操作码的数值还会继续变化;其次,这里的 gas refund 机制,事后证明并没有启动缓解状态数据的膨胀问题,反而恶化了该问题,因为人们可以在 gas price 较低时写入大量垃圾数据,在 gas price 较高时清除这些数据来获得 gas,这就是 “GasToken” 的原理。当前已确定,在 “伦敦” 分叉中会改变 gas refund 机制,见《以太坊 “伦敦” 升级预览》。) 合约提供的消息数据是没有成本的。因为在消息调用期间不需要实质复制任何数据,调用数据(call data)可以简单地视为指向父合约 memory 的指针,该指针在子进程执行时不会改变。 Memory 是一个可以无限扩展的数组,然而,每扩展 32 字节的 memory 就会消耗 1 gas 的成本,不足 32 字节以 32 字节计。(校对注:memory 一般译为内存,但在以太坊的语境下,它是 EVM 由于存储数据的三种类型之一,因此都不译,以示其特殊性。) 某些操作码的计算时间极度依赖参数,gas 开销计算是动态变化的。例如,EXP 的的开销是指数级别的(10 gas + 10 gas/字节,即,x^0 = 1 gas、x^1 … x^255 = 2 gas、x^256 … x^65535 = 3 gas,等等)。复制操作码(如:CALLDATACOPY, CODECOPY, EXTCODECOPY)的开销是 1 gas + 1 gas/32 字节(四舍五入;LOG 操作码的规则也类似)。Memory 扩展的开销不包含在这里。如若包含,会变成一个平方攻击向量(50000 次的 CALLDATACOPY,每次消耗 50000 gas,则其计算量应是 50000^2,但如果不使用动态收费规则,就只需付出 ~50000 gas)。 如果值不是零,操作码 CALL(以及 CALLCODE)会额外消耗 9000 gas。这是因为任何值传输都会引起归档节点的历史存储显著增大。请注意,操作的?实际消耗?是 6700;但是此基础上,我们强制增加了一个自动给予接收者的 gas 值,这个值最小 2300。这样做是为了让接受交易的钱包至少有足够的 gas 来生成 log。(校对注:见《值得考虑删除的 EVM 功能》) Gas 机制的另一个重要部分是 gas 价格本身体现出的经济学原理。比特币中,默认的方法是采取纯粹自愿的收费方式,矿工扮演守门人的角色并且动态设置收费的最小值。以太坊中允许交易发送者设置任意数目的 gas。这种方式在比特币社区非常受欢迎,因为它是 “市场经济” 的体现:允许矿工和交易者之间依据供需关系来决定价格。然而,这种方式的问题是,交易处理并不遵循市场原则。尽管可以将交易处理看作是矿工向发送者提供的服务(这听起来很直观),但实际上矿工所处理的每个交易都必须由网络中的每个节点处理,所以交易处理的大部分成本都由第三方机构承担,而不是决定是否处理它的矿工。因此,“公地悲剧” 问题很有可能发生。 当前,因为缺乏矿工在实际中的行为的明确信息,所以我们将采取一个非常简单公平的方法:投票系统,来设定单个区块可消耗的 gas 总额。矿工有权将在最新区块的 gas 上限基础上变更 0.0975% (1/1024),作为当前区块的 gas 上限。所以最终的 gas 上限应该是矿工们设置的中间值。我们希望将来能够采用软分叉的方法来使用更加精确的算法。 虚拟机 以太坊虚拟机是执行交易代码的引擎,也是以太坊与其他系统的核心区别。请注意,虚拟机应该同 “合约与消息模型” 分开考虑。例如,SIGNEXTEND 操作码是虚拟机的一个功能,但实际上 “某个合约可以调用其他合约并指定子调用的 gas 限定值” 是 “合约与消息模型” 的一部分。 EVM的设计目标如下: 简单:操作码尽可能的少并且低级;数据类型尽可能少;虚拟机的结构尽可能少; 结果明确:在 VM 规范中,没有任何可能产生歧义的空间,结果应该是完全确定的。此外,计算步骤应该是精确的,以便可以测量 gas 的消耗量; 节约空间:EVM 组件应尽可能紧凑; 为预期用途而特化:在 VM 上构建的应用应能处理 20 字节的地址,以及 32 位的自定义加密值,拥有用于自定义加密的模数运算、读取区块和交易数据与状态交互等能力; 简单安全:为了让 VM 不被利用,应该能够容易地让建立一套 gas 消耗成本模型的操作; 优化友好:应该易于优化,以便即时编译(JIT)和 VM 的加速版本能够构建出来。 