【摘要】过去10年的比特币挖矿是一场算力的军备竞赛:解决反向SHA256哈希函数难题是一个很容易进行优化的目标,游戏很快就从在CPU上运行发展到在GPU上运行,进而转移到在专门设计的ASIC上运行,甚至采用矿池的技术。挖矿因消耗大量电力,令矿工们寻找有廉价电力的地方来进行采矿作业。这些都明显在挑战Satoshi的“一CPU一票”基本原则。也就是说,使用专用硬件和廉价电力的军备竞赛最终推翻了挖矿的平等原则,使比特币采矿倾向于集中。 主讲嘉宾:朱江博士 主持人:Claire WuClaire: 大家好!我是今晚的主持人 Claire, 今晚主讲嘉宾朱江博士将会为大家带来一个非常硬核的主题分享:公平挖矿之一:计算与存储之争。
就公平挖矿这个题目,在【魔笛手技术开发社区】发起了热烈的讨论,我把大家的观点在这里总结一下供主讲嘉宾参考: 火星狐狸哥 : 先解释一下,怎么分配才公平? Evan Liu : 需要先定义“公平”。“公平”是一个主观价值判断,而主观价值判断是因人而异的。所以,不存在普世价值意义上的一致定义。因此,个人认为无法实现一个全局的“公平”的挖矿,而任何所谓“公平挖矿”,都应该可以借用《1984》里的那句话来隐喻:所有的动物都是平等的,但是有一些动物比其他动物更平等。 云海 : 规则保证了公平,矿机并没有优先级一说,都平等,因为总算力及难度都极高所以也并没有所谓超级矿机存在,保证了公平性。 SHAN: 赞同 Evan Liu 的观点。对于一辈子都买不起矿机的西部农民,POW公不公平一点都不重要。 老田 : 公平,对所有参与者规则一样,就是公平。难得是公正。 牛虻 : 感觉挖矿这种事情,应该很难公平。不管是 POW,还是 POS,首先还是要有硬实力。只能说对有一定基础实力的矿工公平吧。 Justin : 挖矿本来是个人人可以记账的事,现在都是大型矿场,矿池,变得中心化了,有些寡头垄断,背离中本聪去中心化的初衷了,感觉需要改进改进。而且吧,虽然有云挖矿、矿机托管,但是那不还得让矿场、矿池扒层皮,管理费他们定,卖算力的价格也是他们定,挖矿收益被算的明明白白。。。哈哈哈,以前了解过一些挖矿的事情,但是不知道现在有没有针对过于中心化改善的模式,还请懂的大神讲一讲。其实挖矿发展到现在,已经不是当初设想的那样人人能挖矿。不知道当初有没有想到过这种结果。而且,虽说 BTC 是 POW,但是爆块的永远是那么十几家家矿池,反倒是像 EOS 的 DPOS 了。 PiNetwork早期探索者 : 项目方出来的项目,人人都必须挖币才可以得到,,没有空投!没有代数没有层级!而且都是相互贡献价值。 王成伟: 没有空投币,你觉得有人愿意不为回报的做这样的项目? 牛虻 : 不可能人人平等的,每个人的能力和实力不一样。对项目的投入程度也不一样。 PiNetwork早期探索者: 没有空投,那就是邀请和被邀请的关系,而且是相互贡献价值!只要有一方不挖相互的挖矿都会减少! 关糊糊: 我认为挖矿的公平就是包容性更强,参与的人会多,网络价值就值钱也更安全。 小米鸽子: 矿机在托管中心被盗怎么办呢? 魏洪贵: 关于公平,这幅漫画在不同领域引用过,也争议过。 Claire:非常感谢参与讨论和提出问题的魔笛手群友们。现在我来介绍一下今晚的主讲嘉宾朱江博士。 在朱江博士的简介里面,隐隐感受到他身上闪闪发亮的光环,从国内到国外,就读的都是大名鼎鼎,历史悠久的名校,他之前从事的行业也是目前最热门的。我看过朱博士之前的文章,写得深入浅出,非常亲民,小白都可以大致明白他想要阐述的内容进而启发思考和提出问题。 回到今天的题目: 平等挖矿。