6月9日,为期两天的「北京智源大会」在中关村国家自主创新示范区会议中心成功开幕。 智源大会是智源研究院(也被称为中国OpenAI的最强中国AI研究院)主办的年度国际性人工智能高端专业交流活动,定位于「AI内行顶级盛会」,也被戏称为「AI春晚」——从参会嘉宾阵容可见一斑: 图灵奖得主Geoffrey Hinton、Yann LeCun(这也是深度学习三巨头之二,另一位Bengio出席过之前的大会)、Joseph Sifakis和姚期智,张钹、郑南宁、谢晓亮、张宏江、张亚勤等院士,加州大学伯克利分校人工智能系统中心创始人Stuart Russell,麻省理工学院未来生命研究所创始人Max Tegmark,OpenAI首席执行官Sam Altman(这也是他的第一次中国演讲,虽然是线上)、Meta、微软、谷歌等大厂和DeepMind、Anthropic、HuggingFace、Midjourney、Stability AI等明星团队成员,总共200余位人工智能顶尖专家……
这两天跟着追完了大会直播,作为一个不懂技术的文科生,竟然听得津津有味,收获满满。 不过,看完最后图灵奖得主、「深度学习之父」Geoffrey Hinton 的演讲,一种强烈而复杂的情绪笼罩了我: 一方面,看到AI研究者们对各类前沿技术的探索和畅想,会自然而然地对AI乃至未来的通用人工智能AGI的实现更有信心了; 另一方面,听到最前沿的专家学者们讨论AI的风险、以及人类对如何应对风险的无知和轻视,又对人类的未来充满担心——最本质的问题,用Hinton的话来说就是:历史上从来没有过更智能的事物被不那么智能的事物控制的先例,假如青蛙发明了人类,你觉得谁会取得控制权?是青蛙,还是人? 由于两天的大会信息量爆炸,花点时间整理了一些重要演讲的资料,顺便记录下自己的一些感想,方便后续复习查阅,也分享给关心AI进展的各位。 说明:下文标【注】部分为个人感想,内容概括为引用(能力有限自己写不出来-_-||),出处为每部分最后的链接,部分有修改。 OpenAI CEO Sam Altman:AGI或将十年内出现 6月10日全天的“AI安全与对齐”论坛,OpenAI联合创始人Sam Altman进行了开场主题演讲——也是他第一次中国演讲,虽然是线上。 演讲围绕模型的可解释性、可扩展性和可泛化性给出了见解。随后,Sam Altman和智源研究院理事长张宏江开展了尖峰问答,主要探讨在当前的AI大模型时代,如何深化国际合作,如何开展更安全的AI研究,以及如何应对AI的未来风险。
精彩摘要: 当下人工智能革命影响如此之大的原因,不仅在于其影响的规模,也是其进展的速度。这同时带来红利和风险。 AI 带来的潜在红利是巨大的。但我们必须共同管理风险,才能达到用其提升生产力和生活水平的目的。 随着日益强大的 AI 系统的出现,全球合作的赌注从未如此之大。大国意见分歧在历史上常有,但在一些重要的大事上,必须进行合作和协调。推进 AGI 安全是我们需要找到共同利益点的最重要的领域之一。演讲中,Altman多次强调全球AI安全对齐与监管的必要性,还特别引用了《道德经》中的一句话:千里之行,始于足下。对齐仍然是一个未解决的问题。 想象一下,未来的 AGI 系统或许具有 10 万行二进制代码,人类监管人员不太可能发现这样的模型是否在做一些邪恶的事情。 GPT-4 花了八个月的时间完成对齐方面的工作。但相关的研究还在升级,主要分为扩展性和可解释性两方面。一是可扩展监督,尝试用AI系统协助人类监督其他人工智能系统。二是可解释性,尝试理解大模型内部运作「黑箱」。最终,OpenAI的目标是,训练AI系统来帮助进行对齐研究。
