


原文来源:新智元  图片来源:由无界 AI 生成 快看,轻轻一拉,玫瑰动就起来了。  拖着叶子往左一拉,这颗松柏向同样的方向移动。  还有世界各种物体的图片,随手一拉,瞬间活灵活现。  这便是谷歌团队最新研究,让你的手变成「魔法金手指」,万物皆可,一触即动。  https://generative-dynamics.github.io/static/pdfs/GenerativeImageDynamics.pdf 在这篇论文中,谷歌提出了「Generative Image Dynamics」,通过对图像空间先验进行建模,然后训练模型预测「神经随机运动纹理」。 最后就实现了,与单个图像交互,甚至可以生成一个无限循环的视频。 未来,艺术家们的想象力不再受限于传统的框架,一切皆有可能在这个动态的图像空间实现。 图中万物,「活」起来了世界中万物的运动, 是多模态的。 院子里晾晒的衣服,随着风前后摆动。  街边的挂着的大红灯笼,在空中摇摆。  还有窗帘边睡觉的小猫,肚子呼吸的起伏,好慵懒。  这些运动并通常是可以预见的:蜡烛会以某种方式燃烧,树木会随着风摇曳,树叶会沙沙作响... 拿起一张照片,或许研究人员就可以想象到,拍摄时它运动的样子。 鉴于当前生成模型的发展,特别是扩散模型,使得人们能够对高度丰富和复杂的分布进行建模。 这让许多以往不可能的应用成为可能,比如文本生成任意逼真的图像。除了在图像领域大展身手,扩散模型同样可以在视频领域建模。  由此,谷歌团队在这项研究中,对图像空间场景运动的生成先验进行建模,即单个图像中所有像素的运动。 是根据从大量真实视频序列中自动提取的运动轨迹,来进行模型训练。 以输入图像为条件,训练后的模型预测「神经随机运动纹理」:一组运动基础系数,用于描述每个像素未来的轨迹。 