毋容置疑,比特币挖矿已经取得了巨大的成功并为比特币网络的安全提供了保障。最新公布的胡润百富榜上,有5位新晋的入榜者来自挖矿行业。然而,今时今日,普通人已经无法挤进这个荆棘满途却可以赢取暴利的行业。普通人如何才能跻身于这场竞赛中获得更多机会呢?今晚,带着魔笛手群友们提出的所有问题,我们请来朱江博士为大家阐述一个我们都非常关心的问题: 『平等挖矿之一:计算与存储之争』 有请朱江博士…… 朱江:谢谢主持人 Claire 的邀请和介绍。 大家好,我是朱江,Soteria 的创始人。感谢大家来参加我们今天这次线上分享。今天跟大家来聊一下挖矿的问题。我是技术宅男,但是我会尽量用通俗易懂的语言和例子跟大家一起讨论啊。我保证不用数学公式,即是出现了的话,也是小升初入学考试大纲的范围,大家可以放心。 我们先从挖矿的原理谈起,然后我会讨论如何才能做到公平,最后时间允许的话我们会结合SoteriaDAG的包容特性,介绍一下我们是如何解决平等挖矿这个问题的。当然时间总是过的很快,万一来不及,那就敬请大家期待我们后边会就同主题而发布的文章或者关注一下我们的https://github.com/soteria-dag/soterd 让我们先简单的回顾一下区块链系统里PoW挖矿的机制。PoW挖矿的本质其实就是一个有着如下四个重要特性的计算难题的游戏:1. 求解过程非常困难2. 核实过程非常简单3. 题目本身需要和某些文字消息绑定4. 题目是随机生成的而且难度可以按需调整在比特币网络里这个数字难题被设计成”解决反向SHA256哈希函数“: 在挖矿过程中,矿工将比特币的80个字节长度的区块头数据进行两次SHA256运算,运算结果就是一个256位(32字节)长度的字符串。通过比较与当前难度值的大小判断当前区块是否合法。即满足下列条件:SHA256(SHA256(block_header))< difficulty看看公式来了,很简单吧。[Yeah!] 这是今天唯一的公式哦~如果不满足上面的条件,则需要在区块头中改变一下随机值,这样就能改变区块头的数据,从而找到满足条件的区块。这就是PoW机制的精髓所在:使用单向函数,并且借助奖励机制,鼓励矿工不断地尝试随机数找到符合条件的区块以完成一定的计算量,以不断保障系统的安全稳定。接下来我们讨论一下共识和网络传输的问题:按照上边说的PoW挖矿的方法,假设你找到了这个满足条件的解,可是怎么才能确定你挖出来的这个块儿是有效的呢?这个就是区块链的另一个基本点:异步共识。具体协议大家都仔细研究过,我就不在这里再啰嗦了。但是我可以给大家个很感性的认识,有助于理解我们后边要讨论的内容。具体是这样的啊: POW的安全的基础,是建立在个人算力不超过全网算力的50%这一基础上的。而潜在的必要条件是任何节点要和网络其他节点公平竞争。这就跟赛跑一样,大家得一起起跑才行。而区块链系统是个异步系统,POW的安全性只有系统状态就近同步的情况下才能保证。POW挖矿奖励其实有一个重要原则就是奖励矿工们尽快的把自己挖出来的区块广播出去,被网络接收;同时在使劲的接收从网络传回来的其他区块,而不是把算力浪费在成不了气候的链上(最长链原则)。这进进出出(TX/RX)其实本质是利用矿工在系统框架下的自然行为保证了网络的同步。大家小时候上学的时候都是经常考试吧。那个时候老师会把卷子给第一排的童鞋,然后一个一个的从前往后传。坐在最后一排的童鞋总是非常晚地拿到卷子(我以前个子矮做第一排没有这个问题)。那么好了,如果拿到卷子的童鞋就开始做了,那最后一排的同学拿到卷子的时候,第一排的同学都开始做好久了,搞不好还做完了,这个不公平。