


BlockCDN技术白皮书 概述: BlockCDN是一个去中心化的CDN(Content Delivery Network)交易市场。是通过叠加融合型架构的设计思想把CDN与P2P融合。将传统的CDN架构分为三层,包括:CDN管理层、CDN边缘服务器层、用户P2P层。CDN管理层对整个系统管理;CDN边缘服务器层分布在互联网的边缘,与客户端P2P层网络的对等节点之间相互共享内容资源,同时客户节点端利用P2P网络为其它节点提供内容内容资源,同时也作为服务器为网络提供计算带宽等网络资源。通过客户端的参与减轻了CDN边缘服务器的负担。另一方面,CDN边缘服务器作为P2P网络中的一个超级节点也可以为P2P网络提供更近的网络资源,当P2P网络中没有所需资源的时候,P2P网络可以通过CDN边缘服务器节点获取所需的内容。这种就近获取内容的方式保证了获取内容的速度,从而加快了整体系统的性能。这种架构让CDN性能有了显著的提高。并通过区块链工作量证明对节点的管理,让加入的节点获得收益。让交易变得更透明,更公平。也因为区块链支付的融入让全球支付,全球节点变成可能,让全民参与变得容易,也让资源得到充分利用。 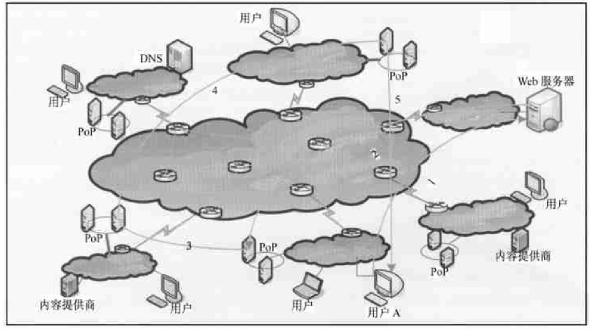 图:BlockCDN的体系结构和数据内容定位 BlockCDN的技术分析: 1) 智能调度的分需求网络框架: 目前对CDN需求最热门的领域有:游戏下载、移动应用、视频点播、在线直播等BlockCDN根据不同的加速需求设置了不同的调度架构,主要分为如下几个: 1-1) 叠加型协助文件分发对等调度网络架构 这种架构主要针对静态数据加速,如:软件下载等。CDN利用内容分发网络与P2P网络的优点为每个使用者(公司组织和个人用户)提供高效和高质量的内容分发,架构如图2-1所示。调度框架整合并利用了CDN和P2P两种分发模型。新架构的目标是利用对等节点网络帮助内容分发网络来分发CDN边缘服务器中的内容,同时CDN可以帮对等节点网络在不同的区域分发并共享内容资源。CDN与P2P发布内容的权限并不是相同的。CDN的内容可以在CDN节点上复制,但P2P内容不可以在CDN节点上复制。设计了一种机制使对等节点变成CDN的一部分,这样CDN和对等节点就可以相互协作分发CDN中的内容。 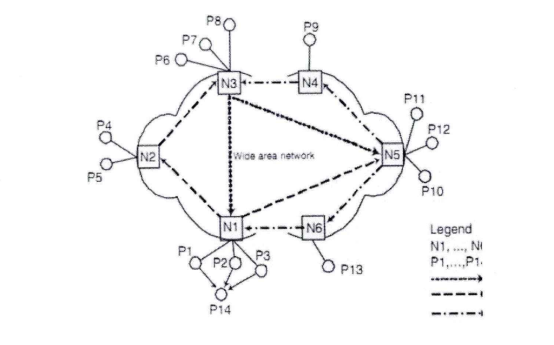 图1- 1叠加型协助文件分发对等调度网络架构 架构中设计一种机制利用CDN帮助P2P网络中的对等节点分发内容。在这种机制下,架构中的CDN边缘服务器节点向P2P网络中的对等节点开放有限的资源。CDN向P2P网络提供的资源限度等于在此之前P2P网络向CDN网络提供的资源。例如,如图1-1所示的对等网络节点己经为CDN做了资源贡献,当他们需要在不同对等节点网络之间分发内容就需要CDN的协助。CDN在N1,N2,N3 , NS三个CDN边缘服务器节点为根节点建立三个不同的有限带宽树。对等节点通过CDN中的这些树传递内容。这些机制基于一些假设模型的基础之上。假设CDN系统的拓扑是可知的并且是静态的。CDN具有网络测量方法来获得CDN的参数信息,例如带宽、延迟等信息。通过CDN传递对等网络中的内容。对等节点之间传递内容有两个场景。第一,当两个共享内容的对等节点处于同一个网路域之中时,CDN节点并不为内容的共享提供加速。因此在这种场景下,CDN节点并不参与到其中,只是对等节点之间通过P2P协议传递内容。例如,图2-1中只有P1, P2, P3需要相互共享内容时,N1并不参与这个过程。第二,如果在不同网络域之间的两个对等节点之间分发内容时,CDN节点参与到这个过程以加快节点之间的分发速度。两者基于一定交换协议相互合作。在对等网络节点使用内容分发网络的边缘服务器分发内容之前需要首先为CDN贡献资源。 1-2) 基于Gossop协议的CDN-P2P系统结构 这是一种应用于视频直播的P2P-CDN混合架构,整体架构如图2-1所示。用户首先浏览流媒体内容列表然后发出对某个内容的请求,请求被定为到最近的CDN边缘服务器。这样就可以减少延迟。支持DNS转发调度机制。图2-1所示为CDN-P2P混合结构的系统组成结构图,当请求数据包被转发到最近的CDN服务器后,被请求的节点在Tracke:服务器注册并接受初始化的邻居节点声明为负责节点,每个节点从负责节点获得一个随机的邻居列表。 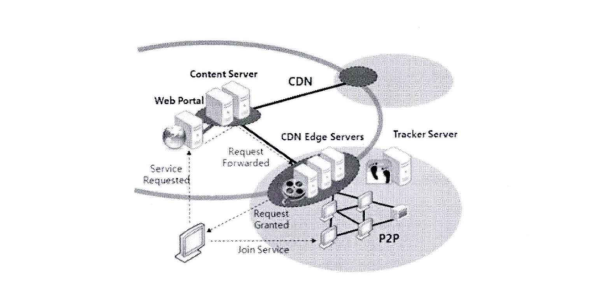 图2- 1基于Gossop协议的CDN-P2P系统结构 网络基于Gossop协议组织。随机接受邻居节点的请求或者转发请求数据包到一个邻居节点列表中的某个随机节点。Gossop协议的随机性确保P2P网络具有本地性。相邻节点的列表定义为成员节点。从成员节点中选择关键的邻居节点共享数据。相互交换数据的节点成为伙伴节点。伙伴节点周期性地共享BM(Buffer Map)。通过BM,一个节点从伙伴节点那里拉取所需要的片段。混合CDN-P2P结构流媒体服务器由内容服务器、CDN服务器、组成对等网络的对等节点组成,这些对等节点是内容消费者。内容服务器包括所有的内容,并且分发到CDN服务器中,通过高带宽链路把内容分发到CDN节点服务器。CDN节点服务器作为CDN-P2P混合结构网络中的一个种子节点,一个CDN服务器只为邻居节点提供下载带宽。【玩币族(http://www.blockvalue.com)专业币圈媒体,重点关注炒币本身。】 