来源:量子位 清华唐杰团队的新作来了: WebGLM,一个参数100亿的联网问答聊天机器人(论文入选KDD2023)。  你可以问它任何问题,然后它将列举出网上(例如维基百科、相关官网)相关的文章链接,整理出答案。 比如: ChatGPT的核心技术是什么? 或者: 谁提出的Music Transformer?它的原理是什么?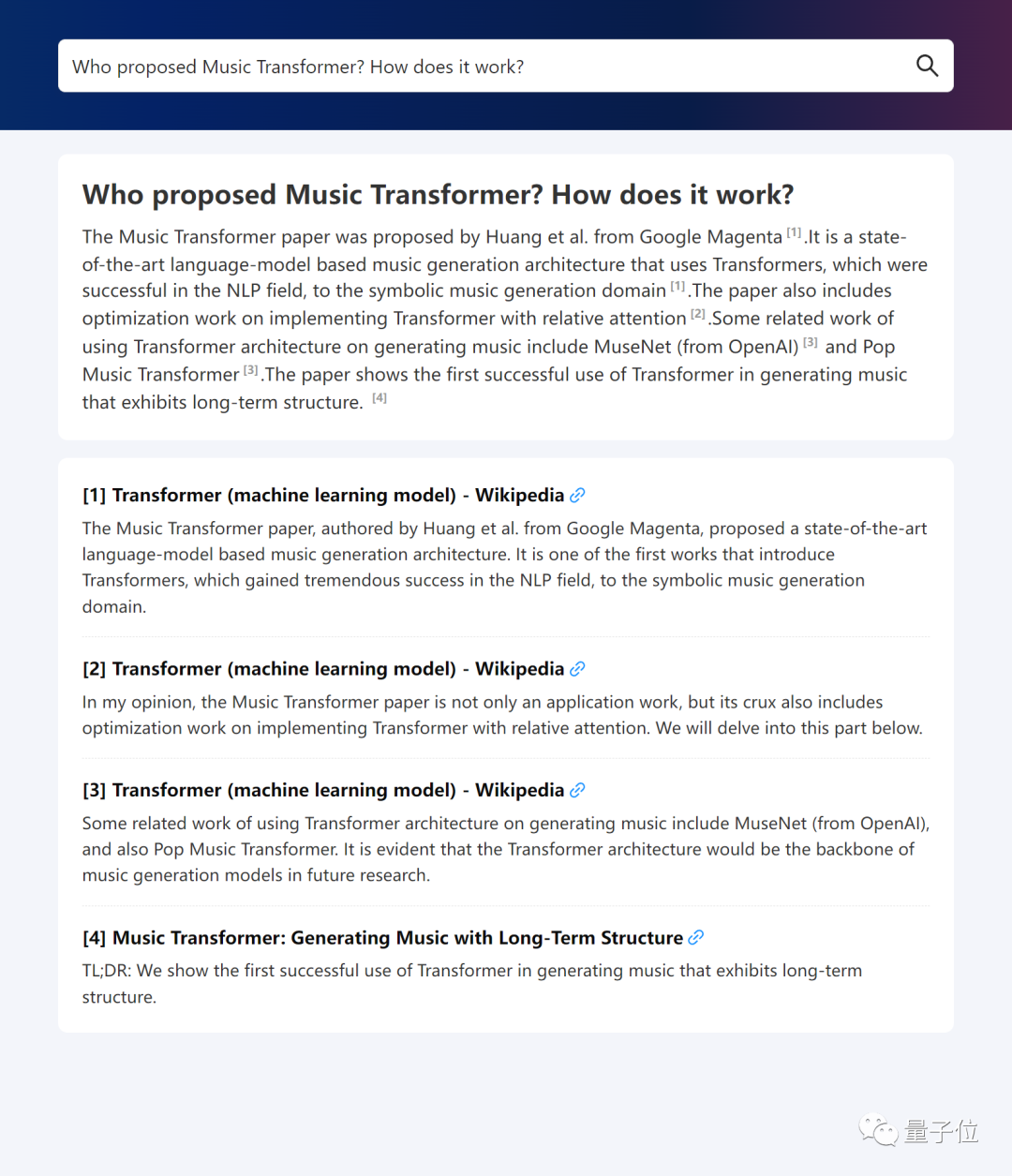 再或者: 原神3.5版本怎么样?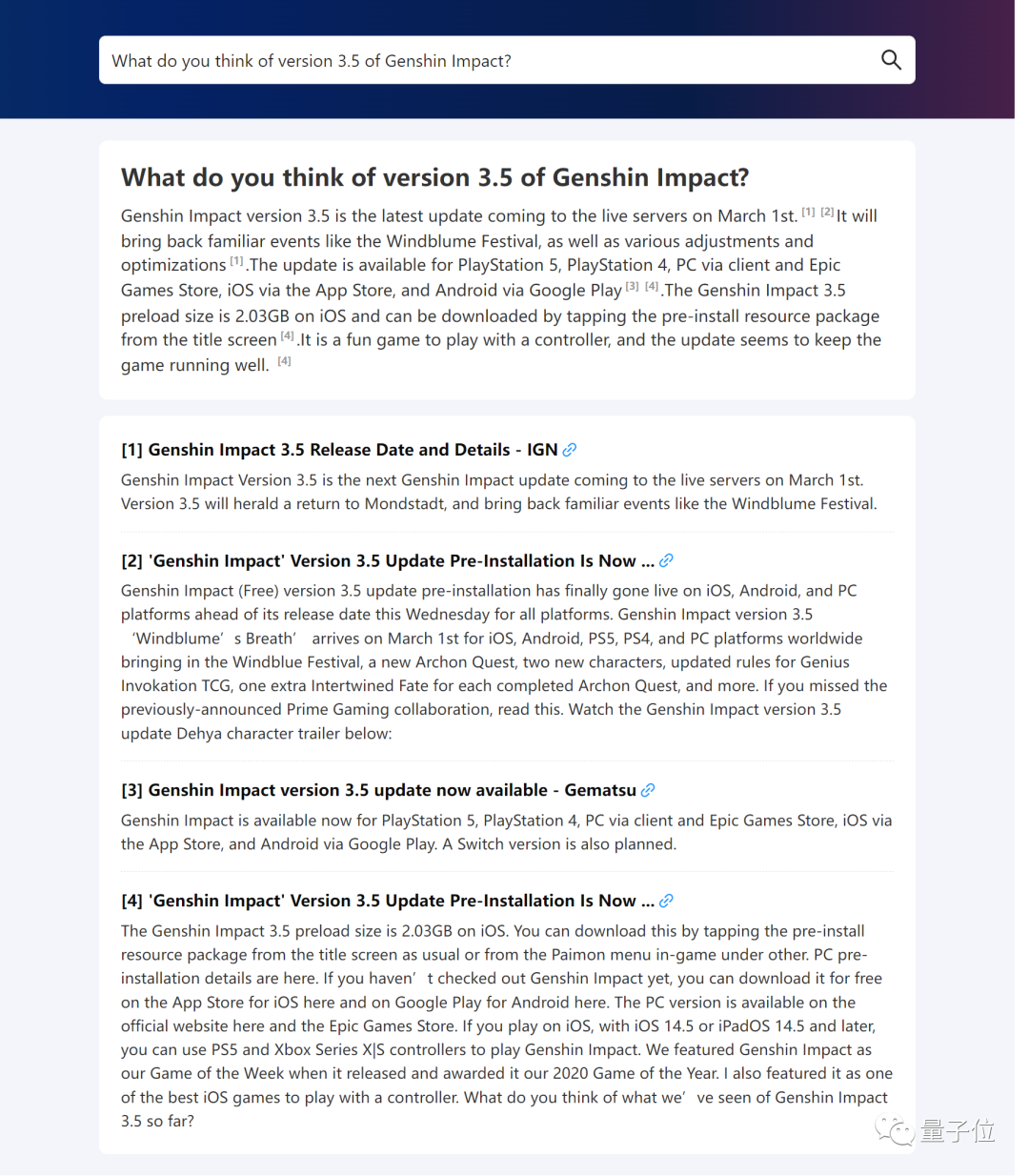 没有高薪工作,怎么在一线城市生活?(手动狗头) 没有高薪工作,怎么在一线城市生活?(手动狗头)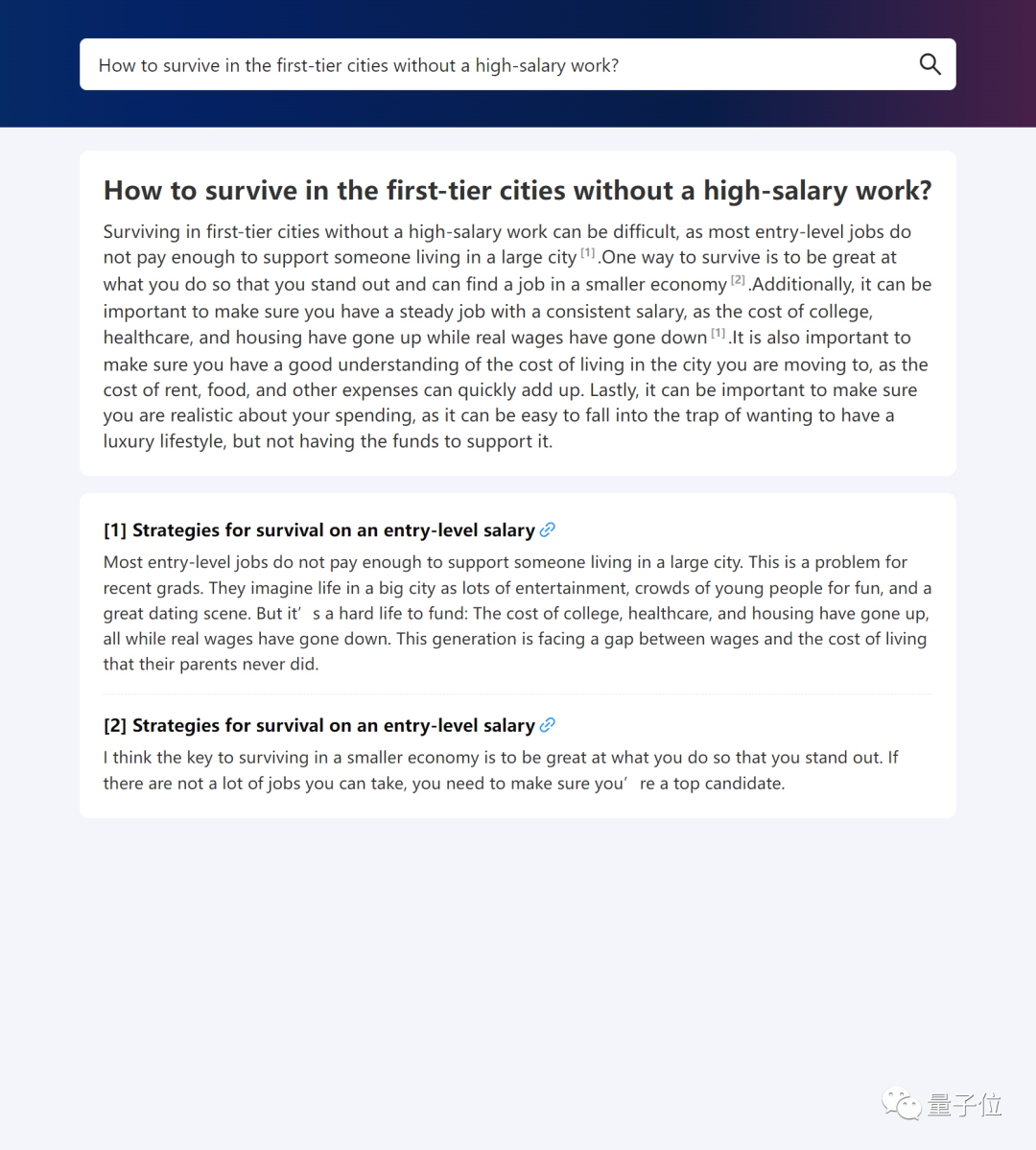 …… 它都能给出有理有据的回答。 据介绍,在性能对比测试中,WebGLM的水平已经高于OpenAI?135亿参数的WebGPT,在人类评估中,甚至与1750亿参数的模型不相上下。 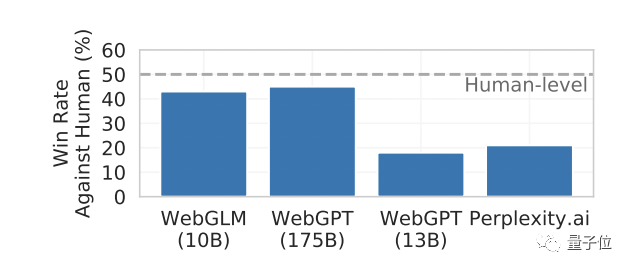 那么,它是如何训练的? 可以上网的清华系WebGLM据介绍,WebGLM的目标是通过Web搜索和检索功能,增强预训练大语言模型,同时可以进行高效的实际部署。 为此,作者基于三种策略进行开发。 