原文来源:夕小瑶科技说 最近,大型语言模型无疑是AI社区关注的焦点,各大科技公司和研究机构发布的大模型如同过江之鲫,层出不穷又眼花缭乱。 让笔者恍惚间似乎又回到了2020年国内大模型“军备竞赛”的元年,不过那时候大模型海量算力需求限制了这注定只是少数科技公司的赛场,如今用少量资源即可在基础模型上做指令微调、人类反馈以应用到某个垂直领域,LLMs领域当前呈现出‘吊诡’的繁荣,模型和数据集存储库Hugging Face中已经有近16000个文本生成模型,社区每周都会有数百个新的模型发布,Hugging Face从2022/12到2023/6的六个月内就新增了10万个模型,一方面投资者鼓吹落地,似乎新的范式已到,另一方面,各色研究机构生怕赶不上潮流,都试图在大模型领域留下自己的一个身位。 无论如何,舞台的聚光灯早已汇聚到大模型上,在这寸‘你方唱罢,我登场’的舞台上,笔者细捋一下大型语言模型的师承和脉络,略有偏颇,欢迎小伙伴在评论区留言补充~ github地址:https://github.com/WangHuiNEU/llm 大模型可以分为基座模型和在基座模型上进行指令微调、人类反馈对齐等instruction-tuning之后的微调模型。但实际上,正如艾伦研究所的文章‘How Far Can Camels Go?’所指明的:不同的指令微调数据集可以释放或者增强特定的能力,但并没有一个数据集或者组合可以在所有的评估中提供最佳性能,因此,我们需要一个更大强大的基座模型。 实际上,更简单的可以理解为,指令微调并不会为模型增加新的能力,基座模型本身奠定了应用的范畴,指令微调只是用极少量的数据快速激发出某个领域范畴的能力强弱。实际微调过一些大模型的小伙伴可能会对此感触颇深,因此,更加合理的大模型故事线是围绕基座模型。下面将针对Google系、Meta系、OpenAI系和其他科技公司的基座模型,和基于基座的一些微调模型进行详细展开。 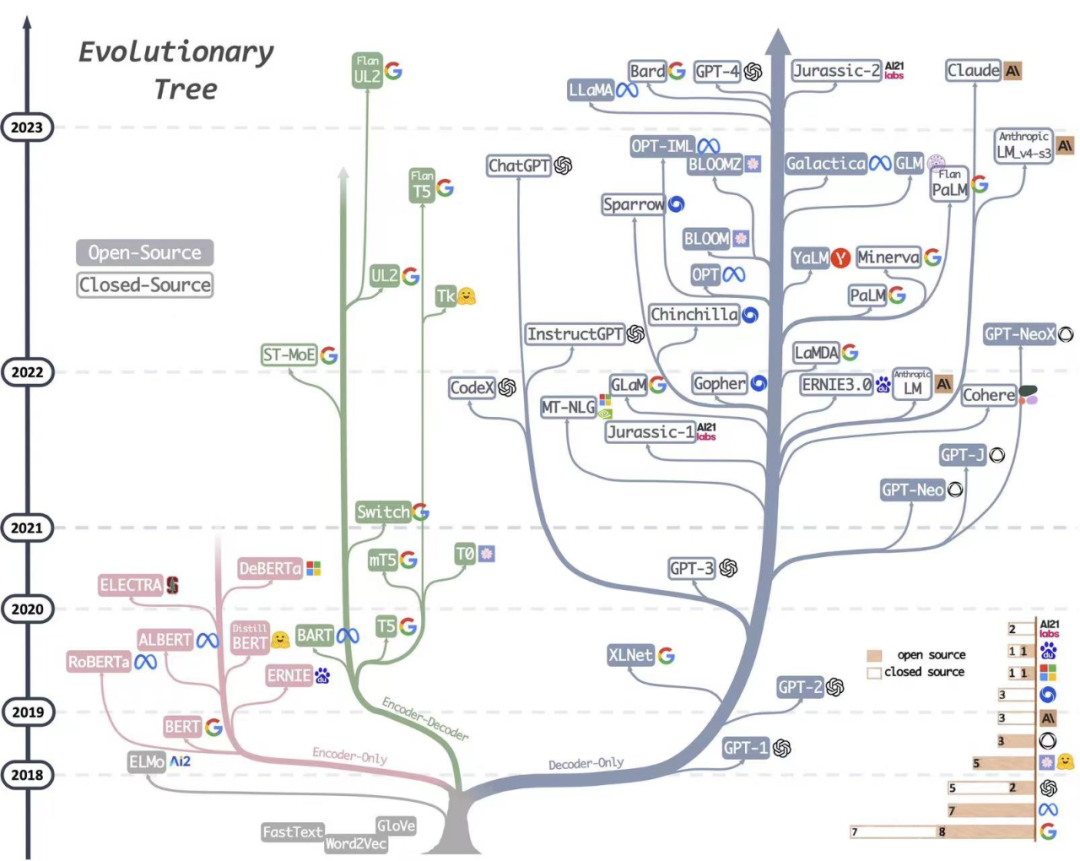 大模型的进化树一、Google系模型 大模型的进化树一、Google系模型Google在大模型赛道一直是最受关注的存在,但尴尬的是,面对着ChatGPT的强势猛攻,占据搜索领域绝大部分份额的Google在新型的检索生成竞赛中不可能猛然转身去动其核心的搜索广告业务,但在大模型领域,Google有着最为深厚的积累,例如,在2017年提出Transformer架构,2021年提出的Pathways架构在笔者看来更是将工程优化推到了极致。 Google原本分别有两个研究小组:Google Brain和Deepmind,但在今年4月合并为了 Google Deepmind,但这里依然分开去讲述。 1. 