 玩币族移动版
玩币族移动版




如果数据被大模型耗尽,我们还能看到通用人工智能吗?
时间:2023-09-11 来源:区块链网络 作者:AIGC
原文来源:自动驾驶下半场  图片来源:由无界 AI? 生成 我们正在通用人工智能的前夜。ChatGPT 在激发了全世界热情的同时,也引燃了AI大模型的竞赛。Google推出Bard 对标, Amazon 也加入战场, 豪赌元宇宙的Meta也不甘示弱,推出了LLaMa和SAM。 大洋这边,公认手握最多资源的 BAT 再次在生成式模型上相遇。而具身智能乘着大模型的东风,似乎也在酝酿一场巨大的变革。 一切仿佛又回到了十年前,创业热潮涌现。只是这一次,通用人工智能的奇点由大模型开启,而数据正式站到了舞台中央。 01、开发大模型的关键要素是什么算力让大模型成了财富的游戏大模型, 通俗来说就是参数量巨大的模型。相较于之前单个GPU就能运行的小模型,只能靠大公司巨量的算力堆叠才有可能完成。例如OpenAI ChatGPT 目前每次训练成本高达百万美元。小实验室参与人工智能浪潮的可能性被大模型直接宣告结束,只有雄厚积累的公司才能完成。 所以通用大模型创业潮中浮现的只有当年互联网创业潮中有过精彩故事的英雄, 美团王慧文,创新工场李开复,搜狗王小川。而模型的摩尔定律已经出现,更大的模型带来了更好的世界理解能力、推理能力, 趋势如此,已经没有停下来犹豫的时间。 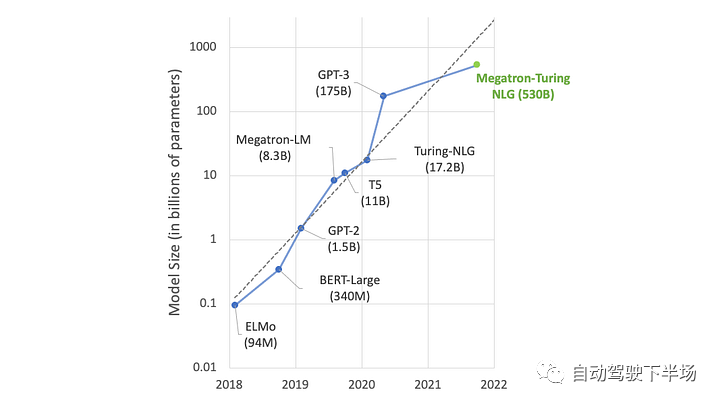 算法模型为中心的开发模式已过 算法模型为中心的开发模式已过目前普遍人工智能公司的开发模式仍旧是以模型为中心的“传统”开发模式,即将数据集固定进而迭代模型。算法工程师们通常会聚焦于几个基准数据集,然后设计各式各样的模型去提高预测准确率。 虽然大模型如雨后春笋般浮现,但是实际上大部分模型背后的算法都趋于一致,并未出现大的模型改动。 而数据量的堆叠让训练好的模型表现远远优于小改动的模型。比如数月前,人工智能先驱Yann LeCun发文称ChatGPT在技术上并不是什么新鲜事物, 但是却取得了优异的表现。精心的算法改动,很有可能并不能比添加、迭代数据产生的效果更好。而巨量优质数据带来的模型表现,相较于某一单独数据集上训练模型的表现,是降维打击。 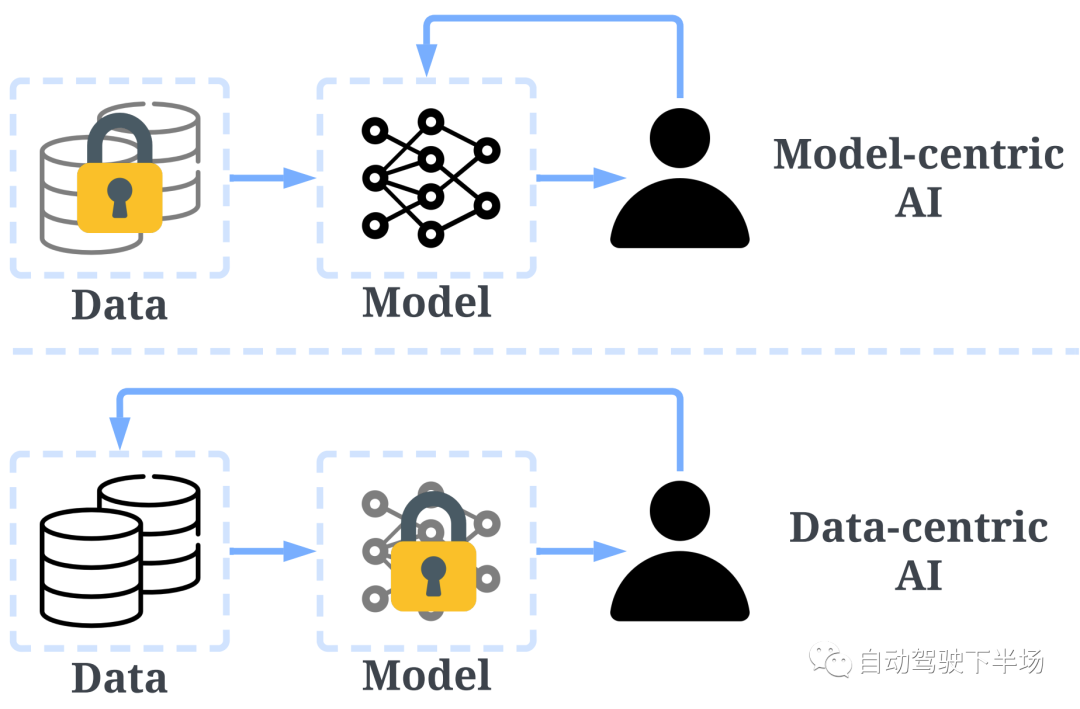 数据成为大模型开发核心要素 数据成为大模型开发核心要素OpenAI大模型的成功正是出自Ilya对于大数据大模型量变带来质变的坚信。例如ChatGPT 用了至少40T的大规模数据进行训练,而且如果有效数据量继续增加,其能获得更好的表现。根据Google研究 Emergent Abilities of Large Language Models,在模型参数的某一个临界点, 突然模型获得了令人意想不到的能力。 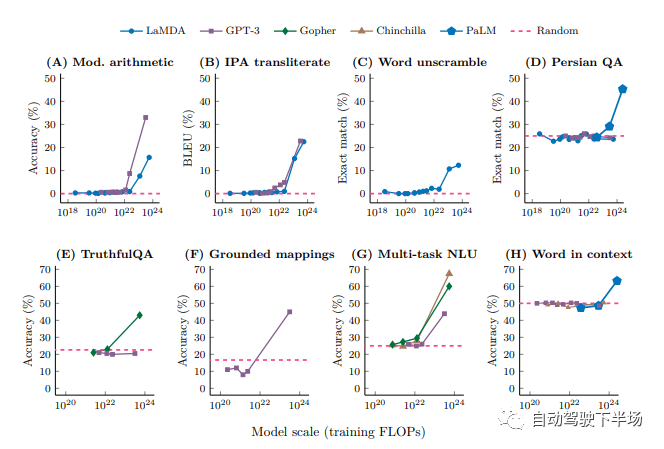 而为了保证如此多的参数能够获得合理的训练,高质量的数据成了关键钥匙。