玩币族移动版
玩币族移动版




揭秘以太坊交易包中未知类型的MEV
时间:2023-09-08 来源:区块链网络 作者:Foresight News
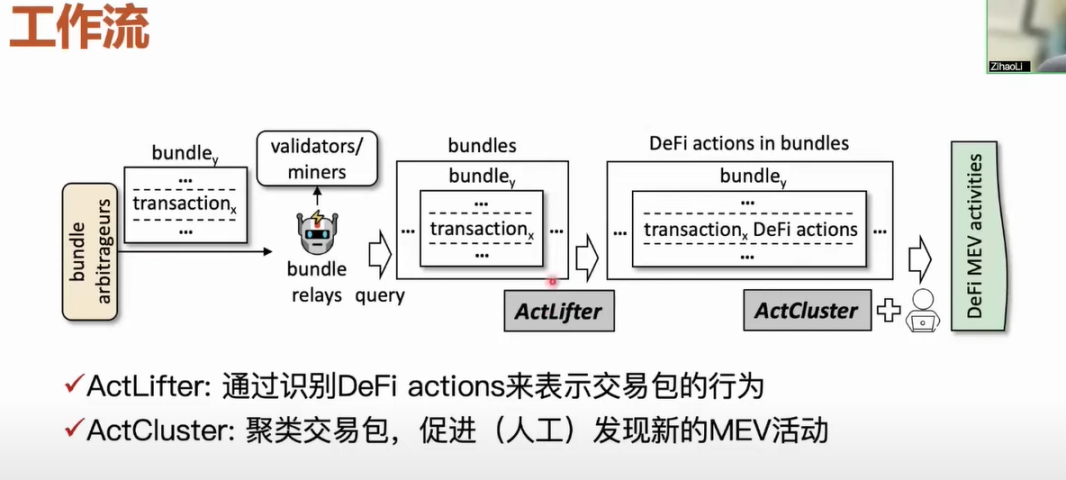
嘉宾:Zihao Li,香港理工大学博士生 整理:aididiao.eth,Foresight News 本文为 Web3 青年学者计划中 香港理工大学博士生 Zihao Li 视频分享的文字整理。Web3 青年学者计划由 DRK Lab 联合 imToken 和 Crytape 共同发起,会邀请加密领域中知名的青年学者面向华语社区分享一些最新的研究成果。 大家好,我是 Zihao Li,香港理工大学三年级博士生,今天分享的主题是《揭秘以太坊交易包中的 MEV 活动》。简单来说就是如何通过交易包发现以太坊网络中未知类型的 MEV 活动。首先我会做一个比较基础的背景介绍,比如 MEV 概念、交易包机制以及我们工作的背景。然后我会详细介绍完整工作流以及一些设计思路,例如基于什么样的设计原则来设计的工作流;我们的数据集有哪些;我们使用了哪些工具在哪些指标上评估我们的工作流等。最后我会介绍三个应用包括相关的实证分析结果。 背景介绍:MEV、交易包、动机 MEV 活动是指区块链中的套利者通过监控区块链网络包括区块状态等生成套利交易。一些交易信息是在区块链 P2P 网络上传播,或者说在矿工或者验证者的交易池中储存还没有正式上链的一些交易,当套利者监听到这些交易信息之后,他通过一些策略产生自己的套利交易,然后把套利交易指定在接下来区块某一个位置,比如说他要在下一个区块的头部,或者说在某个交易的后面紧跟着执行策略化交易来传播一样的套利交易。这样去指定某个位置的套利活动,我们可以把它认为是 MEV 活动。比如套利者监控到资产价格发生了波动,它就可以在价格低的交易池中购买到相应的资产,然后在另外一个价格高的资金池中高点卖出,这样我们认为是一个 MEV 的活动。 MEA 活动目前来说主要是套利者围绕 DeFi 生态展开的,因为 DeFi 生态目前主要聚集着资产,到目前为止,以太坊包括其他链 DeFi 生态已经吸引了超过 400 亿美元的资金量。这里需要提一个关于 DeFi 生态的概念,称之为 DeFi action,它对应的是一个 DeFi 应用提供的原子化服务操作,比如像我们知道 AMM 支持不同类型的资产之间进行兑换,用户可以出售一笔 USDC,然后得到一笔 ETH,这样的一个操作可以被定义为 DeFi action。我们可以用 DeFi action 将 MEV 活动表示出来,例如一个用户监测到不同 AMM 上面资产价格有些差距,用户就可以通过低买高卖的方式,最终获得这笔价差利润。我们可以将这个 MEV 活动表示为两个 DeFi action。 目前学术界对于 MEV 活动的研究主要分三类,分别是三明治攻击、反向套利和清算,在我们工作的数据集里面,我们发现这三种 MEV 活动出现次数超过 100 多万笔。这里其实有一个问题,在我们知道这些 MEV 活动的定义之后,要怎么去识别活动的发生。如果我们想要识别这些 MEV 活动,我们就需要识别套利者的全部活动,比如说套利者产生哪些交易,这些交易里面又有哪些类型的套利,然后我们才能确定当前是哪个类型的 MEV 活动在发生,而整个过程严重依赖于我们对已知 MEV 活动的定义。