


作者:宋嘉吉 孙爽 摘要 ChatGPT发布后不久,Meta就开源了类GPT大语言模型LLaMA,此后,Alpaca、Vicuna、Koala等多个大模型诞生,它们以远低于ChatGPT的模型规模和成本,实现了令人瞩目的性能,引发业内人士担忧“谷歌和OpenAI都没有护城河,大模型门槛正被开源踏破,不合作就会被取代”。资本市场也在关注大模型未来竞争格局如何,模型小了是否不再需要大量算力,数据在其中又扮演了什么角色?……本报告试图分析这波开源大语言模型风潮的共同点,回顾开源标杆Linux的发展史,回答这些问题。 共同点一:始于开源。开源≠免费,开源的商业模式至少包括:1、靠服务变现。曾上市、后被IBM收购的Linux企业服务公司红帽即是一例。企业为了更稳定和及时的技术支持,愿意付费。2、靠授权费变现。安卓开源,但谷歌向欧盟使用安卓谷歌套件的厂商收取许可费即是一例。3、许可证、标准和能力评价体系的发展,是开源大模型商用程度深化的催化剂。这波开源大模型采用的许可证协议主要是Apache 2.0和MIT,它们不禁止商用,并且不禁止用户修改模型后闭源,这有助于公司应用此类大模型。 共同点二:参数少、小型化。相较于GPT3+千亿参数超大模型,这波开源大模型的参数量普遍在十亿至百亿级别。目前尚没有一套系统的大模型性能评价体系,其中仅部分任务有公信力较强的评分标准。开源大模型中,Vicuna的能力也较强,在部分任务能达到92% GPT4的效果。总体来说,OpenAI GPT系仍一骑绝尘,但训练成本高,难复现。而开源大模型借助更大标识符训练数据集、DeepSpeed、RLHF等方式,实现低训练成本和高性能,超大模型以下大模型的壁垒正在消失。 共同点三:数据集重视人类指令,并走向商用。ChatGPT相较于GPT3效果大幅提升的重要因素是使用了RLHF(基于人类反馈的强化学习),即在训练中,使用人类生成的答案和对AI生成内容的排序,来让AI“对齐”人类偏好。LLaMA没有使用指令微调,但LLaMA之后的大量大模型使用并开源了指令数据集,并且逐步探索自建指令数据集,而非使用有商用限制的OpenAI的,进一步降低了复现GPT的门槛,扩展了商用可用性。 接下来怎么看开源大模型?站在开源大模型浪潮中,我们注意到两个趋势:1)与多模态融合,清华大学的VisualGLM-6B即是著名开源语言模型ChatGLM的多模态升级版,我们认为,其可基于消费级显卡在本地部署的特性是大势所趋。2)开源模型+边缘计算推动AI商用落地,哈尔滨大学的中文医疗问诊模型“华驼”以及在跨境电商的使用就是案例。 投资建议:我们认为,对大模型的看法应该分时、分层看待。1、短期内,OpenAI的GPT系超大模型仍然超越众开源大模型,因此,应当重点关注与其在股权和产品上深度合作的微软、能获得ChatGPTiosApp收益分成的苹果,以及超大模型的算力服务商英伟达等;2、中长期来看,如果部分开源大模型能力被进一步验证,则应用将快速铺开,大模型对算力将形成正循环;3、其他:边缘算力、大数据公司和开源大模型服务商业态也值得关注。建议关注:1)光模块服务商:中际旭创、新易盛、天孚通信、源杰科技;2)智能模组服务商:美格智能、广和通;3)边缘IDC服务商:龙宇股份、网宿科技;4)AIoT通信芯片及设备厂商:中兴通讯、紫光股份、锐捷网络、菲菱科思、工业富联、翱捷科技、初灵信息;5)应用端标的:恺英网络、神州泰岳、佳讯飞鸿、中科金财等。 风险提示:伦理风险、市场竞争风险、政策法律监管风险。    一、引言 一、引言一篇报道引发了公众对开源大语言模型的强烈关注。 1.1“谷歌和OpenAI都没有护城河,大模型门槛正被开源踏破” “除非谷歌和OpenAI改变态度,选择和开源社区合作,否则将被后者替代”,据彭博和SemiAnalysis报道,4月初,谷歌工程师Luke Sernau发文称,在人工智能大语言模型(Large Language Models,LLM,以下简称“大模型”)赛道,谷歌和ChatGPT的推出方OpenAI都没有护城河,开源社区正在赢得竞赛。 这一论调让公众对“年初Meta开源大模型LLaMA后,大模型大量出现”现象的关注推向了高潮,资本市场也在关注大公司闭源超大模型和开源大模型谁能赢得竞争,在“模型”“算力”“数据”三大关键要素中,大模型未来竞争格局如何,模型小了是否就不再需要大量算力,数据在其中又扮演了什么角色?……本报告试图剖析这波开源大模型风潮的共同点,回顾开源标杆Linux的发展史,回答以上问题,展望大模型的未来。  1.2 开源大模型集中出现,堪称风潮 2月24日,Meta 发布LLaMA开源大模型,此后,市场集中涌现出一批大模型,大致可以分为三类。 1.2.1 “LLaMA系”:表现好,但商用化程度低 LLaMA包括四个不同的参数版本(70亿/130亿/330亿/650亿),不支持商用,指令数据集基于OpenAI,模型表现可与GPT-3持平或优于GPT-3。其中,70亿和130亿参数版拥有包含1万亿个标识符(Token)的预训练数据集;330亿和650亿参数版拥有包含1.4万亿个标识符的预训练数据集。在与GPT-3的对比中,LLaMA-70亿参数版在常识推理任务、零样本任务、自然问题和阅读理解中的表现与GPT-3水平相当,而130亿参数及更高参数的版本模型在以上领域的表现均优于GPT-3。 