同时 EVM 也有如下特殊设计: 临时/永久存储的区别:我们先来看看什么是临时存储和永久存储。临时存储:存在于 VM 的每个实例中,并在 VM 执行结束后消失。永久存储:存在于区块链状态层。假设执行下面的树(S 代表永久存储,M 代表临时存储): A调用 B; B 设置?B.S[0]=5,B.M[0]=9?; B 调用 C; C 调用 B。此时,如果B试图读取?B.S[0]?,它将得到B前面存入的数据,也就是 5;但如果 B 试图读取?B.M[0]?,它将得到 0,因为 B.M 是临时存储,读取它的时候是虚拟机的一个新的实例。在一个内部调用(inner call)中,如果设置?B.M[0] = 13?和?B.S[0] = 17?,然后内部调用和 C 的调用都终止、回到了 B 的外部调用(outer call),此时读取 M,将会看到?B.M[0] = 9?(此值是在上一次同一 VM 执行实例中设置的),?B.S[0] = 17?。如果 B 的外部调用结束,然后 A 再次调用 B,将看到?B.M[0] = 0,B.S[0] = 17?。这个区别的目的是:1.每个执行实例都分配有内存空间,不会因为循环调用而减损,这让安全编程更加容易。2.提供一个能够快速操作的内存形式:因为需要修改树,所以存储更新必然很慢。 栈/memory 模式:早期,计算状态(除了指向下一个指令的程序计数器)有三种:栈(stack,一个 32 字节标准的 LIFO 栈),内存(memory,可无限延长的临时字节数组),存储项(storage,永久存储)。在临时存储端,栈和内存的替代方案是 memory-only 范式,或者是寄存器和内存的混合体(两者区别不大,寄存器本质上也是一种内存)。在这种情况下,每个指令都有三个参数,例如:?ADD R1 R2 R3: M[R1] = M[R2] + M[R3]?。选择栈范式的原因很明显,它使代码缩小了 4 倍。 单词大小 32 字节:在大多数结构中,如比特币,单词大小是 4 或 8 字节。4 或 8 字节对存储地址和加密计算来说局限性太大了。而不对大小作限制又很难建立相应安全的 gas 模型。32 字节是一个理想大小,因为它足够存储下许多密码算法所需要的大数值以及地址,又不会因为太大而导致效率低下。我们有自己的虚拟机:我们的虚拟机使用 java、Lisp 和 Lua 等语言开发。我们认为开发一款专业的虚拟机是值得的,因为:1)我们的 VM 规范比其他许多虚拟机简单的多,因为其他虚拟机为复杂性付出的代价更小,也就是说它们更容易变得复杂;然而,在我们的方案中每额外增加一点复杂性,都会给集约化发展带来障碍,并带来潜在的安全缺陷,比如共识错误,这就让我们的复杂性成本很高;2)我们的 VM 更加专业化,如支持 32 字节;3)我们不会有复杂的外部依赖,复杂的外部依赖会导致我们安装失败;4)完善的审查机制,可以具体到特殊的安全需求;即使使用外部 VM,也无法节省太多工作量。使用了可变、可扩展的 memory 大小:固定 memory 的大小是不必要的限制,太小或太大都不合适。如果内存大小是固定的,每次访问内存都需要检查访问是否超出边界,显然这样的效率并不高。1024 调用深度限制:许多编程语言在内存还没有溢出时,就因为调用深度太深而崩溃了。所以仅使用区块 gas 上限一种限制是不够的。无类型:只是为了简洁。不过,DIV、SDIV、MOD、SMOD 会使用有符号(signed)或无符号的操作码(事实证明,对于操作码 ADD 和 MUL,有符号和无符号是对等的);转换成定点运算在所有情况下都很简单,例如,在 32 位长度下,a * b -> (a * b) / 2^32, a / b -> a * 2^32 / b?,+、- 和 * 在整数下不变。校对注:在原译本中还有如下一段,但其对应段落在当前版本的原文中已经删除了:?栈大小没有限制:没什么特别理由!许多情况下,该设计不是绝对必要的;因为,gas 的开销和区块 gas 上限总是会充当每种资源消耗的上限。 这个 VM 中某些操作码的功能和用意很容易理解,但也有一些不太好理解,以下是一些特殊的原因: ADDMOD, MULMOD:大多数情况下,?mulmod(a, b, c) = a * b % c?,但在椭圆曲线算法中,使用的是 32 字节模数运算,直接执行?a * b % c?