以ChatGPT的发展为例,GPT-1只用了4629 MB 的文本数据, 而GPT-2 用了40 GB 来自Reddit 上爬取并筛选的文本, 而GPT-3 用了至少45TB的纯文本,GPT-4的具体训练过程并没有披露, 但是鉴于GPT-4的推理速度比GPT-3慢很多,模型的参数数量可以推测出也变多了,进而对应的训练数据显然需要更多。这些高质量的数据是ChatGPT 首先出现在英文世界的重要原因,英文的训练文本比中文的训练文本更为规范和丰富。 中国人民大学交叉科学研究院院长杨东也认为:ChatGPT能够成功的根本原因不仅仅在于技术本身,国内存在严重的数据不开放、数据垄断问题也是一大原因。而最近Meta 发布的语义分割模型Segment Anything Model, 整体有监督的模型并没有明显创新, 但是在语义分割领域海量数据的使用,让模型的表现令人惊叹。千万级的图片量和十亿级的分割Mask,是图像语义分割领域从未出现过的。 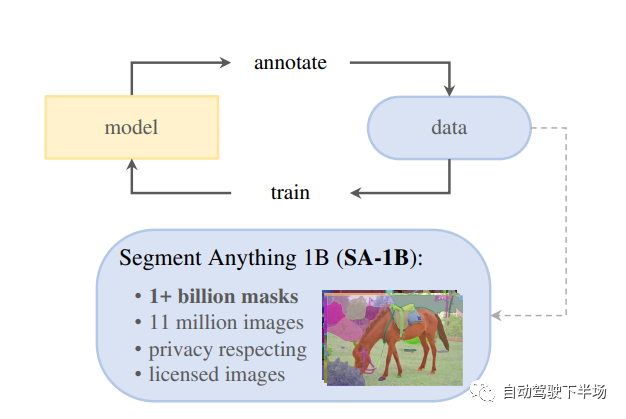 AI的开发模式正从以模型为中心转向以数据为中心。数据从何获取,世界上的数据够大模型们用吗? 02、真实数据会被大模型耗尽这个世界上,人类活动无时无刻不在进行,因此留下的数据痕迹不应该是不断增长的吗?为什么会被耗尽呢? 高质量的数据是稀缺的并非所有人类活动产生的痕迹都能用于模型训练,只有高质量的数据进入模型训练中才能产生最好的效用。 在自然语言处理领域,高质量数据自然是数字化书籍和科学论文。拥有较好的前后逻辑关系,也能保证相对正确。而低质量数据例如聊天记录、电话等, 由于数据连续性不强,对训练的作用也相对有限。在ChatGPT 3 的开发文档中提到,数据过滤在对45TB的纯文本进行质量过滤后,获得了570GB的文本,仅仅使用了1.27%的有效数据。 在自动驾驶领域,高质量的数据是大量不同场景产生的。 例如曲率相对较小的道路可能出现的频率非常高,但是实际上,出现次数越多,其重要性越弱。 反而一些不常规的场景(即Corner Case),数据的质量更高,也需要单独对其做场景适配。而这些相对较小的样本,面对大模型的参数要求,几乎是杯水车薪。 数据安全和隐私带来的局限性Generative AI 的发展一直伴随着数据安全的争议。 Stable Diffusion 开放使用之后,就引起了众多艺术家的不满,迫于压力,Stability AI 宣布允许艺术家们定向删除自己的作品,阻止其进入训练集中。 在某些情况下,公开数据可能包含敏感信息,如个人身份、财务信息或医疗记录等。在许多行业和地区,包含敏感信息的数据是非常难以获取的, 这提高了数据收集的难度,也降低了对应数据集增长的速度。也就成为了行业大模型的掣肘。例如医疗领域, 由于领域的特殊性及私密性,在严格的隐私保护和法规限制下想要获取到可以用于大模型训练的数据量,无异于天方夜谭。 高质量的真实数据可能不足以支持大模型的训练论文《Will we run out of data? An analysis of the limits of scaling datasets in Machine Learning 》探讨了数据短缺(数据量不足以满足大模型训练的需要)的可能性, 按照目前的模型的增长速度,到2026年左右,高质量的NLP数据将会不足以支持训练。语言和视觉模型的数据存量的增长速度比训练数据集的大小慢得多,所以如果按照目前的趋势继续下去,数据集最终会因为数据枯竭而停止增长。 