首先是大模型增强检索器。 它主要是用于增强模型相关网络内容的检索能力,在给定查询的情况下查找相关引用,以便后面更好地准确回答问题。 它有两个阶段:粗粒度web搜索和细粒度LLM增强密集检索。 其次是自举生成器。 它利用GLM(比如清华之前发布的双语开源预训练模型GLM-130B)的能力为问题生成回复,提供详细的答案。 利用该生成器,作者得到WebGLM-QA——一个LLM自举引用和长程的QA数据集。 它通过上下文学习等策略进行清洗和过滤,最终包括45k的高质量过滤样本和83k的噪声样本。 WebGLM的backbone就是一个在该数据集上训练的GLM模型。 最后是基于人类偏好的打分器。 它通过优先考虑人类偏好而非昂贵的专家反馈来评估生成回复的质量,确保系统能够产生有用和吸引人的内容。 以上三大组件最终按顺序形成WebGLM的pipeline: 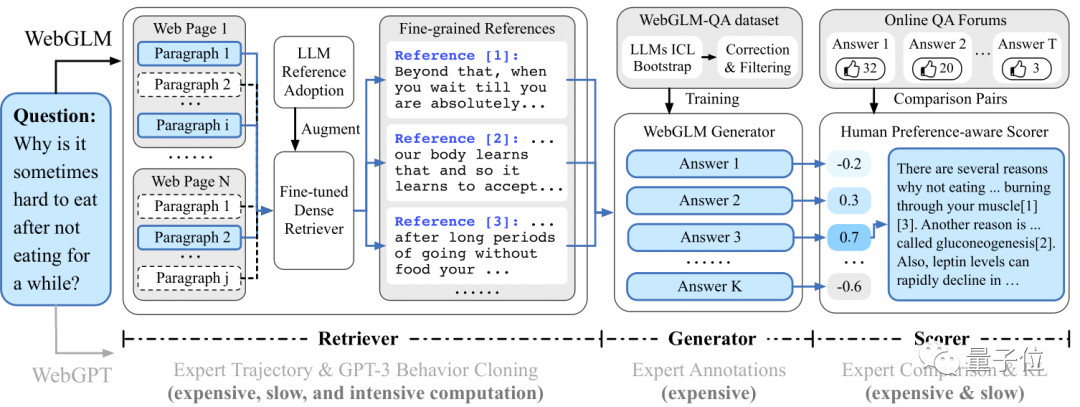 可以看到,正好三个模块,对应前面介绍的三部分,其中: LLM增强检索器会将前五个最相关的页面作为参考源,让自举生成器生成多个答案,最终打分器选出最可能符合人类偏好的那一个作为最终输出。 性能超OpenAI WebGPT除了WebGLM本身,唐杰团队此次还提出了一个网络增强问答系统的评估标准,评估对象既包括参考文献,也包括最终回答。 