实际上是在执行?((a * b) % 2^256) % c?,会得到完全不同的结果。在 32 字节的空间中执行 32 字节数值的?a * b % c?计算的共识非常困难且繁琐。 SIGNEXTEND:SIGNEXTEND操作码的作用是为了方便从大的有符号整数到小的有符号整数的类型转换。小的有符号整数是很有用的,因为未来的即时编译虚拟机也许有能力检测主要处理 32 字节整数又长时间运行的代码块,小的有符号整数能加快处理。 SHA3:在以太坊代码中,SHA3 作为安全的、高强度的、不定长数据哈希映射方法,应用非常广泛。通常,在使用存储器时,需要使用 Hash 函数来防止恶意冲突,在验证默克尔树和类似的以太坊数据结构时也需要使用到 Hash 函数。重要的是,与 SHA3 的相似的哈希函数,如 SHA256、ECRECVOR、RIPEM160,不是以操作码的形式包含在里面,而是以伪合约的形式。这样做的目的是将它们放在一个单独的类别中,如果当我们以后提出适当的 “原生插件” 系统时,可以添加更多这样的合约,而不需要扩展操作码。 ORIGIN:ORIGIN 操作码由交易的发送者提供,主要的作用是允许合约退回支付的 gas。 COINBASE:COINBASE 的主要作用是:1)允许子货币对网络安全作出贡献;2)使矿工能够作为一个去中心化的经济体,来设置基于子共识的应用,如 Schellingcoin。 PREVHASH:PREVHASH 可用作一个半安全的随机来源。此外,允许合约求值(evalute)上一个区块的默克尔树状态证明,而不需要高度复杂的 “以太坊轻客户端” 递归结构 。 EXTCODESIZE, EXTCODECOPY:主要的作用是让合约依据模板检查其他合约的代码,甚至是在与其他合约交互前,模拟它们。见:https://lesswrong.com/lw/aq9/decision_theories_a_less_wrong_primer/ JUMPDEST:当跳转(jump)目的地限制在几个索引时(尤其是,动态目的跳转的计算复杂度是 O(log(有效挑战目的数量)),而静态跳转总是恒定的),JIT 虚拟机实现起来更简单。于是,我们需要:1)对有效变量跳转目的地做限制;2)激励使用静态而不是动态跳转。为了达到这两个目标,我们定下了以下规则:1)紧接着 push 后的跳转可以跳到任何地方,而不仅是另一个 jump;2)其他的 jump 只能跳转到 JUMPDEST。对跳转的限制是必须的,这样就可通过查看代码中的前一个操作来确定当前是一个静态跳转还是动态跳转。缺乏对静态跳转的需求是激励使用它们的原因。禁止跳转进入 push 数据也会加快 JIT 虚拟机的编译和执行。 LOG:LOG是事件的日志。 CALLCODE:该操作码允许合约使用自己的存储项,在单独的栈空间和 memory 中调用其他合约的 “函数” 。这样可以在区块链上灵活实现标准库代码。 SELFDESTRUCT:允许合约删除它自己,前提是它已经不需要存在了。SELFDESTRUCT 并非立即执行,而是在交易执行完之后执行。这是因为如果允许 SELFDESTRUCT 在执行之后回滚,将会极大地提高缓存的复杂度,不利于高效的 VM 实现。 PC:尽管理论上不需要 PC 操作码,因为所有 PC 操作码的实例都可以根据将 push 操作的索引加入实际程序计数器来代替实现,但使用 PC 可以创建独立代码的位置(可复制粘贴到其他合约的编译函数,如果它们以不同索引结束,不会被打断)。 —- 编译者/作者:远大钱程 玩币族申明:玩币族作为开放的资讯翻译/分享平台,所提供的所有资讯仅代表作者个人观点,与玩币族平台立场无关,且不构成任何投资理财建议。文章版权归原作者所有。 |
V神设计理念公布细数以太坊潜在的优缺点
2021-07-12 远大钱程 来源:区块链网络
相关阅读:
- 基于Phala的隐私应用竟然有这么多?2021-07-12
- IPFS最新消息:FIL近期有哪些利好?落地应用要来了吗?2021-07-12
- 橙链宝哥|币安智能链AnkrNetwork(ANKR)研究报告2021-07-12
- CoinEx智能链上线—CET未来价值不可估量2021-07-12
- 世界银行、国际货币基金组织在G20峰会提出的CBDC倡议2021-07-12