所以,老师要求每个同学拿到卷子的时候扣在课桌上,等到大家都拿到了,老师说“现在开始记时”,大家才能开始做。这就是公平竞争带来的同步。来, 我们看一下考场长什么样: 这里边有两个变量:第一个是传卷子的时间,第二个是做题目的时间。卷子可以是一张纸,也可以厚厚一沓。假设我们传卷子必须要一张一张的传,因为老师印卷子的时候是每一页都印了全班的量。所以,传卷子可以半分钟就传完了,也可以传10分钟都没有全发完。同样,题目也难可易,聪明的童鞋用计算器可以十分钟就做完了,严谨的童鞋完全口算,也许要两个小时才做完。 你现在估计明白我为什么说发卷考试了。传卷子就对应我们的区块大小,题目的难度就对应我们的出块时间。或者说是哈希的难度。小小的区别在于:在区块系统里,没有老师给大家喊“现在开始记时”;而是,童鞋们拿到考卷就开始做。 具体是这样一个节奏:每一个新产生的区块,网络传播的时间是半分钟(网络广播半径)。每个矿工都是收到这个新块验证无误了之后才开始在上边挖矿。 新区块就像一份新的试卷,网络传播就是发卷。而这个卷子发给所有同学需要至少半分钟,然鹅,每轮挖矿总有人比别的人早半分钟拿到试卷。但是矿工觉得这其实也无所谓,首先,题挺难的,考试时间是十分钟,晚拿到试卷半分钟影响不太大;其次,和在教室里考试不一样,大家的座次是随机的而且经常在换,先拿到考卷的人每次都不一样,所以也没问题。 有些倒霉的矿工在TA挖出一个新块的时候半分钟在网络另外一边已经产生出来的新块还没有传播到他这里。于是他的新块就被无情的drop了,也就是变成了孤块。TA的工作就也被无情的浪费了。不过这个没办法,设计就是赢者通吃,但是TA在客观上其实对整个网络的安全也做了贡献(此处省去500字有关博弈论的解析)。 本来说到这里我一般会继续扩展到讲扩容的问题,但是鉴于今天时间的关系,我们还是 focus 在挖矿这件事情上。有关扩容和 SoteriaDAG 的扩容方案,大家可以参考一下我们之前写的一些技术文章: 『 Soteria | 区块图是中本聪共识突破发展瓶颈的关键技术 (一) 』 https://bihu.com/article/1780499191 i=4Hjv&c=1&s=1WuNaT&from=groupmessage 『 Jiang Zhu | 区块图是中本聪共识突破发展瓶颈的关键技术(二)』 https://bihu.com/article/1421456668 i=4Hjv&c=1&s=1ychOs 好,我们继续研究挖矿这个任务。刚才我初略的提到过在考场里每个童鞋做题速度不一样:有的童鞋完全靠口算,有的童鞋带了计算器进场,更有夸张的同学带了手机跟场外的家长实时通信,而家长那边带着全家每人一个计算器可以同时算N道计算题,甚至家人手里都不是计算器,而是靠云计算连接起来的量子计算机。那么问题来了,有计算器的童鞋一定比口算的童鞋做题快(也不一定,比如我口算就比计算器快,这是另外一个话题),带着手机坐拥十个计算器甚至量子计算机可以并行计算的童鞋们,那简直就是逆天了:考卷刚发,后排同学还没看到考卷他就做完了。根据我们上面的分析,届时教室里一定是一地鸡毛(不对,应该一地考卷,有完全空白的,有做了一半儿的),直接影响就是能源巨大的浪费,以及浪费导致的整个网络的安全性的大幅下降。就算没有安全攻击,所有的交易手续费和挖矿的薪酬都因为“赢者通吃”这个游戏规则被这些“逆天”的同学拿走了,大家觉得公平吗?当然不公平了,而且是非常的不公平。其实,比特币和其他PoW的区块链项目都面临着这样一个不公平的问题。