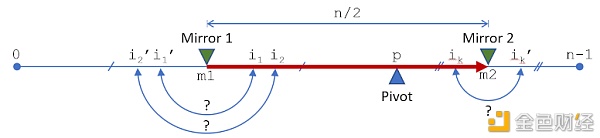
简介 如果你想学鬼步舞 (shuffle dance) 的话,那你就走错地方了。但相信我,Eth2里的混洗 (shuffle) 也一样让人兴奋。 混洗列表是以太坊2.0里一个基本运算。它主要用于在每12秒的slot里伪随机挑选验证者来组成委员会,以及在每个slot里选出信标链区块的提议者。 混洗似乎相当简单。尽管它有一些隐患需要注意,这些隐患在计算机科学里是非常容易理解的。其中的黄金标准大概就是Fisher-Yeats shuffle了。那我们为什么不在Eth2里使用它呢?我将在文末详细解释,但简单来说就是——轻客户端。 我们用的混洗算法是swap-or-not,而不是Fisher-Yates。这个选择是基于这篇本来用于构建加密方案的论文。我最近在Eth2客户端Teku中重写我们的实现,因此我想趁热把它写出来。 Swap-or-Not混洗算法 一轮的操作过程 混洗以轮次进行。每轮的过程是一样的,因此我在下面只会演示一轮的过程,它比看上去简单多了。 选择一个轴心点并找出第一个镜像索引 首先,我们选一个轴心索引p,这是基于轮次和其他一些种子数据,通过伪随机选出的。这个轴心选出后就在该轮次里固定了。 基于这个轴心点,我们在p和0的中间点选出一个镜像索引m1,即m1=p/2。(为了方便解释,我们将忽略麻烦的差一错误舍入问题)
轴心点和第一个镜像index 从第一个镜像索引到轴心点,替换与否 对于镜像索引m1和轴心索引p之间的每个索引,我们随机决定是否对这些元素进行替换。 比如对于索引i1,如果我们选择不替换,那么我们就继续选下一个索引。 如果我们决定替换,那么我们将i1上的列表元素与i1’上的替换,即它在镜像索引上的图像。也就是i1与i1’=m1-(i1-m1)替换,这样i1和i1’到m1的距离是相等的。 我们对每个m1和p之间的索引都做相同的swap-or-not的决定。
从第一个镜像索引到轴心的swap-or-not决定 计算第二个镜像索引 在做完从m1到p的所有索引决定后,我们现在找到第二个以m2为中点的镜像索引,即到p和列表末端的距离相等的点。也就是m2=m1+n/2。
第二个镜像索引 从轴心点到第二个镜像,替换与否 最后,我们重复swap-or-not的过程,考虑所有点到轴心p替换的决定,即p到第二个镜像m2的决定。如果我们选择不替换,就继续下一个。如果我们选择替换,那么我们在镜像索引m2上把j1上的元素与它在j1’上的镜像进行替换。
从轴心到第二个镜像索引的swap-or-not决定 组合起来 在一轮的最后,我们都已经考虑了m1到m2之间所有的索引,即所有索引的一半,且无论替换与否,每个索引都在另一半有一个特定的索引。因此,关于替换与否,所有的索引都已被考虑过一次了。 下一轮以增加 (或减少) 轮次开启,这样我们会有一个新的轴心索引,然后开始循环上述的过程。
同一轮中从一个镜像移向另一个镜像的过程 有趣之处 巧妙的地方 当在决定要不要替换的时候,这个算法会巧妙地选择候选索引或其镜像中的更高者。意思是当在轴心之下时,被选择的是i_1而不是i_1’;当在轴心之上时,被选择的时i_k’而不是i_k。这意味着,我们可以灵活遍历列表中的索引:我们可以将0到m1和p到m2分为两个独立的循环,或将两者合在同一个从m1到m2的循环,如我在上文所描绘(和实现)的。这两种做法的结果是一样的:无论我考虑的是i_1还是镜像i_1’都没有关系;替换与否得出的是相同的结果。 轮次 在Eth2,上述的过程会进行90次。原始论文里提到要经历6lgN个轮次才能“开始在选择性密码攻击 (CCA) 上出现较好的安全性界限”,其中N是列表的长度。在Vitalik的注释规范里,他说“密码学专家建议我们4log2N个轮次就能提供足够的安全性了”。 在Eth2里验证者数量的绝对最大值,也就是我们需要混洗的列表最大次数,大概是222 (420万)。Vitalik给出的预估值是88轮,在论文里的预估值是92轮 (假设lg是自然对数)。因此,我们现在处于一个大致正确的范围,特别是我们最后非常可能没有这么多活跃验证者。 基于列表长度来调整轮次可能会得出有趣的结果,但我们不会这么做,这可能是不必要的优化。 有意思的是,当Least Authority审计信标链的规范时,他们一开始发现在选择区块提议者的混洗中是有偏倚的 (参考Issue F)。但结果是他们错误使用了只有10轮次的混洗配置。