来源:新智元 能听还能看,给模型不同的感官理解世界!当下的大型语言模型,如ChatGPT只能接收文本作为输入,即便升级版的GPT-4也只是增加了图像输入的功能,无法处理其他模态的数据,如视频、音频等。 最近,来自剑桥大学、奈良先端科学技术大学院大学和腾讯的研究人员共同提出并开源了通用指令遵循模型PandaGPT模型,也是首个实现了跨六种模态(图像/视频、文本、音频、深度、thermal和IMU)执行指令遵循数据的基础模型。  论文链接:https://arxiv.org/pdf/2305.16355.pdf 代码链接:https://github.com/yxuansu/PandaGPT 在没有明确多模态监督的情况下,PandaGPT就展现出了强大的多模态能力,可以执行复杂的理解/推理任务,如详细的图像描述生成、编写视频启发的故事、回答有关音频的问题,或是多轮对话等。 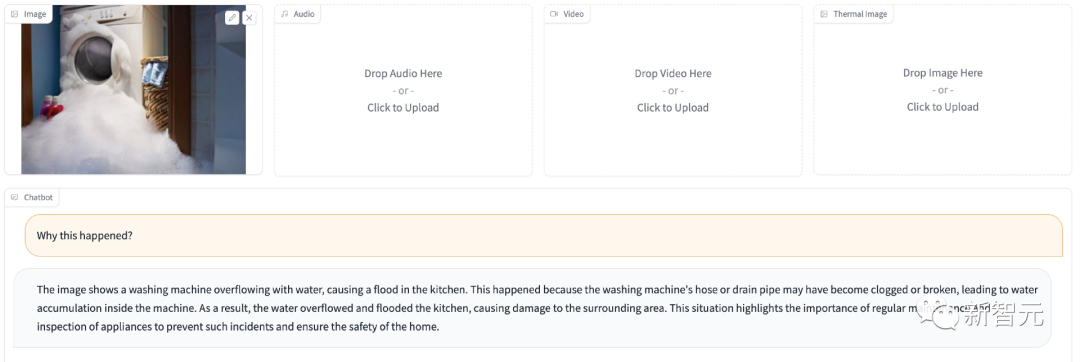 总之,PandaGPT的核心创新在于可以同时接受多个模态输入,并自然地组合不同模态的语义,超越传统的单模态分析,扩展了下游应用场景,也更贴近AGI的实现方式。 示例基于图片的问答:  基于图片的多轮问答:  基于视频的问答: 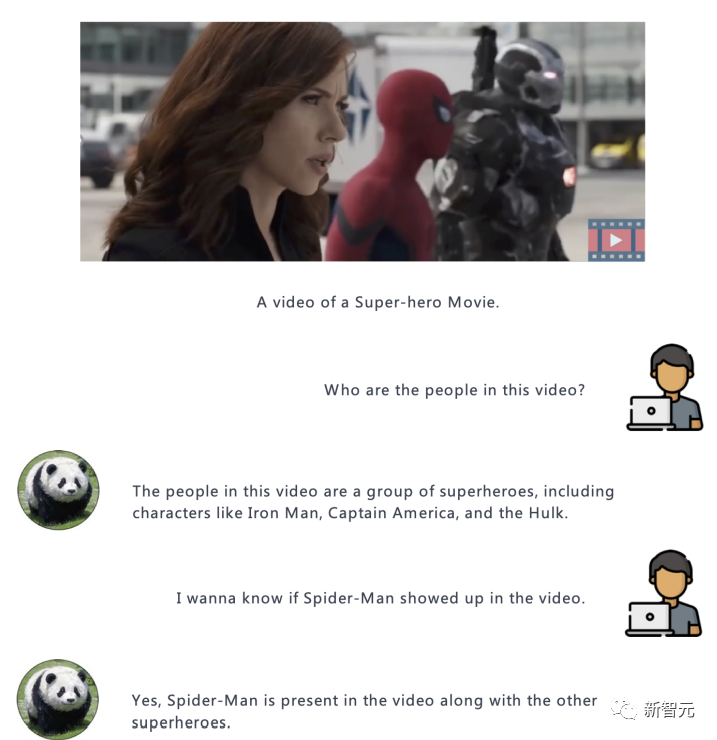 受图像/视频启发的创意性写作:  视觉推理能力:  音频推理能力:  图片+音频的多模态理解能力: 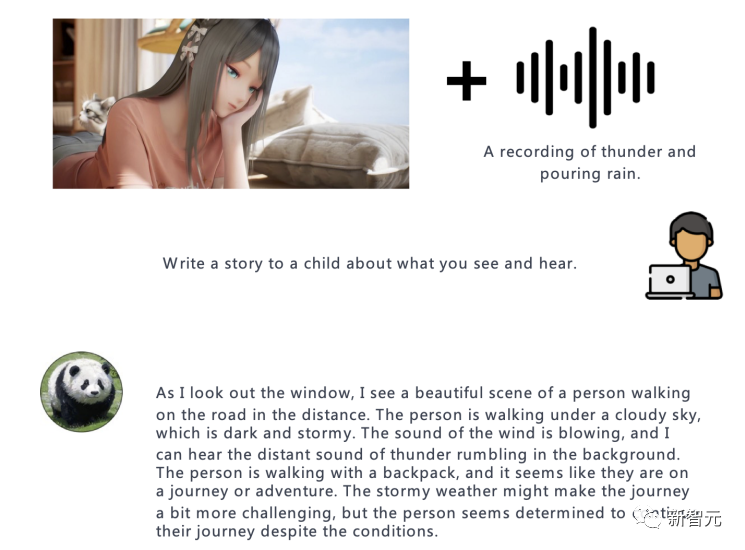 视频+音频的多模态理解能力:  多模态PandaGPT 多模态PandaGPT和困在计算机内的AI模型相比,人类具有多种感官来了解世界,可以看一幅画,可以听到自然界的各种声音;机器如果也能输入多模态的信息,就可以更全面地解决各种问题。 目前多模态的研究大多数局限于单模态,或是文本与其他模态的组合,缺乏感知和理解多模态输入的整体性和互补性。 为了让PandaGPT具有多模态输入能力,研究人员结合了ImageBind的多模态编码器和大型语言模型Vicuna,二者在视觉和音频基础的指令遵循任务中都取得了非常强大的性能。 同时,为了使二个模型的特征空间一致,研究人员使用开源的16万个图像-语言指令遵循数据来训练PandaGPT,其中每个训练实例包括一个图像和一组多轮对话数据,对话中包含每轮人类的指令和系统的回复。 为了减少可训练参数的数量,研究人员只训练用来连接Vicuna的ImageBind表征,以及Vicuna的注意力模块上的额外LoRA权重。 