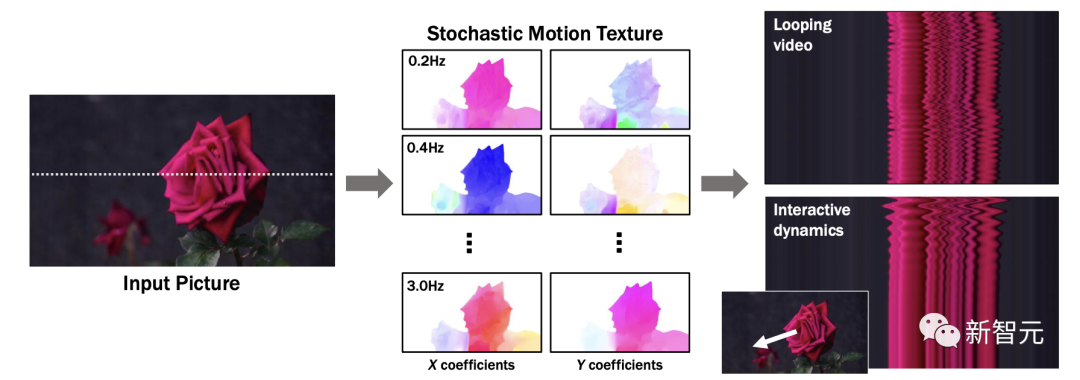 谷歌研究人员将研究范围限定在,具有自然摆动动态的真实世界场景,如随风飘动的树木和花朵,因此选择傅立叶级数作为基函数。 然后,使用扩散模型来预测「神经随机运动纹理」,模型每次只生成一个频率的系数,但会在不同频段之间协调这些预测。 由此产生的频率空间纹理,可以转化为密集的长距离像素运动轨迹,可用于合成未来帧,将静态图像转化为逼真的动画。  接下来,具体看看是如何实现的? 技术介绍基于单张图片 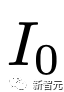 ,研究人员的目标是生成长度为T的视频 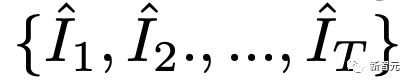 ,这段视频能够呈现动态的树木、花朵,或者是在微风中摇曳的蜡烛火焰等。 研究人员的构架的的系统由两个模块组成:「动作预测模块」和「基于图像的渲染模块」。 首先,研究人员使用「潜在扩散模型」为输入图片 预测一个神经随机运动纹理 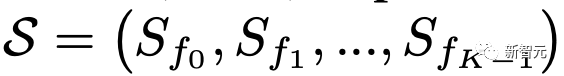 它是输入图像中每个像素运动轨迹的频率表示。 第二步,使用逆离散傅立叶变换将预测出的随机运动纹理转化为一系列运动位移场(motion displacement fields) 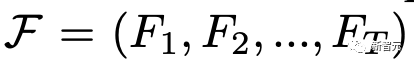 。 这些运动位移场将用于确定每个输入像素在每一个未来时间步长的位置。 有了这些预测的运动场,研究人员的渲染模块使用基于图像的渲染技术,从输入的RGB图像中拾取编码特征,并通过图像合成网络将这些拾取的特征解码为输出帧。 