1-3) P2P-CDN架构的VOD点播系统 这种P2P和CDN混合架构是针对VOD点播服务的P2P-CDN系统。 VOD系统架构如图3-1所示。该调度系统有三层,最顶层是服务器层包括Tracker服务器和媒体源服务器。中间层是CDN层,这层从顶层获得文件为底层提供内容资源称为中间层。最底层是客户层,客户节点可以从相邻的节点或者从中间层获得所需的视频文件。  图3-1 P2P-CDN架构的VOD点播系统 1-4) 移动环境的P2P-CDN混合调度架构 移动环境的P2P-CDN混合调度架构主要针对移动APP加速。 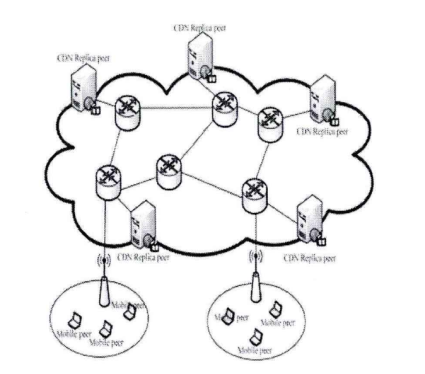 图4-1移动P2P-CDN架构 该架构中包括CDN复制节点和移动节点,如图4-1所示。CDN的复制节点与其它节点交互信息。移动节点从CDN的复制节点并行获得资源。当移动节点需要播放媒体内容时,首先联系最近的CDN复制节点并获得列表。列表包括媒体内容片段位置信息,所有的复制节点维护一个相同的列表。当移动节点收到列表后用户用相应的算法设置CDN复制节点发送切片的时间和内容。在这种架构下,对等节点并不与CDN复制节点交换媒体内容。对等节点从CDN复制节点获得内容,CDN复制节点并不从移动节点获得媒体内容。这样设计的原因如下:首先,CDN复制节点为P2P网络提供高性能、高带宽和稳定的源节点。第二,移动节仅是从CDN节点获得并消费媒体内容。因此,仅仅需要很少的存储空间媒体内容,所需的计算能力也很少。移动终端设备的存储空间和计算能力能满足要求。第三,网络资源与服务资源在复制节点之间共享。 BlockCDN将通过不同的加速需求智能选择最优的调度架构模式,在最大限度地调动P2P分布式节点的加速功能的同时,也最优的解决了加速任务。 2) BlockCDN的数据内容分发存储策略 数据内容分发策略是指CDN管理系统把源服务器中的数据内容推送到边缘节点服务器中的具体方法。BlockCDN提出了一种适合DLC-PCDN系统的内容分发策略:一种基于谱系图的支持服务区分的内容分发策略(Service Differentiation Support and Pedigree Chart Based Content Distribution Strategy,SDPC-CDS)。 BlockCDN在对内容推送过程中的优化控制。对不同的CDN系统中采用不同的内容分发策略,BlockCDN是一种基于谱系图的支持服务质量区分的内容分发策略。用服务区分实现服务质量保障。 SDPC分发策略分为五步,如图3-7所示。前面四步是准备阶段,首先生成谱系图,然后基于谱系图生成决策树。第五步根据决策树完成分发的执行过程。 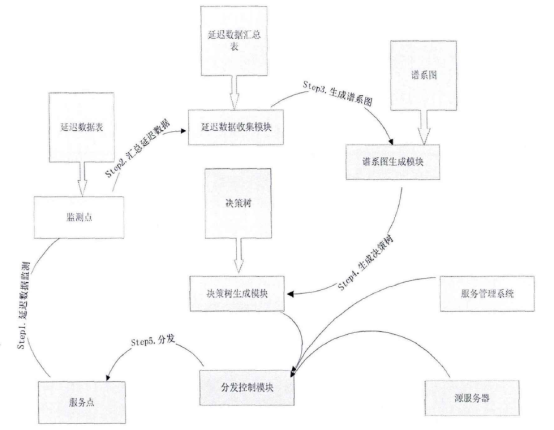 图2-1基于谱系图的支持服务质量区分的分发过程图 下面首先概述五个步骤,然后分别详细说明。 Step 1:网络中的每个监测点MP分别测算延迟数据。监测点MP向服务点SN发送测试数据包,通过测试数据的发收时延计算监测点到服务点的延迟距离。每个监测点分别向所有的服务点发送测试数据,这样每个监测节点就可以得到一个延迟数据表,示例如表2-1所示。表中包括监测点到所有服务点的延迟距离信息。 表2- 1监测点的延迟数据表
Step2:汇总各个监测节点的延迟数据。每个监测点都形成了自己的延迟距离数据表。分发管理系统进行分发决策时,需要所有监测点的延迟距离信息。当分布在网络中的监测点收集到本地的延迟距离数据表后需要向分发管理系统上传这些数据。来自各个检测点的延迟距离数据上传到分发管理系统的延迟数据收集模块。延迟数据收集模块负责把来自各个检测点的延迟距离数据进行汇总。汇总后形成延迟距离汇总表,示例如表2-2所示。 表2- 2延迟数据汇总表
Step3:生成谱系图。上面步骤中的汇总表是一个时延矩阵。对这个矩阵首先进行标准化、正交化等处理,然后根据层次聚类法进行聚类得到谱系图。 Step4:转化谱系图为分发决策树。用转化算法把谱系图数据转化为分发决策树。 Steps:内容分发。首先根据服务管理系统中的信息、分发决策树生成分发决策矩阵。然后根据决策矩阵信息执行分发过程。 下面对各个步骤做详细的说明。 首先详细介绍Step 1与Step2,延迟数据监测与汇总过程。在理想情况下,为了优化分发部署,需要获得任意服务点之间的延迟信息。理论上可以获得这些信息,但在实际应用中获得这些数据的代价很大。这里通过设置监测点(MP )的方法获取监测点到服务点的延迟,然后把这些延迟信息统一上传给分发管理系统中的相关模块。网络中的监测节点部署示意图如图2-2所示。 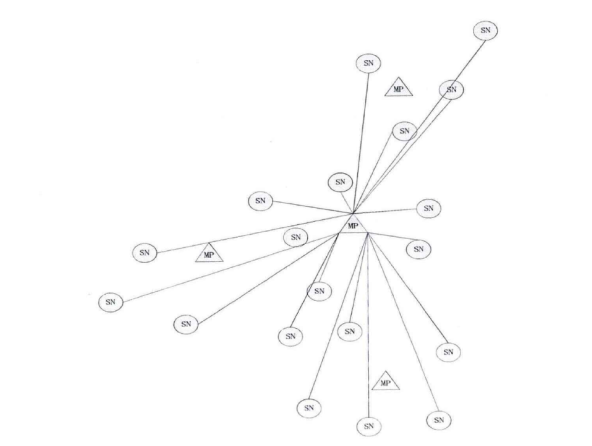 图2-2网络中的监测节点部署示意图 延迟数据监测与汇总的过程如图2-3所示。  图2-3延迟数据监侧与汇总过程 延迟数据监测与汇总的过程包括以下几个步骤: S1.数据监测点MP向服务点SN发送测试包。并记录测试数据包的发送时间Tsend。 S2.服务点SN返回测试数据。用返回时间Trcv减去发送时间得到往返时间MSD。  S3.计算延迟数值。经过前面两步多次的循环得到一组往返时间数值。通过这组数值得到一个平均值MSDave. 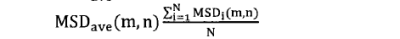 S4.监测节点MP上报数据。每个监测点发送延迟数据到分发管理系统中的数据收集模块。数据收集模块对数据进行汇总得到延迟数据矩阵。 