以三明治攻击举例,我们知道三明治攻击的定义之后,想要确定三明治攻击的套利值,还有它对应的套利交易,我们需要从定义出发设置非常多的规则,然后通过这些规则筛选出候选三明治攻击的套利值和交易。当通过这种方式去识别已知 MEV 攻击类型时,这里会有两个问题,第一个问题是我们已知三种常见的 MEV 活动是否能够代表所有的 MEV 活动?显然是不能的,因为 DeFi 生态一直在发展,新的应用也一直在开发,而这些套利者本身的策略其实也是在一直迭代的。第二个问题是我们怎么才能去发现这些未知的 MEV 活动。我们抱着这样的问题来看一下交易包机制。 交易包机制最早是在 2021 年提出的,简单来说就是用户可以组织交易队列,这个交易队列的长度可以是一个交易,也可以是若干个交易,然后用户将这些交易发给区块链网络中的中继者,中继者将这些交易收集之后直接并且私密地发给相关的矿工或者验证者。目前中继者会运行交易包去承接中继任务。交易包机制有一个非常重要的特征,这些用户在构造交易包的时候,他可以将其他人还没有上链的交易放到一个交易包,并且交易包中的交易顺序是可以任意操纵的。这个时候交易包的用户或者说使用交易包的套利者就可以设计他的套利规则。比如说他可以设计更复杂的并且获利更多的 MEV 活动策略。以三明治攻击为例,如果没有使用交易包,一个三明治攻击的套利者至少需要产生一对交易才能实现套利,而这一对套利交易只能针对这一笔交易。这个攻击交易产生套利需要必须是以一定顺序执行才能确保它能够套利成功。但是如果一个套利者使用交易包时,他就可以收集很多笔可以套利的交易,只需要用一对相应的套利交易就可以同时对多笔交易产生套利。这个交易包只要上链,它就一定套利成功,并且因为它同时对多笔可套利的交易进行套利,所以说它的套利结果也是收益更多的。 交易包的特性是有非常丰富且复杂的 MEV 活动。因为使用交易包的用户将自己完整的交易封装在交易包中,然后发给 P2P 网络的中继者,最后发给相应的矿工和验证者。我们通过交易包可以准确且完整的去识别到全部活动。因此我们是可以通过交易包媒介去比较准确的识别到一些未知的 MEV 活动。 工作流与设计思路 接下来具体介绍一下我们的工作流。我们是怎么通过交易包这样的媒介去发现未知的 MEV 活动的呢?核心工作流包括两个工具,首先我们在中继者收集到交易包之后使用 ActLifter 工具将交易包中的每一笔 DeFi actions 识别出来,在拿到结果之后,再将这个交易包中所有行为表示出来。然后用 ActCluster 工具通过聚类的方法将有着相似活动的交易包聚集到一起,通过聚类出来的结果,更快地发现新的 MEV 活动。如果我们想要发现未知的 MEV 活动,那么不可避免地需要人工最终确认 MEV 活动是不是一个未知类型,当然我们工作设计的目标尽可能的让人工工作量最小化的,并且让整个过程是尽可能自动化地开展。 目前已经有一些工具可以从交易中识别 MEV 活动。我们可以粗略分为两类,第一类是纯人工总结规则;第二类是纯启发式规则,也就是用一个纯自动化的启发式规则识别特定类型的 MEV 活动。例如它识别到目前的一些转账信息之后,检查有没有满足启发式规则,如果满足之后,就能够识别到对应的活动。第一种纯人工总结规则的方法能达到比较好的精度,因为这个过程完全是人工分析特定的应用,然后它可以保证检测结果是准确的,但是分析任务需要涉及到非常大的工作量,所以不能覆盖到各个 DeFi 应用。第二个工作虽然说可以实现纯自动化,但是启发式规则也只能覆盖到一些特定类型。