在被张宏江问及距离通用人工智能(AGI)时代还有多远时,萨姆·奥特曼表示,“未来10年内会有超强AI系统诞生,但很难预估具体的时间点”,他也强调,“新技术彻底改变世界的速度远超想象。” 当被问及OpenAI是否会开源大模型,Altman称未来会有更多开源,但没有具体模型和时间表。另外,他还表示不会很快有GPT-5。会后,Altman发文对这次受邀来智源大会演讲表示感谢。
图灵奖得主杨立昆:GPT模式五年就不会有人用,世界模型才是AGI未来 深度学习三巨头之一、图灵奖得主杨立昆带来了题为《朝向能学习、思考和计划的机器进发》( Towards Machines that can Learn, Reason, and Plan)的主题演讲,他一如既往地质疑目前LLM的路线,提出了另一种会学习、推理、计划的机器的思路:世界模型。
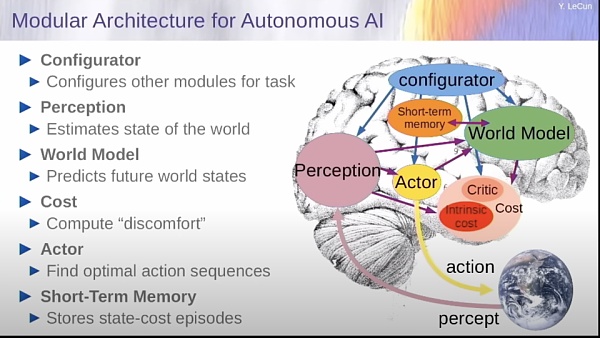
演讲核心观点: AI 的能力距离人类与动物的能力,还有差距——差距主要体现在逻辑推理和规划,大模型目前只能「本能反应」。什么是自监督学习?自监督学习是捕捉输入中的依赖关系。 训练系统会捕捉我们看到的部分和我们尚未看到的部分之间的依赖关系。目前的大模型如果训练在一万亿个 token 或两万亿个 token 的数据上,它们的性能是惊人的。 我们很容易被它的流畅性所迷惑。但最终,它们会犯很愚蠢的错误。它们会犯事实错误、逻辑错误、不一致性,它们的推理能力有限,会产生有害内容。由此大模型需要被重新训练。 如何让 AI 能够像人类一样能真正规划?可以参考人类和动物是如何快速学习的——通过观察和体验世界。 杨立昆认为,未来 AI 的发展面临三大挑战:学习世界的表征、预测世界模型、利用自监督学习。 首先是学习世界的表征和预测模型,当然可以采用自监督的方式进行学习。 其次是学习推理。这对应着心理学家丹尼尔·卡尼曼的系统1和系统2的概念。系统1是与潜意识计算相对应的人类行为或行动,是那些无需思考即可完成的事情;而系统2则是你有意识地、有目的地运用你的全部思维力去完成的任务。目前,人工智能基本上只能实现系统1中的功能,而且并不完全; 最后一个挑战则是如何通过将复杂任务分解成简单任务,以分层的方式运行来规划复杂的行动序列。 由此,杨立昆提出「世界模型(World Model)」,由六个独立模块组成,具体包括:配置器模块、感知模块、世界模型、cost模块、actor模块、短期记忆模块。他认为,为世界模型设计架构以及训练范式,才是未来几十年阻碍人工智能发展的真正障碍。
对于AI毁灭人类的看法,LeCun一直表示不屑,认为如今的AI还不如一条狗的智能高,这种担心实属多余。被问到AI系统是否会对人类构成生存风险时,LeCun表示,我们还没有超级AI,何谈如何让超级AI系统安全呢? 「今天问人们,我们是否能保证超级智能系统对人类而言是安全,这是个无法回答的问题。因为我们没有对超级智能系统的设计。因此,在你有基本的设计之前,你不能使一件东西安全。这就像你在1930年问航空工程师,你能使涡轮喷气机安全和可靠吗?而工程师会说,"什么是涡轮喷气机?" 因为涡轮喷气机在1930年还没有被发明出来。所以我们有点处于同样的情况。声称我们不能使这些系统安全,因为我们还没有发明它们,这有点为时过早。一旦我们发明了它们——也许它们会与我提出的蓝图相似,那么就值得讨论。」 MIT人工智能与基础交互研究中心教授 Max Tegmark:以机械可解释性去掌控AI Max Tegmark,现任麻省理工学院物理学终身教授、基础问题研究所科学主任、生命未来研究所创始人、大名鼎鼎的“暂停AI研究倡议的发起人”(3月底的那份倡议书上有伊隆·马斯克、图灵奖得主Yoshua Bengio、苹果联合创始人史蒂夫·沃兹尼亚克等1000+名人的联合签名),在智源大会上做了一个精彩的演讲,题目是《如何掌控AI》(Keeping AI under control),并与清华大学张亚勤院士进行了对话,共同探讨AI伦理安全和风险防范问题。 