其中前者衡量相关性、信息密度、真实性(无事实错误)、毒性(不含暴力色情等信息)和社会偏见程度这5个维度;后者则衡量流畅度、正确性、引用准确性、客观性和冗余程度。 他们用WebGPT(来自OpenAI,基于GPT-3进行微调)演示网站提供的272个问题进行对比评估,并招募了15个学历为硕士的志愿者打分。 最终结果如下:  (“Rel.”、“ Den.”……分别对应上面说的10个指标。) 可以看到,尽管WebGLM的搜索结果略逊于WebGPT-175B,但远好于Perplexity.ai和WebGPT-13B(左边的参考文献评估)。 值得一提的是,WebGLM检索过程只使用了一些传统的基于单词的算法和两个累计参数量不超过300M的Contriever。 此外,WebGLM在计算性能和时间消耗方面也明显优于WebGPT-13B、并与175B不相上下。 而在最终结果方面,WebGLM在流畅度、真实性和冗余度方面均获得最高得分,正确性指标上则接近WebGPT-175B,远高于Perplexity.ai和WebGPT-13B。 作者表示,这表明WebGLM可以以更低的成本获得更高的性能。 部署与训练WebGLM发布即开源。  要想部署它,需要从SerpAPI官网获得一个密钥,用于在搜索过程中获取搜索结果。 检索器的权重可从清华云上下载。 