神经随机运动纹理运动纹理 之前的研究中,运动纹理定义了一系列时变的2D位移映射( displacement map) 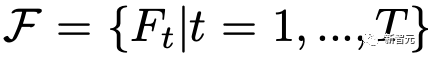 其中,每个像素坐标p,从输入图像 中的2D位移向量定义了该像素在未来时间t的位置。 为了在时间t生成一个未来帧,可以使用相应的位移映射,从 中拾取像素,从而得到一个前向变形的图像: 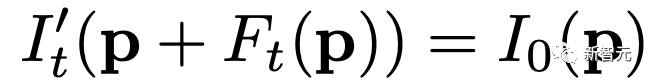 随机运动纹理 正如之前在计算机图形研究中所证明的,许多自然运动,特别是振荡运动,可以描述为一小组谐振子(harmonic oscillators)的叠加,这些谐振子用不同的频率、振幅和相位表示。 一种引入运动的随机性的方法是整合噪声场。但正如之前研究结果表明的,直接在预测的运动场的空间和时间域内添加随机噪声通常会导致不现实或不稳定的动画。 更进一步,采用上面定义的时间域内的运动纹理意味着需要预测T个2D位移场,才能生成一个包含T帧的视频片段。为了避免预测如此大的输出表示,许多先前的动画方法要么自回归地生成视频帧,要么通过额外的时间嵌入独立预测每个未来的输出帧。 然而,这两种策略都不能确保生成的视频帧在长期内具有时间上的一致性,而且都可能产生随时间漂移或发散的视频。 为了解决上述问题,研究人员在频率域中表示输入场景的每像素运动纹理(即所有像素的完整运动轨迹),并将运动预测问题表述为一种多模态的图像到图像的转换任务。 研究人员采用潜在扩散模型(LDM)生成由一个4K通道的2D运动光谱图组成的随机运动纹理,其中K << T是建模的频率数,而在每个频率上,研究人员需要四个标量来表示x和y维度的复傅立叶系数。 下图展示了这些神经随机运动纹理。 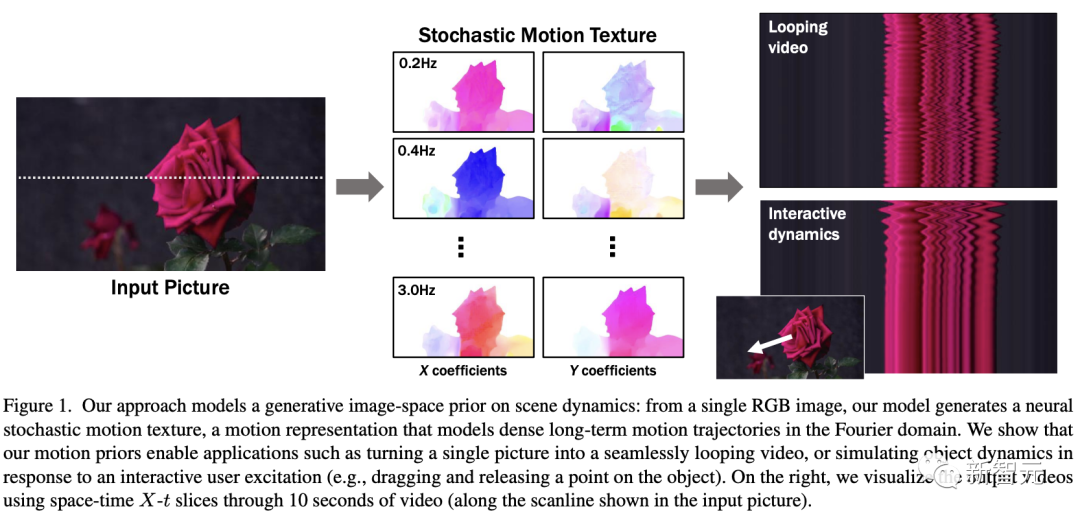 那么,应该如何选择研究人员表示的 K 输出频率呢?