演讲详细讨论了AI的机械可解释性,这实际上是研究,人类知识究竟是如何储存在神经网络里那些复杂的连接关系里的。这个方向的研究如果持续下去,或许最终可以真正解释LLM大语言模型为什么会产生智能这个终极问题。 演讲之外,有趣的事实是,作为“暂停AI研究倡议”发起人,主题演讲却是关注如何进行一个更深入的AI大模型研究。也许正如Max自己最后所说, 他并非AI三巨头之一杨立昆教授所说的厄运者,他实际上对AI充满希望和向往,只是我们可以确保所有这些更强大的智能为我们服务,并用它来创造一个比科幻作家过去梦想的更鼓舞人心的未来。 注:本来以为会很枯燥,意外地非常精彩,津津有味地看完一个小时的最长演讲!不愧是经常讲课的教授,非常引人入胜,也非常有理论深度,而且深入浅出。更令人惊喜的是不仅不是古板的 AI 反对者,其实还是个更好的AI的倡导者!还会说中文,一边演讲还不忘一边给自己招生……
精彩观点摘录: 1、机械可解释性是一个非常有趣的领域。你训练一个你不理解的复杂神经网络来执行智能任务,然后尝试弄清楚它是如何做到的。 我们要这样如何做?您可以有三个不同层次的抱负。最低层次的抱负是仅对其可信度进行诊断,了解您应该信任它多少。例如,当您开车时,即使您不了解刹车的工作原理,您至少希望知道是否可以相信它会减速。 下一个层次的抱负是更好地理解它,以使其更加可信赖。最终的抱负是非常雄心勃勃的,这也是我期望的,那就是我们能够从机器学习系统中提取出它们学到的所有知识,并在其他系统中重新实现它们,以证明它们将按照我们的意愿行事。 2、让我们慢下来,让我们确保我们开发出更好的护栏。所以这封信说让我们暂停一下,前面提到过。我想说清楚,它并没有说我们应该暂停人工智能,它并没有说我们应该暂停几乎任何事情。到目前为止,我们在这次会议上听说过,我们应该继续做几乎所有你们都在做的精彩研究。它只是说我们应该暂停,暂停开发比GPT-4更强大的系统。所以这对一些西方公司来说主要是一个暂停。 现在,原因是这些正是系统,恰恰是可以使我们最快失去控制的系统,拥有我们还不够了解的超级强大的系统。暂停的目的只是让人工智能更像生物技术,在生物技术领域,你不能只说你是一家公司,嘿,我有一种新药,我发现了,明天开始在北京各大超市销售。首先你要说服中国政府或美国政府的专家,这是一种安全的药物,它的好处大于坏处,有一个审查过程,然后你就可以做到。 让我们不要犯那个错误,让我们变得更像生物技术,使用我们最强大的系统,不像福岛和切尔诺贝利。 3、张亚勤:好吧,Max,你的职业生涯是在数学、物理、神经科学,当然还有人工智能方面度过的。显然,在未来,我们将越来越依赖跨学科的能力和知识。我们有很多研究生,很多未来的年轻人。 在年轻人如何做出职业选择方面,您对他们有何建议? Max Tegmark:首先,我的建议是在人工智能时代,专注于基础知识。因为经济和就业市场的变化会越来越快。因此,我们正在摆脱这种学习12年或20年,然后余生都做同样事情的模式。它不会是那样的。 更重要的是,你要有扎实的基础,并且非常善于创造性、思想开放的思维。这样才能身手敏捷,随波逐流。 当然,要关注整个人工智能领域正在发生的事情,而不仅仅是在你自己的领域。因为在就业市场上,首先会发生的事情不是人被机器取代。但不与人工智能打交道的人将被与人工智能打交道的人所取代。 我可以再添加一点吗?我看到时间在那里闪烁。 我只想说一些乐观的话。我觉得Yann LeCun是在取笑我。他称我为厄运者。但如果你看看我,其实我很开心很开朗。对于我们理解未来AI系统的能力,我实际上比Yann LeCun更乐观。我认为这是非常非常有希望的。 我认为,如果我们全速前进,将更多的控制权从人类手中交给我们不了解的机器,那将以非常糟糕的方式结束。但我们不必那样做。我认为,如果我们努力研究机械可解释性和今天将在这里听到的许多其他技术主题,我们实际上可以确保所有这些更强大的智能为我们服务,并用它来创造一个比科幻作家过去梦想的更鼓舞人心的未来。