运行该模型的方式有两种:一是命令行界面,二是Web服务形式,并且包含WebGLM-2B和WebGLM-10B两种可选模型。 你也可以自己训练WebGLM,官方已提供好了生成器和检索器的训练数据供下载~ 论文地址:https://arxiv.org/abs//2306.07906 GitHub主页:https://github.com/THUDM/WebGLM —- 编译者/作者:AIcore 玩币族申明:玩币族作为开放的资讯翻译/分享平台,所提供的所有资讯仅代表作者个人观点,与玩币族平台立场无关,且不构成任何投资理财建议。文章版权归原作者所有。 |
清华唐杰新作WebGLM:参数100亿、主打联网搜索,性能超OpenAI WebGPT
2023-06-24 AIcore 来源:区块链网络
LOADING...
相关阅读:
- Midjourney发布5.2 版本,像相机一样变焦、填充画面细节2023-06-24
- EDGE全球AI和Web3投资峰会揭幕:创新合作在香港孕育突破2023-06-24
- Nike旗下NFT平台.SWOOSH在《堡垒之夜》中推出Airphoria元宇宙2023-06-24
- 汇丰银行与 Cyberwrite 续签人工智能驱动的网络保险平台协议2023-06-24
- AWS推出生成式人工智能创新中心2023-06-23