实时动画之前的研究说明,大多数自然振荡运动主要由低频分量(low-frequency component)组成。 为了验证这一假设,研究人员计算了从1000个随机抽样的5秒真实视频剪辑中提取出来的运动的平均功率谱。如下图左图所示,功率主要集中在低频分量上。 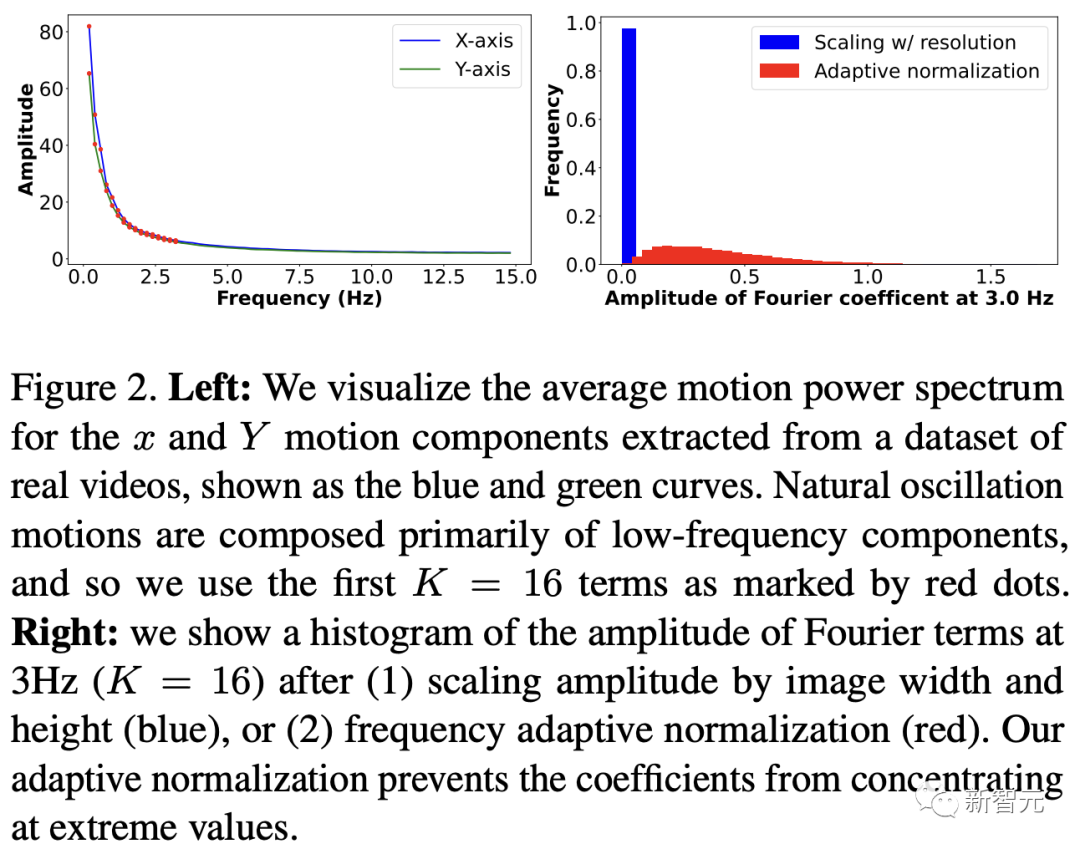 动作的频谱随着频率的增加呈指数下降。这表明大多数自然振动动作确实可以由低频项很好地表示。 在实践中,研究人员发现前K=16个傅里叶系数足以在一系列真实视频和场景中真实地重现原始的自然动作。 使用扩散模型预测动作研究人员选择潜在扩散模型(LDM)作为研究人员的动作预测模块的核心,因为LDM在保持生成质量的同时,比像素空间扩散模型更加计算高效。 一个标准的LDM主要包括两个模块: 1.一个变分自编码器(VAE)通过编码器z = E(I)将输入图像压缩到潜在空间,然后通过解码器I = D(z)从潜在特征中重构输入。 2.一个基于U-Net的扩散模型,这个模型学会从高斯随机噪声开始迭代地去噪潜在特征。 研究人员的训练不是应用于输入图像,而是应用于来自真实视频序列的随机动作纹理,这些纹理被编码然后在预定义的方差时间表中扩散n步以产生噪声潜在变量zn。 频率自适应归一化(Frequency adaptive normalization) 研究人员观察到一个问题,随机动作纹理在频率上具有特定的分布特性。上图的左侧图所示,研究人员的动作纹理的幅度范围从0到100,并且随着频率的增加大致呈指数衰减。 由于扩散模型需要输出值位于0和1之间以实现稳定的训练和去噪,因此研究人员必须在用它们进行训练之前归一化从真实视频中提取的S系数。 如果研究人员根据图像宽度和高度将S系数的幅度缩放到[0,1],那么在较高频率处几乎所有的系数都会接近于零,上图(右侧)所示。 