S5.数据收集点把汇总后的数据传递到谱系图生成模块,为下一步谱系图与决策树的生成做准备。 下面详细介绍Step3谱系图生成的过程。谱系图生成过程包括四个步骤,首先要对上面步骤得到的延迟矩阵进行预处理,然后根据层次聚类的方法得到谱系图。 S1.延迟矩阵的预处理。 首先对延迟矩阵正交化处理。对几个监测点测得延迟数据值转化为[0,1]之间的数据。公式如式2-5所示。  经过上述变换得到与测量单位无关,且所有数据都在[0,1]之间的正规化矩阵。如式2-6所示。  然后标准化,把每个因素(变量)化为均值为0,方差为1的标准化变量。即每一列的均值为0,方差为1。变换的公式如式2-7所示。 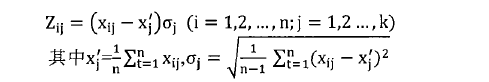 S2.根据式2-8计算距离。 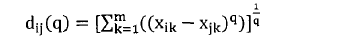 当q-1,称为绝对距离,当q=2时,称为欧式距离,当q=∞,称为切比雪夫距离 S3.定义变量之间的连接,评价聚类信息。 S4.创建聚类,得到层次聚类信息以及谱系图。 例如,一个有六个SN点的矩阵得到谱系图如图2-4所示: 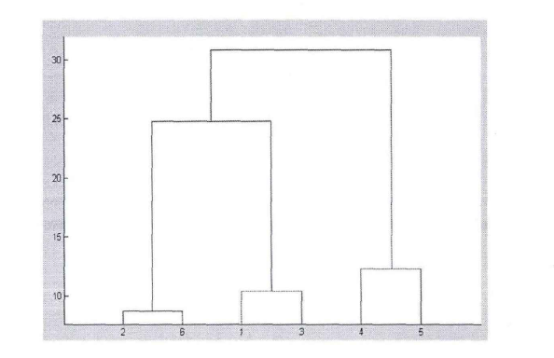 图2- 4谱系图示例 经过以上步骤的处理,通过延迟数据矩阵聚类得到了数据的谱系图。要利用谱系图的信息还需要对谱系图做进一步处理得到分发决策树。下面介绍Step4,从谱系图到分发决策树的转化方法。 谱系图是一个表示节点层级关系的集合。要把谱系图用于分发需要把谱系图转化为分发决策树。网谱系图转化为分发决策树的伪代码描述如图2-11所示。络中有N个SN点,把网络中的N个SN点做为叶子节点,节点类型为L。根据谱系图信J息把节点聚类成N-1组,查看合并的两个集合C3和C4。生成一个决策节点D[N-1],并把C3与C4作为子节点,作为一个决策子树。循环上面的步骤直至所有的决策子树合并到根节点。  图2- 11谱系图转化为分发决策树 前面图2-4所示的谱系图示例转化成分发决策树示例如图2-5所示: 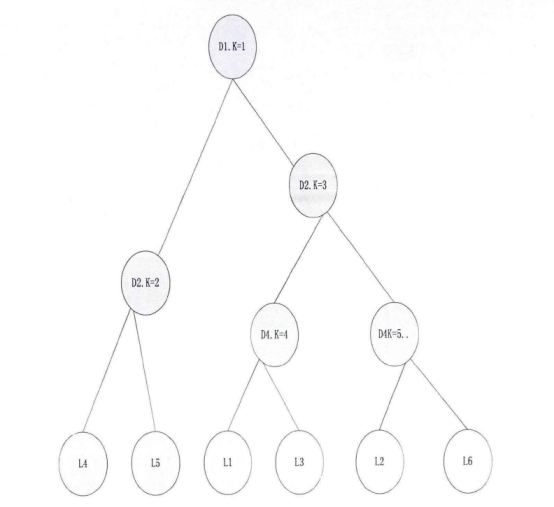 图2-5分发决策树示例 前面四个步骤得到了分发决策树,第五步通过分发决策树完成分发过程。首先通过分发决策树得到分发决策矩阵,这个过程是通过SetMark函数完成的。然后再根据分发决策矩阵信息执行分发过程。SetMark函数的伪代码如图3-13所示。从待分发的内容对象集合中选取一个内容对象CO[i]以及等级信息,根据待分发对象的等级信息得到相应的覆盖率与副本数量CO[i].C。根据SetMark函数得到标记信息,SetMark(Dtree,CO[i].C)。这个获得标记的过程就是通过决策树得到分发决策的过程,把要分发的节点标记为1,其它未标记节点为0。每个内容对象对应一个标记数组,这样待分发内容的标记数组组成一个标记矩阵,也就是分发决策矩阵。 图2-12为通过SetMarK函数完成分发决策标记的例子,C=4,在D1根节点,D1.Type=D,而且C >D1.k+1所以分别继续遍历左右子树。在D2节点,因为D 1.Type=D,而且C>D l .k+1,所以遍历左右子树,左右节点类型L4.Type=L,L5.Type=L,所以L4.m=1,L5.m=1。在D3节点,D3.Type=D,C=D3.k+1,所以遍历左右子树,标记左子树其中一个的L型子节点L1.m=1。标记一个右子树L类型节点L6.m=1 。  图2- 12分发决策标记伪代码 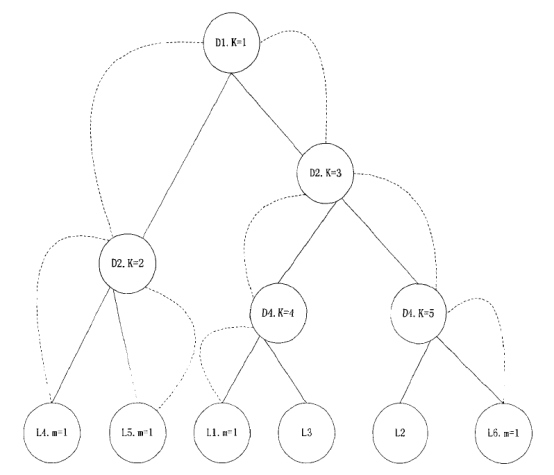 图2-13分发决策标记示例 基于决策矩阵信息执行分发的过程如下所示: Step 1:从待分发的内容集合中以等级从高到低选取内容。 Step2:通过分发决策矩阵得到分发决策信息。 Step3:根据分发决策把内容对象发送到相应的节点。 3) BlockCDN引用全网资源发现算法G1-HOP 3-1) G1-Hop是全局全网范围内查找并发现内容资源的一种算法系统。通过G 1-Hop找到所请求内容所在的服务器协作组信息,然后通过局域内容请求路由算法找到内容所在的节点服务器信息。如图3-1所示。在物理实体层面G 1-Hop是一个由若干分布在互联网中的服务器节点组成的分布式网络系统。 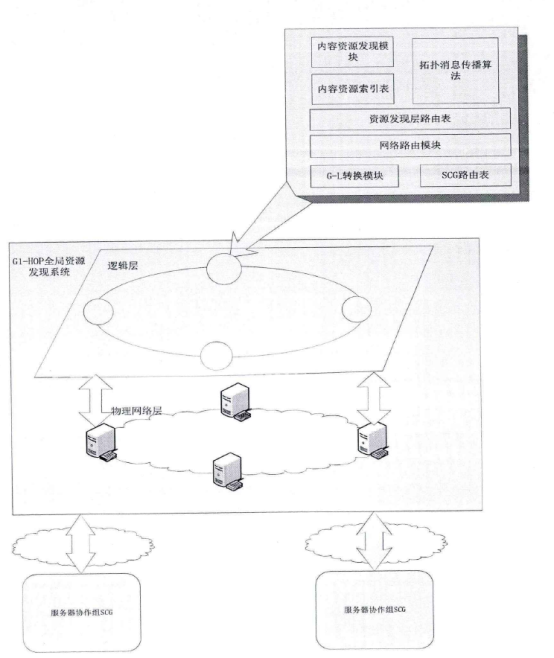 图3-1 G 1-Hop全局资源发现系统 G1-Hop转换模块与SCG路由表负责把内容发现请求定位到SCG中的服务器节点。通过全局资源发现层的资源查找过程把请求定位到资源发现层的目的节点后,需要继续把请求导向内容所在的服务器。这就需要通过G-L转换模块与SCG路由表两个功能单元相互配合完成这个过程。 拓扑消息传播算法模块负责维护节点中的GI-Hop路由信息表,G 1-HoP中每个节点中都存储全状态的拓扑信息用于路由,所以G1-Hop的内容资源发现过程并不复杂。拓扑信J自、表的更新涉及到每一个节点,所以拓扑信息、表的更新算法是一个重要问题[6]。G I -Hop中设计了一种树状拓扑消息传播算法来传递网络拓扑变化信。 下面小节首先介绍内容索引表的分配与索引查询的过程,然后介绍G1-Hop的拓扑更新消息传播算法。 3-2) 数据内容资源发现过程 采用结构化DHT的方法来分配与查询索引。由网络中每个节点IP信息的Hash数值得到节点的ID号码N.ID, N.ID=HASH(IP)。