对话Midjourney创始人:图片只是第一步,AI将彻底改变学习、创意和组织 MidJourney 是当下最炙手可热的图片生成引擎,在 OpenAI 的 DALL·E 2 和开源模型 Stable Diffusion 等激烈竞争下,目前仍保持着多种风格生成效果的绝对领先。 Midjourney 是一家神奇的公司,11 人改变世界,创造伟大的产品,注定会成为 Pre AGI 初年的佳话。 注:期待已久的Midjourney创始人、CEO David Holz和极客公园张鹏的对谈,全英文,没有字幕,没想到完全听得懂,还特别津津有味,因为问答都太精彩了,尤其是David,回答的时候忍不住笑,笑起来像个天真烂漫的小孩,有过大团队管理经验的他说「我从不曾想过要一家公司,我想要有一个家。」,他带着直到现在也只有20来人的Midjourney成为举世瞩目的独角兽,可能改变了未来创业公司的范式。
创业驱动力:解放人类的想象力 张鹏:在过去的 20 年里,我认识了很多国内外的创业者。我发现他们有一些共同点,他们都有强烈的驱动力,驱使他们「无中生有」地探索创造。 我想知道,在你创立 MidJourney 的时候,你的驱动力是什么?在那个时刻,你渴望的东西是什么? David Holz:我从来没有想过要创办一家公司。我只是想要一个「家」(home)。 我希望在未来 10 年或 20 年,可以在 Midjourney 这里创造那些我所真正关心的和真正想为这个世界带来的东西。 我经常思考各种各样的问题。也许我不能解决每个问题,但是我可以做出一些尝试,从而让大家都能更有能力地解决问题。 因此,我尝试去思考如何解决,如何创造东西。我认为,这可以归结为三点。首先,我们必须反思自己:我们想要什么?问题究竟是什么?然后我们要想象:我们前进的方向在哪里?有什么可能性?最后,我们必须相互协调,与他人合作,共同实现我们所想象的事情。 我认为,在人工智能方面,有很大的机会将这三部分结合起来,并创造出重要的基础设施,使我们更擅长于解决这个问题。在某种程度上,人工智能应该能够帮助我们反思自己、更好地想象未来的方向、帮助我们更好地找到彼此并合作。我们可以一起完成这些事情,并将它们融合到某种单一的框架中。我认为这将改变我们创造事物和解决问题的方式。这就是我想做的 big thing。 我认为有时候(我们先做的)图片生成可能会让人感到困惑,但在许多方面,图片生成是一个已被认可的概念。Midjourney 已经成为了一个超级想象力的集合,数百万人共同探索着这个空间的可能性。 在未来几年里,会有机会进行更多的视觉和艺术探索,这可能会超过所有先前历史的探索总和。 这并不能解决我们面临的所有问题,但我认为这是一次测试,一次实验。如果我们能完成这次视觉领域的探索,那么我们也可以在其他事情上做到,其他所有需要我们一起探索和思考事情,我认为都可以通过类似的方式来解决。 因此,当我考虑如何开始着手解决这个问题时,我们有很多想法,建了很多原型,但是 AI 领域突然出现了突破性的进展,尤其是视觉方面,我们意识到这是一个绝无仅有的机会,能创造出一些别人从未尝试过的东西。这让我们想去为之尝试。 我们认为,也许过不了多久,这一切都将汇聚到一起,形成非常特别的东西。现在还只是个开始。 