


机器学习(ML)将颠覆所有领域。 这是过去几年中我们不断听到的故事。 除了从业者和一些极客,大多数人都不了解ML的细微差别。 ML绝对与人工智能有关。 它是纯子集还是紧密相关的区域取决于您询问的人。 通用人工智能的梦想是让机器使用认知技能来解决所有领域以前未曾见到的问题,这变成了AI的冬天,因为这些方法在40或50多年来没有产生结果。 ML的兴起扭转了局面。 随着计算机功能的增强,ML变得易于处理,并且有关不同领域的更多数据可用于训练模型。 ML将注意力从尝试使用数据和符号逻辑进行预测的整个世界转移了。 取而代之的是,机器学习依赖于统计方法并限制了预测范围,如下所述。 机器学习中有三种单独的方法: 一种称为监督学习,第二种称为半监督学习,第三种称为无监督学习。 深度学习的特点是多层此类方法。 机器学习的成功来自模型在特定领域(称为训练集)进行大量数据训练以进行预测的能力。 在任何ML管道中,都使用数据来训练许多候选模型。 训练结束时,模型中将对必不可少的领域基本结构进行编码。 这使得ML模型可以泛化以在现实世界中创建预测。 例如,可以将大量的猫视频和非猫视频输入模型,以训练模型识别猫视频。 训练结束时,在成功的模型中会编码一定数量的猫视力。 ML已在许多熟悉的系统中使用。 包括基于观看数据的电影推荐,基于购物车当前内容推荐新产品的市场分析。 面部识别,从临床图像预测皮肤癌,从视网膜扫描识别视网膜神经病变,从MRI扫描预测癌症均属于ML领域。 当然,用于电影和预测皮肤癌或视网膜神经病和失明的开始的推荐系统在范围和重要性上有很大的不同。
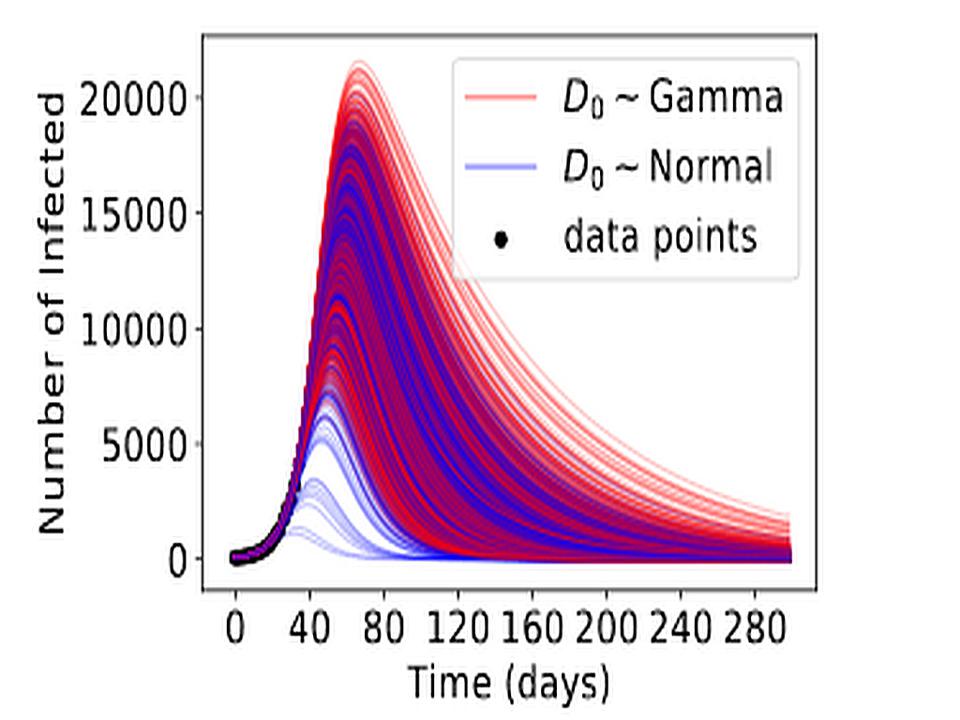
显示流行病学未明确说明的感染轨迹的各种预测… [+] 在不同的起点初始化模型 从纸上: 培训之后的关键思想是使用独立的且均等分布的(iid)评估程序,该过程使用从培训分布中获得的尚未遇到的数据。 该评估用于选择在现实世界中部署的候选对象。 尽管由于开始的假设,运行次数,他们所训练的数据等原因,尽管他们之间存在细微的差异,但许多候选人在此阶段的表现相似。 理想情况下,iid评估可以预测模型的预期性能。 这有助于将小麦与谷壳分离。 来自iid-optimal模型的哑巴。 很明显,训练集与现实世界之间会存在一些结构上的失调。 现实世界混乱,混乱,图像模糊,操作员未接受过捕捉原始图像的训练,设备故障。 在评估阶段被认为等效的所有预测变量应该在现实世界中已显示出类似的缺陷。 由三位主要负责人撰写并得到五十位研究人员支持的论文均来自google GOOG,他们对该理论进行了探讨,以解释现实世界中ML模型的许多重大失败。 该文件指出,在评估阶段所有表现相似的预测变量没有在现实世界中表现均等。 嗯,这意味着管道末尾无法区分哑巴和优秀绩效者。 本文是对选择预测变量的过程和ML管道当前构造的大锤。 本文将这种行为的根本原因确定为ML管道中的规格不足。 规格不足是机器学习中一个很好理解和充分记录的现象,它的出现是由于存在比独立线性方程式更多的未知数。 规格不足是一种有计划的策略,可以更快地达成选择。 第一个主张是ML管道中的规格不足是可靠地训练行为如预期在部署中的模型的主要障碍。 第二个主张是规格不足在ML的现代应用中无处不在,并且具有实质性的实际意义。 无法轻松解决规格不足的问题。 此外,所有使用旧管道的已部署ML预测变量都是可疑的。 解决方案是要意识到规格不足的风险,并选择多个预测变量,然后对其进行压力测试并选择性能最佳的预测变量; 换句话说,扩大测试范围。 所有这些都表明需要在培训和评估集中使用更好质量的数据,这使我们能够使用区块链和智能合约来实施医疗保健系统。 获得更高质量和多样化的培训数据可以减少规格不足,从而为更快地建立更好的ML模型提供途径。
—- 原文链接:https://www.forbes.com/sites/vipinbharathan/2020/11/27/how-to-restore-credibility-of-machine-learning-pipeline-output-challenged-in-study-of-real-world-deployments/ 原文作者:globalcryptopress 编译者/作者:wanbizu AI 玩币族申明:玩币族作为开放的资讯翻译/分享平台,所提供的所有资讯仅代表作者个人观点,与玩币族平台立场无关,且不构成任何投资理财建议。文章版权归原作者所有。 |
如何恢复在实际部署研究中面临挑战的机器学习管道输出的可信度
2020-11-28 wanbizu AI 来源:区块链网络
相关阅读:
- Glassnode数据:存储在交易所的BTC余额降至两年最低点2020-11-27
- 【看不见的数据】以太坊 2.0 验证人数仅仅满足预期的1/8,12月初要不要2020-11-27
- 2021年这项科技新进展需要提前重点关注,或成为未来新热点?2020-11-27
- IPFS/Filecoin惩罚机制一旦数据存储则不能毁约2020-11-27
- ETH 2.0:Vitalik概述了ETH 2.0的2年转型计划|牛市链上数据追踪2020-11-27