这些节点的ID号码按照ID空间中的顺序依次排列,组成节点环。ID空间的大小由Hash数值的位数m决定,T=2"'。 T为ID空间能表示ID的最大值,m为HASH值的位数。所以网络中所有节点ID组成的节点环是ID空间的一个子集,节点环中的节点数量等于主机节点的数量。如图4-8所示,这是一个有5个节点的节点环。m为3,所以这个ID空间能表示的最大的节点数为805个节点的IP散列值分别为0,1,2, 5, 7。这个五个节点组成一个节点环。在环上紧跟着节点n的节点称为节点n的后继节点,节点n称为这个节点的前驱节点。 内容索引表分布在全局资源发现层的节点中。资源名称的Hash函数值作为资源的ID号码,R.ID。资源所在的主机的Hash值作为节点ID号码。资源ID与节点ID组成了索引条目。所有资源的索引条目组成了资源索引表。根据资源ID把索引条目放置在相应的节点中。把资源ID作为索引的关键字,把索引信息存储在关键字的后继节点中。如图4-8所示,关键字为2的索引存储在NID为2的节点中。关键字为4的索引存储在NID为5的节点中。关键字为6的索引为NID为7的节点。 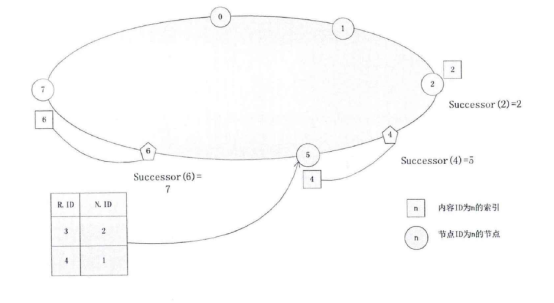 图3-2索引在节点环中的存储 如图3-2所示,当关键字为4的索引存储到节点5后形成一个索引项,节点5中所有索引项组成这个节点的索引表。索引表由内容的关键字与关键字对应的地址信息组成。 查询索引需要用到索引信息表。索引信息表中存储所有节点的信息。所以可以通过一跳路由到对应的索引信息所在的节点。当资源请求到达后,根据资源索引的ID查找路由信息表得到其存储节点的ID,然后根据节点信息把请求导向对 应的节点。如图4一9所示,节点7要查找关键字为3的索引。通过查找路由表, 关键字为3的后继节点为5,然后把请求路由到NID为5的节点。找到对象的后 继节点,到后继节点找到索引,根据索引找到资源所在的节点。 全局资源发现层只能定位到内容所在的服务器协作组,如果需要定位到内容所在的服务器就需要内容所在协作组的局域路由系统的协助。所以,入口节点要保存SCG的拓扑信息表,并通过G一L模块控制全局资源发现层与服务器协作组层的转换。通过这个机制找到内容所在的SCG组内的服务器。  图3-3资源查找过程 3-3)拓扑信息更新算法 当全局资源发现网络出现拓扑变化后要通过拓扑更新算法尽快地传递到网络中的每个节点。One一hoP中的消息传播方法并不适用于资源发现层。原算法中对网络中的节点区分对待,把性能较强的节点作为Slice或者Unit的领导节点,这些节点之间采用广播的方式传播。在普通节点中以Unit节点为中心单方向线状传播。每个节点收到一个消息后,消自、要等待到一个周期才能转发。之所以有这样的设计是由它的应用环境决定的。用户终端P2P网络节点性能的差异性与拓扑变化率较高决定了这样的机制。在G 1-hop的应用环境中并不存在这些限制条件。 全局内容资源发现层的网络拓扑变化并不频繁,网络中节点的性能差异并不大。G 1-hop中的节点分布在网络边缘,这些节点的距离较远。由于每跳距离较远,如何减少消息传播的跳数以最小的时延传播拓扑更新的消息是G I -hop拓扑消息传播算法的设计目标。 G1-Hop中每个节点维护一个拓扑信息表,每个拓扑信息表包括网络中所有节点的信息。这种方法与Chord不同。在Chord算法中拓扑表中只保存部分信息。因此,Chord算法需要几跳才能找到对应的节点,但这个算法只需要一跳能找到相应的节点。 G 1-Hop网络中的每个节点都维护相同拓扑信J自、表,这个拓扑信息表用来路由,所以也称路由表。这个路由表中有网络中所有节点的信息。当网络中节点较多的时候,如何维护这个表是一个重要的问题。当一个路由表中存在与实际拓扑不相同的信,u、时,就会导致查找错误。及时准确的对拓扑信息更新就会减少查找的错误率。 这里提出了基于消息传播树的更新方法。这个算法根据拓扑表本身信息建立传播树,能提高拓扑信息表的更新速度。 引起拓扑变化的事件分为两类,有一类是节点的增加,另一类是节点的减少。其中节点的减少分为节点退出、节点失效两类。节点退出是节点因为维护等需求主动退出网络,这种退出是有准备的退出。节点失效是指节点出现故障导致节点被动退出网络,节点的失效事件是随机发生的。 节点增加时,新增节点会从一个网络中己有节点获得一个路由表信息。新增节点IP的散列值作为节点的NID号码。根据NID的号码的大小把节点信息插入 到路由信息表中。由新增节点的后继节点作为传播树的根节点传播拓扑变化信息。 节点退出时,退出节点把退出信息、发送给后继节点。其后继节点作为传播树 的根节点传播拓扑变化信息。 节点失效时,失效节点不会主动发送失效信息。所以节点之间需要发送Keep-Live信息来确定邻居节点没有失效。每个节点以一定的周期向其前驱节点发送Keep-Live信息。当前驱节点没有回应时就认为前驱节点己经失效,以这个 节点为根节点建立传播树。 把节点环中所有节点分为M个组,每个组有一个Lg节点,Group Leader,如图3-4所示。每个组NID最小的节点为这个组的Lg节点。组中的Lg节点为根节 点组成传播子树。当一个节点发现拓扑变化信J息、后,把信息传播给M个传播子树的根节点,然后通过传播子树传播到每一个节点。 每个节点中存储相同的路由表,路由表中包括序号S、节点标识NID、领导节点标识GLM ( Group Leader Mark )三项。GL节点标识用来标识出网络中的Lg节点。