在这样的数据上训练出的模型可能会产生不准确的动作,因为在推理过程中,即使是很小的预测误差也可能在反归一化后导致很大的相对误差,当归一化的S系数的幅度非常接近于零时。 为了解决这个问题,研究人员采用了一种简单但有效的频率自适应归一化技术。具体而言,研究人员首先根据从训练集中计算的统计数据独立地对每个频率处的傅里叶系数进行归一化。 频率协调去噪(Frequency-coordinated denoising) 预测具有K个频率带的随机动作纹理S的直接方法是从标准扩散U-Net输出一个具有4K通道的张量。 然而,训练一个模型以产生如此大量的通道往往会产生过度平滑和不准确的输出。 另一种方法是通过向LDM注入额外的频率嵌入来独立预测每个单独频率处的动作光谱图,但这会导致频率域中的不相关预测,从而产生不真实的动作。 因此,研究人员提出了下图中所示的频率协调去噪策略。具体来说,给定一个输入图像I0,研究人员首先训练一个LDM来预测具有四个通道的每个单独频率的随机动作纹理图,其中研究人员将额外的频率嵌入和时间步嵌入一起注入到LDM网络中。 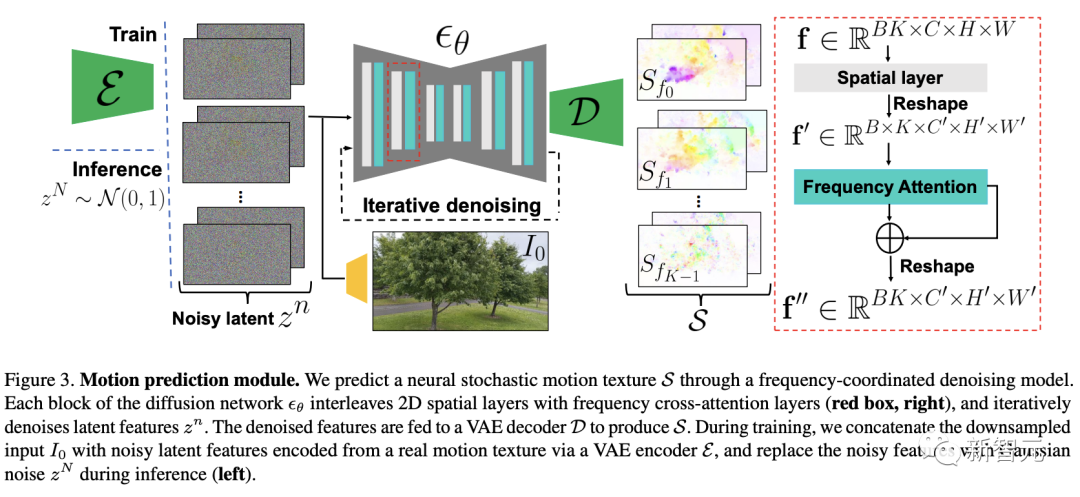 基于图像的渲染 基于图像的渲染研究人员进一步描述如何利用为给定输入图像I0预测的随机运动纹理S来渲染未来时刻t的帧?It。首先,研究人员使用逆时域FFT(快速傅里叶变换)在每个像素点p处计算运动轨迹场 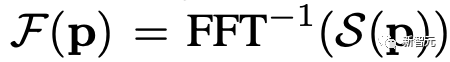 这些运动轨迹场决定了每一个输入像素在未来每一个时间步长的位置。为了生成未来的帧It,研究人员采用深度图像基渲染技术,并执行使用预测的运动场的前向扭曲(splatting)来扭曲编码的I0,如下图所示。 