在数据量越来越多的情况下,在非可控的数据收集方式中,大部分数据的收集是没有任何意义的。例如自动驾驶场景,车辆在路上不断收集新的数据, 但是实际能够被使用的只能是凤毛麟角。因此,在最近一次Nvidia CEO 黄仁勋 与 Ilya Sutskever的对谈中,他们也探讨了数据被耗尽的可能性。 03、合成数据可以满足大模型的巨量数据要求以数据为中心的开发模式让数据成了最重要的一环。训练算法需要数据,可是高质量的数据却难以获取,大模型巨量的数据需求应该如何被满足? 正如在食物上有合成肉一样,数据是否可以被人工合成呢?合成数据是在数字世界中创建的数据。 合成数据的可控性相较于真实数据更好,可以在数学和物理意义上反映真实数据的属性,可以定向生产的数据,保证训练模型时数据的均衡性。 合成数据具有信息增量在真实数据中学习到数据的分布,并且依据这种分布生产出更多的数据,保证多样化的场景下都有足够的数据用于大模型的训练。不同元素的组合带来了不同的场景,场景的变化也就带来了信息的增量,进而保证了合成数据的有效性。 根据OpenAI 和 UC Berkeley 在2017年的研究, 以实际场景出发,泛化摄像头的位置,物体颜色,形状,光照等, 生成大量的合成数据用于物体检测模型的训练。 在完全没有使用真实数据的基础上, 检测模型的3D误差保持在1.5cm以内,而且具有了非常好的鲁棒性。  例如在自动驾驶领域, 一个典型的真实的前车Cut-in 场景,可以通过合成数据进行泛化天气和光照再生产。由此产生的数据训练模型之后, 模型也就在不同的天气和光照下有了更加鲁棒的性能。根据Nvidia 2018年的研究, 使用随机化车辆位置和纹理的情况下生产的合成数据训练模型,检测模型的性能有了明显的提升。这归功于合成数据车辆的位置分布更加均衡,产生的数据也分布范围更广。 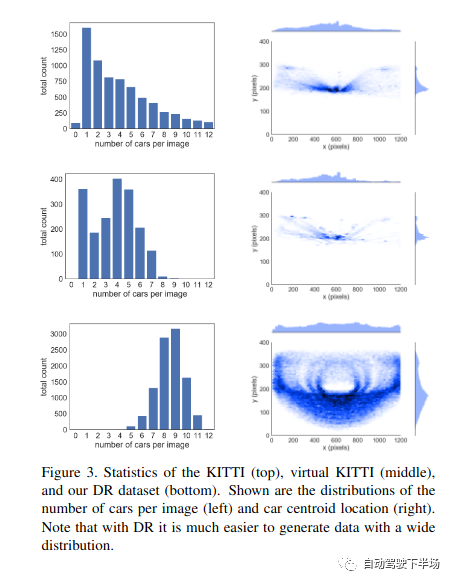 合成数据的可控性相较于真实数据更好,可以在数学和物理意义上反映真实数据的属性,可以定向生产的数据,保证训练模型时数据的均衡性。在定向生成数据时, 也就有了定制化大模型特性的可能性,例如希望语言类大模型在回答某些问题时有偏向性,在生成某些图片时有特别的风格和元素。这些都可以通过定制合成数据完成。 基于真实数据,但是又与真实数据不同。合成数据的这种特质使得其的应用范围越来越广泛,不仅仅用于测试,也能够成为训练数据,让模型能力更加强大。 合成数据的成本优势巨大数据的成本来自于采集和标注,在这两部分,合成数据都有显著的优势。 相对于真实数据低效的收集方式, 合成数据可以定向生成场景,让每一个字节的数据都是有价值的。不需要大量的数据采集团队,也不需要大规模的数据回传系统和数据筛选系统,合成数据从生产开始就根据模型训练的需求出发,大部分产出都可以直接使用,也就降低了数据采集成本。 同时, 合成数据标注成本相较于真实数据有非常大的优势,根据数据服务平台Diffgram 的估算, 在自动驾驶图像标注上,平均一个标注框价格约为0.03 美元, 整体一张图完整标注约为5.79美元, 而对于合成数据,标注价格基本接近于零, 有的只是数据计算成本, 只需要约6美分。