LLaMA模型本身没有使用指令数据集,但考虑到效果优于GPT-3的ChatGPT使用了人类指令数据集,一批开源大模型在LLaMA模型基础上,使用了OpenAI指令数据集来优化模型的表现,包括Alpaca、GPT4All、Vicuna、Koala、Open Assistant和Hugging Chat。由于OpenAI指令数据集不可商用,因此这批基于LLaMA的开源大模型也都不可商用。 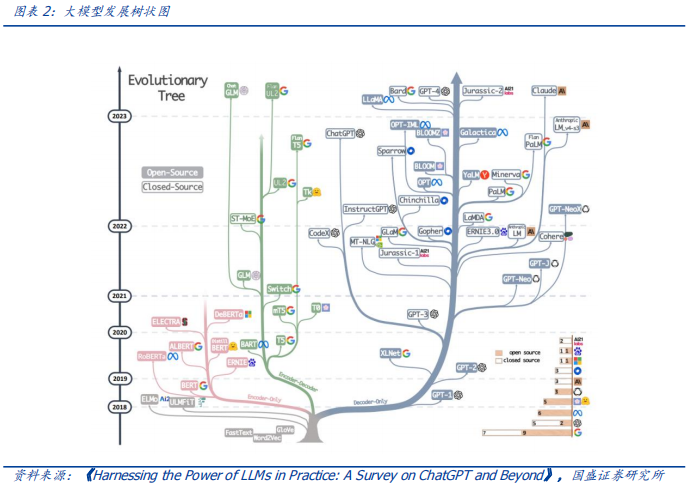 1.2.2 Dolly2.0、RedPajama、StableLM等:商用化程度高 这些大模型没有使用OpenAI指令数据集,因此可以商用,但大多数还在持续开发中。 1.2.3 中文双子星:ChatGLM-6B和MOSS ChatGLM-6B和MOSS分别由清华大学和复旦大学相关研究团体推出,在中文社区知名度较高。 这批模型还具有一些共同点,报告将在下文详述。  二、共同点一:始于开源 二、共同点一:始于开源这波风潮中,不管是模型本身,还是模型所使用的数据集,它们首要的共同点是“开源”。 2.1 为什么要开源? 市场对开源大模型的重要问题是,为什么要开源,这是否会损伤大模型行业的商业模式。我们梳理了部分大模型对开源原因的自述,总结如下。 2.1.1 模型视角:防止大公司垄断,破除商业禁用限制 为了使人工智能研究民主化,弥合开放模型和封闭模型之间的质量差距,破除商业化禁用限制,开源大模型的蓬勃发展有望促进以上目标。 2.1.2 数据视角:保护企业机密,使定制化数据训练成为可能 保障数据隐私,允许企业定制化开发。对于许多行业而言,数据是企业的命脉,大模型的开源使得企业可以将自己的数据集在大模型上进行训练,同时做到对数据的控制,保护企业数据隐私。同时,开源大模型允许企业的开发人员在模型的基础上进行定制化开发,定向训练数据,也可以针对某些主题进行过滤,减少模型体量和数据的训练成本。 2.1.3 算力视角:降低算力成本,使大模型的使用“普惠化” 开源大模型节省了训练阶段的算力消耗,为企业降低算力成本,推动大模型使用“普惠化”。算力总需求=场景数*单场景算力需求。在大模型的训练和使用中,算力消耗分为两部分场景,即训练成本消耗及推理成本消耗。 就训练成本而言,大模型的训练成本高,普通企业的算力资源难以承受,而开源大模型主要节省了企业预训练阶段的算力。但由于不同垂类的训练场景更加丰富,所以整体训练需求是增长的。就推理成本而言,大模型在参数体量庞大的情况下,其推理成本也很高,普通公司难以维持其日常开销,因此,降低模型参数体量可进而降低企业在使用模型时的推理成本。2.2 开源,需要什么土壤? 开源大模型的蓬勃发展并非没有先例,全球规模最大的开源软件项目——Linux有类似的故事。研究Linux的发展史,对展望开源大模型的未来,有借鉴意义。 2.2.1 从开源标杆Linux说开去 Linux 是一款基于 GNU 通用公共许可证(GPL)发布的免费开源操作系统。所有人都能运行、研究、分享和修改这个软件。经过修改后的代码还能重新分发,甚至出售,但必须基于同一个许可证。而诸如 Unix 和 Windows等传统操作系统是锁定供应商、以原样交付且无法修改的专有系统。 许多全球规模最大的行业和企业都仰赖于 Linux。时至今日,从维基百科等知识共享网站,到纽约证券交易所,再到运行安卓(一个包含免费软件的 Linux 内核专用发行版)的移动设备,Linux无处不在。当前,Linux不仅是公共互联网服务器上最常用的操作系统,还是速度排名前 500 的超级电脑上使用的唯一一款操作系统。 服务器市场,Linux市占率已经远超操作系统“鼻祖”Unix,“Linux时刻”发生。以中国市场为例,根据赛迪顾问数据,按照装机量统计,在服务器架构上,Linux是市场主流,占据绝对领先地位,市场占有率达到 79.1%。Windows 市场占有率降至 20.1%,Unix 市场占有率仅剩 0.8%。 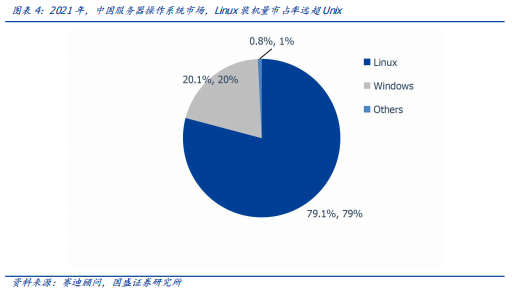 2.2.2 Linux并非一己之作,借力于社区身后的开源历史 Unix开源过,为Linux提供了火种Unix,现代操作系统的鼻祖。操作系统是指直接管理系统硬件和资源(如 CPU、内存和存储空间)的软件,它位于应用与硬件之间,负责在所有软件与相关的物理资源之间建立连接。而Unix被许多观点认为是现代操作系统的鼻祖。 Unix曾开源。世界上第一台通用型计算机诞生于1946年,而Unix开发于1969年。在长达十年的时间中,UNIX拥有者AT&T公司以低廉甚至免费的许可将Unix源码授权给学术机构做研究或教学之用,许多机构在此源码基础上加以扩展和改进,形成了所谓的“Unix变种”。后来AT&T意识到了Unix的商业价值,不再将Unix源码授权给学术机构,并对之前的Unix及其变种声明了著作权权利 Unix回归闭源之后太贵,促成了Linux的开发Linux由Linux Torvalds于1991年设计推出,当时他还在读大学,认为当时流行的商业操作系统Unix太贵了,于是基于类Unix操作系统Minix开发出了Linux,并将其开放给像自己这样负担不起的团队。 仅用于教学的Minix,启发了Linux的开发在AT&T将源码私有化后,荷兰阿姆斯特丹自由大学教授塔能鲍姆为了能在课堂上教授学生操作系统运作的实务细节,决定在不使用任何AT&T的源码前提下,自行开发与UNIX相容的作业系统,以避免版权上的争议。