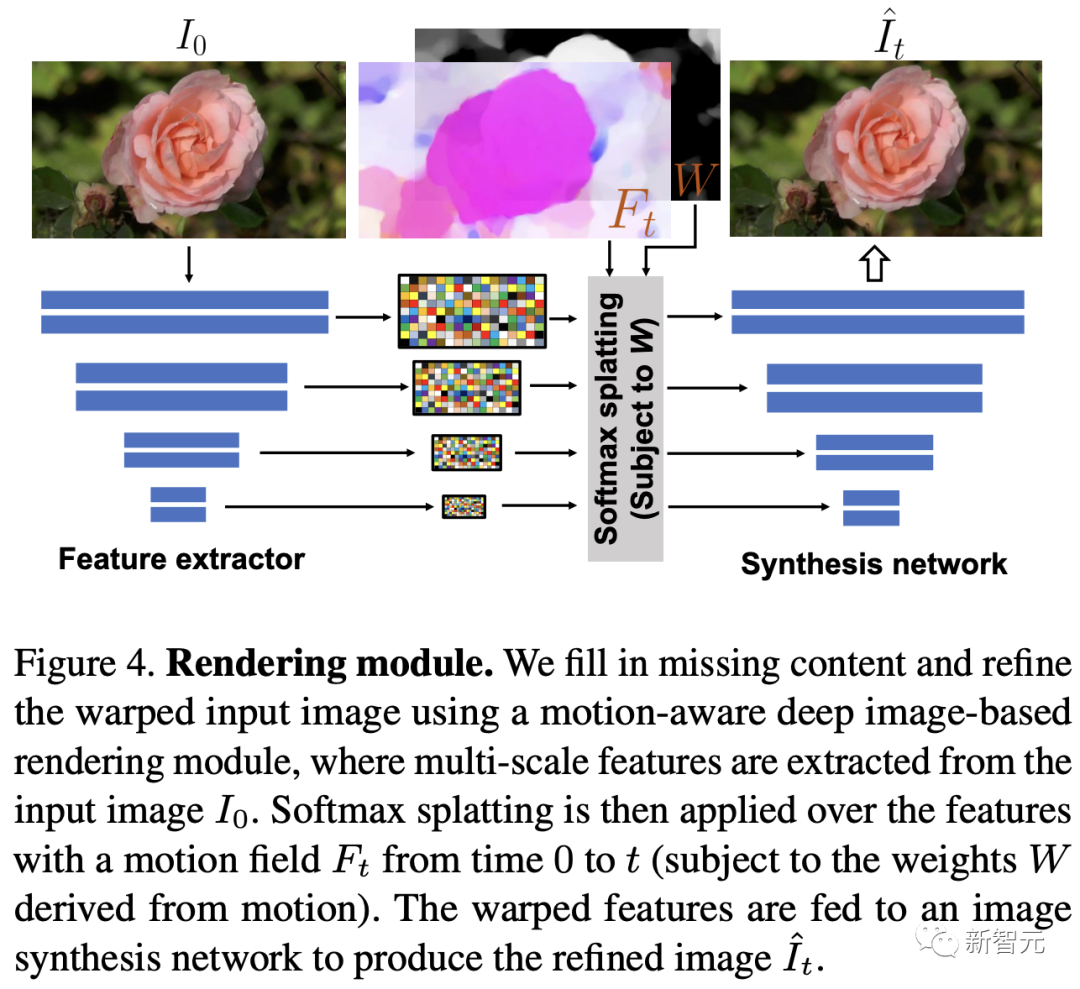 由于前向扭曲可能导致图像出现空洞,以及多个源像素可能映射到相同的输出2D位置,研究人员采用了先前在帧插值研究中提出的特征金字塔Softmax扭曲策略。 研究人员共同训练特征提取器和合成网络,用从真实视频中随机抽取的起始和目标帧,其中研究人员使用从I0到It的估计流场来扭曲I0的编码特征,并用VGG感知损失对预测的?It进行监督。  如上图所示,与直接平均扭曲和基线深度扭曲方法相比,研究人员的运动感知特征扭曲生成了一个没有空洞或者人工痕迹的帧。 进一步的扩展应用研究人员进一步展示了利用研究人员提出的运动表示和动画流程,为单张静态图像添加动态效果的应用。 图像到视频 研究人员的系统通过首先从输入图像预测出一个神经随机运动纹理,并通过应用研究人员基于图像的渲染模块到从随机运动纹理派生出的运动位移场,实现了单张静态图片的动画生成。 由于研究人员明确地对场景运动进行了建模,这允许研究人员通过线性插值运动位移场来生成慢动作视频,并通过调整预测的随机运动纹理系数的振幅来放大(或缩小)动画运动。 无缝循环 有时生成具有无缝循环运动的视频是非常有用的,意味着视频开始和结束之间没有外观或运动的不连续性。 不幸的是,很难找到一个大量的无缝循环视频的训练集。因此,研究人员设计了一种方法,使用研究人员的运动扩散模型,该模型训练在常规的非循环视频片段上,以产生无缝循环的视频。 受近期有关图像编辑指导研究的启发,研究人员的方法是一种运动自引导技术,该技术使用明确的循环约束来引导运动去噪采样过程。 具体来说,在推断阶段的每个迭代去噪步骤中,研究人员在标准的无分类器引导旁边加入了一个额外的运动引导信号,其中研究人员强制每个像素在开始和结束帧的位置和速度尽可能相似。 