如果网络中的某个节点为Group Leader节点那么路由表中对应节点的领导节点标识GLM为1}否则路由表中对应节点的领导节点标识GLM为Oo Lg节点与相邻的Lg节点之间通过Keep-Live信息保持沟通。通过 KL信息相邻的Lg节点之间可以获得邻居节点是否在线,如果邻居节点失效或者退出网络,相邻的Lg节点会临时代替失效或退出的领导节点,通过相邻节点向失效或退出节点的子节点发送信息来确保Lg组内传播正确的拓扑变化信息。但相邻节点只是临时代替失效或退出的领导节点,还需要设计相应的机制为失效Lg对应的组找到新的根节点,并通知失效的组内重现标识领导节点重构传播树。 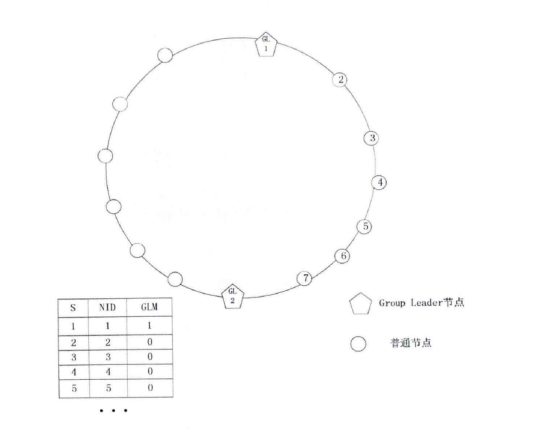 图3-4 GI-hop节点分组 如图3-5所示,当一个点N。发现拓扑变化后,Nc节点把事件信息传递给节点环内所有的Lg节点。Lg节点要把这个拓扑变化的信息更新到每个组内的节点。如果Lg直接把消息传递给所有的节点,就要消耗大量的带宽资源。由于带宽限制,每个节点允许发送给M个节点。发现节点Nc只负责告知M个Lg节点。Lg节点告知组内的M个节点,这M个节点再分别告知另外M个节点。以Lg为根节点形成传播子树。这样就形成了一个基于树的更新机制。 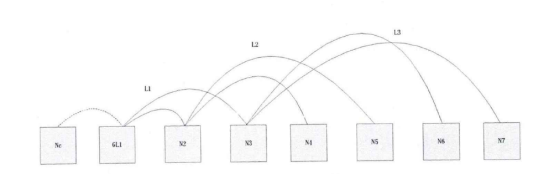 图3-5事件消息的传播 例如,M等于2的情况下,当一个节点退出,这个节点的后继节点N。发现拓扑的变化。后继节点以传播树的形式通知其它节点。首先N。节点发送到M个Lg节点。其中Lg节点为根节点组成传播子树,以第一个Lg为根结点的消息传播子树如图3-6所示。 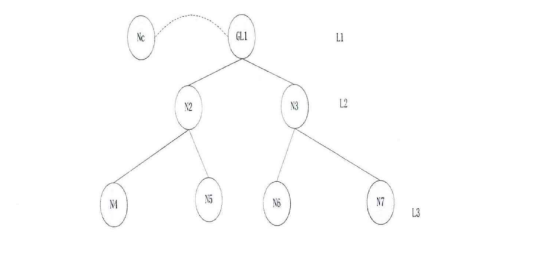 图3-6消息传播子树 在传播子树内,拓扑信息从组内根节点传播到各个节点。首先根节点发送信息给M个后继节点。M个后继节点收到时间信息后继续传播。 一个组内的消J自、传播路径树建立过程的伪代码如图4-13所示。每个分组的GL节点为根节点。用N (ij)表示节点在树中的相对位置ID o i表示所在第几层子节点,j为所在层数的叶子节点中的标号。 一个节点收到建树消息后,首先得到本节点的树坐标。然后根据本节点的坐标计算M个子节点的坐标Nn,如式3-1所示。 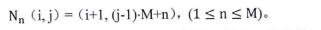 得到子节点坐标后,通过坐标号计算节点的序号Sn,如式3-2所示。 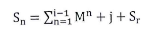 Sr为根节点的序号。如果这个序列号大于St那么序列号为Sc = Sn-St为表的总序列号,否则Sc=Sn。 特殊情况下,会发生领导节点失效或退出的情况。因为领导节点处于组内的边缘,是组内信息传递的根节点,所以在种情况下需要特殊处理。领导节点之间有Keep-Live信息确保相邻节点在线。如果一个邻居节点的退出或失效,那么相邻的领导节点把信息直接传给失效节点的子节点以确保失效组内不受Lg失效的影响而能继续通过传播树的来传播信息。但这是应急传播结构,这种应急结构会使失效节点的邻居节点负责的过多的事务,还要通过重构机制来重新构筑失效组的传播树。重构机制中首先把失效节点的后继节点作为新的Lg节点,并把原Lg节点的传播树子节点作为新Lg节点的子节点,这样就可以只需要重构传播树的一层结构就可以恢复传播树的功能。找到新的Lg节点并重构传播树后还需要其它节点更新GLM标识信息,Lg失效后各个节点更新路由表中的GLM标识信息。  图3-7消息传播路径树建立的过程伪代码 3-4) 算法性能分析 在G 1-Hop算法中拓扑变化事件消息的传播路径为树状传播,与One-hop的路径不同。在原算法中的拓扑信息传播方式中把节点分为若干个Slice,一个Slice分为若干个Unit。每个Slice都有一个Slice Leader,每个Unit也有一个Unit Leader,其他节点为普通节点。消息的传播路径为:SL一其它SL-UL一后继或者前驱节点依次传播,本质上是一种线状传播路径。本方法中传播的路径为:GL一各层子节点,采用的是一种树状的传播方式,这样能更快的传播消息。在原方法中,首先从发现事件的节点传到SL节点,再从SL节点到其他SL节点。事件消息经过SL到UL节点。前面这几次传播需要3跳,最后从UL节点线性传播出去,一个Unit的节点数量为U,那么时间消息传遍Unit的跳数为U/2,所需的总跳数为3十U/2,跳数的渐进函数集合为O(n)。 如消息直接从发现消息的节点发送到M个GL节点,不需要经过本组的GL节点发送到其他GL节点。每个节点都有相同的路由信息,所以这样能充分利用这些信息,直接把消息传到所有GL节点。到达GL节点后,以GL节点为根节点通过消息传播子树把事件消息通知给每一个节点。所以G1-hop传播拓扑变换消息所需的跳数为H,如式3-4-1所示。跳数的渐进函数集合为Φ logs (n)。  计算可得两种算法消息传播跳数对比如表3-4-1,对应的传播跳数对比如图3-8所示。算法1为G 1-hop算法,算法2为One-hop算法。从图4-14中可以看出,G 1-hop所需的跳数少于One-hop算法。而且随着网络中节点数量的增加,这种差距更大。在传播时间上,One-hop算法的事件消息的总传播时间分为传播时间和周期等待时间,所以总的消息传播时延除了包括每一跳对应的传播时间外,还要包括周期等待时间。G1-hop算法不需要等待时间,所以总的消息传播时延 只需要每一跳对应的传播时间。在同样网络的条件下,每一跳对应的平均传播时间相同,所以G 1-hop算法的消息传播时延小于One-hop算法。G1-Hop是一种分布式P2P系统中的全局资源发现算法,算法的性能瓶颈在于网络交互时延,通过事件消息传播树机制减少了信息在网络中的传播跳数,从而也减少了信息在网络中的传播时间,把每一跳作为网络传播基本时间,原传播方法的网络传播时间复杂度为。(n),而Gl-Hop传播方法的网络传播时间复杂度为Φ (logs (n)) 表3-4- 1两种事件消息传播算法所需跳数计算结果