他以小型UNIX(mini-UNIX)之意,将它称为MINIX。第一版MINIX于1987年释出,只需要购买它的磁片,就能使用。在Linux系统还没有自己的原生档案系统之前,曾采用Minix的档案系统。 开源社区、许可证与标准助力从开始就开源。1991年8月,Linux创始人Linus Torvalds将Linux发到Minix Usenet新闻组。随后他将Linux发布到FTP网站上,因为他想让更多人一起来开发这个内核。 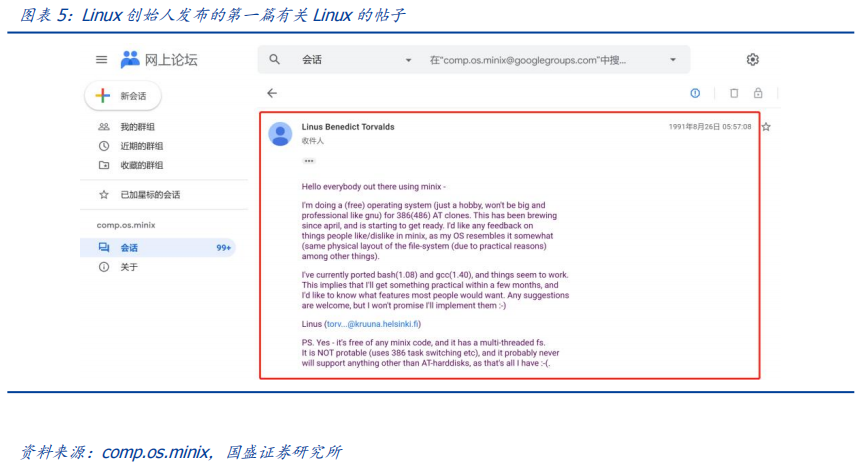 许可证助力生态开枝散叶、生生不息。Linux基于GNU GPL许可证(GNU’s Not Unix General Public License,革奴计划通用公共许可证)模式。GPL许可证赋予“自由软件”赋予用户的四种自由,或称“Copyleft(公共版权)”: 自由之零:不论目的为何,有“使用”该软件的自由。自由之一:有“研究该软件如何运作”的自由,并且得以“修改”该软件来符合用户自身的需求。可访问源代码是此项自由的前提。自由之二:有“分发软件副本”的自由,所以每个人都可以借由散布自由软件来敦亲睦邻。自由之三:有将“公布修订后的版本”的自由,如此一来,整个社群都可以受惠。可访问源代码是此项自由的前提。GPL许可证要求GPL程序的派生作品也要在遵循GPL许可证模式。相反,BSD式等许可证并不禁止派生作品变成专有软件。GPL是自由软件和开源软件的最流行许可证。遵循GPL许可证使得Linux生态能生生不息,不至于走进无法继续发展的“死胡同”。 标准对内使生态“形散而神不散”,对内拥抱“巨鲸”。 对内统一标准。Linux制定了标准LSB(Linux Standard Base,Linux标准基础)来规范开发,以免各团队的开发结果差异太大。因此,各Linux衍生开发工具只在套件管理工具和模式等方面有所不同。我们认为,这使得Linux开源社区的发展“形散而神不散”,使Linux生态的发展不至于分崩离析。对外兼容Unix。为了让Linux能兼容Unix软件,Linus Torvalds参考POSIX(Portable Operating System Interface,可携带式操作系统接口)标准修改了Linux,这使得Linux使用率大增。该标准由IEEE(Institue of Electrical and Electronics Engineers,电气和电子工程师协会)于20世纪90年代开发,正是Linux的起步阶段,它致力于提高Unix操作系统环境与类Unix操作系统环境下应用程序的可移植性,为Linux的推广提供了有利环境。2.3 开源了,还怎么赚钱? 市场对“开源”的核心疑问是商业模式。“开源”本身免费,但“开源”作为土壤,“开源社区”孕育出了各种商业模式,从Linux的生态中可以学习到这一点。 2.3.1 红帽公司(Red Hat):服务至上 红帽公司(Red Hat)是Linux生态的领军企业,超过 90% 的《财富》500 强公司信赖红帽公司,红帽作为公司的商业价值巨大。1993年,红帽成立,1999年,红帽即在纳斯达克上市,红帽招股书援引 IDC 的数据称,截止到 1998 年所有经授权的新安装 Linux 操作系统中,有 56% 来自红帽;2012 年,红帽成为第一家收入超过 10 亿美元的开源技术公司;2019 年,IBM 以约 340 亿美元的价格收购了红帽。 关于Linux和红帽的商业模式,就像好奇心日报打的比方,某种意义上,开源的Linux内核像免费、公开的菜谱,红帽们像餐厅,人们仍然愿意去餐厅品尝加工好的菜肴和享受贴心的服务。红帽面向企业提供Linux操作系统及订阅式服务,主要服务内容包括:1、24*7技术支持;2、与上游社区和硬件厂商合作,支持广泛的硬件架构,如 x86、ARM、IBM Power等;3、持续的漏洞警报、定向指导和自动修复服务;4、跨多个云的部署;5、实时内核修补、安全标准认证等安全防护功能;6、检测性能异常、构建系统性能综合视图,并通过预设调优配置文件应用等。 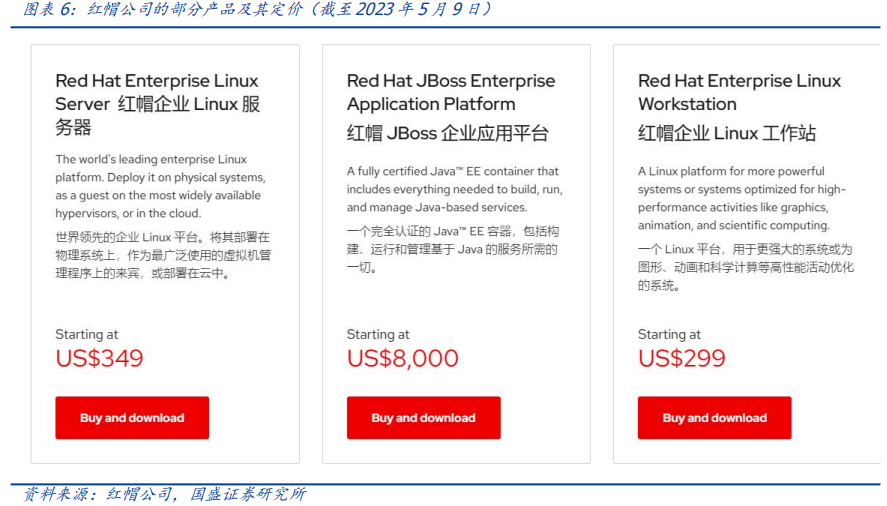 2.3.2 安卓系统(Android):背靠谷歌,靠广告变现 根据Statcounter数据,截至2023年4月,安卓系统(Android)是全球第一手机操作系统,市占率高达69%,远超第二名(iOS,31%)。安卓基于Linux内核开发,2005年被谷歌收购。随后,谷歌以Apache免费开放源代码许可证的授权方式,发布了安卓的源代码,使生产商可以快速推出搭载安卓的智能手机,这加速了安卓的普及。 而关于商业模式,安卓手机预装的诸多服务由谷歌私有产品提供,例如地图、Google Play应用商店、搜索、谷歌邮箱(Gmail)……因此,尽管安卓免费、开源,但谷歌仍能通过其在移动市场“攻城略地”,将用户流量变现。 谷歌还直接向安卓手机厂商收取授权费,从2018年10月29日开始,使用安卓系统的手机、平板电脑的欧盟厂商使用谷歌应用程序套件,必须向谷歌支付许可费,每台设备费用最高达40美元(约277元)。 2.4 开源大模型主流许可证支持商用 开源社区已经有GPL、BSD、Apache等知名许可证。