当他们将混洗配置增加到90轮 (我们在主网使用的轮次) 时,偏倚的情况消失了。 (伪) 随机 混洗算法要求我们在每一轮里随机选一个轴心点,且在每轮里随机选择是否对每个元素进行替换。 在Eth2,我们肯定会从一个种子值产生随机性,由此这同一个种子总会产生同一个混洗结果。 轴心指标是由把与轮次串联的种子进行8字节的SHA2哈希产生的,轴心索引由种子值SHA2哈希的八个字节生成,该种子值与轮次相串联,因此它通常在每轮里都有会改变。 用来决定是否要替换元素的决定性数位从以下几个元素中提取:种子的SHA256哈希、轮次、列表上元素的索引。 效率 这个混洗算法比Fisher-Yates算法要慢得多。如果Fisher-Yates算法需要N次混洗的话,我们的算法平均需要90N/4次。我们还要考虑伪随机性的产生,这是算法中成本最高的部分。Fisher-Yates需要接近Nlog2N数位的随机性,而我们需要90(log2N+N/2)数位,根据我们在Eth2里需要的N值范围,超出的数位是相当多的?(当N为一百万时,Eth2大约需要N的两倍)。 为什么选择swap-or-not这种算法 如果效率不高,为什么要选择这个实现? 对单一元素进行混洗 这个算法的闪光点在于,如果我们只关注少数几个索引,我们不需要对整个列表的混洗进行计算。事实上,我们可以将这个算法用于单个索引,来找出哪个索引将会被替换。 因此,如果我们想知道索引217的元素被混洗到哪里了,我们可以运行只针对该索引的算法,而无需混洗整个列表。此外,相反地,如果我们想知道是什么元素被混洗到索引217,我们可以将算法倒过来运行来找到元素217 (倒过来的意思是从高到低运行轮次,而不是从低到高)。 总之,我们可以在恒定时间内计算出元素?i?被混洗到哪里,也可以计算出元素?i?的源头在哪里 (用反向操作),计算时间并不取决于列表的长度。Fisher-Yates混洗并不具有这种特性,且不能对单个索引进行混洗,它们往往需要重复混洗整个列表。 在Eth2规范里写的就是关于如何将算法应用到对单个索引进行混洗。事实上,一次性混洗整个列表只是它的一种优化!如果我们想的话,我们可以轮流只对列表里的一个元素进行混洗:(反向) 运行混洗来找出哪个元素最终落在索引0,再运行一次混洗找出哪个元素最终落在索引1,如此进行下去。 我们不那样做的原因只是由于决定swap-or-not需要一次性生成一个256位的哈希,且就这样抛弃255位是很浪费的。如果我们使用1位的哈希或预言,混洗列表中一个元素的效率与混洗整个列表相去无几。 做到真正的“轻”客户端 这个特性之所以有意义,原因全在于轻客户端。轻客户端相当于是Eth2信标链和分片链的观测者,他们不储存整个状态,但希望可以安全地访问链上的数据。要对他们的数据正确性进行验证,即没有发生欺诈,其中的必要一步就是对证明数据的委员会进行计算。 也就是要用到混洗算法,且我们并不希望轻客户端必须存储或是混洗整个验证者列表。通过swap-or-not混洗,他们可以只对他们需要的一小部分委员会成员进行计算,这样将在整体上大幅提高效率。 历史 如果你像我一样喜欢GitHub的考古特性,你可以在这里查看最初为Eth2寻求混洗算法的讨论,这里公布了最后的胜出者。 如果想从另一个角度看swap-or-not混洗算法,可以看一下Protolambda发表的一个更可视化的解释。 最后 这张图片是2019年我在EthCC上一边听Justin Drake讲swap-or-not混洗,一边在Teku客户端 (当时它还叫Artemis) 中实现初版swap-or-not混洗。?
作者 | Ben Edgington —- 编译者/作者:ETH中文网 玩币族申明:玩币族作为开放的资讯翻译/分享平台,所提供的所有资讯仅代表作者个人观点,与玩币族平台立场无关,且不构成任何投资理财建议。文章版权归原作者所有。 |
以太坊2.0的混洗算法
2020-09-18 ETH中文网 来源:区块链网络





LOADING...
相关阅读:
- 通过DeFi Pulse设置协议合作伙伴以启动10令牌DeFi索引(DPI)2020-09-16
- 新公司要如何推广?2020-09-13
- 区块链数据索引项目 The Graph 新增索引器栈,实现完全可扩展的代理设置2020-09-07
- 深入了解TheGraph(下)2020-09-03
- 加密谷日报 | 去中心化交易协议 Uniswap 推出代币列表索引,以解决假币2020-08-27