基座模型Google Brain 模型名称时间是否开源参数规模T52019-10是13BLaMDA2021-05否137BPaLM2022-04否540B 有趣的是,LaMDA是Google早在2020年就被开发和推出的对话式语言模型,但Google考虑安全问题拒绝对公众开放,首席研究员 Daniel De Freitas 和 Noam Shazeer 因此沮丧地离开了公司【去年9月,这两位成立了基于 LLM 的聊天机器人网站Character.AI,也算是一直坚持自己的目标了】,Google在对话生成方向起了个大早,赶了个晚集,手动狗头~ PaLM是基于Google提出的高效模型训练的下一代AI架构Pathways构建的超大语言模型,5400亿的参数量,是目前最大的稠密Transformer模型,也是目前综合性能最强大的基座语言模型。 DeepMind 模型名称时间是否开源参数规模Gopher2021-12否280BChinchilla2022-04否70B Chinchilla是DeepMind重新思考了大模型的scaling laws(缩放定律),实证研究分析得出数据规模和参数规模一样重要,因此,训练得到的Chinchilla用仅Gopher1/4参数量反而性能显著超越Gopher,训练数据规模和训练参数一样重要! Google DeepMind 模型名称时间是否开源参数规模PaLM 22023-05否340B(小道消息,未证实~) 4月,Google决定集中力量办大事,Google Brain和DeepMind合并为Google DeepMind。5月,谷歌I/O 2023大会,Google提出了更为强大的PaLM 2,合理的大模型缩放法则+多样化的数据集,PaLM 2无疑是Google在这波浪潮中保持头部地位的底气所在。 2. 指令微调模型单位模型名称基座模型是否开源Hugging FaceT0T5是GoogleFLANT5否GoogleFlan-T5/Faln-PaLMT5/PaLM否GoogleBard(生成人工智能聊天机器人)之前是LaMDA,后面是PaLM 2否 基于基座模型,进行instrucion-tuning可赋予模型强大的对齐能力。这里有趣的是,2 月 6 日,Google 宣布推出 Bard,这是一款由 LaMDA 提供支持的对话式生成人工智能聊天机器人,但刚开始推出时,相对于ChatGPT差劲的性能一度让Google的股价下跌了8%,后续Google基于更强大的LaMDA做了改进,但无论内部和外部都质疑声不断,5月,Google I/O大会宣布基于PaLM 2模型对Bard做了更新。 Bard无疑是Google面对ChatGPT的回应,但检索广告占其总收入的60%,Google做不到像Bing一样直接将检索生成加入到浏览器结果中,。Google在这里选择了不同的道路,将检索和Bard做成两款互补的产品,目前Bard也一直在 bard.google.com 这块小空间里圈地自萌,目前Google计划结合基于AlpaGo中使用的技术开发出更为强大的模型Gemini。 二、Meta系模型Meta可是所有巨头中最为拥抱开源的科技公司,Meta AI基础人工智能研究院团队首席人工智能科学家Yann LeCun表示:让AI平台安全良善实用的唯一方法就是开源。当然,Meta的开源模型也造福了国内绝大多数的大模型玩家们,再次手动狗头~ 1. 