总之, 合成数据可以更加可控地,更加高效,并且低成本批量生产海量数据,用于大模型的训练。 如果说真实数据的收集还停留在刀耕火种的农牧时代, 那合成数据的生产就进入了高效自动的工业时代, 低成本提供大规模高质量的产品。根据《MIT科技评论》将合成数据列为2022 年全球十大突破性技术, 认为合成数据可以解决数据资源不丰富的领域人工智能发展缓慢的现状。 04、哪些行业会需要合成数据事实上在国外,合成数据已经有了较为广泛的应用,机器人领域,自动驾驶领域,自然语言处理, 金融,医疗等等,我们都能看到合成数据的身影。 早在2018年,OpenAI 就使用仿真模拟环境对机器人控制器进行训练,训练过程会随机环境动态, 然后把控制器直接应用在实体机器人身上,通过这种方式让机器人在执行简单任务时,可以应对外界环境预料之外的变化。  2019年根据摩根大通的报告,其使用合成数据去进行金融欺诈检测模型训练,以克服金融欺诈数据极少的问题。 斯坦福大学最近也发布了自己的70亿参数的对话大模型Alpaca,尤其有趣的是,研究所涉及到的数据集, 是团队用OpenAI 的API生成的, 也就是说,整个训练数据集完全由合成数据组成,并且最后效果也比肩GPT-3.5。 再以自动驾驶为例,作为计算机视觉的重要落地应用,自动驾驶行业已经在合成数据的使用上走的很远了。为了降低测试成本,提高迭代效率,行业内广泛使用仿真引擎来进行自动驾驶算法的测试和验证。 基于视觉的自动驾驶功能需要采集海量的真实场景数据来训练深度学习模型,用以完成对世界的感知。然而量产的长尾数据通常难以在真实世界中进行采集,或者无法采集。同时,在不同时间和天气条件下,即使同一物体的外观也会有很大差异,这给视觉感知带来极大的挑战。 相较真实数据的采集,合成数据的成本可控,且无需人工标注,大大减少了因数据采集流转流程以及人为标准不一致所带来的人为误差。因此合成数据被业界认为是解决长尾问题的有效方式之一。 但是为了更好地训练自动驾驶系统,大部分仿真数据的质量是远远不够的, 它们无法反映真实世界,只是真实世界的高度抽象。所以业界很多公司在提升数据的真实度上投入巨大, 例如Nvidia的自动驾驶仿真软件DriveSim采用先进的物理渲染技术,让合成数据的真实度得到提升。  Cruise和Waymo使用NeRF 相关技术生成数字孪生世界进而生产合成数据, Nvidia 也在2022 年提出Instant NGP, 极大提升了NeRF的训练效率。  Telsa 早在2021 年的AIDay 上就用高速上奔跑的一家人场景和难以标注的人群训练了感知系统,令人印象十分深刻。  与此同时,在行业前沿的硅谷众多合成数据公司开始涌现,为自动驾驶服务的Parallel Domain、Applied Intuition、为广义机器视觉行业服务的Datagen、扎根自然语言处理的Gretel ai,这些公司背后站着行业领先的巨头们。 Gartner预测称,2024年, 60%的训练数据会由成数据取代,而 2030年合成数据将彻底取代真实数据,成为训练AI的主要数据来源。 但是国内,实际上合成数据的应用相对较少,目前大部分公司还是使用真实数据去完成模型的训练。 