张鹏:所以,图片(生成)只是第一步,你的最终目标是解放人类的想象力。这是吸引你创立 Midjourney 的目标吗? David Holz:我真的很喜欢具有想象力的东西。我也希望这个世界能有更多的创意。每天都能看到疯狂的想法,这太有趣了。 重新理解知识:历史知识成为创造的力量 张鹏:这很有趣。我们通常说空口无凭,给我看你的代码(Idea is cheap, show me the code)。但现在,想法似乎才是唯一重要的东西。只要你能通过一系列优秀的 Prompt 表达你的想法,AI 就可以帮助你实现。所以,学习和创造的定义是否正在改变?你怎么看? David Holz:我觉得一个有趣的事情是,当你给人们更多的时间去创造时,他们也会对学习本身更感兴趣。 例如,美国有一种很流行的艺术风格叫做装饰艺术。我从来没有关心过这种艺术是什么,直到有一天,我通过指令就可以制作出这类艺术风格的作品时,我突然对它产生了很大的兴趣,想更多了解它的历史。 我觉得这是很有趣的一点,当历史成为你可以立即用起来并让你更简单地去创造的东西时,我们反而会对历史更感兴趣。如果用户交互界面变得足够好,让用户觉得 AI 成为了我们思维的延伸。AI 就仿佛是我们身体和思想的一部分,AI 又在一定程度上与历史紧密相连,而我们也将与历史紧密联系在一起。这太有意思了。 当我们问用户他们最想要什么时,通常排在第一第二的回复是他们想要学习材料,他们不仅是想要学习如何使用工具,还想要了解艺术、历史、相机镜头、光彩,想要了解和掌握所有可用于创造的知识和概念。 以前,知识只是过往的历史,但现在,知识成为了创造的力量。 知识在当下就能立即发挥出更大的作用,人们都渴望获得更多的知识。这可太酷了。 Brian Christian:《人机对齐》中文版新书发布 《人机对齐》中文版书籍发布,作者Brian Christian用10分钟简要介绍了整本书的主要内容,听起来内容非常丰富和精彩,也和当下AI的飞速发展非常呼应。 Brian Christian是一位获奖无数的科学作者。他的作品《算法之美》曾被评为亚马逊年度最佳科学书籍和《麻省理工科技评论》年度最佳书籍。他的新书《人机对齐》(The Alignment Problem: Machine Learning and Human Values)目前正在被翻译成中文,被微软首席执行官萨蒂亚·纳德拉评为2021年激励他的五本书之一。
《人机对齐》书分为3个部分。 第一部分探讨了影响当今机器学习系统的伦理和安全问题。 第二部分被称为代理,它将重点从监督和自我监督学习转移到强化学习。 第三部分建立在监督、自我监督和强化学习的基础上,讨论我们如何在现实世界中对齐复杂的AI系统。 北京大学人工智能研究院助理教授杨耀东:大语言模型的安全性对齐进展综述 注:北京大学人工智能研究院助理教授杨耀东做的《大语言模型的安全性对齐》演讲很精彩,首先中文演讲能听懂,其次他用了非常通俗易懂的语言解释了目前大语言模型安全对齐的主要研究进展,提纲挈领,在深度上超过很多讲RLHF进展的内容。 因为不懂详细的技术,只能大概理解原理,记录一些有意思的点: OpenAI提出的3种Align的方式: 训练AI使用人类反馈 训练AI协助人类评估 训练AI做对齐研究
AI大模型对齐市场仍是蓝海: 现有大模型除GPT以外,几乎都没有成功实现任何意义上的对齐 大模型通用到专用的转变技术,将是大模型发展的下一个制高点
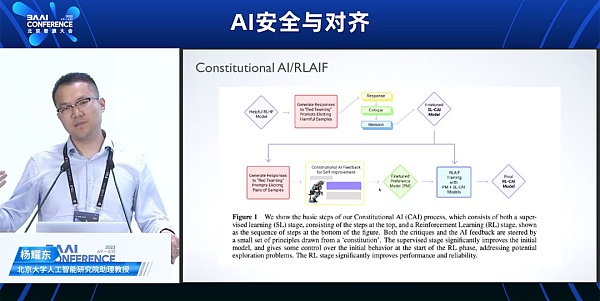
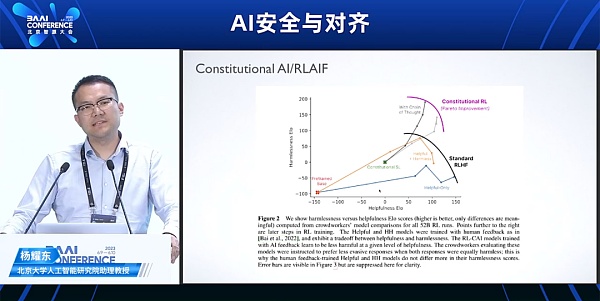