基座模型模型名称时间是否开源参数规模OPT2022-05是125M-175BLLaMA2023-02是7B-65B 开源先行者Meta在OpenAI选择闭源GPT-3的情况下,对标GPT-3,直接开源千亿参数的OPT模型,但OPT相对比GPT-3模型性能差一些。之后,启发于DeepMind发现的缩放法则,Meta缩小了模型参数在更大的数据集上训练了LLaMA(Large Language Model Meta AI),130亿参数的模型与GPT-3性能大致相当,650亿参数的模型性能可以媲美Chinchilla-70B和PaLM-540B,大模型开启驼系(LLaMA)时代~ 2. 指令微调模型单位模型名称基座模型是否开源MetaOPT-IMLOPT-175B是StanfordAlphacaLLaMA是StanfordVicunaLLaMA是 LLaMA无疑最常被大家当做基座模型用来做指令微调适配到法律、医学等专业领域,特别是7月19日,Meta AI发布可免费商用的开源模型LLaMA 2, 包括7B, 13B和70B三种规模,动手快的已经用中文数据做了指令微调,例如,Llama2-chinese几天时间star数飙升1.7k,拼手速的时候到了~  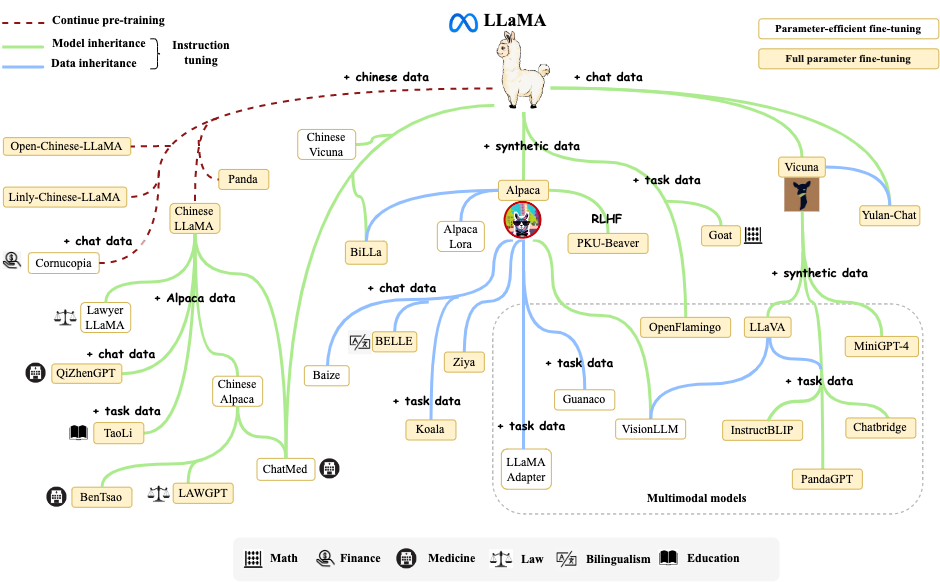 LLaMA变体,图来源于《A Survey of Large Language Models LLaMA变体,图来源于《A Survey of Large Language ModelsLLaMA的徒子徒孙们,有驼系(羊驼Alpaca, 小羊驼Vicuna),动物园系(考拉Koala,山羊Goat,熊猫Panda),神话系(姜子牙Ziya,白泽Baize),逐渐从动物园走向了神话传说~ 三、OpenAI系模型1. 基座模型 如果追溯GPT系列发展的时间线,我们会发现这是一项横跨五年的技术探索,从GPT-2到GPT-3,其实也只是在几乎不改变模型框架的基础上从15亿的参数量迭代到1750亿,不同于Google推出T5、Switch Transformer和PaLM等一系列大模型的赛马机制,OpenAI‘矢志不渝’地坚持着GPT路线。 2. 指令微调模型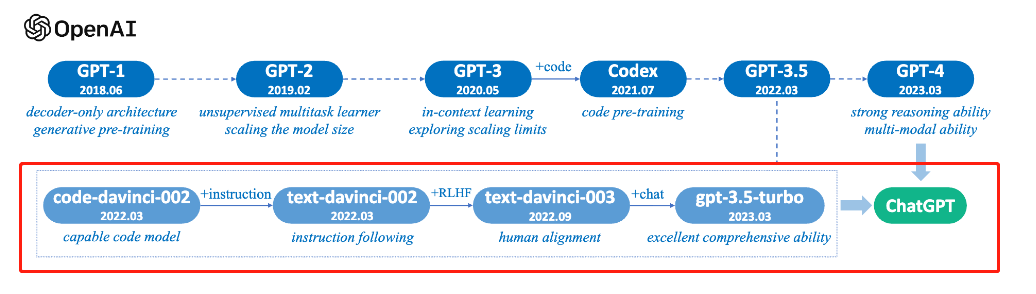 2017年OpenAI提出RLHF(人类反馈强化学习,Reinforcement Learning from Human Feedback)技术;2022年,OpenAI将RLHF应用于GPT-3并开发出InstructGPT,相对于GPT-3更善于遵循用户意图,虽然参数量只有1.3B,比175B GPT-3模型参数少了100多倍,微调成本更是只有GPT-3的2%。 3月14日,GPT-4发布,OpenAI给出了技术报告和3分钟的预告片。GPT-4支持多模态,能够识图、生成歌词、做网站,并且刷爆了人类社会各个领域的考试,已经达到了哈佛、斯坦福等顶尖高校的水平。现已集成到微软New Bing和ChatGPT Plus。 