另一方面启发式规则在设计上是有些问题的,导致它的识别精度不能让人满意。 我们综合两类方法的优点设计了我们工作流程。我们可以识别到十种目前比较主要的 DeFi action。我们只需要人工确定出来 DeFi 应用里面哪一个事件在发起之后是对应着哪一个类型 DeFi action 之后,我们就可以不需要人工分析,后面就可以完全交给自动化分析。第二类方法可以完全自动化识别到 DeFi action,但是它不能确定分析的对象是和 MEV 活动相关的。比如说我们识别到 SWAP 转账,它可能会将两个完全不相关的转账组合去识别成一个 DeFi action,自然它识别的结果是错误的。但我们可以借助这个信息去筛选出来真正和 DeFi action 相关的信息。而拿到这些信息之后,我们可以通过自动化方法规避掉像第二类方法中发生的一些错误情况。 比如这里有一笔交易一共涉及到了四笔转账,它们的发生顺序、资金数量和类别等用序号标示出来。在这个过程中,AMM 其实是发起了一个和 Swap action 相关的事件。第一类方法在确定到这个事件发起之后,它要通过事件的一些参数来恢复出来当前的内容。例如它需要看 699 合约的代码、业务逻辑和一些函数变量恢复出来当前的内容。我们在拿到这些信息之后,针对它特有的资产转账特征设计了一个规则,比如说我们提炼的规则就是当前操作 DeFi 的合约是有收到和转出不同类型资产,当我们发现有两笔这样的资产转账是符合这样的特征之后,我们就可以恢复出来对应的一个 Swap action 内容。第二类方法就直接去匹配两笔资产转账,这两笔资产转账账户是收到和转出了不同类型的资产。第一笔和第五笔这两笔转账它就会认为是一对相关的转账,并且认为中间的账户是一个 AMM,显然我们可以很直观看到识别结果是不准确的。 我们通过人工分析总结出来的规则是相关事件对应的 DeFi action 类型的,虽然说结果是通过人工分析总结出来的,但是我们还是尽量把人工分析的过程提炼成一个半自动化的过程,从而确保我们整个过程的可靠性。我们会从 DeFiPulse.com 和 Dapp.com 官网查询 DeFi 应用的官网、开发者文档,包括一些合约源码。我们开发解析工具能够从这些涉及到的材料中提取出关于事件在文档中的一些描述,例如这个事件是怎么用代币定义的以及在哪些函数里面,这些事件被使用的代码片段和代码注释。我们把这些东西提取之后,通过我们人工分析加讨论,最后确定出来有 88 个事件分别对应着不同类型的 DeFi action。 我们将待分析的交易输入这个字典当中,从交易中解析它发生了哪些事件。然后当事件在这个字典中出现之后,我们根据相应的规则提取出关键信息,例如是哪个合约在操作这个 DeFi action,然后这个 DeFi 的类型是什么,以及哪些资产转账是和这个 DeFi action 相关的。在拿到这样的内容之后,我们会对应总结出来资产转账的特征规则,然后用这个规则匹配最终的 DeFi action。我们从十个 DeFi action 定义出发,将资产转账的特征规则做了总结。我们在前一步收集到这些信息之后,我们会用这些匹配规则进行匹配,最终帮助我们识别到这个交易中有哪些 DeFi 发生了哪些具体内容。在 ActCluster 识别出来交易包中的每一笔交易之后,我们就可以表示出交易包的行为。 我们先了解一下 ActCluster 设计原则。我们知道人工分析在这个过程中是不可避免的,它必须要依赖人工才能确定出来交易包的活动是不是一个未知类型的 MEV 活动。