都在说分布式搜索好,能落地才是重头戏! 一、痛点的背后是创新的空间 关于分布式搜索引擎,现在大家都怎么看呢?达瓴看到有说是Web3.0数据价值转换的重要板块的,也有说中心化搜索引擎不够中立、数据泄露、数据丢失等问题,进而突出分布式优势的。但是说实话,单纯去比较分布式和中心化搜索引擎的好和坏,其实意义不大。 因为就目前的应用价值来看,中心化搜索引擎的应用价值肯定是比分布式搜索引擎大很多,这是由时间积累所决定的。想要通过技术研发的突破就去替代某些中心化巨头引擎,显然是不现实的。 但毕竟中心化搜索引擎存在诸多缺点,所以当人们开始思考有没有办法去做一些改变时,就一定会创新出一种能弥补中心化缺点的搜索引擎——分布式搜索引擎。 二、分布式搜索引擎的第一步必须是“存数据”,还得是“有效数据” 由此从创新价值的角度来看,讨论分布式与中心化搜索引擎的对比是有必要的。但最终想要落地,还是要殊途同归,分布式还是要向中心化“学习”,该落地的步骤一个也不能少了解更多加 Slf345678。 那么,这第一步怎么走呢?可能很多人会直接搬出IPFS和HTTP的优缺点对比,告诉大家IPFS能降低存储成本、加快网络访问速度、保障数据安全,一定要应用IPFS。但是要知道HTTP已经存在20余年,其背后存储的文件数量要远远超出IPFS。即使目前在IPFS上存储的数量文件已超过50亿份,这个数据的悬殊也绝对不是一两年就能追上的。 而对于搜索用户来说,能够快速得到想要的结果才是第一位,偶尔“牺牲”下隐私对他们看来是无关痛痒的,若是连一点数据搜不到,哪里还来谈分布式呢?HTTP不香吗? 所以,分布式搜索引擎的第一步必须是““存数据”,而且还得是“有效数据”!这就很好地解释了为什么分布式存储的项目要比搜索引擎快一步落地呢?毕竟相比起怎么设计算法能让用户快速查到内容,有内容给查才是基本。 2021年5月26日,发改委、网信办、工业和信息化部、能源局联合,明确提出布局全G算力网络G家枢纽节点,启动实施“东数西算”工程,构建G家算力网络体系。 在这样的背景下,分布式存储能从架构上解决了数据存储的安全问题,并能减少能源消耗,完全是助力“东数西算”工程的好帮手!因此达瓴相信分布式存储的数据一定会越来越充足,这会是必然的结果。 可是,分布式存储不能因为技术等优势就干等着数据送到嘴里,主动去设计激励手段,不断创建新的生态,才能加速实现国家数据安全的建设。这样看来,存数据的“球”现在传到了激励层的脚下,怎么做好激励,怎么建好生态,成为分布式项目能否落地的关键。 有些项目直接一来就用token奖励用户去刚刚搭建好的搜索界面搜索,以扩充数据。但此时搜索到的大部分还是HTTP打头的中心化网页,少部分存在的IPFS的网页可能无法满足搜索需求。更多项目还是以奖励存储数据的用户为主,存储商户也能通过机器P盘数据获得token奖励,以此实现良性循环。 但俗话说得好,想象总是美好的,现实总是残酷的。虽说任何生态都需要token做支撑,但是为了这个目的才去建设生态的项目比比皆是。大家还没有开始用token筑起生态,就开始按捺不住,先玩起token的金融价值,想着赚波快钱。 所以说,如果能将设计的激励层和生态共同促进,就是掌握了此类项目成功的部分关键要素。 三、生态的核心——激励机制 激励模式一定是要有回流和循环的,token不能只是外送到一个地方后就固定了,没有流转的设计,token就很难实现它的价值。因此分布式搜索的激励层设计一定要合理,且肯定要比存储项目考虑得更多,设计到的各方利益面也更复杂。 上文看来,激励层首先就是要激励用户和存储商户去存储数据,存了以后还需要存储商户及时打包上链,所以最开始的激励力度肯定是要偏向于二者的。例如:传统云存储的代表——阿里云,据官网数据显示,其对存储商户的收费=固定费用+数据大小(单位:GB)*倍数,达瓴估算该固定费用为65180元,倍数为8.25左右。 因此,在不考虑固定费用的情况下,存储1GB的数据大约需要8.25元。紧接着派出分布式存储的代表——IPFS的激励层Filecoin,据调查,每个FIL每天可以存储约782.73GB的数据容量,折算下来存储1GB的数据大约需要0.623元。 这样一对比就可以发现分布式项目在存储数据成本方面有着显著优势。更有项目加大力度,不仅不收取存储数据者的费用,反而奖励其token,以实现数据层的快速建设。