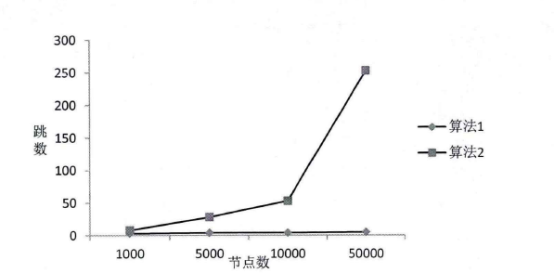
图3-8 G1-hoop与One-Hop消息传播跳数对比 3-5)局域内容路由算法LCRR 3-5-1)LCRR基于结构化DHT网络,每个服务器协作组SCG为一个独立的结构化DHT网络。当一个节点要加入服务器协作组SCG的时候,通过节点加入算法找到所归属的全局内容资源发现层入口节点与相应的SCG组。找到所归属的内容资源发现层节点后,新加入的节点与相关节点完成信息交换与更新。 如图3-9所示,SCG节点中与LCRR相关的模块包括路由表、索引表、索引存储与缓存模块、服务区分与负载调度模块、L-G转换模块等。LCRR基于路由表与索引表中的信息完成请求过程。路由表中存储的是服务器协作组SCG的辑层网络路由信息,包括网络中节点的逻辑层地址信息。索引表中存储的是内容对象所在服务器的信息。网络中内容索引信息分散在SCG的各个节点中,每个SCG节点保存部分内容索引信息。通过内容索引存储与缓存模块控制内容索引在网络中的存储分配,并且通过关联内容索引缓存机制对内容索引进行缓存。当内容请求被路由到内容所在节点后,要通过服务区分与负载调度模块来为请求分配服务资源。如果SCG中没有Client所需内容,那么通过L-G转换模块把局域内容路由过程转换为全局内容资源发现过程,通过全局内容资源发现算法去全局范围内查找内容资源。 在此详细介绍网络节点加入方法、G-L协作机制、内容索引分配与缓存机制、服务区分与负载调度、请求路由过程。  图3-9 LCRR相关模块 3-5-2)网络节点的加入 LCRR位于架构的SCG层。服务器协作组SCG是距离较近的服务器的集合,这些服务器组成一个P2P协作网络。另外,SCG组之间需要协作,这个协作是通过全局资源发现层来实现的。每个服务器协作组SCG都要选择一个较近的资源发现层节点作为进入全局资源发现层的入口节点。所以当一个节点需要加入服务器协作组时,需要找到一个入口节点。找到了入口节点也就找到了所要加入的服务器协作组。 全局资源发现层的节点分布在网络中。CDN管理层存储有这些节点的谱系图信息。通过谱系图可以得到这些节点之间的分组信息。本节所设计的入口节点选择方法主要思想是:首先,需要加入网络的节点找到距离上比较近的全局资源发现层节点分组。然后在这个分组中找到距离较近的节点。把这个节点作为入口节点。 根据谱系图可以把所有资源发现层节点分为K组。当节点要加入时首先获得网络中一个一直在线的固定节点信息,相当于其它方法中的自举节点。加入节点首先通过固定节点告知网络有节点要加入。当服务器协作组SCG有节点要加入时,监测节点MP测量这个节点的时延距离Dti找到与Dti时延差最小的分组,把这个分组作为入口分组。然后加入节点在这个分组中找到距离最近的节点,把这个节点作为入口节点。 每一个入口节点负责一个服务器协作组。节点找到入口节点后,从入口节点下载服务器协作组节点的拓扑信息。然后找到前驱节点和后继节点,即找到加入的位置。与前驱节点和后继节点建立连接。最后把拓扑更新信息传播到其它节点。 Step 1:要加入节点向固定节点上报信J息、。 Step2:测量MP到加入节点的距离。 Step3:得到最近的内容资源发现层分组信J自、。 Step4:从分组选择接入节点。 Steps:下载服务器协作组SCG的拓扑信J息 Step6:找到前驱与后继节点,更新拓扑信息表,告知其它SCG组内节点。 3-5-3) G-L协作机制 全局资源发现层与服务器协作组SCG层在一些情况下需要相互协作。服务器协作组在组内的服务器之间协作,所以SCG层的局域路由只支持在同一个服务器协作组之内的内容共享。如果服务器协作组中不存在所请求的内容,会启动全局资源发现过程在全局范围内查找所请求的内容。通过全局资源发现系统找到存储有所请求内容的服务器协作组。全局资源发现层只能定位到内容所在的服务器协作组,如果需要定位到内容所在的服务器同样需要局域路由系统的协助。这就需要一个在全局资源发现层与局域请求路由之间的协作模块。这里设计了路由表和相关的功能模块支持局域路由系统与全局资源发现层之间的协作。 首先介绍从局域路由系统转换到全局资源发现系统的机制。当一个用户对内容的请求被重定向系统定向到最近的服务器后,如果这个服务器中没有所请求的内容,请求将被发送到局域路由系统。请求将被路由系统路由到服务器协作组中具有所请求内容的服务器中。如果服务器协作组中没有所请求的内容那么请求被导向全局资源发现层。 为了实现上面所述的机制,设计一种路由表,并基于路由表由L-G转换模块控制转换。路由表的第一个功能是维护服务器协作组的网络拓扑信息。路由表的第二个功能是提供接入全局资源发现层所需的信息。服务器协作组中的每个节点维护一个路由信息表,每个节点中的路由信息表是相同的。路由表分为两个部分,组内路由信息和组外路由信息。当协作组内没有所请求的内容资源时,请求被路由到组外去寻找相应的内容资源。