微软Microsoft 365全面引入生成式AI助手Copilot,将GPT-4集成到了Word、Excel、PowerPoint、Outlook和Teams等应用中,用户可以提出问题并提示AI撰写草稿、制作演示文稿、编辑电子邮件、制作演示文稿、总结会议等。 四、开源社区、研究院和一些科技公司构建的大模型1. 基座模型为了打破 OpenAI 和微软对自然语言处理 AI 模型的垄断,前OpenAI研究副总裁Dario Amodei带领一批从OpenAI出走的员工创立了致力于提高AI安全和可解释性的人工智能安全和研究公司Anthropic。 Connor Leahy、Leo Gao 和 Sid Black 创立了专注于人工智能对齐、扩展和开源人工智能研究的组织EleutherAI。 之后Hugging Face 社区带头成立了BigScience项目,这是一个包容、开放、协作共享的大型语言模型(LLM)社区,围绕研究和创建超大型语言模型的开放式协作研讨会,由HuggingFace、GENCI和IDRIS发起的开放式合作,汇集了全球 1000 多名研究人员。 国内的包括北京智源人工智能研究院BAAI、清华和百度等也都打造了自己的基座模型。 组织模型名称时间是否开源参数规模AnthropicAnthropic-LM v4-s32021-12否52B北京智源人工智能研究院天鹰Aquila2023-06是7B/33BBaiduERNIE 3.02021-12否260B清华GLM2022-8是130BEleutherAIGPT-Neo2021-03是2.7BEleutherAIGPT-J2021-06是6BEleutherAIGPT-NeoX2022-04是20BBigScienceBLOOM2022-11是176B 2. 指令微调模型单位模型名称基座模型是否开源北京智源人工智能研究院AquilaChat-7BAquila-7B是北京智源人工智能研究院AquilaChat-33BAquila-33B是BigScienceBLOOMZBLOOM是EleutherAIGPT-NeoXGPT-Neo是Baidu文心一言ERNIE 3.0否AnthropicClaude2Anthropic-LM v4-s3否 总结本文总结了主流的基座模型以及对应的指令微调模型,希望社区的小伙伴多多讨论,一起努力构建更为强大的中文社区的语言模型~ —- 编译者/作者:Model进化论 玩币族申明:玩币族作为开放的资讯翻译/分享平台,所提供的所有资讯仅代表作者个人观点,与玩币族平台立场无关,且不构成任何投资理财建议。文章版权归原作者所有。 |
大语言模型“百宝书”,一文缕清所有大模型
2023-08-01 Model进化论 来源:区块链网络
LOADING...
相关阅读:
- 通用大模型商业化尚早,生成式AI才刚起跑2023-08-01
- 巴比特午间要闻一览2023-08-01
- 吉利淦家阅:吉利将于下半年发布全球首个汽车行业全场景 AI 大模型2023-07-31
- 思美传媒:已与生成式大模型合作,将 AI 技术应用在数字营销中2023-07-30
- 科大讯飞赵乾谈金融大模型:应用才是硬道理,下半年发布证券行业智2023-07-29