除了针对用户的存储费用激励,不少项目也奖励token给打包数据的存储商户,以加速数据上链。比如最近主网即将上线的QitChain(QTC),基于Web3.0有效数据存储的分布式搜索引擎,以不同的网络节点来存储数据,防止丢失。 QTC在生态建设上就根据用户搜索的关键词,列出分布式节点中的所有结果,中间不插入广告,同时采用了加密技术,除非用户会通知他人,对方才能拥有用户的私人数据密钥。因此用户在QTC的生态里可以完全控制自己的数据信息。 据QTC的官方白皮书显示, 其通过设计长期激励的经济模型保证整个生态的良性发展,同时对现有 POC 进行优化做出了一些改进,将其升级为CPOC(Conditioned-Proof of Capacity)共识,并增加了 POS 权益激励,可以增强社区共识度。 CPOC条件的发行方式会让参与方的产生正向商业博弈,使整个系统始终会有一个较为主力的临时商业既得利者去无形推动整个生态。
四、搜索引擎的定位不同,有效数据的内容也不同 而且需要注意的是,不同的搜索项目聚焦的数据也是不同。例如:The Graph作为一个查询区块链数据的索引协议,允许使用查询语言GraphQL查询不同的网络(ETH或IPFS)了解更多加 Slf345678。 在The Graph的资源管理器中,用户可轻松查找最流行协议(如Uniswap,Compound,Balancer或ENS)的子图,而子图能提供对许多有用数据的访问,比如说自协议启动以来所有买卖对的总买卖量,每个买卖对的买卖量数据以及有关特定token或买卖的数据等。因此对它们来说,有效数据主要是由区块链项目的各种数据分析和历史数据组成的。 由此看来,搜索引擎的定位不同,有效数据的内容也不同。但是可以肯定的是,项目方需要重视有效数据在数据层中的重要作用,并在有效数据的数量与奖励之间设定相关关系,以实现一个合理的数据区间。
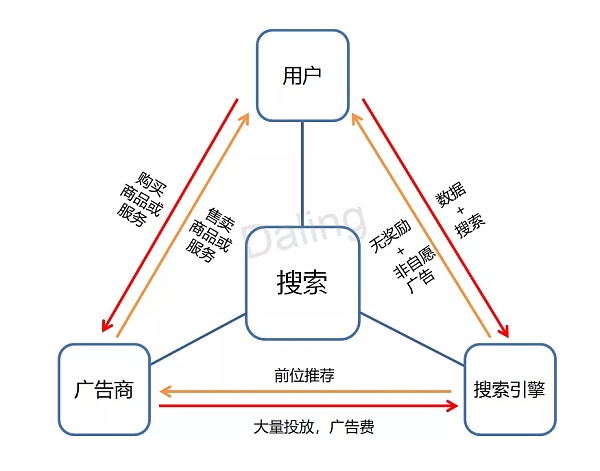
总的来说,只有激励层设计好了,数据这一层的基础才能打好,再来走搜索就好走多了! 五、生态的流动——收益机制 如果数据有了,怎么提供给用户一个较好的搜索体验,怎么平衡用户、广告商和项目方的收益,是分布式搜索引擎的另一关键。 在中心化搜索引擎下,我们的个人信息经常通过一些表单、记录等方式被跟踪和记录了,紧接着这些信息就被用于各种各样的广告活动。企业也要为此付出巨额的资金,才能在在线消费的产业中分得一杯羹。 此时的关系就如下图所示,红色箭头为资金流动方向。可见在此生态下三方处于极不公平的地位,资金流动性一致偏向搜索引擎的项目方。
传统搜索引擎的运行机制 因此,若要让分布式搜索引擎长久发展下去,项目方需要开创新的生态环境。在这里资金是流动循环的,用户可以选择开放自己的数据,并让广告商对这一数据进行投放,而广告商所支付的广告费将会与数据的所有人进行分成。在这样的布局下,三方都能有进有出,生态才得以建设起来。 这里可以来看分布式搜索引擎Boogle的设计。其规定一旦用户选择开放自己的数据,并让广告商对这一数据进行投放时,其所支付的广告费用将会与数据的所有人进行分成。 在Boogle中,每个广告点,会有10%的费用被分给用户,仅15%直接支付给项目方,剩余的通证则将全部转入一个公开的销毁地址。因此在这样的设计中,资金流动性没有偏向固定的一方,反而在不停的进行流转,这才是搜索引擎该有的样子! 分布式搜索引擎的运行机制 六、分布式搜索的未来 其实一个好的分布式搜索引擎还有许多方面需要注意,无论是对数据信息的筛选、审核,还是对用户习惯的调试,亦或是未来在存储、搜索的基础上开拓更多的分布式应用了解更多加 Slf345678,例如:支付、通讯、邮件等等,这都需要项目方细细打磨。 我们相信:IPFS/Filecoin,了解更多加 Slf345678分布式搜索引擎的未来一定是稳步前进的,但其落地绝对不是靠炒token实现的,而是项目方匠心打造的生态,这其中包括索引奖励、隐私计算、边缘计算等一系列技术的叠加以及Dapp的兴起。希望大家能给予认真落地的分布式搜索引擎项目足够的信心和耐心,不要浮躁于token价格的起起伏伏,分布式搜索引擎的未来将由大家一起创造和见证。 查看更多 —- 编译者/作者:蔡蔡解读 玩币族申明:玩币族作为开放的资讯翻译/分享平台,所提供的所有资讯仅代表作者个人观点,与玩币族平台立场无关,且不构成任何投资理财建议。文章版权归原作者所有。 |
IPFS系列之Web3.0有效数据和分布式搜索
2021-08-20 蔡蔡解读 来源:区块链网络


LOADING...
相关阅读:
- 挖矿生财有道2021-08-20
- 行业动态:数字经济时代法治建设的五大任务2021-08-20
- BSPC生态是什么?BitstampPro比特印记详细介绍(建议收藏)2021-08-20
- 全网算力将突破10EiB,5点分析Filecoin为何如此与众不同?2021-08-20
- 海南日报:到底是谁偷走了我们的隐私?2021-08-19