组外的路由信息是服务器协作组到资源发现层的入口节点列表。这些列表就是节点加入方法中的同一个聚类分组中资源发现层节点的信息。一般情况下SCG节点接入到直接负责本协作组的入口节点,当直接负责入口节点出现故障的时候可以通过列表依次选择其它节点。 从图3-10可以看到,组内路由信息由协作组中节点的拓扑信息组成。一个服务器的地址信息对应表的一项。所以在组内路由时可以通过这个表找到相应节点的地址信息。组外的路由信息由全局层接入点的地址信息组成。一般情况下,由距离协作组最近的一个或者几个全局层节点作为接入点。 如图3-10所示,全局层有四个节点,协作组也有四个节点。路由表中的条目Ga_ID是这个服务器协作组的全局接入点。接入点是ID为2的节点。路由表的组内信息有四项,是组内的四个节点的地址信息、。 其次,还需要设计从全局资源发现层到局域路由转换机制。全局资源发现层只能定位到内容所在的服务器协作组,如果需要定位到内容所在的服务器就需要内容所在协作组的局域路由系统的协助。所以,入口节点要保存SCG的拓扑信息表,并通过G-L模块控制全局资源发现层与服务器协作组层的转换。 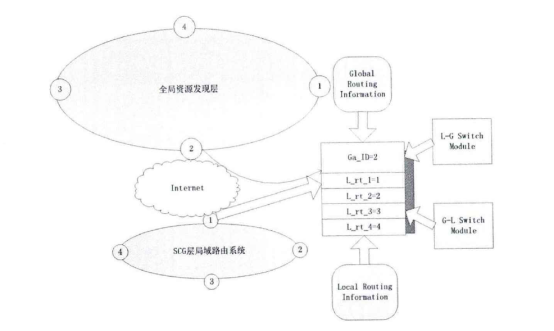 图3-10 G-L协作机制与相关模块 3-5-4) 内容索引分配与缓存机制 在LCRR中设计了一种关联内容索引缓存的方法来提高内容路由效率。用户对内容的请求是有关联的,把有关联的内容索引缓存到相应的节点。当用户再需要其它内容的时候就不需要再次对内容请求路由。 内容的索引项是与内容数据对象的存储相对应的,每个内容对象对应一条内容索引。例如,如果CDN中分发的内容为视频文件,以切片为单位存储,那么每个切片对应一条索引。当一个内容切片存储在服务器中后,索引项也随之建立。索引项的形式是 .P.id是文件切片名称的ID,也就是切片名字的Hash值。N.id是协作组中的节点ID,也就是节点IP地址的Hash值。切片索引项存储在切片名称关键字P.ID的后继节点中。所谓内容关键字的后继节点就是在节点空间中第一个ID大于P.id的节点。同一个视频文件中若干项不同的切片为关联内容,这些切片相对应的索引是关联索引。把相互关联索引缓存到第一个切片索引所在节点中。每个切片索引项中加上相关索引标号RaID ,RaID为第一个切片的ID。这样每个节点通过RaID就可以找到所有相关索引所在的位置。 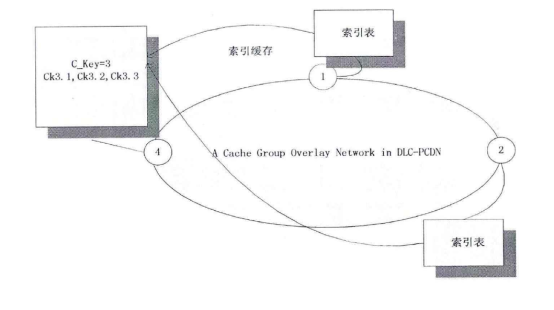 图3-11索引的存储 例如,如图4-17所示,有三个点的协作组。文件有四个切片,首个切片的ID为3,后继节点为4,所以存储在节点4中。其它切片ID为1} 2} 4。其它三个切片的索引从节点1和2缓存到节点4中。CK3.1, CK3.2与CK3.3为ID为ID3的三个关联索引。 伪代码如图3-12所示。  图3-12索引存储过程 3-3-5) 服务区分与负载调度 内容请求被路由到服务器节点后,服务器满足服务请求。服务器节点的服务负载能力是有限的,如何分配服务资源是一个需要解决的问题。前面已经介绍,内容对象是有质量等级区分的。对不同质量等级的内容提供不同的服务。在服务器节点的服务资源分配上也是根据服务等级区分的。这里设计了基于多队列的服务资源分配机制。 在内容路由时,同一个内容会有多个副本,需要在多个副本之间做出选择。这里根据“近期忙标记数,,做副本选择。在多队列服务资源分配的基础上,根据排队论理论,控制多个队列的队长来控制排队时间。如果排队时间超过一定的时间,发出忙标记。并在内容的索引中记录忙标记信息。通过标记信息选择副本。【玩币族(http://www.blockvalue.com)专业币圈媒体,重点关注炒币本身。】 下面详细介绍服务区分与负载调度机制。 通过多队列管理与调度模块实现服务资源的服务区分。如图3-13所示,与之相交互的模块包括重定向系统与局域路由系统。当请求通过重定向系统或者局域路由系统达到服务器后,通过多队列模块来决定是否接受这个请求和如何分配资源。 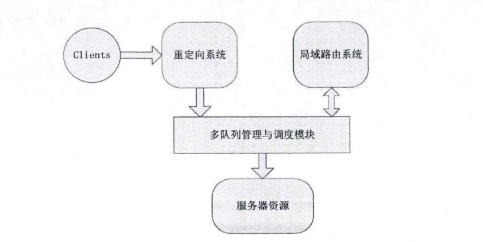 图3-13多队列服务资源分配调度机制相关模块图 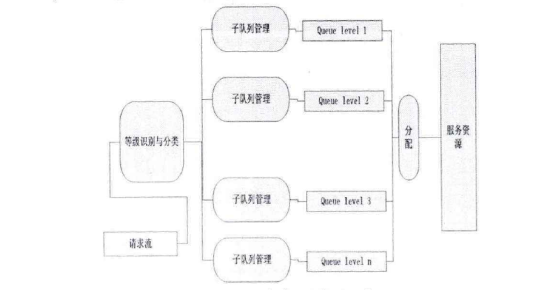 图3-14队列管理与调度 如图3-14所示,多队列服务资源分配调度机制包括以下模块:请求队列,分类模块,队列管理,子队列,资源请求调度模块,服务资源。当用户的请求来自重定位系统或者内容路由子系统,请求按先后顺序排列在请求队列中,分类模块根据内容等级把请求分配到子队列中。子队列管理系统负责对子队列的管理。根据等待时间要求来控制队长,确定请求插入子队列或者是拒绝服务。调度模块负责从各个子队列中选择请求分配服务资源。子队列管理模块通过控制队长来控制最大等待时间。内容路由时面临多副本选择,每个内容都有多个副本,统计多个副本的近期忙标记数。选择近期忙标记较低的副本作为请求的选择副本。这样就可以把请求均衡地导向服务器。 3-5-6) 内容请求路由过程 当本地服务器中没有所请求内容的时候就需要发起局域内容路由过程,把请求导向内容所在的服务器。LCRR算法请求路由过程的伪代码如图3-15所示。首先通过路由表找到内容ID的后继节点作为下一跳节点。跳到下一跳后,查找索引表,找到内容ID所对应的索引。查看索引中的RaID,如果RaID与ID相同,那么查看所有RaID与ID相等的记录,每个P.ID选择一个内容。