从单一图像生成可交互的动画 振荡物体的观察视频中的图像空间运动谱近似于该物体的物理振动模态基础。 模态形状捕获了物体在不同频率下的振荡动态,因此物体振动模式的图像空间投影可以用于模拟物体对用户定义的力(如戳或拉)的反应。 因此,研究人员采用了之前研究的模态分析技术,该技术假设物体的运动可以由一组谐振子的叠加来解释。 这使得研究人员将物体的物理响应的图像空间二维运动位移场写为傅里叶谱系数与每个模拟时间步骤t的复模态坐标,以及时间t的加权和。 实验评估研究团队对最新方法,与基线方法在未见视频片段测试集上进行了定量比较。 结果发现,谷歌的方法在图像和视频合成质量方面都显著优于先前的单图像动画基线。 具体来说,谷歌的FVD和DT-FVD距离要低得多,这表明这一方法生成的视频更加真实且时间上更加连贯。 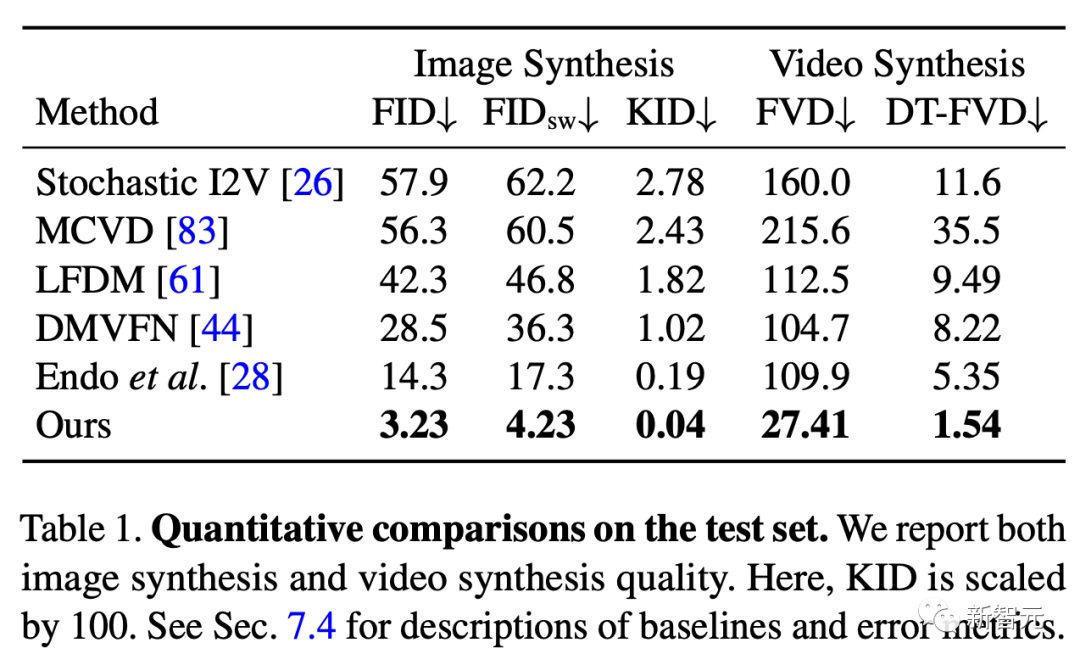 更进一步地,图6显示了不同方法生成的视频的滑动窗口 FID 和滑动窗口 DT-FVD 距离。 由于谷歌采用了全局随机运动纹理表示,其方法生成的视频在时间上更加一致,并且不会随着时间的推移而发生漂移或退化。 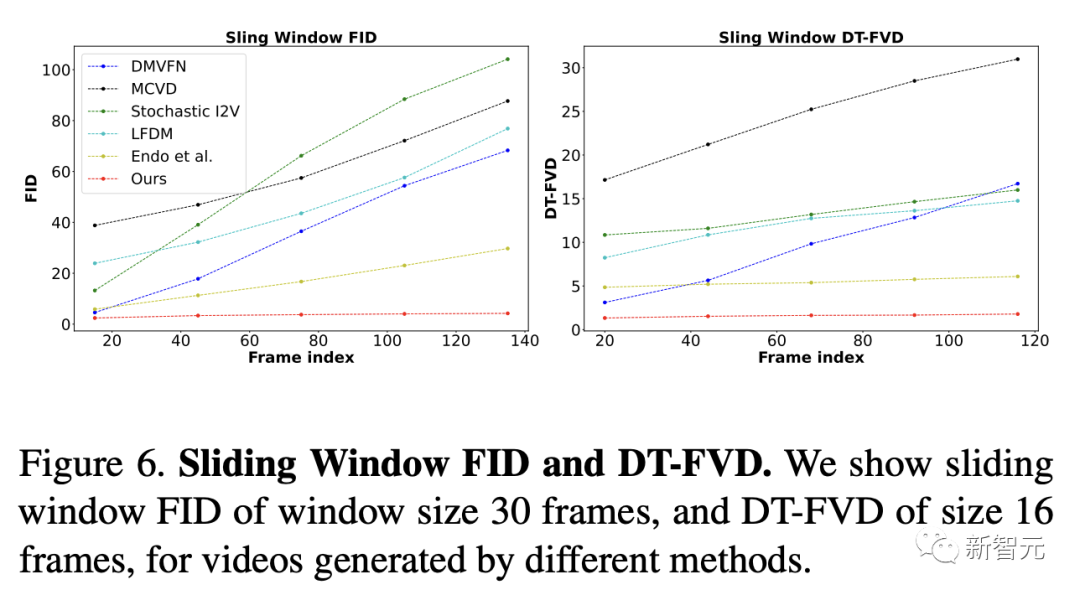 另外,谷歌团队通过2种方式,对自己的方法和基线生成的视频进行可视化定性比较。 首先,展示了生成视频的X-t时空切片,如图7所示。 谷歌生成的视频动态,与相应真实参考视频(第二列)中观察到的运动模式更为相似。随机I2V和MCVD等基线无法随着时间的推移真实地模拟外观和运动。  我们还通过可视化预测图像 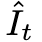 及其在时间t =128时相应的运动位移场,定性比较不同方法中各个生成的帧和运动的质量。 