基于这点,我们的基本思路是通过聚类的方式,将一些活动相似的一些交易包聚到一起。对于每个聚类,我们只需要随机抽样一个或者是几个交易包分析,就能加速人工分析的过程,最终发现不同类型的 MEA 活动。我们使用聚类分析对交易包进行聚类时,会面临一个两难的问题。当我们把交易包的聚类力度设置的比较粗时,包含着不同类型活动的交易包会被聚到一起,这个时候虽然说聚类出来的数量是变少了,相应的人工分析任务也是变少了,但是有一些新的 MEV 活动会被漏掉。假如说我们把聚类的力度调的比较细的话,虽然说我们能区分出来一些相似但是不同的 MEA 活动对应的交易包,但是相关涉及到的人工分析的工作量大大增加了。 基于这样的一个问题,我们设计了迭代聚类分析的方法,它会多轮迭代地进行聚类分析。每一轮我们会把包含着已知的前几轮发现了新 MEV 活动交易包剔除出去,然后对接下来剩下的交易包提升聚类的力度。我们不能直接使用传统的聚类方法对交易包进行聚类的,因为交易包其实是包含着多笔交易,而一笔交易里面又可以包含着多个 DeFi action。整个交易包我们如果把它表示出来,它的结构其实是异构,是分层的。这个时候我们就用了表示学习的方法将这个交易包的内容表示到一个定位空间里面。我们使用表示学习的优点就是我们不需要对我们要分析处理的数据进行深度学习和理解,也不需要很丰富的领域知识,我们只需要单纯的做数据导向处理就可以了。 比如说我们只需要对交易包用标签标注一下交易包里面包含哪些 MEV 活动。如果知道一个 MEV 活动定义的话,我们是比较容易设计相应的规则,能够自动化的检测出来它有没有存在。我们可以自动化对这些要表示学习的交易包进行标签标注。我们的聚类分析是一个迭代类型的,而在每次迭代之后,我们可以发现新的 MEV 活动,这个时候我们其实是可以将这些新发现的 MEV 活动对应的标签丰富到我们表示学习的过程中。当我们表示学习过程中使用的标签被丰富的时候,整个表示学习模型训练的性能和效率是可以迭代提升的,而且这个表示学习对交易包的活动表示能力也可以迭代提高。一个交易包里面其实是可以有多笔交易的,而一笔交易里面其实也是可以有多笔 DeFi action 的,我们需要将交易包需表示出来。首先对于每一类的 DeFi action,我们定义出一个标准化参数,比如哪个合约在操作在进行的,然后收到的和转出的资产的数量和类型是什么?我们通过这种方式去定义出每种 DeFi action。如果我们识别到一个交易里面有多个 DeFi action,我们将它们用 action block 表示出来,从而能够将这个交易对应的 transaction block 表示出来,包含着交易的源信息,比如这个交易谁发起的,这个转向又是发给谁的等。交易里面发生 DeFi action,我们会按照顺序去用 action block 做填充。其中的每一笔交易用 transaction block 做一个表示,最后我们获得的交易包的结构,而这个可以认为是一个矩阵。在这个交易包表示出来之后,我们就可以拿去做表示学习。每个交易包是一个统一结构,然后我们就可以用模型进行批量处理了。 性能评估 接下来分享我们用了哪些方法来评估工作流性能。我们整个分析过程的数据集是通过 Flashbots 提供的 API,并且收集了 2021 年 2 月到 2022 年 12 月的交易包数据,包括了超过 600 万个交易包以及 2600 万个交易。 