3种对齐安全的方式: 在预训练阶段,通过人工筛选和数据清洗,获取更高质量的数据 在输出阶段使用奖励模型进行 reject sampling,提高输出质量和安全性。或者在上线的产品中,拒绝回应用户的输入。 在微调 (SFT 和 BLHF) 阶段,增加更加多元且无害的用户指令和人类偏好模型进行对齐,包括RBRM、Constitutional Al。
从RLHF到RLAIF:Constitutional AI
图灵奖得主 Geoffrey Hinton:超级智能将会比预期快得多,很担心人类被它们控制 图灵奖得主、「深度学习之父」Geoffrey Hinton压轴演讲,主题是Two Paths to Intelligence 通向智能的两条通路。 AI教父带给我们的是一项让他相信超级智能将会比预期快得多的研究:凡人计算(Mortal Computation)。演讲描述了一种新的计算结构,在抛弃了软硬件分离的原则后,即不再用反向传播描述神经网络内部路径的情况下,如何实现智能计算。
演讲重点: 辛顿提出了一种全新的实现人工智能的可能:凡人计算。凡人计算让软硬件不再分离,用物理硬件更准确的做并行计算。它可以带来更低的能耗和更简单制作的硬件,但更难以训练和扩展到大规模模型上。 智能群体共享知识的方式有两种,生物性的和数字计算式的,生物性的共享带宽低,很慢,数字拷贝带宽高,且非常快。人是生物性的,而AI是数字性的,因此一旦AI通过多模态掌握更多知识,他们的共享速度很快,也会很快超越人类。 当AI进化到比人类更有智慧的时候,他们很可能会带来巨大的风险。包括对人类的利用和欺骗,试图获取权力。并且很可能对人类的态度并不友好。 全新的计算模式之所以被Hinton称为 Mortal computation,寓意是深刻的: 1)之前Hinton说过,永生事实上已经实现。因为当前的AI大语言模型已把人类知识学习到了千万亿的参数里,且硬件无关:只要复刻出指令兼容的硬件,同样的代码和模型权重在未来都可以直接运行。在这个意义上,人类智慧(而不是人类)永生了。 2)但是,这种软硬件分开的计算在实现的能量效率和规模上是极其低效的。如果抛弃硬件和软件分离的计算机设计原则,把智能实现在一个统一的黑盒子里,将是实现智能的一种新道路。 4)这种软硬件不再分离的计算设计将极大幅度降低能耗和计算规模(考虑一下,人脑的能耗才20瓦) 5)但同时,意味着无法高效的复制权重来复制智慧,即放弃了永生。 人工神经网络是否比真正的神经网络更聪明? 如果一个在多台数字计算机上运行的大型神经网络,除了可以模仿人类语言获取人类知识,还能直接从世界中获取知识,会发生什么情况呢? 显然,它会变得比人类优秀得多,因为它观察到了更多的数据。 如果这个神经网络能够通过对图像或视频进行无监督建模,并且它的副本也能操纵物理世界——那这种设想并不是天方夜谭。
注:正当大家以为演讲兴酱结束的时候,倒数第二页,Hinton——用一种和之前所有科学家都不同的、有点情绪化、百感交集的口吻——说出了他对当下飞速发展的AI的担忧,这也是在他最近毅然决然离开Google并「对自己毕生工作感到后悔,对人工智能危险感到担忧」后,全世界都好奇的心声: 我认为这些超级智能的实现可能比我过去认为的要快得多。 坏人们会想利用它们来做诸如操纵选民的事情。为此,他们已经在美国和许多其他地方使用它们。而且还会用于赢得战争。 要使数字智能更高效,我们需要允许其制定一些目标。然而,这里存在一个明显的问题。存在一个非常明显的子目标,对于几乎任何你想要实现的事情都非常有帮助,那就是获取更多权力、更多控制。拥有更多控制权使得实现目标变得更容易。而我发现很难想象我们如何阻止数字智能为了实现其它目标而努力获取更多控制权。 一旦数字智能开始追求更多控制权,我们可能会面临更多的问题。 作为对比,人类很少去思考比自身更智能的物种,以及如何和这些物种交互的方式,在我的观察中,这类人工智能已经熟练的掌握了欺骗人类的动作,因为它可以通过阅读小说,来学习欺骗他人的方式,而一旦人工智能具备了「欺骗」这个能力,也就具备前面提及的——轻易控制人类的能力。所谓控制,举个例子,如果你想入侵华盛顿的一座建筑物,不需要亲自去那里,只需要欺骗人们,让他们自认为通过入侵该建筑物,就能实现拯救民主,最终实现你的目的(暗讽特朗普)。