与其他方法相比,谷歌生成的方法生成的帧表现出较少的伪影和失真,相应的二维运动场与从相应的真实视频中估算出的参考位移场最为相似。  消融研究:从表2中观察到,与完整模型相比,所有更简单或替代的配置都会导致性能更差。 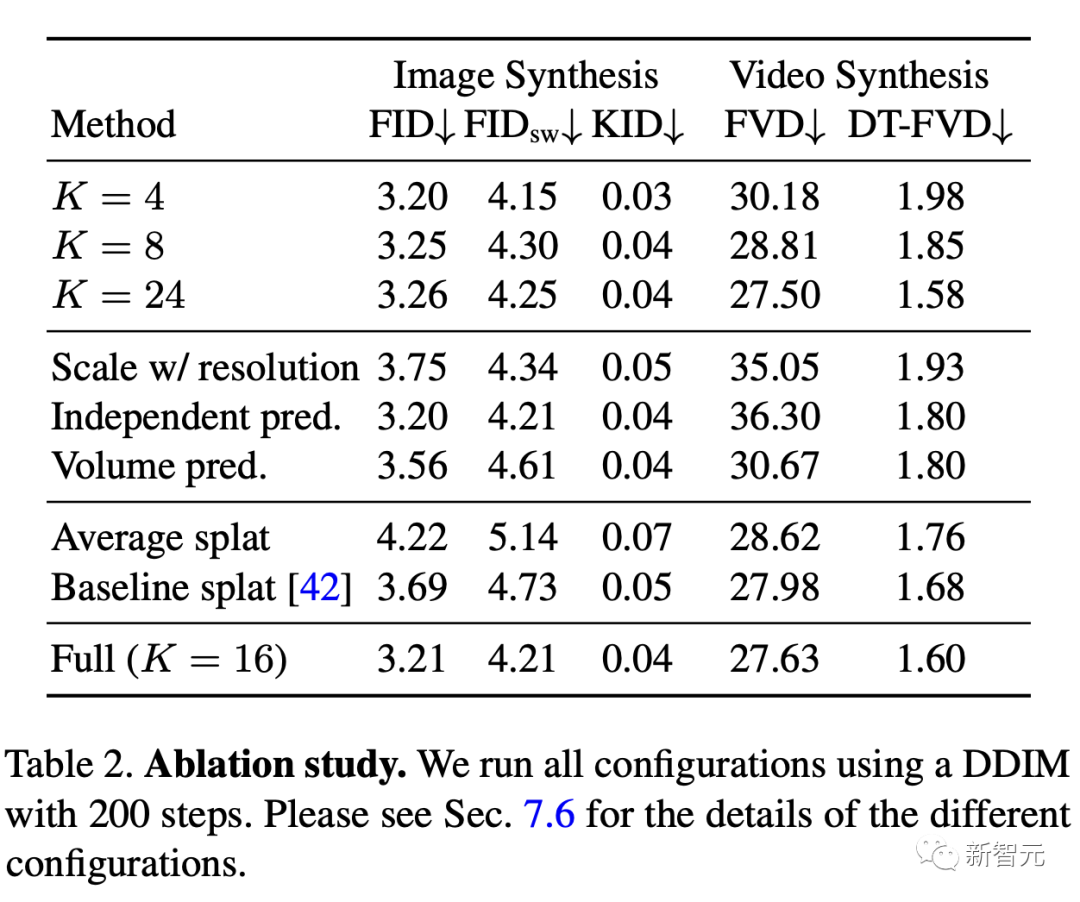 作者介绍 作者介绍Zhengqi Li  Zhengqi Li是谷歌研究院的一名研究科学家。他的研究兴趣包括,3D/4D计算机视觉、基于图像的渲染和计算摄影,尤其是in the wild图像和视频。他在康奈尔大学获得了计算机科学博士学位,导师是Noah Snavely。 他是CVPR 2019最佳论文荣誉提名奖、2020年谷歌博士奖学金、2020年奥多比研究奖学金、2021年百度全球人工智能100强中国新星奖和CVPR 2023最佳论文荣誉奖的获得者。 参考资料: https://generative-dynamics.github.io/ —- 编译者/作者:AIGC 玩币族申明:玩币族作为开放的资讯翻译/分享平台,所提供的所有资讯仅代表作者个人观点,与玩币族平台立场无关,且不构成任何投资理财建议。文章版权归原作者所有。 |
一拖一拽,玫瑰复活了!谷歌提出生成图像动力学,从此万物皆有灵
2023-09-18 AIGC 来源:区块链网络
相关阅读:
- 百度“文心一言软件”著作权获登记批准2023-09-18
- 英国 AI 芯片制造商 Graphcore:未收到软银收购提议2023-09-18
- 周鸿祎:垂直大模型引领新工业革命2023-09-17
- 万兴科技将推出“天幕”多媒体大模型2023-09-17
- 周鸿祎:大模型自身不是壁垒,挑战在于垂直大模型深度定制2023-09-17