我们设计了一些工具用来比较 DeFi action 的精度和完整度。这里需要注意的是,在这些链上工具里面,目前只有 Etherscan 可以通过它的网页和它的提供的信息恢复出来交易里面的 DeFi action。而像 DeFiRanger,我们是根据他们的论文复现出来他们的方法。在此之外,我们设计了一个叫做 EventLifter 工具,尝试直接从交易事件去恢复出来 DeFi action。我们在不同的配置下测试了 ActLifter,同时用了多样工具去比较识别的精度。对于 ActCluster 来说,我们主要思路是采用消融学习的方式,我们对于能够识别到的新活动,在消融掉 ActCluster 一部分模块之后,我们如果还想识别到没有发现的一些新活动,我们需要人工分析多少交易包或者说我们人工分析的工作量是有多大。比如我们对 ActCluster 表示学习模块中的动态标签更新做了一个消融,我们其实就是把整个过程消融掉了。我们从 600 万个交易包中去随机抽样,然后看我们要人工分析多少个交易包才能发现同样数量的新 MEV 活动。 我们的工具在配置统一的情况下是能够达到接近百分之百的精度和完整度。但是像其他工具如 Etherscan 虽然它的精度能达到百分之百这比较满意的情况,但是会有漏掉非常多的 DeFi action。Etherscan 本身是没有开源方法的,我们推测它可能是用人工分析的方法总结规则来识别 DeFi action,它相应的会漏掉一些人工无法覆盖到的类型。这里需要注意一点 Etherscan 其实是没有提供自动化接口,如果你想去做大规模识别,其实是不能直接完成这样的任务。完全使用潜规则识别的 DeFiRanger 在精度和完整度上不能让人满意。我们对 ActCluster 做实验之后,发现可以通过四轮迭代分析,一共只需要分析 2000 个交易包就可以找出来 17 个未知 MEV 活动。像我们将其中的一些模块进行消融之后,我们最多可能需要人工分析 17 万个交易包,才能把刚刚提到的 17 种未知 MEV 活动识别出来。 实证分析和应用 我们这样能够识别到未知类型 MEV 活动的方法有哪些具体的应用呢?第一它是否能够增强当前存在的 MEV 缓解措施,能够去防御一些 MEV 活动。第二个是利用分析结果,我们是否能够更全面的分析 MEV 活动对区块链生态的影响,包括对区块林分叉重组和用户金融安全的影响。 我们前面有提到过 MEV boost 网络攻击者会运行工具将交易包从用户这里拿到,然后最后分发给连接他们的这些矿工和验证者。中继者会把他们收到的交易包中包含着 MEA 活动的交易包剔除出去,他们通过这样的方式能够减少 MEA 活动对区块链的一些负面影响。这个环节主要的思路是通过已有的 MEV 活动的定义设计相应的规则去检测交易包里面有没有包含 MEV 活动。显然这些中继者是无法排除掉一些包含未知 MEV 活动的交易包。基于我们的工作流,我们就设计了一个 MEVHunter 工具,这个工具可以把我们检测到的新类型 MEV 活动从交易包里面检测出来。 检测结果显示有 100 多万个交易包里面是包含反向套利 MEV 活动的,另外 600 万个交易包里面有 30% 的交易包是包含三种已知的 MEV 活动。对于我们新发现的 MEV 活动,我们发现接近一半的交易包是只包含这些新 MEV 活动的。如果中继器用 MEVHunter 工具的话,可以帮助他们筛选出来 300 万个包含着 MEV 活动的交易包,然后可以选择把这些交易包去剔除出去,降低 MEV 活动对区块链的负面影响。 