05、合成数据的局限在完全取代真实数据之前, 合成数据还有哪些问题需要被解决?这里以自动驾驶为例做一些探讨。 真实度从感知的角度看, 真实度确实是第一评价指标。在这批数据进入训练系统前,是否能通过人类的视觉第一性检验,保证看起来真实? 对于真实度的劣势,肉眼所及的真实并不代表数据的真实效用, 一味地追求图片视觉的真实度可能并不具备实际可量化的意义。评价合成数据真实度的量化标准需要建立在合成数据集对于经过合成数据集训练的算法在真实数据集上的提升上。目前,在对合成数据真实度要求最高的自动驾驶行业,已经有Cruise、Nvidia、Waymo、Tesla等基于合成数据实实在在有效大幅提升算法在真实道路上表现的实例。当然,随着算法的提升,对于合成数据真实度的要求也会水涨船高。而生成式AI近期的不断突破又给了我们很好的增强合成数据真实度的切实方向。 场景的多样性合成数据世界模型的构建,例如自动驾驶场景的构建。 我们需要创建一个虚拟世界,并且模拟真实世界的运行,让合成数据如泉水般流淌出来。传统方式会基于人工算法建模来实现,比如传统合成数据生产商纯基于物理引擎的构建方式决定了场景构建的速度,整个物理世界需要3D 资产工程师们手动搭建,一个建筑,一个路牌都需要手动放置,这也就制约了场景的构建速度,也极大限制了场景的多样性。而生成式AI如Diffusion Model、Nerf为合成数据的产线提供了以数据为中心,自动化建模的可能性。 人工搭建的场景让合成数据的泛化性受到了极大的限制,毕竟我们希望训练的算法具有足够高的鲁棒性,能够直接在真实世界中有足够好的表现。 显然,用人工搭建的方式无法覆盖真实世界中的每一个场景,为了创建足够覆盖真实世界的所有数据, 我们需要学习到真实世界的隐式表达,进而生产足够多样的场景。这必须依赖生成式AI。 生产效率为了快速提供大批量、高泛化性的数据,云端大量并行生产是第一要义,用高算力支持数据的快速生产能让数据以真实世界中无法比拟的速度合成 06、生成式AI让合成数据大规模取代真实数据成为可能NVidia 黄仁勋认为,人类的反思和梦境都属于合成数据的一部分,这相当于AI生成数据去训练AI。为了满足大模型的巨量数据需求,我们需要完全自动化合成数据的生产链路, 让AI训练AI成为可能。 得益于最近发展迅速的Diffusion Model 和 NeRF, 高质量的AI合成数据不再是幻想。Diffusion Model 的基于马尔科夫链的精巧数学过程让更大,更稳定的图片生成模型成为可能, 也克服了对抗生成网络训练难度太大的问题。 Stable Diffusion Model 用巨大的图片集让人们看到了Diffusion Model 的无限可能,而ControlNet 相关网络的提出也让特定领域的适配变得更加便捷。 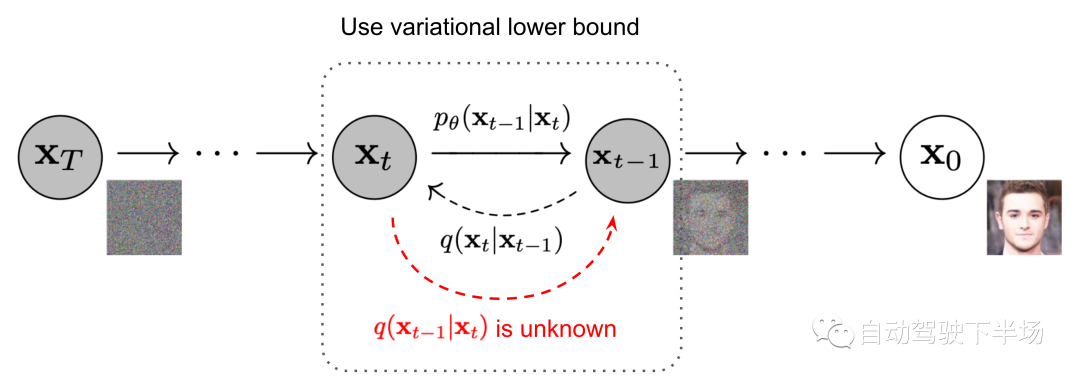 而NeRF( Neural Radiance Fields) 将3D 世界的构建变成一个神经网络的学习过程,将神经场(Neural Field)与体素渲染有效结合在一起,能够非常逼真地重建3D世界,非常有希望取代繁琐的物理引擎构建过程。 Waymo 基于此技术发展了BlockNeRF, 将旧金山高效重建出来,并且在其中进行合成数据的生产。