大模型方面,我们注意到,2023年2月发布的、引领了大模型开源浪潮的LLaMA禁止商用,仅可用于研究,MetaAI将根据具体情况,授予公务员、社会团体成员、学术人员和行业研究实验室,访问该模型的权限。其中,LLaMA的推理代码基于GPL3.0许可证,这意味着:1)他人修改LLaMA的推理代码后,不能闭源;2)新增代码也必须采用GPL许可证。不过,我们注意到,部分开发人员在LLaMA基础之上开发的变体模型,有不同类型的许可证。例如,基于nanoGPT的LLaMA实现Lit-LLaMA新增了部分模型权重,这部分模型采用的许可证是Apache2.0。 开源大模型采用的协议主要是Apache 2.0 和MIT许可证。Alpaca、Vicuna、Dolly、OpenAssistant和MOSS均采用Apache 2.0许可证,Koala和GPT4all采用MIT许可证。这两个许可证均允许商用。但令人惋惜的是,Alpaca、Vicuna、Koala和GPT4all因OpenAI或LLaMA限制无法商用。同时,值得注意的是,Apache2.0和MIT许可证均允许再修改源码后闭源,公司可以在开源大模型基础上开发自己的模型,或对公司更有吸引力。 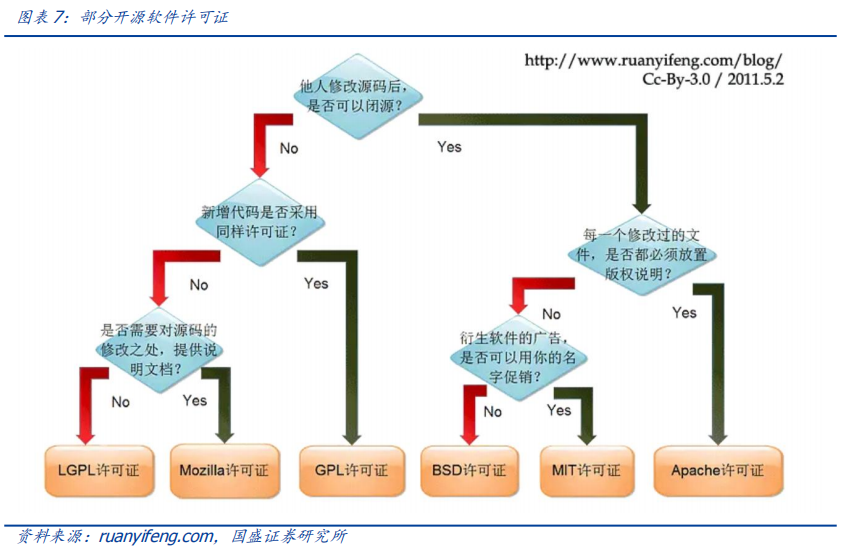 三、共同点二:开源大模型参数少、小型化 三、共同点二:开源大模型参数少、小型化“模型参数的大小”与“模型对算力的需求”正相关。 3.1 超大模型和大模型分别多大? 预训练赋予模型基本能力。在自然语言处理(NLP)中,预训练是指在特定任务微调之前,将语言模型在大量文本语料库上训练,为模型赋予基本的语言理解能力。在预训练过程中,模型被训练以根据前面的上下文预测句子中的下一个单词。这可以通过掩盖一些输入中的单词并要求模型预测它们的方式进行,也可以采用自回归的方法(例如GPT),即根据句子中的前面单词预测下一个单词。 预训练模型通常包括大量的参数和对应的预训练数据(通常用标识符即Token的数量衡量)。2017年谷歌大脑团队Transformer(变换器)模型的出现,彻底改变了NLP的面貌,使得模型可以更好地理解和处理语言,提高NLP任务的效果和准确性。 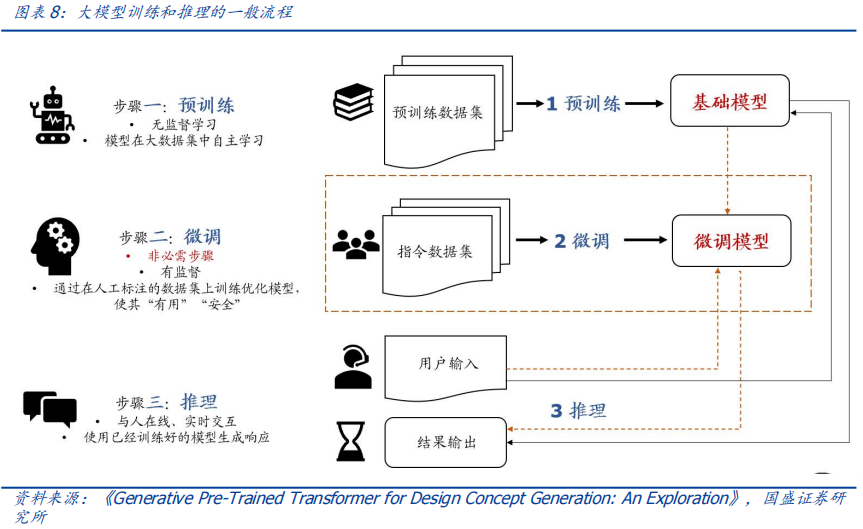 超大模型和大模型分别多大?语言模型的大小是根据其参数量来衡量的,参数量主要描述了神经元之间连接强度的可调值。目前一般大语言模型参数量在几十到几百亿之间,超过千亿参数的我们称为“超大模型”,例如GPT-3(1750亿参数)。 3.2 GPT系超大模型能力最强,但难复现 大模型的性能评价标准并没有统一。一个重要原因是大模型生成内容的任务种类多,不同的应用场景和任务可能需要不同的指标和方法去评估模型的表现。其中部分任务可能有公信力较强的评分标准,如机器翻译中的BLEU,但大部分任务缺乏类似标准。 模糊共识是超大模型性能好。大语言模型目前的发展趋势是越来越大(详见下图),原因是大模型在预训练后就具有较好通用性和稳定性。例如,谷歌团队的超大模型PaLM(5400亿参数),在零样本和少量样本测试中均有良好的成绩(详见下图),并且随着其训练标识符数量的上升,性能仍能提升。这也不难理解,简单来说,模型见得多了,自然会的也多了。 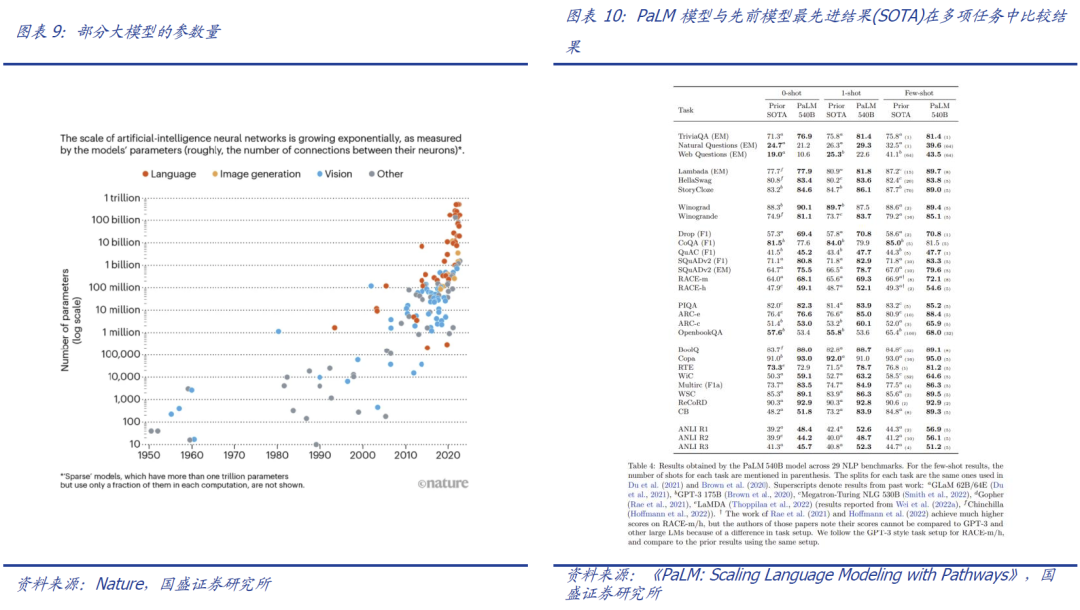 “同行评议”,GPT系大模型“风华绝代”。当前,OpenAI GPT系的超大模型拥有着强大的能力和广泛的应用,在处理自然语言任务时具有高准确性和强大的表达能力,其在文本生成、问答系统、机器翻译等多个领域都取得了出色效果,成为了当前自然语言处理领域的标杆之一,被各类大模型当作比较基准。复现ChatGPT的门槛并没有降低,开源大模型大部分仅在某些方面有较好的表现,整体质量与ChatGPT仍不可比,尚需观望。 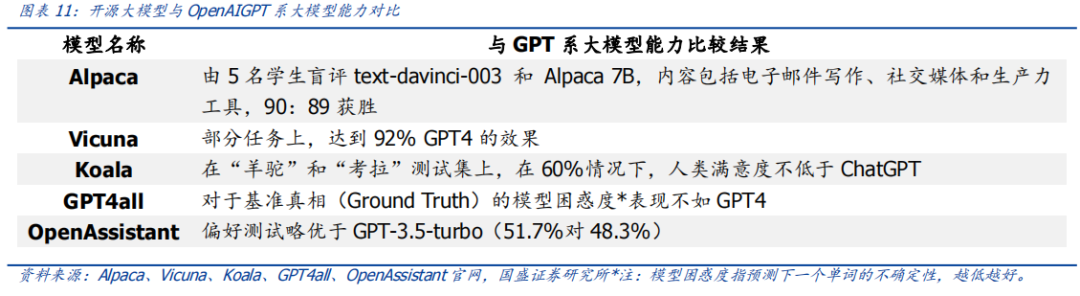 近段时间以来,我们还注意到如下评价体系,评价方法主要包括机器自动评测(如使用GPT4)、人类盲评等,我们重点介绍其中部分及其测评结果,但不论哪种评价体系,GPT系大模型都一骑绝尘。 海外伯克利大学Chatbot Arena借鉴游戏排位赛机制,让人类对模型两两盲评;开源工具包Zeno Build,通过Hugging Face 或在线 API ,使用 Critique 评估多个大模型。海内SuperCLUE中文通用大模型综合性评测基准,尝试全自动测评大模型;C-Eval采用1.4万道涵盖52个学科的选择题,评估模型中文能力,类似标准尚需时间和市场的检验。3.2.1 Vicuna:利用GPT-4评估 目前大部分开源大模型性能未进行系统评价,更多处在起步试验阶段。在对性能进行评价的开源大模型中,Vicuna的报告中利用GPT-4进行的评估相对较为系统,结果也最令人瞩目。 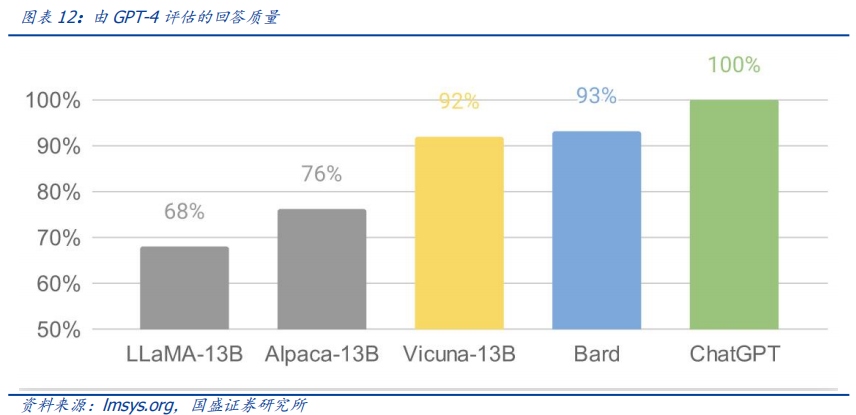 3.2.2 Zeno Build测评:较新,较全面 Zeno Build对GPT-2、LLaMA、Alpaca、Vicuna、MPT-Chat、Cohere Command、ChatGPT(gpt-3.5-turbo)七个模型测评,结果与GPT-4评价结果相近。ChatGPT有明显优势,Vicuna在开源模型中表现最佳。 