过去10年的比特币挖矿其实就是是一场算力的军备竞赛:解决反向SHA256哈希函数难题是一个很容易进行优化的目标,游戏很快就从在CPU上运行发展到在GPU上运行,进而转移到在专门设计的ASIC上运行,甚至采用矿池的技术。挖矿业务的运行也消耗了大量的电力,这促使矿工们寻找有廉价电力的地方来进行采矿作业,例如靠近水力发电站。这些都明显在挑战Satoshi的“一CPU一票”基本原则。也就是说,使用专用硬件和廉价电力的军备竞赛最终推翻了挖矿的平等原则,使比特币采矿倾向于集中。集中的直接结果就是垄断,垄断就可能导致整个系统的安全性受到严重的损害。先发个GPU的图预热一下: 然后我们回到最开始讲的PoW挖矿的基础。 PoW挖矿的反向SHA256哈希函数的难题其实是计算密集型的算法。我们先来看看这个算法在CPU和GPU环境下的情况。这个算法不需要特别多的内存。所以,对CPU而言,我们假设有4核,所有的数据都放在缓存或者SRAM里,空间可以忽略不计,但因为只有四核,就只能启动四个进程。对GPU而言,一般有1000到3000个计算单元,于是我们可以启动几千个进程。当然每个进程的效率可能比不上CPU但总计效率提升几百到几千倍是完全没有问题的。然鹅可是以及但是。。。对于ASIC而言,一个内核中有几千个门电路,可以在一个时钟周期内,完成CPU、GPU需要几千时钟周期内完成的工作。差不多一个矿机的内核就顶的上一块显卡。所以ASIC的挖矿效率动辄就是CPU或者GPU百万倍,不用ASIC基本没有胜利的可能性了。这里我稍微停一下,大家消化一下这些数字,看看这几个情景的对比是多么的无奈。对于一辈子都买不起矿机的西部农民,我将是会多么的无语啊~ 好了,碰巧我们还是有情怀的,不能甘于这种不公,对吧。那我们设想一下,如果有一个神奇的算法,在整个计算过程中,需要使用1G内存,那么情况会如何呢?对CPU来说,4核,保守一点装上4G内存,最多也就同时开四个进程来计算。这里我们就不考虑虚拟内存了,因为实在太慢了,调度交换的过程还不够折腾的呢。对GPU而言,再高端的显卡也就几个G的内存,假设4G,那我们也就是开四个进程同时计算。要是想把所有的计算单元都用上,我们得装上4TB到12TB的SRAM,已经开始有点不太现实了。那ASIC的情况就更可怕了:对内存的要求再翻几千倍甚至上万倍。 我再次的停顿一下,大家再消化一下这一批数字。作为西部农民的我,看到敌人花费如此多钱就为了挖个矿,心里是不是稍稍的好受一些呢?鉴于这个分析,我们来看看处理器技术和内存技术的发展趋势吧,主要目的是看看在可以预见的未来,是不是这类矿机可以恢复到之前让我们无语的标准: 这个图线讲的很清楚的:从八十年带以来,计算技术的革新完全在遵循着摩尔定律,每年的性能提升基本稳定在60%左右。 可是你看到没有,存储技术却只有每年7%的龟速在爬行。而且,这还仅仅是DRAM的提升率哦。 所以来个计算密集型的算法,过几年就变成在手机上也跑的飞快了,而且贼便宜。 内存密集型的明显就不太行,而且说了这个是DRAM的趋势。 由于DRAM存在刷新的问题,DRAM的延迟和带宽都不太适合强算力的应用。这个问题应该在计算机组成与结构这门课里讲过的,有兴趣的童鞋可以读读这本教材。 挖矿不懂computer architecture不太ok的。不过我在斯坦福上这门课的时候,差点挂了。 但不是我笨啊,是我英语不太好,哦不对,是Greek不太好,大牛Christos老师上课有Greek口音,我基本都没听懂。回到挖矿的内存问题,为了保证存储访问带宽和延迟,我们只能采用SRAM。可是SRAM的性能和价格的进步就更加有限了。