第二个应用是我们去探究新型 MEV 活动对区块链分叉和重组的影响。之前的一些研究有报道说一些金融性的矿工会被一些 MEV 活动的收益所激励,从而去分叉和重组当前的区块链,自己去进行 MEV 活动并享有收益。比如当一个区块的 MEV 活动的收益是区块奖励的 4 倍时,就会有不少于 10% 的矿工对这个区块进行分叉和重组。 我们首先根据刚刚提到的 MEVHunter 工具识别到哪些交易包包含新的 MEV 活动,然后通过这些交易包中矿工的收益去预估这些 MEV 活动相应的强度。这里需要介绍一个概念,在交易包机制里面,这些套利者为了确保自己的套利交易包能够上链,通常会将 MEV 活动收益的一部分分享给矿工,然后矿工最终会选择收益最高的交易包上链。我们用这一笔收益是可以统一预估出来每个交易包中 MEV 活动的。根据我们的统计结果发现 MEV 收益是区块奖励的四倍到八倍的区块一共有 900 多个,另外有一个区块的 MEV 奖励甚至是区块奖励的 700 多倍。我们用马尔科夫决策的框架确定给定一个 MEV 收益,最少能够激励多少矿工进行区块分叉和重组。我们最终发现有 1000 多个区块是可以激励不少于 10% 的矿工去做区块分叉和重组。而像最严重的区块,有不少于万分之六比例的矿工去做区块分叉和重组的。 第三个应用是探究 MEV 活动对区块链用户金融安全的影响。MEV 活动其实是可以导致区块链用户的交易在交易池或者 P2P 网络上等待上链的时间会被延长,这也是 MEV 活动对用户的金融安全主要威胁之一。如果用户的交易被延迟上链了,那么套利者就可以有更多的时间设计更复杂且获利更多的 MEV 活动。第三个应用是比较 MEV 活动对于用户交易最后上链需要等待时间的影响。第一步我们同样是收集交易的等待时间。我们主要是通过在网络上部署节点,然后记录第一次发现在网络上发现这个交易的时间,以及这个交易最终上链的时间,最后算出它需要等待的时间。我们用每个区块中所有交易的等待时间的三个四分位点去做统计,这样我们就可以以每个区块为单位将交易的等待时间整理成一个时间序列。然后对应每个区块里面的 MEV 活动也是用每个区块里面矿工从包含着新 MEV 活动的交易包中获得的收益刻画出来,这样的话我们就拿到了多条时间序列。我们通过格兰杰因果测试评估 MEV 活动对于交易时间的影响,因果测试可以确定一条时间序列里面的波动是否导致另外一条时间序列的波动,以及它在多长范围内影响或者导致了另外时间序列里面的波动。当 MEV 活动发生波动的时候,它是否导致用户的交易的等待时间变长,以及在后续的多少个区块范围内影响是存在的。 因果测试的 P 值小于等于 0.5 时,意味着这个区块内的交易等待时间被之前的 MEV 活动影响而延长了。根据分析结果可以发现当发生 MEV 活动时,后续两个区块内 50% 的交易等待时间会被延长。当 MEV 活动发生之后,接下来 30 个区块内 25% 的交易等待时间会被延长。矿工或者验证者会把 Gas 费比较低的交易放到封装区块的尾部,用户交易 Gas 越低,受到 MEV 活动的影响范围就会越大,等待时间会被延长的更久。 最后总结,我们首先分享了如何通过工作流找到未知的 MEV 活动,以及工作流中两个模块的详细设计,然后我们通过实证分析验证了工作流的有效性,同时列举了三个应用。目前,我们用工作流发现了 17 种新的 MEV 活动。 查看更多 |