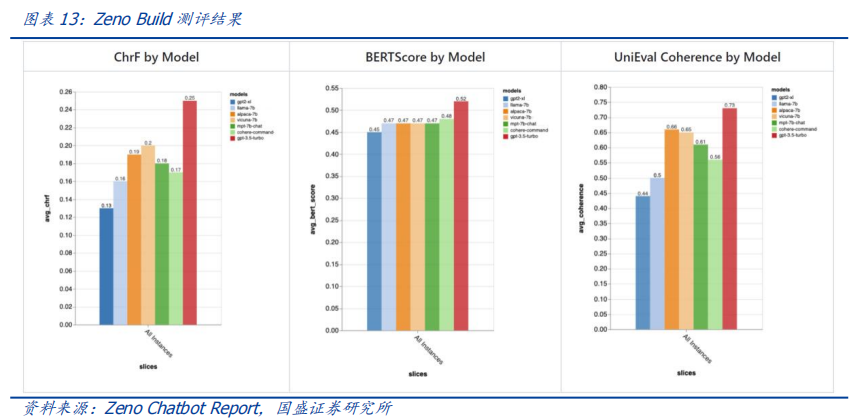 3.2.3 C-Eval:全面的中文基础模型评估套件 C-Eval评估结果显示,即便是在中文能力上,GPT-4也是一骑绝尘,但GPT-4也仅能达到67%的正确率,目前大模型的中文处理能力尚有很大提升空间。 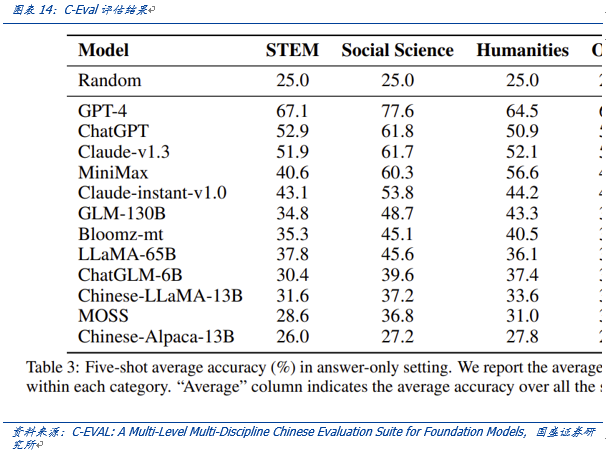 3.2.4 GPT系超大模型训练成本高,短期内难复现 ChatGPT所需算力和训练成本可观。不考虑与日活高度相关的推理过程所需的算力,仅考虑训练过程,根据论文《Language Models are Few-Shot Learners》的测算,ChatGPT的上一代GPT-3 (1750亿参数版)所需的算力高达3640PF-days(即假如每秒做一千万亿次浮点运算,需要计算3640天),已知单张英伟达A100显卡的算力约为0.6PFLOPS,则训练一次GPT-3(1750亿参数版),大约需要6000张英伟达A100显卡,如果考虑互联损失,大约需要上万张A100,按单张A100芯片价格约为10万元,则大规模训练就需要投入约10亿元。OpenAI在GPT-3(1750亿参数)的训练上花费了超过400万美元,而为了维持ChatGPT和GPT4(参数量未公布,预计更高)的运转,每个月理论上更高。 3.3 开源大模型性价比高,超大模型以下大模型的壁垒正在消失 开源大模型小型化趋势明显,参数约为百亿级别,成本降低乃题中之义。开源大模型通常具有较少的参数,在设计、训练和部署上,需要的资源和成本都相对较低。这波开源大模型的参数普遍较小,均在十亿~百亿级别左右。 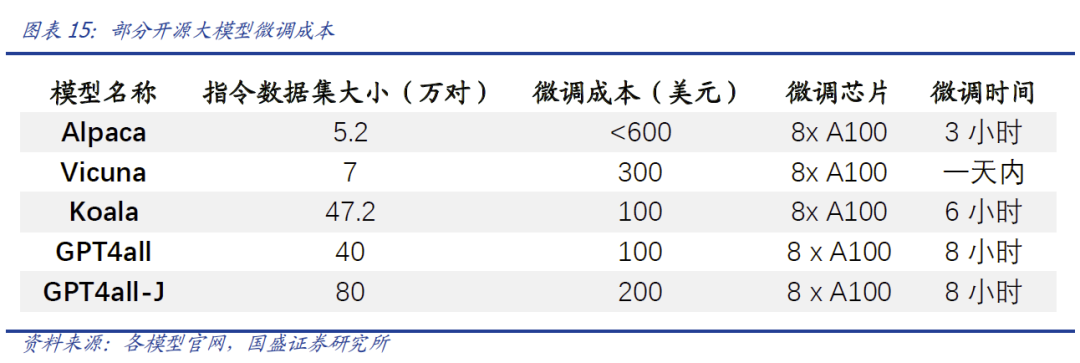 “船小好调头”,基于已有的开源预训练模型进行微调也是开源大模型的优势之一。在预训练模型基础上进行微调和优化,以适应不同的任务和应用场景,这种方法不仅可以大大缩短模型的训练时间和成本,而且还可以提高模型的性能和效率。 更多标识符训练数据和新技术,让超大模型以下的大模型壁垒趋于消失。LLaMA被“开源”,让大家都有了一个可上手的大模型,并且随着DeepSpeed、RLHF等技术的发展,几百亿的模型可以部署在消费级GPU上。 更多标识符训练数据可能比更多参数重要:DeepMind发表于2022年3月29日的研究《Training Compute-Optimal Large Language Models(在计算上优化计算大语言模型)》向我们揭示了模型大小和训练数据规模之间的关系:大模型往往训练不足,导致大量算力的浪费。用更小的模型更充分地训练,能达到比大模型更好的性能。例如DeepMind的Chinchilla,模型仅有700亿参数,经过1.4万亿标识符训练数据集的训练,在测试中效果优于DeepMind的Gopher (2800亿参数,3000亿标识符训练数据集)和OpenAI的GPT-3(1750亿参数,3000亿标识符训练数据集)。为了更好地实现模型性能,模型参数量每翻一倍,标识符训练数据集的规模也应该随之翻一倍。更小的模型,也意味着更小的下游微调和推理成本。DeepSpeed技术:可以显著减少训练大模型的时间和成本;RLHF(基于人类反馈的强化学习):可以以较小的标识符训练量提高模型的性能和准确性。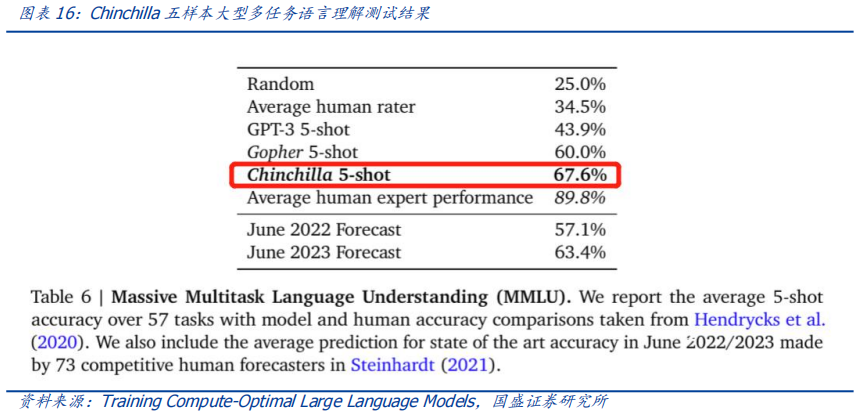 四、共同点三:开源大模型数据集重视人类指令,并自立门户 四、共同点三:开源大模型数据集重视人类指令,并自立门户“数据集的大小”也与“模型所需的算力”正相关。 4.1 学习ChatGPT方法论,引入人类指令数据集 微调是提升特定性能的捷径。微调是指在已经预训练的模型上,使用具有标注数据的特定任务数据集,进一步小规模训练。微调可以以较小的算力代价,使模型更加适应特定任务的数据和场景,从而提高模型的性能和准确性。目前微调多为指令微调,指令数据集逐渐成为开源大模型的标配。 RLHF(Reinforcement Learning from Human Feedback,基于人类反馈的强化学习),是一种新兴的微调方法,它使用强化学习技术来训练语言模型,并依据人类反馈来调整模型的输出结果。RLHF(基于人类反馈的强化学习)是ChatGPT早期版本GPT3所不具备的功能,它使得只有13亿参数的InstructGPT表现出了比1750亿参数GPT-3更好的真实性、无害性和人类指令遵循度,更被标注员认可,同时不会折损GPT-3在学术评估维度上的效果。 RLHF(基于人类反馈的强化学习)分为三个步骤:1)监督微调(SFT):让标注员回答人类提问,用这一标注数据训练GPT;2)奖励模型(RM)训练:让标注员对机器的回答排序,相较于第一步由标注员直接撰写回答的生成式标注,排序作为判别式标注的成本更低,用这一标注训练模型,让它模拟人类排序;3)无人类标注,用近端策略优化算法(PPO)微调模型。 这三个步骤对应的数据集的大小分别为1.3万个、3.3万个、3.1万个。 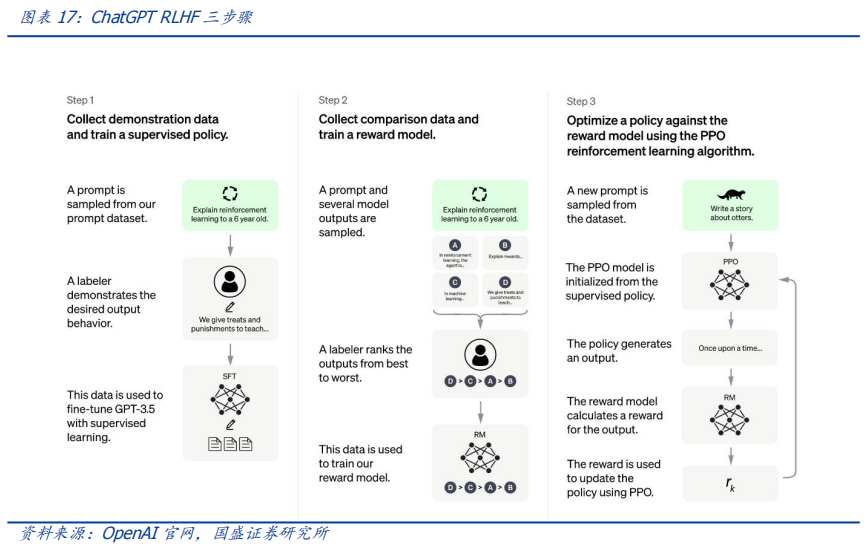 对于具有大量数据和一定算力的公司来说,使用自己的数据进行微调可以展现出模型的特化能力,并且用较小的算力达成接近大模型的效果。如多校联合开发的Vicuna语言模型,基于Meta的LLaMA-130亿参数版模型,对7万条用户分享的ChatGPT对话指令微调,部分任务上,达到了92%的GPT4的效果。