而最近CVPR的Highlight 论文UniSim 更是将NeRF 的应用向前推了一大步。 基于这些技术,AIGC独角兽开始出现。 StabilityAI(Diffsion Model)、Midjourney(Diffusion Model)、LumaLab AI (NeRF)用大批量的数据训练之后,图片的真实性已经无法被质疑,而由此产生的艺术效果和新数据的表现方式让我们看到了合成数据泛化的光明未来。 07、写在最后ChatGPT 只是起点,自然语言领域的大模型也只是星星之火。虽然ChatGPT 已经基本具备初级人工智能的能力,这种能力是通过学习人类自然语言数据获取的,但是实际上,人类对世界的认知思考绝对不仅仅局限在语言和文字, 而是多模态的(图、文、声、光、电、影……)。不难推论,真正的AGI必须能像人类一样即时、高效、准确、符合逻辑地处理这个世界上所有模态的信息,完成各类跨模态或多模态任务。最近具身智能的热潮也在期待着新的多模态交互方式出现。 而这也就需要多模态的数据, 这又进一步加大了真实数据的获取难度,多模态的真实数据更加稀缺。 例如相较于随处可见的文字数据,图片数据,对应的高质量的3D数据集屈指可数。常用的科研图像数据集通常都包含上亿或更多图片,而很多质量较高,可用于科研的3D数据集只有数千或数万个3D模型。如果我们希望人工智能可以理解3D 世界,势必需要大量包含3D 模型的多模态数据。 这可能也需要合成数据去解决。 自动化构建世界模型、让AI可控生成多模态数据、去训练出更加智能的大模型才是真正通向通用人工智能的道路。 部分参考: https://lifearchitect.ai/ilya/?https://arxiv.org/pdf/1703.06907.pdf?https://arxiv.org/pdf/1804.06516.pdf?https://mp.weixin.qq.com/s/LTIISTtveQyaWYGXIyZJpghttps://crfm.stanford.edu/2023/03/13/alpaca.html?https://blogs.nvidia.cn/2022/09/20/drive-sim-neural-reconstruction-engine/?https://www.gartner.com/en/newsroom/press-releases/2022-06-22-is-synthetic-data-the-future-of-ai?https://lilianweng.github.io/posts/2021-07-11-diffusion-models/?https://mp.weixin.qq.com/s/CjwkWqgXFz6FaCqY_AE-Twhttps://new.qq.com/rain/a/20221221A05SQQ00?https://uxplanet.org/gpt-4-facts-rumors-and-expectations-about-next-gen-ai-model-52a4ddcd662a?https://mp.weixin.qq.com/s/CjwkWqgXFz6FaCqY_AE-Tw |