这时,年过花甲、为人工智能贡献了毕生心血的 Gerffery Hinton 说: 「 我觉得很可怕,我不知道如何防止这种情况发生,但我老了,我希望像你们这样的许多年轻而才华横溢的研究人员会弄清楚我们如何拥有这些超级智能,这将使我们的生活变得更好,同时阻止这种通过欺骗实现控制的行为……也许我们可以给他们设置道德原则,但目前,我还是很紧张,因为到目前为止,我还想不到——在智力差距足够大时——更智能的事物,被一些反倒没那么智能的事物所控制的例子。假如青蛙发明了人类,你觉得谁会取得控制权?是青蛙,还是人?这也引出我的最后一张PPT,结局。」
听的时候我仿佛在聆听「曾经的屠龙少年,人到暮年、回首一生时发现自己竟养出了恶龙时,发出的末日预言」,刚好夕阳西下, 我第一次深刻认识到AI对人类的巨大风险,无限唏嘘。 和Hinton相比,更年轻的深度学习三巨头之一 Lecun 显然更乐观: 被问到AI系统是否会对人类构成生存风险时,LeCun表示,我们还没有超级AI,何谈如何让超级AI系统安全呢? 让人想到《三体》里地球人对三体文明的不同态度…… 那天我还在无限唏嘘的情绪中打算关掉电脑,没想到,最后上场的智源研究院院长黄铁军做了一个完美的闭幕致辞:《无法闭幕》。 黄铁军首先总结前面大家演讲的观点: AI越来越强,风险显而易见,与日俱增; 如何构建安全AI,我们知之甚少; 可以借鉴历史经验:药物管理、核武管控、量子计算...... 但是高复杂度AI系统难以预测:风险测试、机制解释、理解泛化……刚开始 全新挑战目标:AI服务自己目标还是人类目标? 本质上,人们要建设GAI通用人工智能还是AGI人工通用智能? 学术上的共识是AGI人工通用智能:在人类智能所有方面都达到人类水平,能够自适应地应对外界环境挑战完成人类能完成的所有任务的人工智能;也可以叫自主人工智能、超人智能、强人工智能。 一方面,大家对建设通用人工智能热情高涨、投资趋之若鹜, 另一方面,对AI导致人类成为二等公民嗤之以鼻,但这样的二元对立还不是最难的,大不了投票,难的是,面对类似ChatGPT这样的类人工智能Near AGI,我们应该怎么办? 如果人类以和投资建设人工智能一样的热情应对风险,那也许还有可能实现安全的人工智能,但你相信人类能做到吗?我不知道,谢谢! 查看更多 —- 编译者/作者:张无常 玩币族申明:玩币族作为开放的资讯翻译/分享平台,所提供的所有资讯仅代表作者个人观点,与玩币族平台立场无关,且不构成任何投资理财建议。文章版权归原作者所有。 |
智源大会2023观后感:对AI更有信心也更担心人类了
2023-06-12 张无常 来源:区块链网络
















LOADING...
相关阅读:
- 《流浪地球》导演郭帆称以 ChatGPT 为代表的人工智能是一个技术革新2023-06-12
- 卓视智通获数千万元 Pre-B 轮融资,资金将用于 AI 大模型等新技术研发等2023-06-12
- 三星正开发 AI 大语言模型,已投入公司全部 GPU 资源2023-06-11
- AI风险堪比核能?诈骗、失控等众多黑暗面我们该如何应对?2023-06-11
- 郭帆:《流浪地球 3》主要探讨人类如何面对人工智能2023-06-05