如果RaID与ID不相同,查找路由表把RaID的后继节点作为下一跳节点,找到所有相关索引记录。经过以上步骤获得了与请求内容相关的所有内容的信息,然后把内容请求导向相应的节点。  图3-15 LCRR伪代码 3-5-7)智能调度流程 BlockCDN的节点调度分为两层: 节点选择层:通过不同的选点方式,选出所有符合的节点信息 选点方式包括: (1) 内容调度:对指定规则的文件请求调度到指定的节点 (2) Location(区域)调度:根据工IP的location进行调度 节点筛选层:根据不同的筛选规则,将由上一层选出的节点进行筛选筛选的方式包括: (1) 负载均衡:根据不同节点的负载信息进行筛选。 (2) 随机:在列出的节点中随机选择一个 流程图: 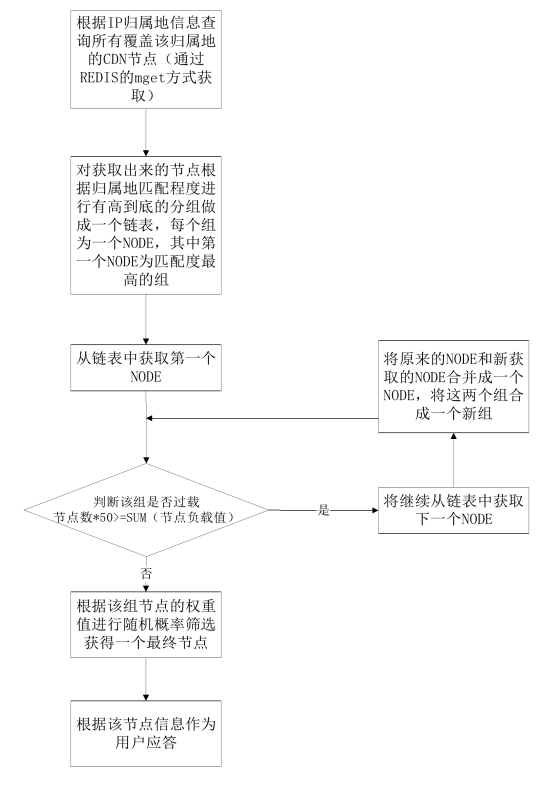 图3-16调度模块流程图  图3-17主要实现伪代码: 4)区块链在BlockCDN中的应用 如何在将闲置设备变成CDN缓存节点 BlockCDN是基于开源Squid,结合SDK和P2P技术开发的智能CDN节点部署软件。充分发挥了P2P和传统CDN的智能节点调度和SDK实现数据串行变并行、单路变多路,算法与协议可长期持续优化,且100%防盗链防劫持的多重优点。轻松让智能设备升级为CDN节点。BlockCDN团队充分掌握和利用分布式CDN、智能调度,分层发布、动态部署、动态防御DDOS等核心技术优势。有效的实现了互联网热门领域如:游戏下载、移动应用、视频点播、智能硬件和在线直播等的加速服务。并团队计划研发以分布CDN 节点为基础的衍生产品:云计算和云存储。 Squid开源代码如下:https://github.com/squid-cache/squid 如何运用区块链智能合约完成支付 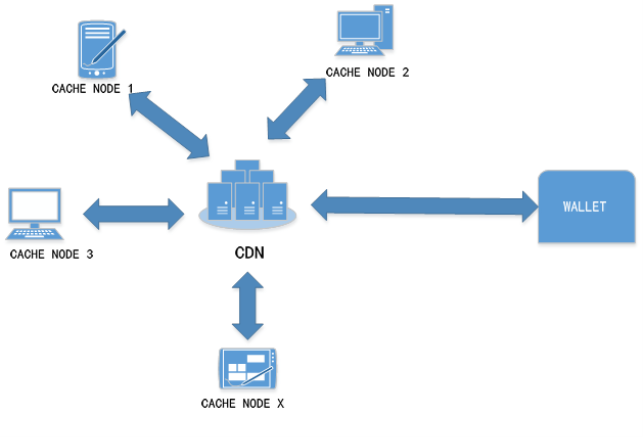 上面的图片是操作框架。 钱包:数字钱包保持令牌(BCDN)。钱包可以在自助平台购买CDN加速量,通过输入需要加速网站和加速流量大小,流量单价。 CDN需求者:为网站,通过虚拟钱包买了自己需求的CDN服务 分享者:通过闲置的PC、路线、电视盒、手机等可以成为CDN缓存节点和为网站提供分布式加速,根据上传流量获得相应的BlockCDN代币 。【玩币族(http://www.blockvalue.com)专业币圈媒体,重点关注炒币本身。】 交易平台:用户可以通过第三方交易平台购买和出售BCDN。 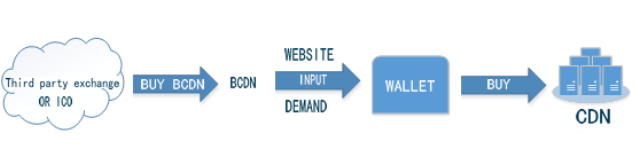 以上图片为CDN加速采购流程。 用户可以通过交易和官网众筹获得代币BCDN并保存它在钱包。 需要加速的网站主只要将需要加速的域名和加速流量以及bcdn需要支付数量输入BlockCDN平台。  上面的图片是bcdn获得、交易过程。 节点分享者通过上传上传加速流量根据区块链智能合约获得代币BCDN,他可以将BCDN保存在钱包。也可以在第三方交易平台出售或直接出售给需要CDN的客户。 交互所有数据所涉及的记录在blockchain随时可查,绝对公平正义和防修改。 CDN需求者的网站所有者可以在自助服务平台BlockCDN发布自己网站的加速度任务和奖励,该网站的数据将被部署在全网的缓存节点并通过数据将分散的SDK来保护数据的安全性。当网站被缓存节点用户附近的用户访问时, DNS智能调度和P2P的几个节点将为用户完成访问提供服务。节点缓存部署软件通过API提供上传数据(工作量)到blockchain节点。blockchain智能合同根据工作量奖励自动支付代币BCDN给节点分享者。 总结: BlockCDN 充分融合P2P网络在分布式文件,共享及定位等方面的优势,通过将各分享节点变成对等数据缓存库,并运用负载均衡、集群节点和服务定位等关键调度技术,使的CDN系统更灵活性、更健康、更具动态性。并BlockCDN保留了传统的Web服务器,让访问者在不用改变传统访问习惯,直接登陆Web服务器,系统会根据访问者的IP地址查找本地对应关系表,定位到相应的邻近节点服务器。由附近的节点服务器负责处理请求,并通过本地动态负载分配调度全局范围内的节点服务器进行动态负载均衡、内容分发、查找和管理从而建立完善的数据传输体系。作为自助CDN交易平台的BlockCDN通过融入区块链技术,让CDN交易更透明、更公正、价格更低廉,也又于区块链代币的支付功能让全民参与变得简单,让节点分享者收益支付更加便捷。(http://www.blockvalue.com/xinbi/blockcdn/201610267815.html) —- 编译者/作者:BlockCDN 玩币族申明:玩币族作为开放的资讯翻译/分享平台,所提供的所有资讯仅代表作者个人观点,与玩币族平台立场无关,且不构成任何投资理财建议。文章版权归原作者所有。 |
BlockCDN技术白皮书
2016-10-26 BlockCDN 来源:BlockCDN

- 上一篇:没有了
- 下一篇:BlockCDN白皮书1.2
相关阅读:
- Blockcdn又一个突破性的项目进展--电视机顶盒挖矿2016-11-30
- BlockCDN挖矿:BCDNMiner内测体验2016-11-30
- BlockCDN--创建区块链驱动的分享型CDN2016-11-25
- 优酷将首次试用BlockCDNs的区块链内容分发网络2016-11-25
- BLOCKCDN挖矿测试二三事2016-11-18