这个对游戏发烧友也许不是个好事,因为顶配的游戏机的价格不会下降很多。但是这个情况对公平挖矿会不会是个契机呢? 来我们推演一下:SRAM的性能价格比这么离谱,那么有没有一种挖矿算法, TA必须使用真正足够大的内存来计算?也就是说,新的挖矿算法不再是比CPU,比GPU,更不是比ASIC,而是比内存的大小和带宽。因为我们上边提到的内存技术进步的速度,这使得在挖矿军备竞赛的过程中,即使可以调动大规模的资源,也无法以几万或几十万倍的优势在挖矿中占统治地位。那么好了,你再有钱也没法把屌丝矿机给完全屏蔽下去。虽然不能做到绝对公平,但这无形中就客观的提高了挖矿的公平性。这恰恰是我们挖矿和异步共识的的初衷,对吧。 那么我们来研究一下这一类的算法吧。这类算法除了要具有我们前边提到的那四个必要特性以外,TA还要满足如下几个附加条件: 1. 算法需要巨大的内存空间:太小的话,直接做在GPU或者ASIC上,最后又变成拼计算了,这个不公平。 2. 对内存的访问不可以预测:即使整个算法需要大内存,但内存访问如果可以预测,多级缓存技术就可以大幅度减低系统对高性能高带宽的内存的容量要求,第一条就不满足了。 3. 算法不可以存在时间复杂度和空间复杂度的转换:如果你能用高性能计算来跟大内存兑换,也就是减少多高性能高带宽内存容量的要求变小,那就又回到 GPU 和 ASIC 的军备竞赛了。 满足如上这些条件的算法就被称为"Memory-Hard/内存密集型算法”。而基于Cuckoo Hash的Cuckoo Cycle PoW算法则是一款不错的Memory-Hard的算法。该算法在Grin项目中被成功的采用,Soteria的平等挖矿技术也是基于这个算法。 下面我们简单的介绍一下这个算法的工作原理,如果时间还来的及的话,我会给大家预演一下公平挖矿在SoteriaDAG这个项目中的设计和实现。 我们先看一下Cuckoo Cycle Pow的必修课吧,今天我们来点数据结构讲讲Hash Table和Cuckoo Hash。Hash Table大家一定都很熟悉,我们有个哈希函数Hash,TA可以把一个Key映射到一个线性表的某一个位置,这样一个put操作就可以把一个Key Value Pair 存到表里,如图所示: 有碰撞的时候怎么办呢?也就是两个key都映射到同一个位置。那也没关系,新来的就将就一下看看下一个位置是不是空的,如果空,就存在那个位置好了。如图所示: 还有这张 查询的时候同样,用哈希函数找到相应的位置,如果Key是我们想查询的key,找到了返回值就ok了。如果key不一样,那只好看看下一个位置,如果key一样就找到了。如果还不match就继续下去,直到碰到空的位置或者遍历了所有位置,也就是碰到边界条件了。
这就是哈希表也就是hash table的原理。cuckoo hash是在 hash table 的基础上的一个跃进。不同的是TA引入了两套 hash functions 和两个线性表,每个函数对应一个线性表。同一个key可以在两个表上各对应一个位置。如图所示:
看,两个函数对应两个线性表。
添加操作和哈希表类似,把key 映射到线性表的一个位置,因为有两个表了,我们可以先随便选一个表来放,比如用第一个哈希函数映射到第一个表的一个位置,如图所示:
就这样我们可以加载很多记录到线性表里边,如果其中一个表的映射位置有人了,那就用另外一套哈希函数去映射到另外一个表,然后加载在第二表的相应位置。然鹅,假设下一个加载的记录,非常不幸,用两个哈希函数映射出来的两个表上的位置都正好已经有人了,这个时候怎么办呢?