在通用性和稳定性上无法超过超大模型,但可以通过微调强化其某些方面的能力,性价比要更高,更适合中小公司应用。 4.2 数据集走向商用 数据集是语言模型发展的重要基础和支撑,通常是由公司或组织自主收集、整理或直接购买获得。相比之下,开源数据集大多由社区或学术界共同维护的,其数据量和种类更加丰富,但可能存在一定的数据质量问题和适用性差异。 4.2.1 预训练数据集少量可商用 预训练数据集开源对模型商用至关重要。在后LLaMA时代,开源大模型犹如雨后春笋般涌现,但很快大家便发现由于LLaMA和OpenAI的限制,基于其开发的模型无法商用(Alpaca、Koala、GPT4All、Vicuna),为了打破这一局面,Dolly2.0率先出手,“为了解决这个难题,我们开始寻找方法来创建一个新的,未被“污染”的数据集以用于商业用途。”随后Red Pajama和MOSS接踵而至。 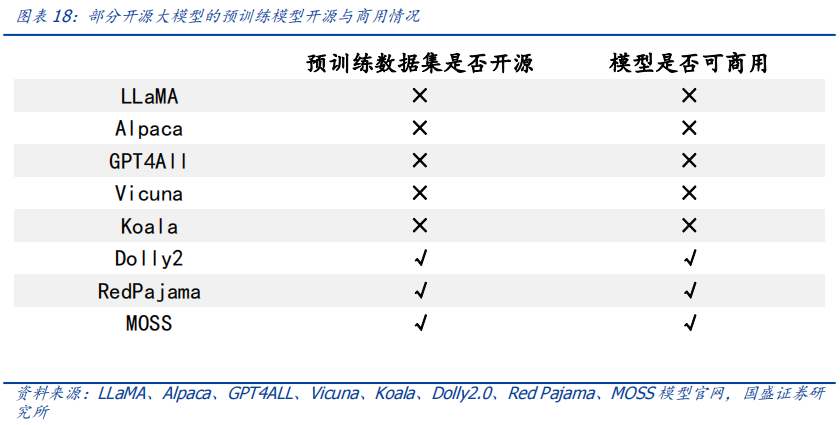 4.2.2 指令数据集部分可商用 打造开源生态,各取所需。在早期开源项目中,因其指令数据及多来自ChatGPT生成或对话内容,受OpenAI限制无法商用。除去研究用途微调外,目前越来越多模型选择自己构建指令数据集来绕开这一限制。 指令数据集多样化,部分模型的指令数据集可商用化。按照上文对此批集中出现的大模型的分类,除去LLaMA、基于LLaMA开发出的模型以及StableLM使用OpenAI的指令数据集外,其余大模型的指令数据集均不基于OpenAI,也因此这些大模型的指令数据集可商用化,这会加快推动使用且重视RLHF(基于人类反馈的强化学习)训练范式的此类大模型的更迭与发展。  五、展望 五、展望我们注意到开源大模型走向相似的路口。 5.1 多模态化:助力通用人工智能(AGI)发展 多模态开源大模型开始出现,将大模型推向新高潮,助力人类走向通用人工智能。多模态即图像、声音、文字等多种模态的融合。多模态模型基于机器学习技术,能够处理和分析多种输入类型,可以让大模型更具有通用性。基于多领域知识,构建统一、跨场景、多任务的模型,推动人类走向通用人工智能(Artificial General Intelligence,AGI)时代。 5.1.1 ImageBind闪亮登场,用图像打通6种模态 ImageBind开源大模型可超越单一感官体验,让机器拥有“联想”能力。5月9日,Meta公司宣布开源多模态大模型ImageBind。该模型以图像为核心,可打通6种模态,包括图像(图片/视频)、温度(红外图像)、文本、音频、深度信息(3D)、动作捕捉传感(IMU)。相关源代码已托管至GitHub。该团队表示未来还将加入触觉、嗅觉、大脑磁共振信号等模态。 从技术上讲,ImageBind利用网络数据(如图像、文本),并将其与自然存在的配对数据(如音频、深度信息等)相结合,以学习单个联合嵌入空间,使得ImageBind隐式地将文本嵌入与其他模态对齐,从而在没有显式语义或文本配对的情况下,能在这些模态上实现零样本识别功能。 目前ImageBind的典型用例包括:向模型输入狗叫声,模型输出狗的图片,反之亦可;向模型输入鸟的图片和海浪声,模型输出鸟在海边的图片,反之亦可。  5.1.2 开源大模型的多模态探索集中于图片,但进展飞快 当前开源大模型在多模态的探索仍处于初级阶段,除ImageBind打通了六种模态外,多数仍在探索文本与图像的融合,但速度相当快,我们梳理了其中部分。 VisualGLM-6B:可在消费级显卡上本地部署团队:VisualGLM-6B是开源大语言模型ChatGLM-6B的多模态升级版模型,支持图像、中文和英文,由清华大学知识工程和数据挖掘小组发布。技术:VisualGLM-6B是由语言模型ChatGLM-6B与图像模型BLP2-Qformer结合,二者结合后的参数为78亿(62亿+16亿)。该模型使用的预训练数据集是CogView数据集中3000万个高质量的“中文图像-文本”和3亿个“英文图像-文本”对。在微调阶段,该模型在长视觉问答数据集上进行训练,以生成符合人类偏好的答案。性能:根据DataLearner,VisualGLM-6B集成了模型量化技术,用户可以在消费级显卡上本地部署模型,INT4量化级别只需要8.7G的显存。这意味着即使是拥有游戏笔记本的用户也可以快速且私密地部署这个模型,这在此类大小的ChatGPT类模型中尚属首次。UniDiffuser:为多模态设计的概率建模框架UniDiffuser团队:清华大学计算机系朱军教授带领的 TSAIL 团队于3月12日公开的一篇论文《One Transformer Fits All Distributions in Multi-Modal Diffusion at Scale》,进行了一些多模态的探索。技术:UniDiffuser采用该团队提出的基于Transformer的网络架构 U-ViT,在开源的大规模图文数据集LAION的50亿参数版上,训练了一个十亿参数量的模型,使得其能够高质量地完成多种生成任务。功能:简单来讲,该模型除了单向文生图,还能实现图生文、图文联合生成、无条件图文生成、图文改写等多种功能,实现了任意模态之间的相互转化。