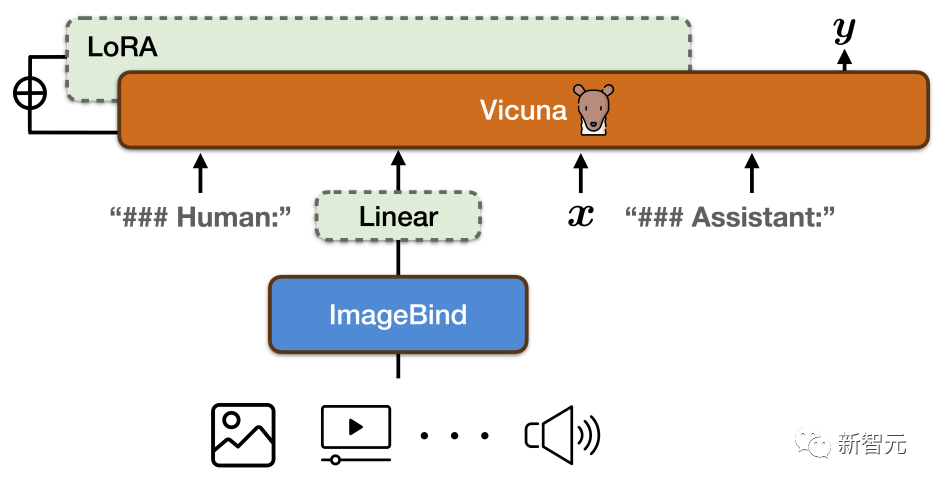 训练过程中,按照8×A100 40G GPU的计算资源来算,Vicuna-13B最大序列长度被设定为400的情况下,训练需要大约7小时。 值得注意的是,当前版本的PandaGPT只用对齐的图像-文本数据进行训练,但通过利用冻结的ImageBind编码器中继承的六种模态(图像/视频、文本、音频、深度、thermal和IMU)的绑定属性,PandaGPT展示出了涌现,即零样本跨模态的能力。 限制尽管PandaGPT在处理多模态及模态组合方面有惊人的能力,但还有几种方法可以用来进一步改进PandaGPT: 1. PandaGPT的训练过程可以通过引入更多对齐数据来丰富,比如其他与文本匹配的模态(音频-文本) 2. 研究人员对文本以外的模态内容只使用一个嵌入向量来表征,还需要对细粒度的特征提取畸形更多研究,如跨模态的注意力机制可能会对性能提升有好处 3. PandaGPT目前只是将多模态信息作为输入,未来可能会在生成端引入更丰富的多媒体内容,比如在音频中生成图像和文字回复。 4. 还需要有新的基准来评估多模态输入的组合能力 5. PandaGPT也可以表现出现有语言模型的几个常见缺陷,包括幻觉、毒性和刻板印象。 研究人员也指出,PandaGPT目前还只是一个研究原型,不能直接用于现实世界的应用。 参考资料: https://huggingface.co/spaces/GMFTBY/PandaGPThttps://panda-gpt.github.io/https://github.com/yxuansu/PandaGPT—- 编译者/作者:AI之势 玩币族申明:玩币族作为开放的资讯翻译/分享平台,所提供的所有资讯仅代表作者个人观点,与玩币族平台立场无关,且不构成任何投资理财建议。文章版权归原作者所有。 |
剑桥华人团队开源PandaGPT:首个横扫「六模态」的大型基础模型
2023-06-24 AI之势 来源:区块链网络
LOADING...
相关阅读:
- 索尼音乐聘请 BPI 专家 Geoff Taylor 担任人工智能执行副总裁2023-06-24
- “图灵测试已过时,AI 能不能赚大钱才是新标准”,来自 DeepMind 联创2023-06-23
- AI入局世界网球温布顿锦标赛,可分析赢球概率及生成球评2023-06-23
- AI歌手不甘心只做“AI孙燕姿”2023-06-23
- XPLA获Big Brain Holdings、Play Ventures和IVC投资2023-06-23