这个时候,我们新的记录就会把已经在的人踢到另外一个表的相应位置上,那个位置则由相应表的哈希函数决定。如图:
如果又不幸的碰到被踢到的地方又有人了,那就把那个位置上的人继续踢到另一个表的位置。以此类推,直到把被踢的记录安顿好,或者又碰到之前踢别人的那个记录,形成环路为止。如图所示:
现在大家知道为什么这个算法叫Cuckoo Hash了吧。cuckoo其实就是布谷鸟,他们喜欢把自己的蛋产在别人的窝里,然后把别人的蛋踢出去。跟我们刚才描述的cuckoo hash的加载算法还真的是神似呢。 看看这个经典的图:
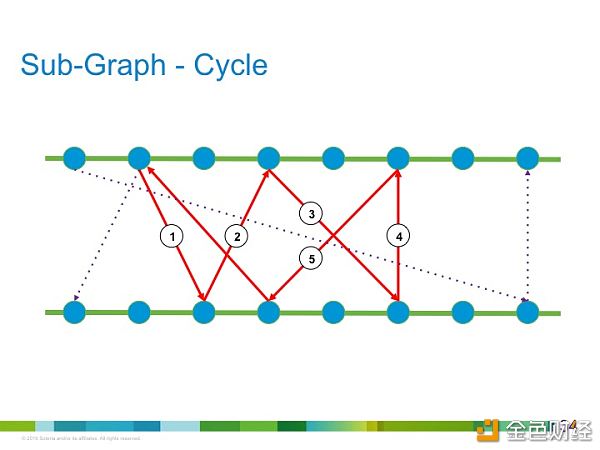
我第三次停顿一下,大家消化一下这个算法的过程,这是非常重要的算法。后边稍微烧脑了,不过绝对没有公式,我们把加载和踢的路线在图上表达出来就可以看到下边这个有向的二分图:
这个就是布谷鸟把别人家的蛋踢出去的路线图。在这个二分图里边其实可能存在着一个子图,这个子图正好是一个环,就像我们之前说的,踢着踢着居然踢到自己呆的那个位子了。如下图所示:
我们前边提到的那个算法其实就是在一个随机生成的一个二分图里边找一个特定长度的环状结构。这个过程其实基本上是对内存的访问和存取,完全符合我们之前提到的那几个必要的特性: 1. 算法需要巨大的内存空间:这个二分图是很大的; 2. 对内存的访问不可以预测:这个图本身是随机生成的; 3. 算法不可以存在时间复杂度和空间复杂度的转换:找环路这个问题还真是不能换。 这个算法让我们有可能在“公平挖矿”这个目标的方向往前近了一步。有很多设计和实现上的细节我们会在下一次分享中仔细讨论。 我所在的城市在北加州 这两天由于恶劣的天气导致大面积停电。给大家看一下停电的地图吧。
我们会在下次的分享中着重介绍这个PoW算法的工作原理,并且给大家预演一下公平挖矿在SoteriaDAG这个项目中的设计和实现。今天的分享就先到这里吧,我这边分分钟会一片黑暗,抱歉没有足够的时间在线回答大家的问题了。不过没关系,你们的所有问题都会被汇总,等我们这边来电了,我们再会以文章的形式分别回答。另外后边还会有更多的文字分享。我们马上还会在我们的 https://github.com/soteria-dag/soterd 上发布挖矿更新。敬请期待,谢谢大家! Claire: 感谢朱博士为我们带来了这么丰富的资讯。时间过得真快,又到今天主题分享的尾声了。我相信大家还有很多问题或观点,欢迎你们继续在社区留言和讨论,我们会收集给朱博士和 Soteria 团队 , 他们会在适当的时候再和大家讨论。再次感谢朱江博士在百忙之中为我们准备这么丰富的硬核资讯!我们下次再见。 朱江:谢谢大家 ! 谢谢主持人Claire. (全文完) —- 编译者/作者:Soteria 玩币族申明:玩币族作为开放的资讯翻译/分享平台,所提供的所有资讯仅代表作者个人观点,与玩币族平台立场无关,且不构成任何投资理财建议。文章版权归原作者所有。 |
Soteria 主题分享丨平等挖矿之一:计算与存储之争
2019-10-14 Soteria 来源:区块链网络


























LOADING...
相关阅读:
- 谁是以太坊的创始人,他们现在在做什么?2020-08-02
- 中国仲裁员表示加密镇压并不意味着禁止BTC2020-08-02
- 暴跌后牛市就走了?8月2日分析记2020-08-02
- 牛市来了准备发车2020-08-02
- 还是老老实实的屯币靠谱2020-08-02