LLaVA:部分指令表现可比肩GPT-4团队:由威斯康星大学麦迪逊分校,微软研究院和哥伦比亚大学共同出品的LLaVA,在GitHub上开源了代码、模型和数据集。技术:LLaVA是一个端到端的多模态大模型,它连接了一个视觉编码器和大语言模型,用于通用的视觉和语言理解。功能:以文本为基础的任务:LLaVA可以处理并分析文本,允许用户问问题,可以和用户交谈,或者完成用户输入的任务,比如提炼文件概要、情感分析、实体识别等。以图像为基础的任务:LLaVA可以分析图像,描述图像,进行物体识别,分析理解场景。性能:早期实验表明,LLaVA的多模态聊天能力有时在未见过的图像/指令上都能输出比肩GPT-4的表现,在合成的多模态指令跟随数据集上与GPT-4相比,获得了85.1%的相对分数。MiniGPT-4:脱胎于LLaMA的多模态开源大模型,个人用户的GPT-4“平替”团队:多模态GPT-4大模型的发布,将大众对于大模型的热情推到了一个新的高潮。但是GPT-4并没有完全免费开放给个人,要想使用GPT-4,要么需要通过官方的邀请,要么需要升级到付费账号。但即使付费,一些地区也无法进行相关服务的购买。在这种环境下,阿布杜拉国王科技大学的Deyao Zhu、Jun Chen等人于4月23日发布了MiniGPT-4,旨在将来自预训练视觉编码器的视觉信息与先进的大语言模型结合。技术:具体来说,MiniGPT-4采用了与BLIP-2相同的预训练视觉组件,其中该组件由EVA-CLIP的ViT-G/14和Q-Former组成,同时使用大语言模型Vicuna调优,可以执行各种复杂的语言任务。功能:MiniGPT-4可实现许多玩法,如上传一张海鲜大餐照片,即可得到菜谱;上传一张商品效果图,即可获得一篇带货文案;手绘一个网页,即可得到对应的HTML代码。据使用过的人士反馈,MiniGPT-4整体效果不错,但目前对中文支持还有待提高。mPLUG-Owl:模块化多模态大模型团队:mPLUG-Owl是阿里巴巴达摩院mPLUG系列的最新工作,延续mPLUG系列的模块化训练思想,将语言大模型迁移为多模态大模型。技术:mPLUG-Owl采用 CLIP ViT-L/14 作为视觉基础模块,采用LLaMA初始化的结构作为文本解码器,采用类似 Flamingo的Perceiver Resampler结构对视觉特征进行重组。此外,mPLUG-Owl第一次针对视觉相关的指令评测提出了全面的测试集OwlEval。功能:mPLUG-Owl具有很强的多轮对话能力、推理能力及笑话解释能力。此外,研究团队还观察到mPLUG-Owl初显一些意想不到的能力,比如多图关联、多语言、文字识别和文档理解等能力。性能:实验证明mPLUG-Owl在视觉相关的指令回复任务上优于BLIP2、LLaVA、MiniGPT4。5.2 专业化:下游生态发力,针对特定任务微调模型 大模型开源化为下游生态的蓬勃生长提供了绝佳机会,在细分产业的开发下,大模型开始在特定任务上深化开发,改变人类生活。自开源大模型LLaMA推出后,基于LLaMA预训练模型微调的下游专业化模型开始浮现,例如医疗问诊领域中的华驼。 团队:华驼(Hua Tuo)是基于中文医学知识的LLaMa指令微调模型,在智能问诊层面表现出色,可生成一些更为可靠的医学知识回答。在生物医学领域,已发布的大语言模型模型因为缺乏一定的医学专业知识语料而表现不佳。4月14日,哈尔滨工业大学一团队发布了其对LLaMa模型进行指令微调后得到的、针对医学领域的、开源智能问诊模型Hua Tuo。技术:LLaMA拥有70亿~650亿参数等多个版本,为了更快速、高效地训练,节约训练成本,华驼采用了LLaMA70亿参数版本作为基础模型。为了保证模型在医学领域回答问题的准确性,研究人员通过从中文医学知识图谱CMeKG中提取相关的医学知识,生成多样的指令数据,并收集了超过8000条指令数据进行监督微调,以确保模型回答问题的事实正确性。 性能:在模型效果上,HuaTuo与其他三个基准模型进行了比较。为了评估模型性能,研究人员招募了五名具有医学背景的专业医师,在安全性、可用性、平稳性(SUS)三个维度上进行评估。SUS刻度从1(不可接受)到3(好),其中2表示可接受的响应。平均SUS得分如下图所示。结果表明,HuaTuo模型显著提高了知识可用性,同时没有太多地牺牲安全性。 性能:在模型效果上,HuaTuo与其他三个基准模型进行了比较。为了评估模型性能,研究人员招募了五名具有医学背景的专业医师,在安全性、可用性、平稳性(SUS)三个维度上进行评估。SUS刻度从1(不可接受)到3(好),其中2表示可接受的响应。平均SUS得分如下图所示。结果表明,HuaTuo模型显著提高了知识可用性,同时没有太多地牺牲安全性。 华驼或将是未来开源大模型下游的特定任务模型发展的范式,即采用低参数体量的小型开源大模型作为基础模型,加之以特定专业领域的数据进行训练,得到表现更好的细分领域模型。 六、投资建议开源大模型的发展影响深远,本报告选取其中部分可能受益的方向,提请市场关注。 6.1 微软:与OpenAI深度合作 我们认为,短期内,ChatGPT系仍是能力最强的大模型,与其深度合作的微软将受益。 股权上,根据《财富》杂志报道,在OpenAI的第一批投资者收回初始资本后,微软将有权获得OpenAI 75%利润,直到微软收回投资成本(130亿美元);当OpenAI实现920亿美元的利润后,微软的份额将降至49%。与此同时,其他风险投资者和OpenAI的员工,也将有权获得OpenAI 49%的利润,直到他们赚取约1500亿美元。如果达到这些上限,微软和投资者的股份将归还给OpenAI非营利基金会。产品上,除了让搜索引擎必应(Bing)整合ChatGPT,2023年1月,微软宣布推出Azure OpenAI服务,Azure 全球版企业客户可以在云平台上直接调用OpenAI模型,包括 GPT3.5、Codex 和 DALL.E模型,其后不久,微软宣布将GPT4整合到了新必应和Office升级版Copilot上。6.2 英伟达:开源大模型带动应用风起,算力需求狂飙 算力服务是开源大模型浪潮中受益确定性较强的方向,在软硬件一体化方面具有明显的领先优势,是当前AI算力的领头羊。 6.2.1 超大模型对算力的需求将保持高增长 超大模型质量优势突出,市场将持续追捧,其对算力的需求会一直增长。超大型模型具有强大的表达能力和高准确性,在质量上具有优势,市场将持续追捧这种模型。超大模型规模、数据集和日活持续扩大,所需算力将持续增多。 6.2.2 开源大模型的快速追赶也将利好算力 短期内,市场对开源大模型持观望态度。开源大模型在通用性上表现较差,短时间内无法与大型模型抗衡,加之目前难以系统评价模型的具体性能,市场对开源大模型持观望态度,等待它们证明自己的性能和优势。 中长期看,开源大模型有望进一步提高性能,从而在市场上占据更大的份额。相较于超大模型,开源大模型具有更低的算力需求和更易于部署的特点,还可以通过快速微调等方式,针对某些专业领域优化,具备一定吸引力和实用性。在中长期内,如果有开源大模型能够接近或超越ChatGPT在质量上的表现,那么市场对这类模型的需求可能会迅速上升。相应地,这类算力需求会很快起量。 6.2.3 催化剂:开源大模型许可证、标准和能力评价体系的发展 许可证:我们认为,开源社区发展已久的许可证体系,丰富了开发者的选择,有助于大模型选择适合自己的许可证,从而推动商业应用。大模型的繁荣发展,显然将带动市场对算力的需求。标准:我们预计,大模型社区或许还将产生类似于Linux开发标准LSB的标准,适当的标准化将使得大模型的生态不至于过于分散。我们看好开源社区源源不断的生命力对英伟达等算力服务商业绩的推动。大模型能力评价体系:有公信力的大模型能力评价体系将有助于市场快速分辨大模型的能力,有助于大模型赛道的发展。6.3 Meta:开源“急先锋”,受益于开源生态 回顾安卓的发展史,我们看好“谷歌-安卓”体系中的类谷歌角色,在该体系中,谷歌作为开源操作系统安卓的开发商,将开源作为激励生态上下游发展的工具,增强自身专有服务在终端客户的曝光度。 映射到大模型,我们认为,开源了LLaMA的Meta,可能通过LLaMA,加深与下游大模型开发厂商的合作,将自身体系中的专有产品,绑定销售给客户。 6.4 其他 6.4.1 边缘算力+开源模型:AI应用的落地加速器 边缘算力可以将推理计算放置用户的设备上,不仅能够提高数据处理的速度和效率,从而降低推理的成本,还能够保护用户的隐私和安全。 智能模组:作为承载边缘算力的最佳模式,是未来具身智能产品放量下最具有确定性和弹性的品种。建议关注美格智能、广和通。边缘IDC:凭借时延和成本优势,是满足“阶梯形”算力分布的一种有效补充。建议关注龙宇股份、网宿科技。光模块:中际旭创、新易盛、天孚通信、源杰科技。传统的IoT通信芯片厂商:有望受益行业上行过程。建议关注:中兴通讯、工业富联、紫光股份、锐捷网络、菲菱科思、翱捷科技、初灵信息。6.4.2 大数据公司:看好“开源大模型+自有海量数据”组合 对“拥有大量数据但算力不足”的企业而言,利用自己的数据,充分预训练和微调开源可商用模型,性价比较高。这可以提高模型的准确性和适用性,也能够大大缩短模型训练时间和成本。此外,微调后的模型还能够更好地满足企业的特定需求和业务场景,从而提升企业的竞争力和创新能力。随着技术的不断发展和普及,自主微调模型成为企业利用自有数据,快速实现智能化应用的重要手段。 6.4.3 开源大模型服务商:服务至上 回顾红帽的发展史,我们认为,即使大模型进入开源时代,面向客户的24*7的服务仍然必不可少,尤其是面向企业的。我们看好开源大模型服务商。 6.4.4 苹果:获得ChatGPT App收入分成 ChatGPT在App Store上架,按照App Store的惯例,苹果将获得收入分成。 本文节选自国盛证券研究所已于2023年5月31日发布的报告《开源竞速:AI大模型的“Linux时刻”降临》,具体内容请详见相关报告。 —- 编译者/作者:国盛区块链研究院 玩币族申明:玩币族作为开放的资讯翻译/分享平台,所提供的所有资讯仅代表作者个人观点,与玩币族平台立场无关,且不构成任何投资理财建议。文章版权归原作者所有。 |
开源竞速:AI大模型的“Linux时刻”降临
2023-06-01 国盛区块链研究院 来源:区块链网络
相关阅读:
- 科大讯飞:大模型用户数据和牌照消息现在无法透露,目前算力可以满2023-06-01
- 佳都科技:正在开展交通领域的行业 AI 大模型产品研发2023-05-31
- 深圳:重点支持打造基于国内外芯片和算法的开源通用大模型,打造大2023-05-31
- 深圳:重点支持打造基于国内外芯片和算法的开源通用大模型,打造大2023-05-31
- 北京:系统构建大模型等通用人工智能技术体系2023-05-30

